FLUENT UDF并行化(1)
来源:ANSYS FLUENT UDF帮助文档,翻译自用,如有错误,欢迎指出!
本章概述了并行ANSYS Fluent的用户定义函数(UDF)及其用法。有关并行UDF功能的详细信息,请参见以下部分,本文介绍前两部分 。
7.1.Overview of Parallel ANSYS Fluent
7.2.Cells and Faces in a Partitioned Mesh
7.3.Parallelizing Your Serial UDF
7.4.Reading and Writing Files in Parallel
7.5.Enabling Fluent UDFs to Execute on General Purpose Graphics Processing Units (GPGPUs)
7.1. Overview of Parallel ANSYS Fluent
ANSYS Fluent的并行求解器通过同时使用可能在同一台机器上或网络中的不同机器上执行的多个进程来计算大型问题的解。它通过将计算域拆分为多个分区(图7.1:并行ANSYS Fluent中的分区网格),并将每个数据分区分配给不同的计算进程,称为计算节点(compute node)(图7-2:分布在两个计算节点之间的分区网格)。
每个计算节点在其自己的数据集上与每个其他计算节点同时执行相同的程序。主机进程(host process)或简单的主机(host)不包含网格单元、面或节点(使用DPM共享内存模型时除外)。其主要目的是解释来自Cortex(负责用户界面和图形相关功能的ANSYS Fluent进程)的命令,然后将这些命令(和数据)传递给计算节点(compute node-0),该节点将其分发给其他计算节点。
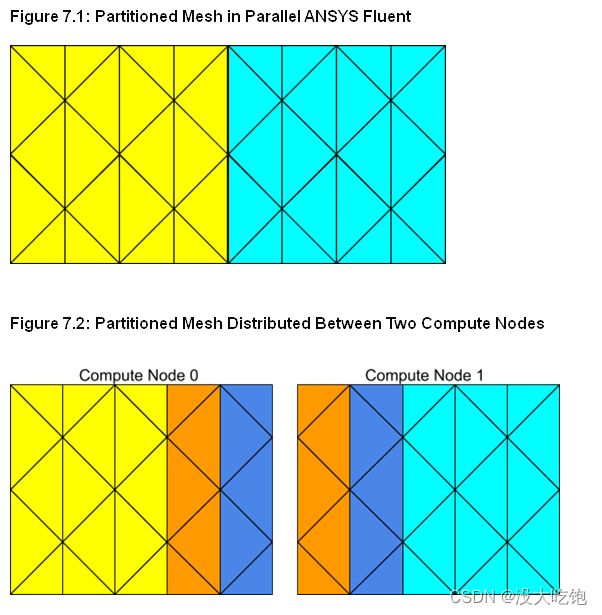
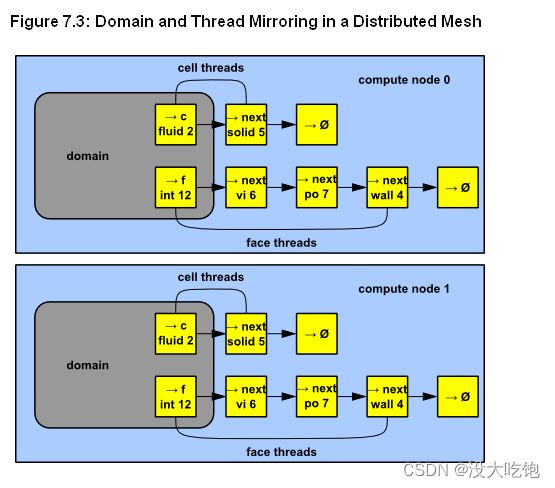
计算节点在其网格部分上存储和执行计算,而沿分区边界的单层重叠单元提供跨分区边界的通信和连续性(图7.2:分布在两个计算节点之间的分区网格)。即使单元和面是分区的,网格中的所有域和线程(domains and threads)都在每个计算节点上镜像(图7.3:分布式网格中的域和线程镜像)。线程存储为链表(The threads are stored as linked lists as in the serial solver.),与串行解算器一样。计算节点可以在大规模并行计算机、多CPU工作站或使用相同或不同操作系统的工作站网络上实现。
-
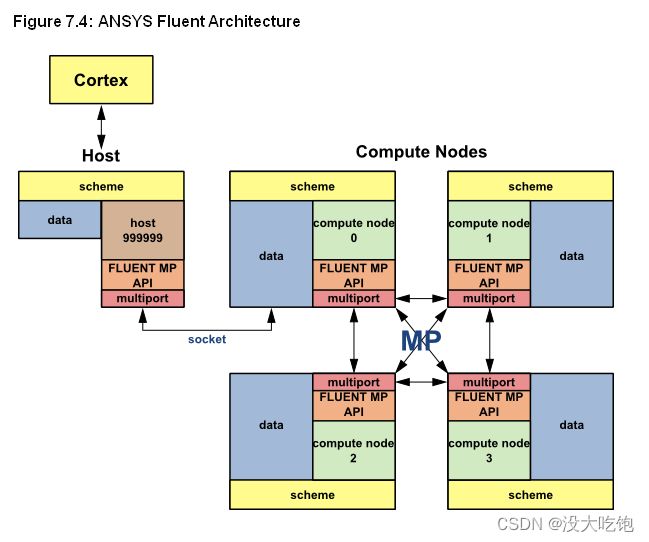
7.1.1 Command Transfer and Communication
ANSYS Fluent会话中涉及的进程由Cortex、主机进程(host)和一组n个计算节点(node)进程(称为node)定义,计算节点标记为 0 到 n-1 (图7.4:ANSYS Fluent架构)。主机从Cortex接收命令,并将命令传递给compute node-0。compute node-0 反过来将命令发送给所有其他计算节点。所有计算节点(0除外)都从compute node-0接收命令。在计算节点将消息传递给主机(通过compute node-0)之前,它们彼此同步。
每个计算节点“虚拟地”连接到每个其他计算节点,并依靠其“通信器”("communicator")执行发送和接收阵列、同步、执行全局缩减(如所有单元的求和)以及建立机器连接等功能。ANSYS Fluent communicator是一个消息传递库。例如,它可以是消息传递接口(MPI)标准的供应商实现,如图7.4:ANSYS Fluent Architecture所示。
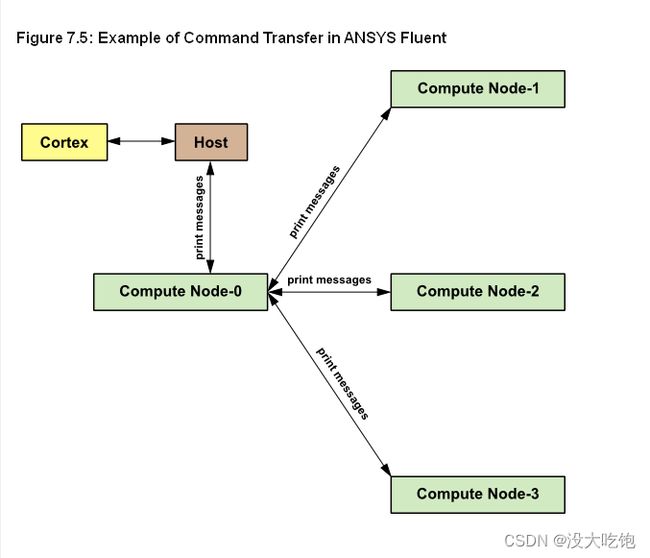
所有ANSYS Fluent进程(包括主机进程)都由唯一的整数ID标识。主机进程被分配ID host(=999999)。主机从compute node-0收集消息,并对所有数据执行操作(如打印、显示消息和写入文件)(见图7.5:ANSYS Fluent中的命令传输示例)。
7.2 Cells and Faces in a Partitioned Mesh
引入一些术语来区分分区网格中不同类型的单元和面。请注意,该术语仅适用于ANSYS Fluent中的并行编码。
7.2.1 Cell Types in a Partitioned Mesh
7.2.2 Faces at Partition Boundaries
7.2.3 PRINCIPAL_FACE_P
7.2.4 Exterior Thread Storage
7.2.5 Extended Neighborhood
-
7.2.1 Cell Types in a Partitioned Mesh
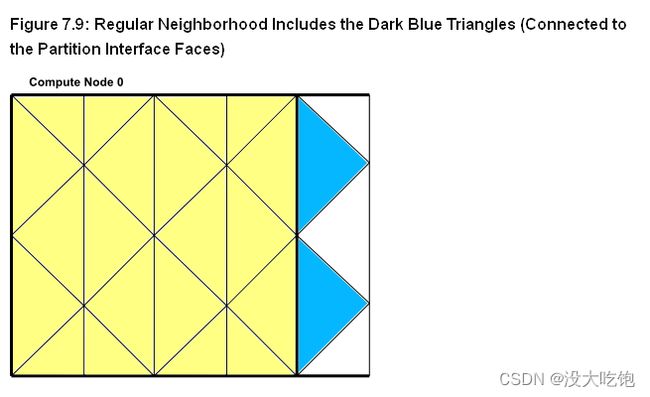
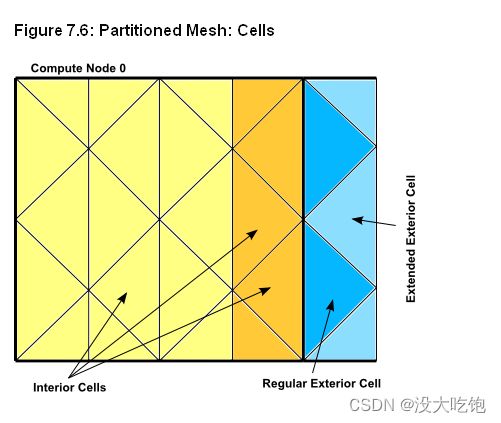
分区网格中大致有两种类型的单元:内部单元和外部单元(interior cells and exterior cells)(图7.6)。内部单元(interior cells)完全包含在网格分区中。分区的外部单元(exterior cells)不包含在该网格分区内,而是连接到其与一个或多个相邻分区的接口上的节点。如果外部单元与内部单元共享一个面,则将其称为常规外部单元(regular exterior cell)。如果外部单元仅与内部单元共享一条边或一个节点,则将其称为扩展外部单元(extended exterior cell)。
一个计算节点(compute node)上的外部单元对应于相邻计算节点中的相同内部单元。(图7.2)。当您希望在并行网格中的单元上循环时,分区边界上的重叠单元变得非常重要。有单独的宏用于在内部单元格、外部单元格和所有单元格上循环。有关详细信息,See Looping Macros for details.。
7.2.2 Faces at Partition Boundaruies
分区网格中的面有三种分类:内部、边界区域和外部( interior, boundary zone, and external 图7.7)。内部面有两个相邻单元。位于分区边界上的内部面称为“分区边界面”(partition boundary faces)。边界分区面(Boundary zone faces)位于物理网格边界上,并且只有一个相邻单元相邻。外部面(Boundary zone faces)是属于外部单元的非分区边界面。外部面通常不用于并行UDF,因此,这里将不讨论。

注意,每个分区边界面在相邻计算节点上重复(图7.2)。这是必要的,以便每个计算节点可以计算其自己的面值。然而,当UDF涉及包含分区边界面的线程中的求和数据的操作时,这种重复可能导致面数据被计数两次。例如,如果UDF对网格中所有面上的数据求和,则当每个节点在其面上循环时,重复的分区边界面可以计数两次。
因此,ANSYS Fluent将每个相邻集合中的一个计算节点指定为分区边界面的“主要”(principal)计算节点。换句话说,虽然每个面可以出现在一个或两个分区上,但它只能“正式”属于其中一个分区。如果面f是当前计算节点上的主面,则布尔宏PRINCIPAL_FACE_P(f,t)返回TRUE。
7.2.3 PRINCIPAL_FACE_P
可以使用PRINCIPAL_FACE_P来测试给定的面是否是主面,然后将其包含在面循环求和中。在下面的示例源代码中,只有当面是主面时,才将面面积添加到总面积。PRINCIPAL_FACE_P只能在编译的UDF中使用。
Example:
begin_f_loop(f,t)
if PRINCIPAL_FACE_P(f,t) /* tests if the face is the principal face
FOR COMPILED UDFs ONLY */
{
F_AREA(area,f,t); /* computes area of each face */
total_area +=NV_MAG(area); /* computes total face area by
accumulating magnitude of each
face’s area */
}
end_f_loop(f,t) 7.2.4 Exterior Thread Storage
每个线程将与其单元格或面关联的数据存储在一组数组中。(Each thread stores the data associated with its cells or faces in a set of arrays.)例如,压力存储在阵列(array)中,单元c的压力通过访问该阵列的单元c获得。外部单元和面数据的存储发生在每个线程数据数组的末尾。对于单元线程,常规外部单元的数据出现在扩展外部单元之前,如图7.8。

7.2.5 Extende Neighborhood
ANSYS Fluent基于interface面和corner节点创建完整的扩展外部单元邻域。这使得某些操作更容易(例如网格操作和求解器梯度重建),并增强了此类操作的性能。解算器仅使用常规邻域(regular neighborhood),因此解算器相关数据仅填充规则外部单元,而不填充扩展外部单元( extended exterior cells)。