Amazon Bedrock 知识库现可提供完全托管的 RAG 体验
Amazon Bedrock 知识库预览版已于9月问世。从今天开始,Amazon Bedrock 知识库正式全面发布。正式推出。
借助知识库,可安全地将 Amazon Bedrock 中的基础模型 (FM) 连接到贵公司的数据,供检索增强生成 (RAG) 使用。模型生成的响应更具相关性、更加特定于上下文以及更准确;访问其他数据在其中发挥重要作用,无需不停地重新训练基础模型。对于从知识库检索的所有信息,它们均附有来源归属,从而提高透明度,并最大限度地减少幻觉。若对其工作方式感兴趣,请查看之前的帖子,其中包含关于 RAG 的入门介绍短片。
亚马逊云科技开发者社区为开发者们提供全球的开发技术资源。这里有技术文档、开发案例、技术专栏、培训视频、活动与竞赛等。帮助中国开发者对接世界最前沿技术,观点,和项目,并将中国优秀开发者或技术推荐给全球云社区。如果你还没有关注/收藏,看到这里请一定不要匆匆划过,点这里让它成为你的技术宝库!
在今天的产品发布过程中,知识库具有完全托管的 RAG 体验,以及在 Amazon Bedrock 中开始使用 RAG 的简便方法。目前,知识库管理初始向量存储设置,处理嵌入和查询,并提供创建 RAG 应用程序所需的来源归属和短期内存。如果需要,也可自定义 RAG 工作流,从而满足特定的用例要求,或集成 RAG 与其他生成式人工智能 (AI) 工具和应用程序。
完全托管的 RAG 体验
适用于 Amazon Bedrock 的知识库会管理端到端 RAG 工作流。指定数据位置,选择嵌入模型,将数据转换为向量嵌入,然后通过 Amazon Bedrock 在账户中创建向量存储,以便存储向量数据。在选择此选项(仅控制台支持)时,Amazon Bedrock 将在账户的 Amazon OpenSearch Serverless 中创建向量索引,不必自行管理任何内容。

向量嵌入包含文档内部文本数据的数字表征形式。每个嵌入旨在获取数据的语义或上下文含义。Amazon Bedrock 负责在向量存储中创建、存储、管理和更新嵌入,同时确保始终同步数据和向量存储。
目前,Amazon Bedrock 也支持 RAG 的 2 个新 API,这用于处理嵌入和查询,同时提供创建 RAG 应用程序所需的来源归属和短期内存。
通过全新的 RetrieveAndGenerate API,直接从知识库检索相关信息;在 API 调用中指定基础模型,Amazon Bedrock 便可根据结果生成响应。以下内容将围绕工作方式。
使用 RetrieveAndGenerate API
要试用,导航到 Amazon Bedrock 控制台,创建并选择知识库,然后选择“测试知识库”。在本演示中,创建知识库,从而访问亚马逊云科技生成式 AI 的 PDF 文件。选择“选择模型”,指定基础模型。

然后,提问,“何为 Amazon Bedrock?
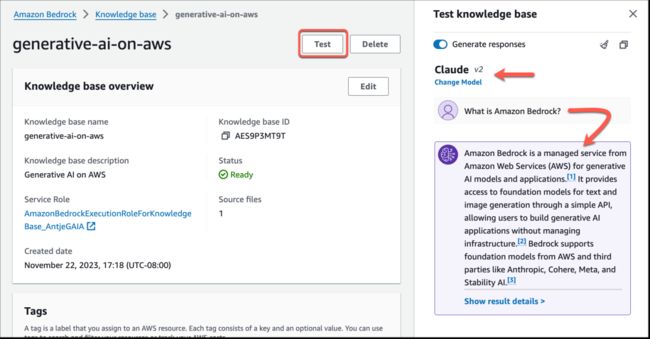
Amazon Bedrock 会在在后台将查询转换为嵌入,查询知识库,然后利用搜索结果作为上下文信息扩充基础模型提示,并返回基础模型生成对问题的回复。对于多轮对话,知识库管理对话的短期内存,从而提供更多上下文结果。
以下快速演示介绍了如何同时使用 API 与适用于 Python 的亚马逊云科技开发工具包 (Boto3)。
def retrieveAndGenerate(input, kbId):
return bedrock_agent_runtime.retrieve_and_generate(
input={
'text': input
},
retrieveAndGenerateConfiguration={
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': kbId,
'modelArn': 'arn:aws:bedrock:us-east-1::foundation-model/anthropic.claude-instant-v1'
}
}
)
response = retrieveAndGenerate("What is Amazon Bedrock?", "AES9P3MT9T")["output"]["text"]RetrieveAndGenerate API 输出包含生成的响应、来源归属和检索的文本块。在演示中,API 响应如下所示(为简洁起见,已编辑部分输出实施):
{ ...
'output': {'text': 'Amazon Bedrock is a managed service from AWS that ...'},
'citations':
[{'generatedResponsePart':
{'textResponsePart':
{'text': 'Amazon Bedrock is ...', 'span': {'start': 0, 'end': 241}}
},
'retrievedReferences':
[{'content':
{'text': 'All AWS-managed service API activity...'},
'location': {'type': 'S3', 's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}}},
{'content':
{'text': 'Changing a portion of the image using ...'},
'location': {'type': 'S3', 's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}}},...]
...}]
}生成的响应如下所示:
Amazon Bedrock 是一项托管服务,这将通过简单 API 为生成式 AI 提供 Serverless 体验。该款产品支持访问亚马逊云科技和第三方的基础模型,从而执行文本生成、图像生成和构建对话代理等任务。对于通过 Amazon Bedrock 处理的数据,它们需要保持隐私和加密。
自定义 RAG 工作流
若要进一步处理检索的文本块,查看检索的相关性分数,或自行开发文本生成的业务流程,请使用新检索 API。使用该 API,用户查询会转换为嵌入,搜索知识库并返回相关结果,便于您更妥善地控制根据语义搜索结果构建自定义工作流。
使用检索 API
在 Amazon Bedrock 控制台中,切换开关,禁用“生成响应”。

然后,再次提问“何为 Amazon Bedrock?”这次,输出展示了检索结果,其中也有文本块来源的源文档链接。

下方将介绍如何同时使用检索 API 与 boto3。
import boto3
bedrock_agent_runtime = boto3.client(
service_name = "bedrock-agent-runtime"
)
def retrieve(query, kbId, numberOfResults=5):
return bedrock_agent_runtime.retrieve(
retrievalQuery= {
'text': query
},
knowledgeBaseId=kbId,
retrievalConfiguration= {
'vectorSearchConfiguration': {
'numberOfResults': numberOfResults
}
}
)
response = retrieve("What is Amazon Bedrock?", "AES9P3MT9T")["retrievalResults"]检索 API 的输出包含检索的文本块、源数据的位置类型和 URI,以及检索分数。分数将有助于确定与查询匹配度更高的区块。
在演示中,API 响应如下所示(为简洁起见,已编辑部分输出):
[{'content': {'text': 'Changing a portion of the image using ...'},
'location': {'type': 'S3',
's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}},
'score': 0.7329834},
{'content': {'text': 'back to the user in natural language.For ...'},
'location': {'type': 'S3',
's3Location': {'uri': 's3://data-generative-ai-on-aws/gaia.pdf'}},
'score': 0.7331088},
...]要进一步自定义 RAG 工作流,请定义自定义区块策略,并选择自定义向量存储。
自定义区块策略 — 为高效从数据中检索,一种常见做法是先将文档拆分为可管理的区块。模型的理解和信息处理能力进一步增强,从而改进相关检索和生成语义连贯的响应。适用于 Amazon Bedrock 的知识库可管理文档的区块。
在为知识库配置数据源时,现可定义区块策略。默认区块会将数据拆分为区块,其中最多 200 个令牌,并专为问答任务优化。在不确定数据的最佳区块大小时,使用默认区块。
此外,也可选择指定自定义块大小,其中内容与固定大小的区块重叠。若知晓数据的最佳区块大小和重叠范围(基于文件属性、准确性测试等),应当使用固定大小的区块。在建议的 0-20% 范围内,区块间的重叠区域有助于提高准确性。重叠范围越高,相关性分数降低。
若选择根据每个文档创建一个嵌入,知识库会将每个文件保存为单个区块。如果不希望 Amazon Bedrock 对数据进行区块划分,例如若要使用特定于用例的算法离线区块数据,使用此选项。常见用例包含代码文档。
自定义向量存储 — 也可选择自定义向量存储。可用向量数据库选项包含适用于 Amazon OpenSearch Serverless 的的向量引擎、Pinecone 和 Redis Enterprise Cloud。要使用自定义向量存储,必须从支持的选项列表创建全新空向量数据库,并附上向量数据库索引名称,以及索引字段与元数据字段映射。该向量数据库应专属于 Amazon Bedrock。

集成 RAG 与其他生成式 AI 工具和应用程序
AI 助手可执行多步骤任务并访问公司数据源,从而生成相关性和上下文感知更高的响应;若要构建此类助手,可集成知识库与 适用于 Amazon Bedrock 的代理 。也可使用 LangChain 的知识库检索插件,集成 RAG 工作流与生成式 AI 应用程序。
可用性
亚马逊云科技区域美国东部(弗吉尼亚北部)和美国西部(俄勒冈州)现已支持适用于 Amazon Bedrock 的知识库。
了解更多
-
适用于Amazon Bedrock 的知识库
-
知识库用户指南
-
控制台中的 Amazon Bedrock
文章来源:Amazon Bedrock 知识库现可提供完全托管的 RAG 体验