多角度剖析redis数据结构及底层实现原理、应用场景
目录
1.字符串(string)
1.1 redis的字符串类型:
1.2 string的编码方式有三种:
1.3 string的预分配空间机制;
1.4对比C语言的字符串优点:
1.5 string的使用场景:
2.链表(list)
2.1 redis3.2版本之前链表结构:
2.2 redis3.2版本之前ziplist转化为linklist条件 :
2.3 linklist结构:
2.3.1 linklist缺点:
2.4 ziplist结构:
2.4.1 ziplist数据结构定义:
2.4.2 ziplist的连锁更新问题:
2.4.3 ziplist使用场景:
2.5 redis版本3.2后的quicklist(快速链表):
2.5.1 quicklist相关结构:
2.5.2 注意quicklist的插入:
2.5.3 quicklist的优点:
2.6 list应用场景:
3.哈希(hash)
3.1 hash数据结构:
3.2 hastable的实现:
3.3 hashtable如何解决hash冲突:
3.4 rehash过程:
3.4.1 触发条件:
3.4.2 扩容过程:
3.4.3 扩容的意义:
3.5 hash应用场景:
4.无序集合(set)
4.1 set的数据结构:
4.2 使用intset结构的条件:
4.3 intset结构属性:
4.4 intset升级过程;
4.5 intset优缺点:
4.6 set应用场景:
5 有序集合(zset)
5.1 zset的数据结构:
5.2 使用skiplist的条件:
5.3 skiplist结构:
5.4 skiplist查找过程:
5.5 skiplist的插入过程:
5.6 删除过程:
5.7 修改过程:
5.8 skiplist的优点:
5.9 zset的应用场景:
6. bitmap定义:
6.1 bitmap的优点:
6.2 bitmap的使用场景:
7. HyperLogLog定义:
7.1 HyperLogLog的使用场景:
8. GEO定义:
总结:
redis是由C语言编写的,是以键值对(K-V)的方式来存储数据,K的数据类型为字符串(string)类型,V的值则为下文中的5种数据类型
1.字符串(string)
1.1 redis的字符串类型:
是由SDS(simple dynamic string) 来实现的。
结构定义:
struct sdshdr{
int len; //buff中已使用的空间
int free; //buff中未使用的空间
char buff[]; //数据空间
}
1.2 string的编码方式有三种:
int(整数类型,直接用redisObject存储), raw(大于39字节长度) , embstr(小于等于39字节长度)(redis 4.0之前的版本)
redisObject{
unsigned type : 4 //string ,list,hash,set,zset(4位 = 0.5字节)
unsigned econding: 4 //redis内部编码类型,如:hashtable,sds,ziplist skiplist等 (4位 = 0.5字节)
unsigned lru ://记录对象最后一次被访问的时间(24位 = 3字节)
int refcount: //用来记录被使用的次数,当值为0时,则可回收空间 (32位 = 4字节)
void *pre: //如果是int类型 则存储值,如果是其它类型则存储指向数据的指针(8字节)
}
使用重点提示:在高并发的情况下,尽量使其长度小于等于39字节,采用embstr类型,字符串SDS和redisObject一起分配(同时创建redisObject,sdshdr对象,分配空间连续),从而只需要一次内存操作(raw需要2次),减少创建redisObject的内存分配次数来提高性能
知识点提示:39字节长度 = embstr最小分配64字节 - len free 8字节 - /0 1个字节(结束字符) - redisObject(16字节)(
版本提示:在redis 5.0 后39字节 -> 44 字节,优化了SDS小内存使用,因为unsing int 可以表示很大的范围,但是对于很短的sds则浪费了2个unsigned int(8个字节的空间)
优化后为: struct __attribute__((_packed__)) sdshdr8(还有16,32, 64的使用){
uint8_t len;
uint8_t alloc;
unsigned char flags;
char buff [];
}
知识点提示:44字节 = (变动)原来的len 8个字节 - (uint8_t len uint8_t alloc unsigned char flags)3个字节 + 39字节
1.3 string的预分配空间机制;
在修改SDS时,会先检查空间是否足够,不足的会尽行扩容,防止缓冲区溢出。
扩容:当小于1M的时候,采用空间翻倍+1M,当大于1M,则每次+1M,上限为512M
缩短的时候,也不会立即缩短,而是采用惰性释放空间,采用对应的API来释放
1.4对比C语言的字符串优点:
使用起来更方便,C语言要碰到结束/0标志才用停止。
防止内存空间溢出,在使用之前会检查空间大小
预分配空间机制
1.5 string的使用场景:
缓存,session共享,限流,计数器
2.链表(list)
2.1 redis3.2版本之前链表结构:
ziplist(压缩列表),linklist(双向链表),redis3.2版本后使用quicklist(快速链表)
创建新列表时默认优先采用ziplist,节省内存空间
2.2 redis3.2版本之前ziplist转化为linklist条件 :
一:新添的字符串长度大于64字节。二:键值对数量大于512,则会由redis_encoding_ziplist编码转换成redis_encoding_linklist编码。以上2个条件的值在redis.conf中 list-max-ziplist-value 64 list-max-ziplist-entries 512可更改
2.3 linklist结构:
linklist是双向链表,Node节点包含prev,next指针,使其可以双向遍历,同时list还保存了head,tail两个指针,使其对于链表头部与尾部的进行插入的操作复杂度都为O(1),使用lpush,rpop命令具有高效性
链表节点:
struct listNode{
struct listNode *prev; //前置指针
struct listNode *next;//后置指针
void *value;//节点的值
}listNode;
链表:
struct list{
lsitNode *head;//表头节点
listNode *tail; //表尾结点
unsigned long len; //链表节点数量
void *(*dup)(void *ptr);//节点值复制函数
void (*free)(void *ptr);//节点值释放函数
int (*match)(void *ptr,void *key); //节点值对比函数
}
2.3.1 linklist缺点:
附加空间太高,prev next指针就占了16个字节,每个节点的内存都是单独分配的,容易产生内存碎片
2.4 ziplist结构:
是特殊编码的连续内存块组成的顺序存储结构,包含多个节点(entry),每个节点都可以用来存储一个整数或者一个字符串。
ziplist是通过上一个entry的长度 + 当前entry的长度来推算下一个entry的位置,牺牲读性能,来获取更低的内存空间的使用,存储短字符串存储指针比存储entry长度更费内存,典型的“时间换空间”
2.4.1 ziplist数据结构定义:
zlbytes:unit32_t zilplist的长度(字节)是一个32位的无符号整数,表示整个ziplist占用的内存字节数,对ziplist进行内存重分配跟计算末端时使用
zltail:unit32_t 到达ziplist表尾结点的偏移量,通过这个偏移量,可以直接弹出表尾结点。
zilen:unit16_t iplist节点的数量,当值小于UINT16_MAX(65535) 就是节点数量,等于时,需要遍历整个ziplist才能计算出
entry: 节点 ,长度由内容决定 =zlentry
zllend‘:标记ziplist的末端
知识点提示:entries才是存储节点的区域
typedef struct zlentry{
unsigned int preverawlensize,prevrawlen;// prevrawlen表示前一个节点的长度,preranlensize表示prevrawlen长度用1或者5字节表示
unsigned int lensize, len ;//len表示当前节点的长度 lensize表示 当前节点所需字节大小
unsigned int headersize// 表示当前节点header大小
unsigned char encoding;//节点的编码方式
unsigned char *p//指向节点的指针
}zlentry
如何通过一个节点找到另一个节点? 通过使用当前指针-前一个entry的长度,就可以获取指向另一个节点的地址
zlentry中属性值的作用:
prevrawlen:记录前一个节点的所占用的字节数,可以计算当前节点的前一个节点的地址,可以用来表尾向表头节点遍历。
len/encoding:记录当前content占有的内存字节数及存储类型,用来解析content
content:保存了当前节点的值
prevrawlen:如果前一个节点prevranlen长度小于254字节 则值为1。如果大于等于,那么 将第一个字节设置为254,后4个字节用来表示实际长度
2.4.2 ziplist的连锁更新问题:
在ziplist中,zlentry都会保存上一个节点的长度prevrawlen,假设新插入了一个节点长度254,而下一个节点的长度为253,就会导致由原来给的1字节变为5字节,使得下一个节点的整体长度发生改变,进而又影响到了下下节点,以此类似,会导致想多米诺骨牌一样发生连锁更新反应,产生空间再分配。
2.4.3 ziplist使用场景:
数据量小的情况下,不适合修改操作。
2.5 redis版本3.2后的quicklist(快速链表):
quicklsit实际上是ziplist跟linklist的混合体,结合了双方的优点,是一个ziplist组成的双向链表,quicklist分成N个quicklistNode中包含ziplist,prev,next.

未压缩时结构图

压缩后(LZF算法)的结构图
2.5.1 quicklist相关结构:
typedef struct quicklist {
quicklistNode *head; //指向头节点的指针
quicklistNode *tail;//指向尾结点的指针
unsigned long count;//所有ziplist数据的个数总和
unsigned long len;//quicklist节点个数
int fill : 16;//ziplist中entry能保存的数量,由list-max-ziplist-size配置项控制
unsigned int compress : 16//压缩深度,由list-compress-depth配置项控制
}quicklist;
typedef struct quicklistNode{
struct quicklistNode *prev;//前节点指针
struct quicklistNode *next;//后节点指针
unsigned char *zl;//数据指针,当前节点如果没有压缩则指向ziplist结构,如果压缩了,则指向quicklistLZF;
unsigned int sz; //指向ziplist实际占用的内存大小,即使压缩了也是指向压缩前的大小
unsigned int count:16 ;// ziplist包含的数据项个数
unsigned int encoding:2; //ziplist是否压缩 1 :ziplist , 2:quicklistLZF
unsigned int container:2;//存储类型,2表示使用ziplist存储
unsigned int recompress : 1; //查看已经压缩后的数据,用来标记暂时解压,后期再进行压缩
unsigned int attemped_compress:1; /* node can't compress; too small */
unsigned int extra :10; /* more bits to steal for future usage */
}quciklistNode;
typedef struct quicklistLZF{
unsigned int sz; //压缩后的ziplist大小
char compressed[];//柔性数组,用来存放压缩后的ziplist字节数组
}quicklistLZF;
2.5.2 注意quicklist的插入:
当要插入的数据没有超过限制的大小时,则直接插入
当插入的数据大于要插入的ziplist位置时,如果相邻的quicklist链接节点的ziplist没有超过限制大小那么就转为插入相邻quicklistNode的ziplist中,
当插入的数据大于要插入的ziplist位置时,如果相邻的quicklist链接节点的ziplist也超过限制大小时,则新建一个quicklistNode插入
2.5.3 quicklist的优点:
中和了linklist,ziplist的优点,进一步的压缩了列表,提高了性能。
2.6 list应用场景:
消息队列,排行榜,评论列表,点赞列表
3.哈希(hash)
3.1 hash数据结构:
hashtable ,ziplist(上文已有说明)
当哈希对象保存的键值对小于512,字符串长度小于64字节时,使用ziplist,反之则使用hashtable
3.2 hastable的实现:
是由一个dict的结构体,类似hashmap中的数据结构
typedef struct dict {
dictType *type; //类型函数
void *privdate;//私有数据
dictht ht[2]; //哈希表
int rehashidx//rehash索引 当rehash不在进行时 = -1 ,正在进行时为0
} dict;
struct dictht{
dictEntry **table; //哈希数组
unsigned long size; //哈希表大小
unsigned long sizemask;/掩码,用于计算索引值 = size -1
unsigned long used;//已有节点数量
}dictht;
struce dictEntry{
void *key; //key值
union{ //value值
void *val; //指针
unit64_tu64; //整数
int64_ts64;//整数
}v;
struct dictEntry *next; //下一个节点的指针
}dictEntry;
3.3 hashtable如何解决hash冲突:
取决于hash函数,需要均匀分布。redis默认的函数是siphash,均匀分布,性能佳。当出现hash冲突时,会采用数组+链表的方式来解决,被分到同一个哈希桶上的多个哈希表节点用next指针构成一个单链表,时间复杂度O(n)。
3.4 rehash过程:
3.4.1 触发条件:
负载因子 = 哈希表已保存的节点数量/哈希表大小
load_factor = ht[0].used/ ht[0].size
一,当负载因子大于等于1时,并且没有执行bgsave或者bgrewriteaof命令,即没有执行RDB快照或者没有进行AOF的重写。二:当负载因子大于等于5时,就会强制rehash
提示:当负载因子小于0.1时,执行收缩操作
3.4.2 扩容过程:
在将ht[0]的所有键值对移到ht[1]中时,采用的渐进式的rehash,防止数据量大的时候,会影响服务器的使用。
在扩容期间,dict.rehashidx= 0,删改查的操作会同时作用在ht[0],ht[1]两张表中,查找时会优先查找ht[0],找不到就到ht[1]中找,增加的操作只会出现在ht[1]中,随着rehsh操作,将dict.dictht[0].table中的每个dictEntry重新计算哈希值跟索引值,移到dict.dictht[1].table中,知道dict.dictht[0].used = 0时,表示rehash完毕.ht[0]会变成空表,并将ht[1]设置为ht[0],重新创建一个ht[1],为下一次扩容做准备,rehashidx值变为-1.
扩容大小:当初始化,dict.dictht[0].table时,会将容量增大到 DICT_HT_INITIAL_SIZE会扩容到4个,其它情况,会扩容到dict.dictht[0].used*2的2^n
3.4.3 扩容的意义:
在哈希冲突增多的情况下,时间复杂度由O(1) -> O(n),扩容的意义就是将时间复杂度逐渐趋于O(1)
3.5 hash应用场景:
用户信息,购物车
4.无序集合(set)
4.1 set的数据结构:
hashset(上文已有说明) intset
4.2 使用intset结构的条件:
集合保存的所有元素都是整数值,保存的元素数量不超过512个
4.3 intset结构属性:
typedef struct intset{
unit32_t conding;//编码方式 三种:INTSET_ENC_INT16 INTSET_ENC_INT32 INTSET_ENC_INT64
unit32_length;//集合包含的元素数量
int8_t contents[]; //保存元素的数组,从小到大有序排列,不包含重复值 ,时间复杂度为O(1)
}intset;
提示:intset存储的数据是有序的,查找的时候是通过二分查找来实现的
4.4 intset升级过程;
当要新增的元素已经超过设定的编码方式时,就发生整数的升级过程.
首先了解旧的编码方式,
然后确定新的编码方式计算出要新增的内存大小,将新元素从尾部插入,
根据新的编码方式,将之前的值充值,contents存在2种编码格式设置的值,需要统一,从新插入的元素位置开始,从后向前(防止数据被覆盖)将之前的数据按照新的编码方式来移动和设置。
4.5 intset优缺点:
优点:节省内存,只在需要升级的时候进行升级操作 缺点:升级过程耗费资源,而且不支持降级
4.6 set应用场景:
交集,并集,差集,交友圈,社交圈,点赞,收藏
5 有序集合(zset)
5.1 zset的数据结构:
ziplist(上文已有说明) skiplist(跳表)
5.2 使用skiplist的条件:
有序集合的元素数量小于512,有序集合的元素长度小于64字节时使用ziplist,否者使用skiplist
5.3 skiplist结构:
是一个有序的数据结构。它通过在每个节点中维持多个指向其它节点的指针,从而打到快速访问节点的目的,类似于二分查找,时间复杂度最快O(logn),最慢0(N)。
typedef struct zskiplist{
struct zskiplistNode *header,*tail;//头尾指针
unsigned long length;//节点数量
int level;//表中最大的节点的层数
}zskiplist
提示:可以通过以上属性来快速找到头尾节点,最大节点层数,实现时间负责度O(1)
type struct zskiplistNode{
sds ele;//节点存储的具体指
double score;//节点对应的分值,节点都按照分值从小到大排序
struct zskiplistNode *backward//前向指针
struct zskiplistLevel{
struct zskiplistNode *forward; //每一层的后向指针
unsigned long span;//到下一个节点的跨度
}level[]; //双向链表
}zskiplistNode;
提示:多个节点的分值可以相同,但是节点的成员对象必须唯一,然后按照对象的大小进行排序,对象小的排在前面(靠近表头的方向),对象大的排在后面(靠在表尾的方向)。
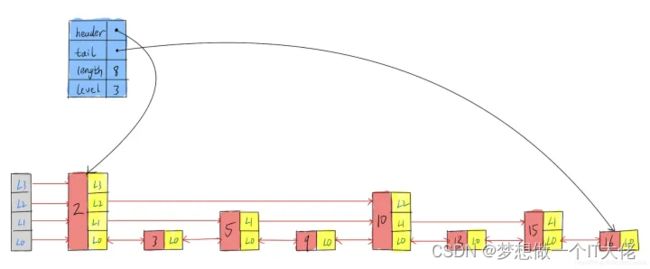
数据结构图
5.4 skiplist查找过程:
采用链表是想要保值修改时间复杂度低,那么查找过程的时间复杂度如何优化呢?故而出现了跳表,类似于二分查找的实现思想。只要保证整体上二分之一的概率就行,不用保证两两层级之间二分之一的概率
假设要找score为5的元素。
(1)首先从头结点的最高层(也就是64层)开始查找,但是由于头指针中保存了当前跳表的最高层数,所以直接从头结点的level层开始查找即可。如果zkiplistLevel的forward为NULL,则继续向下。
(2)直到头结点中第5层的zskiplistLevel的forward不为空,它指向了第6个节点的第5层,但是这个节点的score为6,大于5,所以还要从头结点向低层继续查找。
(3)头结点中第4层的zskiplistLevel的forward指向第3个节点的第4层,这个节点的score为3,小于5,并且第一个节点的span=2,这个span的作用就是用来累加并计算最终目标节点的排名的。继续从这个节点的forward向后遍历。它的forward指向第6个节点的第4层,这个节点的score为6,大于5,所以还要从前一个score为3的节点向低层继续查找。
(4)第3个节点第3层的zskiplistLevel的forward指向第5个节点的第3层,而它的score正好为5,查找成功。并且第3个节点的span=2,再加上原来的span=2等于4,所以目标节点5的排名是4。
5.5 skiplist的插入过程:
(1)插入节点时,会随机分配一个小于64的层数,层数越小概率越大,层数越高概率越小
(2)查找小于待插入score分数值中最大的那个节点,如果score相同,则比较对象大小
(3)在找到的节点后面插入新的节点,同时更新前面节点的跨度跟跳表的最大层高
(4) 更新新节点的各层forward和backward指针
5.6 删除过程:
(1)(2)找位置方式同上
(3)找到待删除的节点,删除节点,更新前面节点的跨度跟跳表最大层高
(4)更新被删除的节点各层的forward和backward指针
5.7 修改过程:
找到要修改的节点位置,直接删除,然后插入修改后的新的节点
5.8 skiplist的优点:
并不是特别耗内存,只要通过调整节点到更高level的概率,就能做到比B树更少的内存消耗
sorted set可能会面对大量的zrange和zreverange操作,跳表作为单链表遍历的实现性能亚于其它平衡树
实现和调试更简单
5.9 zset的应用场景:
实时排行榜
6. bitmap定义:
-又称位图,以位为单位的存储,内部还是采用String类型(最大长度为512M)存储(上限为2^32),可以理解为一个bit数组来存储特定数据的一种数据结构
6.1 bitmap的优点:
节省内存,适合处理大数据。可以实现快速排序,去重,快速查询是否存在(布隆过滤器),能方便的通过位预算(AND,OR,XOR,NOT)高效对多个bitmap数据进行处理
6.2 bitmap的使用场景:
活跃用户在线状态,活跃用户统计,用户签到等场景,适合大量的用户,几千万上亿级别
实时分析,存储与对象ID相关的信息
7. HyperLogLog定义:
-估算基数统计的算法,是LogLog算法的升级,在redis中实现HyperLogLog,只需要12k内存就能统计2^64个数据,存在一定的误差,误差率在0.81%
7.1 HyperLogLog的使用场景:
可以用来统计页面实时UV,注册IP数,每日访问IP数,
8. GEO定义:
-信息定位功能,支持存储地理位置信息,实现诸如附近位置、摇一摇这类依赖于地理位置信息的功能
总结:
根据自己的需要查阅多方资料,参考多为大佬的心得所写,记录下来,以便后面随时再复习一遍。