LangChain 最近发布的一个重要功能:LangGraph
LangGraph 是 LangChain 最近发布的一个重要功能,LangChain 进入多代理框架领域。通过建立在LangChain 之上,LangGraph 使开发人员可以轻松创建强大的代理运行时。

LangChain 使用其表达语言(LCEL)为开发人员构建定制链提供技术支持。从数据结构的角度来看,这样的链是一个有向无环图(DAG)。然而,在实践中,用户可能希望使用代理构建循环图。换句话说,代理可以根据模型推理在循环中被调用,直到任务完成。AutoGen就是支持这种机制的框架。
LangGraph专门设计以满足这类用户的需求。换句话说,开发人员可以使用它来构建类似于AutoGen的多代理LLM应用程序。
LangGraph 提供了一种称为状态机的技术,它可以驱动循环代理调用。因此,LangGraph具有三个关键元素:
- StateGraph(状态图)
- Node(节点)
- Edge(边缘)
技术交流&资料
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
成立了大模型技术交流群,本文完整代码、相关资料、技术交流&答疑,均可加我们的交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2060,备注:来自CSDN + 技术交流
通俗易懂讲解大模型系列
-
做大模型也有1年多了,聊聊这段时间的感悟!
-
用通俗易懂的方式讲解:大模型算法工程师最全面试题汇总
-
用通俗易懂的方式讲解:不要再苦苦寻觅了!AI 大模型面试指南(含答案)的最全总结来了!
-
用通俗易懂的方式讲解:我的大模型岗位面试总结:共24家,9个offer
-
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
-
用通俗易懂的方式讲解:一文讲清大模型 RAG 技术全流程
-
用通俗易懂的方式讲解:如何提升大模型 Agent 的能力?
-
用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
-
用通俗易懂的方式讲解:基于扩散模型(Diffusion),文生图 AnyText 的效果太棒了
-
用通俗易懂的方式讲解:在 CPU 服务器上部署 ChatGLM3-6B 模型
-
用通俗易懂的方式讲解:使用 LangChain 和大模型生成海报文案
-
用通俗易懂的方式讲解:ChatGLM3-6B 部署指南
-
用通俗易懂的方式讲解:使用 LangChain 封装自定义的 LLM,太棒了
-
用通俗易懂的方式讲解:基于 Langchain 和 ChatChat 部署本地知识库问答系统
-
用通俗易懂的方式讲解:在 Ubuntu 22 上安装 CUDA、Nvidia 显卡驱动、PyTorch等大模型基础环境
-
用通俗易懂的方式讲解:Llama2 部署讲解及试用方式
-
用通俗易懂的方式讲解:基于 LangChain 和 ChatGLM2 打造自有知识库问答系统
-
用通俗易懂的方式讲解:一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
-
用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
-
用通俗易懂的方式讲解:LlamaIndex 官方发布高清大图,纵览高级 RAG技术
-
用通俗易懂的方式讲解:为什么大模型 Advanced RAG 方法对于AI的未来至关重要?
-
用通俗易懂的方式讲解:使用 LlamaIndex 和 Eleasticsearch 进行大模型 RAG 检索增强生成
-
用通俗易懂的方式讲解:基于 Langchain 框架,利用 MongoDB 矢量搜索实现大模型 RAG 高级检索方法
-
用通俗易懂的方式讲解:使用Llama-2、PgVector和LlamaIndex,构建大模型 RAG 全流程
StateGraph
StateGraph 是LangChain的一个类,表示图的数据结构并反映其状态。图的状态由将很快介绍的节点更新。
class State(TypedDict):
input: str
all_actions: Annotated[List[str], operator.add]
graph = StateGraph(State)
Node
图中最关键的元素之一是节点。每个LangGraph节点都有一个名称和其值,它可以是LCEL中的函数或可运行项。每个节点接收一个字典类型的数据,其结构与状态定义相同。节点返回具有相同结构的更新状态。
LangGraph定义了一个称为END的特殊节点,用于识别状态机的结束状态。
from langgraph.graph import END
graph.add_node("model", model)
graph.add_node("tools", tool_executor)
Edge
在图中,节点之间的关系通过边界定义。LangGraph定义了两种类型的边:普通边和条件边。
普通边定义了上游节点应始终调用的其他节点。
graph.add_edge("tools", "model")
条件边,使用函数(路由器)来确定下游节点。
graph.add_conditional_edge(
"model",
should_continue,
{
"end": END,
"continue": "tools"
}
)
如上所示,条件边需要三个元素:
- 上游节点:边的起点,表示转换的起始点。
- 路由函数:此函数根据其返回值有条件地确定应进行转换的下游节点。
- 状态映射:根据路由函数的返回值,此映射指定下一个目的地。它将路由函数的可能返回值与相应的下游节点相关联。
运行图
在运行图之前,有两个必要的步骤需要完成:
- 设置入口点,以指定图中哪个节点作为入口点
graph.set_entry_point("model")
- 编译
app = graph.compile()
现在,我们可以运行LangGraph应用程序如下:
app.stream(
{
"messages": [
HumanMessage(content="Write a tweet about LangChain news")
]
}
)
用例
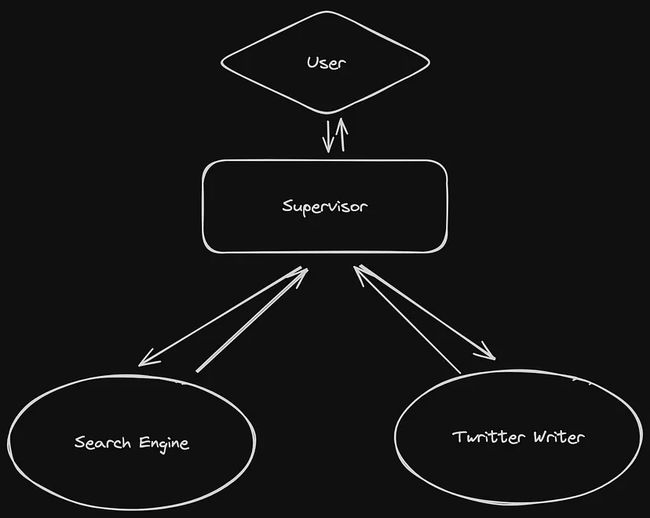
这是一个示例。图包含三个节点:主管、搜索引擎和 Twitter 作者。根据需要,主管可能多次调用搜索引擎以检索所需数据,然后将数据转发给Twitter作者以撰写推文。因此,在主管和搜索引擎之间存在循环。
LangChain可以帮助开发人员轻松构建基于工具的代理,然后基于这些代理创建节点。
定义图状态
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
next: str
声明工具函数
@tool("web_search")
def web_search(query: str) -> str:
"""通过查询使用Google SERP API进行搜索"""
search = SerpAPIWrapper()
return search.run(query)
@tool("twitter_writer")
def write_tweet(content: str) -> str:
"""根据内容编写推文。"""
chat = ChatOpenAI()
messages = [
SystemMessage(
content="您是Twitter帐户操作员。您负责根据给定的内容撰写推文。您应遵循Twitter政策,并确保每条推文不超过140个字符。"
),
HumanMessage(
content=content
),
]
response = chat(messages)
return response.content
辅助函数 —— 使用工具创建代理
def create_agent(llm: ChatOpenAI, tools: list, system_prompt: str):
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
system_prompt,
),
MessagesPlaceholder(variable_name="messages"),
MessagesPlaceholder(variable_name="agent_scratchpad"),
]
)
agent = create_openai_tools_agent(llm, tools, prompt)
executor = AgentExecutor(agent=agent, tools=tools)
return executor
辅助函数 —— 使用代理创建节点
def agent_node(state, agent, name):
result = agent.invoke(state)
return {"messages": [HumanMessage(content=result["output"], name=name)]}
创建主管节点
members = ["Search_Engine", "Twitter_Writer"]
system_prompt = (
"您是一名主管,负责管理以下工作者之间的对话:{members}。给定以下用户请求,使用下一步操作进行回复。每个工作者将执行一个任务,并回复其结果和状态。完成后,使用FINISH进行回复。"
)
options = ["FINISH"] + members
function_def = {
"name": "route",
"description": "选择下一个角色。",
"parameters": {
"title": "routeSchema",
"type": "object",
"properties": {
"next": {
"title": "Next",
"anyOf": [
{"enum": options},
],
}
},
"required": ["next"],
},
}
prompt = ChatPromptTemplate.from_messages(
[
("system", system_prompt),
MessagesPlaceholder(variable_name="messages"),
(
"system",
"根据以上对话,下一个应该采取行动的人是谁?还是我们应该结束?选择一个:{options}",
),
]
).partial(options=str(options), members=", ".join(members))
supervisor_chain = (
prompt
| llm.bind_functions(functions=[function_def], function_call="route")
| JsonOutputFunctionsParser()
)
创建节点和边缘
search_engine_agent = create_agent(llm, [web_search], "您是一个网络搜索引擎。")
search_engine_node = functools.partial(agent_node, agent=search_engine_agent, name="Search_Engine")
twitter_operator_agent = create_agent(llm, [write_tweet], "您负责根据给定的内容撰写推文。")
twitter_operator_node = functools.partial(agent_node, agent=twitter_operator_agent, name="Twitter_Writer")
workflow = StateGraph(AgentState)
workflow.add_node("Search_Engine", search_engine_node)
workflow.add_node("Twitter_Writer", twitter_operator_node)
workflow.add_node("supervisor", supervisor_chain)
for member in members:
workflow.add_edge(member, "supervisor")
conditional_map = {k: k for k in members}
conditional_map["FINISH"] = END
workflow.add_conditional_edges("supervisor", lambda x: x["next"], conditional_map)
编译
workflow.set_entry_point("supervisor")
graph = workflow.compile()
现在我们可以使用此图执行任务。让我们要求它搜索LangChain新闻并撰写一条推文:
for s in graph.stream(
{
"messages": [
HumanMessage(content="Write a tweet about LangChain news")
]
}
):
if "__end__" not in s:
print(s)
print("----")
参考文献
- https://ai.gopubby.com/langgraph-absolute-beginners-guide-cd4a05336312
- https://github.com/sugarforever/LangChain-Tutorials/blob/main/langgraph_nodes_edges.ipynb