Redis布隆过滤器详解
目录
-
- 一、前言
- 二、RedisBloom 安装与使用
- 三、RedisBloom 常用命令汇总
- 四、通过 Jedis 使用 RedisBloom
- 五、Redisson 封装的布隆过滤器
- 六、使用哪种方式的过滤器比较好?
一、前言
布隆过滤器(Bloom Filter)是 Redis 4.0 版本提供的新功能,它被作为插件加载到 Redis 服务器中,给 Redis 提供强大的去重功能。
相比于 Set 集合的去重功能而言,布隆过滤器在空间上能节省 90% 以上,但是它的不足之处是去重率大约在 99% 左右,也就是说有 1% 左右的误判率,这种误差是由布隆过滤器的自身结构决定的。俗话说“鱼与熊掌不可兼得”,如果想要节省空间,就需要牺牲 1% 的误判率,而且这种误判率,在处理海量数据时,几乎可以忽略。
二、RedisBloom 安装与使用
(1)第一步:安装Redis
关于Linux当中redis的安装:https://blog.csdn.net/weixin_43888891/article/details/125830622
(2)第二步:安装RedisBloom
在 Redis 4.0 版本之后,布隆过滤器才作为插件被正式使用。布隆过滤器需要单独安装,可以去GitHub,找到对应的版本下载,链接:https://github.com/RedisBloom/RedisBloom/releases,下载后再通过xftp上传到Linux系统里,当然也可以直接通过wget来下载。
这里注意我下载的2.2.18版本,最新版本2.6我没有用,原因是make编译的时候会报异常。
# 下载
wget https://codeload.github.com/RedisBloom/RedisBloom/tar.gz/refs/tags/v2.2.18
# 解压
tar -zxvf v2.2.18
# 进入到解压目录
cd RedisBloom-2.2.18/
# 编译
make
编译成功,可以看到redisbloom.so文件

(3)第三步:Redis集成RedisBloom插件
在redis.conf配置文件中加入如RedisBloom的redisbloom.so文件的地址
# vim查看redis.conf
vim /opt/redis-stable/redis.conf
# 在文件后面加上如下配置
loadmodule /opt/RedisBloom-2.2.18/redisbloom.so
(4)第四步: 重启Redis进行测试
# 关闭redis
ps -ef | grep redis | awk -F" " '{print $2;}' | xargs kill -9
# 启动redis
/opt/redis-stable/src/redis-server redis.conf
# 连接客户端
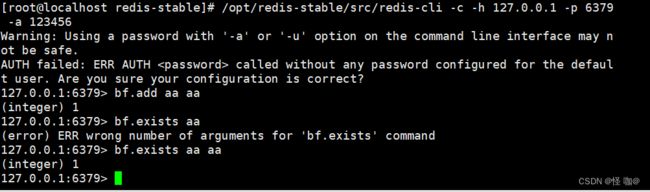
/opt/redis-stable/src/redis-cli -c -h 127.0.0.1 -p 6379 -a 123456
三、RedisBloom 常用命令汇总

127.0.0.1:6379> bf.add spider:url www.baidu.net
(integer) 1
127.0.0.1:6379> bf.exists spider:url www.baidu.net
(integer) 1
127.0.0.1:6379> bf.madd spider:url www.taobao.com www.123qq.com
1) (integer) 1
2) (integer) 1
127.0.0.1:6379> bf.mexists spider:url www.jd.com www.taobao.com
1) (integer) 0
2) (integer) 1
注意使用AnotherRedisDesktopManager客户端是没办法查看该数据类型的值的。
四、通过 Jedis 使用 RedisBloom
Java 客户端 Jedis没有提供指令扩展机制,所以你无法直接使用 Jedis 来访问Redis Module 提供的 bf.xxx 指令。RedisLabs 提供了一个单独的包 JReBloom,但是它是基于 Jedis的。
我们使用的话只需要引入JReBloom就可以,JReBloom内部引用了Jedis 。假如系统引用了jedis,又要引用jrebloom,这时候需要注意版本冲突的问题。
<dependency>
<groupId>redis.clientsgroupId>
<artifactId>jedisartifactId>
<version>3.9.0version>
dependency>
<dependency>
<groupId>com.redislabsgroupId>
<artifactId>jrebloomartifactId>
<version>2.2.2version>
dependency>
代码示例:
import io.rebloom.client.Client;
import redis.clients.jedis.Jedis;
public class JrebloomDemo {
public static void main(String[] args) {
//连接本地的 Redis 服务
Jedis jedis = new Jedis("192.168.115.239", 6379);
//jedis.auth("123456");
//创建client也支持连接池的:public Client(Pool pool)
Client client = new Client(jedis);
// 测试数据
int capacity = 10000;
// 容错率,只能设置0 < error rate range < 1 不然直接会异常!
double errorRate = 0.01;
// 测试的key值
String key = "ceshi";
// 创建过滤器:可以创建指定位数和容错率的布隆过滤器,如果过滤器已经存在创建的话就会异常
if (!jedis.exists(key)) {
client.createFilter(key, capacity, errorRate);
}
for (int i = 0; i < capacity; i++) {
client.bfInsert(key, String.valueOf(i));
}
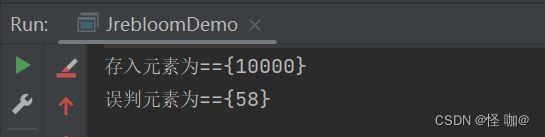
System.out.println("存入元素为=={" + capacity + "}");
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (int i = capacity; i < capacity * 2; i++) {
if (client.exists(key, String.valueOf(i))) {
count++;
}
}
System.out.println("误判元素为=={" + count + "}");
// 删除过滤器
client.delete(key);
}
}
运行示例:
现在存在个问题,假如我们redis并没有安装RedisBloom,那他可以运行吗?
答案是不可以的,他根本无法识别bf.xxx 指令
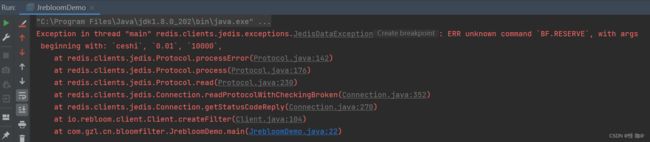
错误率越低,所需要的空间也会越大,因此就需要我们尽可能精确的估算元素数量,避免空间的浪费。我们也要根据具体的业务来确定错误率的许可范围,对于不需要太精确的业务场景,错误率稍微设置大一点也可以。
查看刚刚创建的过滤器:这个数据结构不支持get查询。

五、Redisson 封装的布隆过滤器
Redisson布隆过滤器官网介绍
引入依赖:
<dependency>
<groupId>org.redissongroupId>
<artifactId>redissonartifactId>
<version>3.22.1version>
dependency>
代码示例:
import org.redisson.Redisson;
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
public class RedissonBloomFilter {
public static void main(String[] args) {
Config config = new Config();
config.useSingleServer()
.setAddress("redis://127.0.0.1:6379")
//.setPassword("123456")
.setDatabase(0);
//获取客户端
RedissonClient redissonClient = Redisson.create(config);
// 测试数据
int capacity = 10000;
// 容错率,只能设置0 < error rate range < 1 不然直接会异常!
double errorRate = 0.01;
// 测试的key值
String key = "ceshi";
RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(key);
// 初始化布隆过滤器,预计统计元素数量为10000,期望误差率为0.01
bloomFilter.tryInit(capacity, errorRate);
for (long i = 0; i < capacity; i++) {
bloomFilter.add(String.valueOf(i));
}
System.out.println("存入元素为=={" + capacity + "}");
// 统计误判次数
int count = 0;
// 我在数据范围之外的数据,测试相同量的数据,判断错误率是不是符合我们当时设定的错误率
for (int i = capacity; i < capacity * 2; i++) {
if (bloomFilter.contains(String.valueOf(i))) {
count++;
}
}
System.out.println("误判元素为=={" + count + "}");
// 删除过滤器
// bloomFilter.delete();
}
}
运行结果:
通过运行结果不难发现,同样是10000数据,和0.01容错,Redisson 实现的布隆过滤器明显没有基于RedisBloom的过滤器容错率好。

查看刚刚创建的过滤器:

六、使用哪种方式的过滤器比较好?
RedisBloom和Redisson实现的过滤器区别:
- 数据结构: RedisBloom相当于为了实现过滤器而新增了一个数据结构,而Redisson是基于redis原有的bitmap位图数据结构来通过硬编码实现的过滤器。
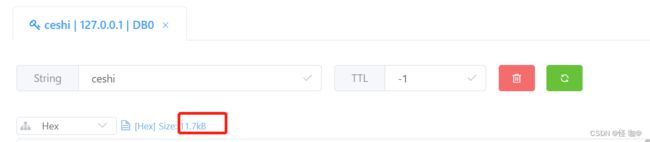
- 存储: 存储两者其实并没有差距,都没有存储原数据,我使用Redisson存储了10000条数据然后设置的0.01容错占用了11.7kb也符合布隆过滤器的占用。
- 容错: 同样是10000条数据0.01容错,RedisBloom误判元素是58,Redisson实现的是227。
- 耦合度: 使用RedisBloom就需要安装RedisBloom,如果不安装RedisBloom程序直接就不能使用了,而使用Redisson他只依赖于redis。
- 分片: RedisBloom只是redis一种数据结构,本身redis集群就是支持分片的,所以RedisBloom肯定也没问题,Redisson的布隆过滤器也支持分片,但是需要付费。
- 性能: 使用 redis 的位图来实现的布隆过滤器性能上要差不少。比如一次 exists 查询会涉及到多次 getbit 操作,网络开销相比而言会高出不少。
综上比较,个人建议使用RedisBloom比较好一点!