Python学习笔记之NumPy模块——超详细(安装、数组创建、正态分布、索引和切片、数组的复制、维度修改、拼接、分割...)
文章目录
- NumPy模块
-
-
- 1.1 什么是NumPy?
- 1.2 NumPy的安装
-
-
- 1.2.1 按住 Win + R 键,输入cmd,然后回车
- 1.2.2 输入命令
-
- 1.3 数组的创建
-
-
- 1.3.1 array创建
- 1.3.2 arange创建
- 1.3.3 随机数创建
- 1.3.4 随机整数创建
- 1.3.5 其他方式创建
-
- 1. zeros创建指定大小的数组
- 2. ones创建指定形状的数组
- 3. empty创建指定形状、类型且未初始化的数组
- 4. linspace创建一维数组
- 5. logspace创建一维数组
-
- 1.4 NunPy创建正态分布
-
-
- 1.4.1 什么是正态分布?
- 1.4.2 正态分布的创建
-
- 1.5 ndarray对象
- 1.5 数组的切片和索引
- 1.6 NumPy中的浅拷贝与深拷贝
-
-
- 1.6.1 浅拷贝
- 1.6.2 深拷贝
-
- 1.7 修改数组的维度
-
-
- 1. 使用 reshape 将一维数组变成多维维数组
- 2. 使用 ravel 函数将多维数组变成一维的数组
- 3. 使用 flatten函数将多维数组变成一维的数组
-
- 1.8 数组的拼接
-
-
- 1.8.1 水平数组组合
- 1.8.2 垂直数组组合
-
- 1.9 数组的分隔
-
-
- 1. 水平分隔
- 2. 垂直分隔数组
-
-
NumPy模块
1.1 什么是NumPy?
NumPy(Numerical Python) 是科学计算基础库,它提供了大量科学计算相关功能。比如数据统计,随机数生成等。其提供最核心类型为多维数组类型(ndarray),支持大量的维度数组与矩阵运算,NumPy支持向量处理ndarray对象,提高程序运行速度。
1.2 NumPy的安装
安装NumPy最简单的方法就是使用pip工具,具体安装步骤如下:
1.2.1 按住 Win + R 键,输入cmd,然后回车

1.2.2 输入命令
- pip install numpy
注意:这种安装方式速度可能会比较慢,所以我们这里建议换源安装
1. 使用清华源进行pip安装
命令: pip install 包名 -i https://pypi.tuna.tsinghua.edu.cn/simple
示例: pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple


像上图出现Successfully 就说明我们的NumPy安装成功啦
【示例1】arange函数测试环境安装
# 导入numpy模块,
import numpy as np # as是取别名
a = np.arange(10) # 调用numpy模块中的arange函数,创建一个数组
print(a)
print(type(a)) # 查看a的类型
下面是运行结果:
[0 1 2 3 4 5 6 7 8 9]
<class 'numpy.ndarray'> # ndarray类型
【示例2】对列表中的元素开平方
# 导入numpy模块
import numpy as np
# 创建一个数组
b = [3, 6, 9]
# 对数组中的每一个数进行开平方
print(np.sqrt(b))
下面是运行结果:
[1.73205081 2.44948974 3. ]
1.3 数组的创建
1.3.1 array创建
NumPy模块中的array函数可以生成多维数组。例如,如果要生成一个二维数组,需要向array函数传递一个列表类型的参数。每一个列表元素是一堆的ndarray类型数组,作为二维数组的行。另外,通过ndarray类的shape属性可以获得数组每一堆的元素个数(元组形式),也可以通过shape[n]形式获得每一堆的元素个数,其中n是维度,从0开始。
语法格式如下:
numpy.array(object, dtype = None, copy = True, order = None, subok = False, ndmin = 0)
下面是array函数的参数名称及其作用描述:

【示例1】使用array函数创建数组
import numpy as np
a = np.array([1, 2, 3]) # 创建一维数组
b = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]) # 创建二维数组
c = np.array([[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]) # 创建三维数组
print(a)
print(b)
print(c)
print(type(a), type(b), type(c))
运行结果如下:
[1 2 3]
[[1 2 3]
[4 5 6]
[7 8 9]]
[[[1 2 3]
[4 5 6]
[7 8 9]]]
<class 'numpy.ndarray'> <class 'numpy.ndarray'> <class 'numpy.ndarray'>
由上可知:使用array函数创建的数组都是ndarray对象
【示例2】array函数中dtype的使用
a = np.array([4, 5, 6], dtype=float)
b = np.array([4, 5, 6], dtype=complex)
print(a, type(a))
print(b, type(b))
运行结果如下:
[4. 5. 6.] <class 'numpy.ndarray'>
[4.+0.j 5.+0.j 6.+0.j] <class 'numpy.ndarray'>
由上可知:array函数中dtype参数可以设置创建数组内的元素类型
【示例3】array函数中ndmin的使用
a = np.array([4, 5, 6], ndmin=3)
print(a)
[[[4 5 6]]]
由上可知:array函数中ndmin参数可以设置创建数组的最小维度
1.3.2 arange创建
使用arange函数创建数值范围并返回ndarray对象,函数格式如下:
numpy.arange(start, stop, step, dtype)
下面是arange函数的参数名称及其作用描述:

【示例】使用arange函数创建数组
# 与range函数类似,括号内的范围是左闭右开
a = np.arange(11) # 未设置起始值时,默认从0开始
b = np.arange(1, 11) # 设置起始值和终止值,左闭右开
c = np.arange(1, 11, 2) # 设置步长,默认值为1
d = np.arange(1, 11, 2, dtype=float) # 设置数组元素的类型,这里设置为浮点型
print(a)
print(b)
print(c)
print(d)
运行结果如下:
[ 0 1 2 3 4 5 6 7 8 9 10]
[ 1 2 3 4 5 6 7 8 9 10]
[1 3 5 7 9]
[1. 3. 5. 7. 9.]
1.3.3 随机数创建
使用numpy.random.random(size=None),该方法返回[0.0, 1.0)范围的随机数。
格式如下:
numpy.random.random(size=None)
【示例1】使用numpy.random.random(size=None)创建一维数组
# size表示要生成的数组大小,size=5就表示包含 5 个元素的一维数组
a = np.random.random(size=5)
print(a)
运行结果如下:
[0.84174708 0.60109444 0.93239501 0.36488593 0.24012724]
由运行结果可知:一维数组中的每个元素都是[0.0, 1.0)之间的随机数
【示例2】使用numpy.random.random(size=None)创建二维数组
# 函数的参数 size=(3, 4) 表示要生成的数组的形状为3行4列,即包含3个子数组,每个子数组包含4个元素。
a = np.random.random(size=(3, 4))
print(a)
运行结果如下:
[[0.32989944 0.76740016 0.10208365 0.01924679]
[0.20753174 0.09438332 0.44283362 0.41200616]
[0.89764502 0.62156786 0.06232488 0.40479654]]
【示例3】使用numpy.random.random(size=None)创建三维数组
# 由2个平面组成的三维数组。每个平面有3行4列的元素。
a = np.random.random(size=(2, 3, 4))
print(a)
运行结果如下:
[[[0.60235703 0.83229013 0.55511265 0.84317137]
[0.26768256 0.98907851 0.97608121 0.33226806]
[0.94246877 0.71305221 0.72211643 0.21610183]]
[[0.61838121 0.28558197 0.24185245 0.09372992]
[0.78479353 0.9609283 0.11742715 0.46640449]
[0.04459701 0.07881661 0.32281088 0.54882584]]]
1.3.4 随机整数创建
语法格式:
numpy.random.randint(low, high=None, size=None, dtype=int)
下面是randint函数的参数名称及其作用描述:
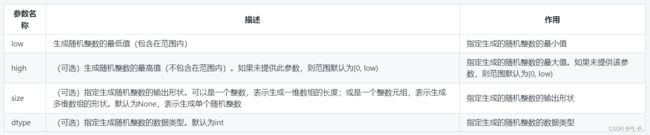
【示例1】生成0到5的随机整数一维数组
# 生成一个长度为10的一维随机整数数组,其元素的取值范围在[0, 6)之间
random_int = np.random.randint(6, size=10)
print(random_int)
运行结果如下:
[1 3 5 5 5 3 4 5 3 4]
【示例2】生成0到5的随机整数二维数组
# 生成一个大小为3x4的二维随机整数数组,其中每个元素的取值范围在[0, 6)之间
random_int = np.random.randint(0, 6, size=(3, 4))
print(random_int)
运行结果如下:
[[3 5 1 5]
[1 5 4 1]
[3 1 2 2]]
【示例3】生成0到5的随机整数三维数组并查看类型
# 生成一个大小为2x4x3的三维随机整数数组,其中每个元素的取值范围在[0, 6)之间
random_int = np.random.randint(0, 6, size=(2, 4, 3), dtype=int64)
# 默认的dtype为int32,这里修改为int64,一般使用默认的,不对其进行设置
print(random_int)
print(random_int.dtype)
运行结果如下:
[[[2 1 2]
[2 1 2]
[2 1 3]
[1 2 5]]
[[3 0 3]
[1 4 1]
[5 1 5]
[1 5 4]]]
int64
1.3.5 其他方式创建
ndarray数组除了可以使用底层ndarray构造器来创建外,也可以通过以下几种方式来创建。
1. zeros创建指定大小的数组
注意:数组元素以0来填充
语法格式:
numpy.zeros(shape, dtype=float, order='C')
下面是arange函数的参数名称及其作用描述:

【示例】使用zeros创建数组
# 创建一维数组
a = np.zeros(5)
# 指定类型
a1 = np.zeros((5,), dtype=int) # dtype指定为整型
# 创建二维数组
b = np.zeros((3, 4))
print(a)
print(a1)
print(b)
运行结果如下:
[0. 0. 0. 0. 0.]
[0 0 0 0 0]
[[0. 0. 0. 0.]
[0. 0. 0. 0.]
[0. 0. 0. 0.]]
2. ones创建指定形状的数组
注意:数组元素以1来填充
语法格式:
numpy.ones(shape, dtype=float, order='C')
参数与zeros一样。
【示例】使用zeros创建数组
# 创建一维数组
a = np.ones(5)
# 指定类型
a1 = np.ones((5,), dtype=int) # dtype指定为整型
# 创建二维数组
b = np.ones((3, 4))
print(a)
print(a1)
print(b)
运行结果如下:
[1. 1. 1. 1. 1.]
[1 1 1 1 1]
[[1. 1. 1. 1.]
[1. 1. 1. 1.]
[1. 1. 1. 1.]]
3. empty创建指定形状、类型且未初始化的数组
里面的元素的值都是之前内存的值
语法格式:
numpy.empty(shape, dtype=float, order='C')
参数与zeros和ones一样。
【示例】使用empty创建数组
# 创建一维数组
a = np.empty(5)
# 创建二维数组
b = np.empty((3, 4))
print(a)
print(b)
运行结果如下:
[0. 0.25 0.5 0.75 1. ]
[[0. 0. 1. 1.]
[1. 1. 1. 1.]
[1. 0. 0. 1.]]
4. linspace创建一维数组
注意:数组是由一个等差数列构成的
语法格式:
numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None)
下面是linspace函数的参数名称及其作用描述:

【示例】使用linspace创建数组
# linspace本身只能创建一维数组,但可以通过reshape()函数改变数组的形状,从而将其转换为多维数组。
a = np.linspace(1, 10, 10)
# linspace的参数使用
b = np.linspace(5, 20, 5, endpoint=False) # 数列中是否包含结束值,默认是True,这里的结束值为20
print(a)
print(b)
运行结果如下:
[ 1. 2. 3. 4. 5. 6. 7. 8. 9. 10.]
[ 5. 8. 11. 14. 17.]
5. logspace创建一维数组
注意:数组是由一个等比数列构成的
语法格式:
numpy.logspace(start, stop, num=50, endpoint=True, base=10.0, dtype=None, axis=0)
下面是linspace函数的参数名称及其作用描述:
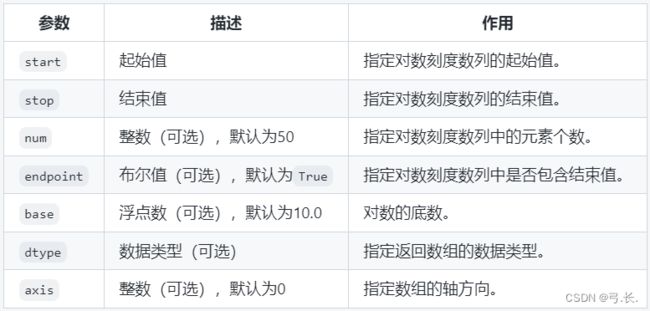
【示例】使用logspace创建数组
# logspace本身只能创建一维数组,但可以通过reshape()函数改变数组的形状,从而将其转换为多维数组。
# 参数base是对数的底数,默认为10.0,这里base修改成2,就是二的零次方到二的九次方,共十个数
a = np.logspace(0, 9, 10, base=2)
print(a)
运行结果如下:
[ 1. 2. 4. 8. 16. 32. 64. 128. 256. 512.]
以上就是利用NumPy模块创建数组的方法啦。
1.4 NunPy创建正态分布
1.4.1 什么是正态分布?
- 正态分布是一种概率分布。正态分布是具有两个参数μ和σ的连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的均值,第二个参数σ是此随机变量的方差,所以正态分布记作N(μ,σ )。
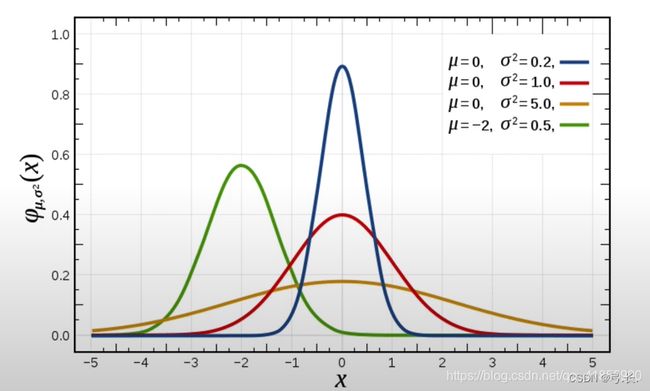
正态分布的应用
生活、生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。
正态分布特点
μ决定位置,标准差σ决定分布的幅度。当μ=0,σ=1时的正态分布是标准正态分布。
标准差的由来
是在概率论和统计方差衡量一组数据时离散程度的度量
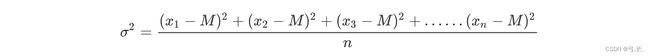
其中M为平均值,n为数据总个数,σ为标准差,σ^2可以理解一个整体为方差
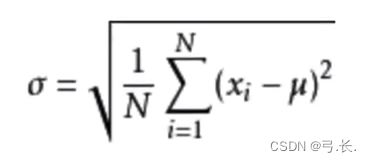
意义:
- 衡量数据集中离散程度的统计量
- 评估数据的稳定性与可靠性
- 判断异常值
- 比较数据集的差异
1.4.2 正态分布的创建
1 使用np.random.randn(d0,d1.…,dn)
功能:返回一个或一组样本,具有标准正态分布(期望为0,方差为1)。
其中dn表示维度,返回值为指定维度的array。
【示例1】创建标准正态分布
import numpy as np # 导入numpy模块,并取别名为np
a = np.random.randn(4) # 创建一维正态分布,4个样本
b = np.random.randn(2, 3) # 创建二维正态分布,2行3列
c = np.random.randn(2, 3, 4) # 创建三维正态分布,两个3行4列
print(a)
print(b)
print(c)
运行结果如下:
[-0.16930696 0.06248915 1.14694234 -0.67915553]
[[ 0.3593049 1.03306886 1.22526589]
[ 0.61003873 -0.27869365 -1.85060132]]
[[[-1.27024862 -0.77071883 0.38358392 -0.47510941]
[ 0.6838695 -1.17981501 -0.02296724 0.49406554]
[ 1.3592937 -0.44472263 -1.06859185 0.45612865]]
[[ 0.97739867 1.65453604 1.28613116 0.38836202]
[ 0.25522913 0.06706893 0.02789549 -0.2660675 ]
[ 0.30396508 0.92458245 0.4289461 0.47960441]]]
【示例2】创建指定方差和期望的正态分布
这里使用np.random.normal()创建指定方差和期望的正态分布
语法格式:
numpy.random.normal(loc=0.0, scale=1.0, size=None)
下面是参数说明:

import numpy as np # 导入numpy模块,并取别名为np
a = np.random.normal(size=5) # 默认的期望loc=0.0,方差scale=1.0
b = np.random.normal(loc=2, scale=3, size=(2, 3)) # 指定期望和方差,创建一个二维的正态分布(2行3列)
print(a)
print(b)
运行结果如下:
[-1.35319011 -0.68628191 0.64808923 -1.14593456 0.02243171]
[[ 5.58788096 6.42265409 1.89002242]
[-3.04814133 -4.60432636 0.37355701]]
1.5 ndarray对象
NumPy最重要的一个特点是其N维数组对象ndarray,它是一系列同类型数据的集合,以0下标为开始进行集合中元素的索引。
ndarray对象是用于存放同类型元素的多维数组。
ndarray中的每个元素在内存中都有相同存储大小的区域。
ndarray内部由以下部分内容组成:
- 一个指向数据(内存或内存映射文件中的一块数据)的指针。
- 数据类型或dtype,描述在数组中的固定大小值的格子。
- 一个表示数组形状(shape)的元组,表示各维度大小的元组。
ndarray对象属性有:
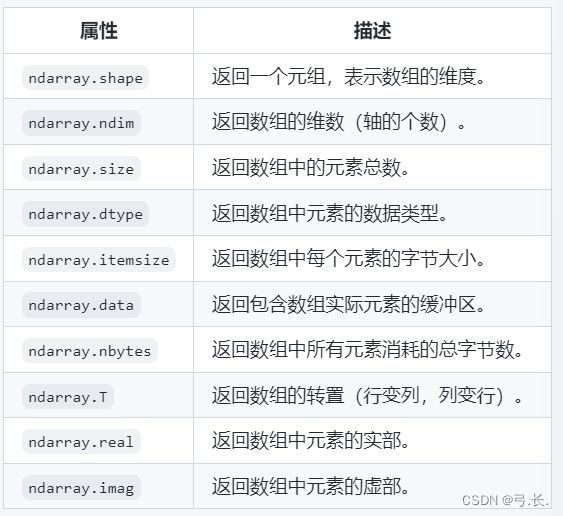
【示例】查看ndarray对象属性
# 创建一维数组
a = np.array([1, 2, 3, 4])
# 创建二维数组
b = np.random.randint(4, 10, size=(2, 3))
# 创建三维数组
c = np.random.randn(2, 3, 4)
# ndim属性
print('ndim:', a.ndim, b.ndim, c.ndim) # 查看数组的维度,如一维数组的维度为1
# shape属性
print('shape:', a.shape, b.shape, c.shape) # 表示数组的维度,如b是一个2行3列的二维数组
# dtype属性
print('dtype:', a.dtype, b.dtype, c.dtype) # 查看数组中元素的数据类型,如a和b是int32,c是float64
# size 元素的总个数
print('size:', a.size, b.size, c.size) # 查看数组中的元素总个数,如c中三维数组的元素个数为24
# itemsize 每个元素所占的字节
print('itemsize', a.itemsize, b.itemsize, c.itemsize) # 查看每个元素的字节大小(与数据类型有关),如b中每个元素占4个字节
...
运行结果如下:
ndim: 1 2 3
shape: (4,) (2, 3) (2, 3, 4)
dtype: int32 int32 float64
size: 4 6 24
itemsize 4 4 8
1.5 数组的切片和索引
ndarray对象的内容可以通过索引或切片来访问和修改,与Python中list的切片操作一样。
ndarray数组可以基于0 - n的下标进行索引,并设置star,stop及step参数进行,从原数组中切割出一个新数组。
【示例】一维数组切片和索引的使用
# 创建一维数组
a = np.arange(10)
print(a)
# 索引访问:1.正索引访问,从0开始到当前长度减一
print('正索引为0的元素:', a[0])
print('正索引为5的元素:', a[5])
# 负索引访问,从-1开始
print('最后一个元素:', a[-1])
# 切片操作 [star:stop:step]
print(a[:]) # 从开始到结尾
print(a[3:5]) # 从索引3开始到索引4结束[star:stop)
print(a[1:7:2]) # 从索引1开始到6结束,步长为2
print(a[::-1]) # 反向获取
运行结果如下:
[0 1 2 3 4 5 6 7 8 9]
正索引为0的元素: 0
正索引为5的元素: 5
最后一个元素: 9
[0 1 2 3 4 5 6 7 8 9]
[3 4]
[1 3 5]
[9 8 7 6 5 4 3 2 1 0]
【示例】二维数组切片和索引的使用
# 创建一维数组
x = np.arange(1, 13)
a = x.reshape(4, 3) # 重新转化形状,把一维数组转化为4行3列的二维数组
# 数组元素
print(a)
print('-'*15)
# 使用索引获取
print(a[2]) # 获取第三行
print(a[1][2]) # 获取第二行,第三列的元素
print('-'*15)
# 切片的使用 [对行进行切片, 对列进行切片] [star:stop:step, star:stop:step]
print(a[:, :]) # 获取所有行所有列
print(a[:, 1]) # 获取所有行第二列
print(a[:, 0:2]) # 获取所有行第一二列,所有行部分列
print('-'*15)
# 获取部分行所有列与之类似
print(a[::2, :]) # 获取奇数行
print(a[::2, 0:2]) # 获取奇数行,第一二列
# 坐标获取 [行, 列]
print(a[1, 2]) # 获取第二行第三列的元素
# 同时获取不同行不同列,获取第二行第三列和第三行第一列,这是获取的值,可以用创建数组的方式将两个值组成一个数组
print(a[(1, 2), (2, 0)]) # 两个括号的第一个值组成一组,第二个值组成一组即第二行第三列和第三行第一列
# 索引为负数来获取
print('-'*15)
print('获取最后一行')
print(a[-1])
print('行进行倒序')
print(a[::-1])
print('行列都倒序')
print(a[::-1, ::-1])
运行结果如下:
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
---------------
[7 8 9]
6
---------------
[[ 1 2 3]
[ 4 5 6]
[ 7 8 9]
[10 11 12]]
[ 2 5 8 11]
[[ 1 2]
[ 4 5]
[ 7 8]
[10 11]]
---------------
[[1 2 3]
[7 8 9]]
[[1 2]
[7 8]]
6
[6 7]
---------------
获取最后一行
[10 11 12]
行进行倒序
[[10 11 12]
[ 7 8 9]
[ 4 5 6]
[ 1 2 3]]
行列都倒序
[[12 11 10]
[ 9 8 7]
[ 6 5 4]
[ 3 2 1]]
1.6 NumPy中的浅拷贝与深拷贝
1.6.1 浅拷贝
共享内存地址的两个变量,当其中一个变量的值改变时,另一个变量的值也随之改变。此时,变量间的“拷贝”是“浅拷贝”
共享“视图”(view)的两个变量,当其中一个变量的值改变时,另一个变量的值也随之改变。
【示例】浅拷贝
a = np.array([1, 2, 3])
b = a
print(b is a)
运行结果如下:
True
原因:两个变量指向同一块内存地址,如下所示:

1.6.2 深拷贝
深拷贝是创建一个全新的对象,包含原始对象中所有属性和值,并且递归地复制所有嵌套的对象,而不仅仅是复制表面层次结构。
【示例】深拷贝
a = np.array([1, 2, 3])
b = a.copy() # 调用copy方法进行深拷贝
print(b is a)
运行结果如下:
False
原因:两个变量指向两个不同的地址,所以一个变量的改变不会影响另一个变量
如下所示:

总结:我们只要记住在浅拷贝中,原始数组和新的数组共同执行同一块内存;同时在深拷贝中,新的数组是原始数据的单独的拷贝,它指向一块新的内存地址。
1.7 修改数组的维度
处理数组的一项重要工作就是改变数组的维度,包含提高数组的维度和降低数组的维
度,还包括数组的转置。Numpy 提供的大量 API 可以很轻松地完成这些数组的操作。例如,
通过 reshape 方法可以将一维数组变成二维、三维或者多维数组。通过 ravel 方法或 flatten
方法可以将多维数组变成一维数组。改变数组的维度还可以直接设置 Numpy 数组的 shape
属性(元组类型),通过 resize 方法也可以改变数组的维度。
1. 使用 reshape 将一维数组变成多维维数组
【示例】
# 创建一维数组
x = np.arange(1, 25)
a = x.reshape(2, 3, 4) # 转化成两个三行四列的三维数组
print(a)
运行结果如下:
[[[ 1 2 3 4]
[ 5 6 7 8]
[ 9 10 11 12]]
[[13 14 15 16]
[17 18 19 20]
[21 22 23 24]]]
注意:转化维度之前要确保转化后的数组与原数组元素个数相统一,否则无法转化。
【示例】将多维数组转化为一维数组
a = np.array([[[1, 2, 3], [4, 5, 6], [7, 8, 9]]]) # 创建三维数组
b = a.reshape(9) # 括号中填入多维数组的元素个数
c = a.reshape(-1) # 不管几维数组,有多少元素,都会转化为一维数组
print(b)
print(c)
运行结果如下:
[1 2 3 4 5 6 7 8 9]
[1 2 3 4 5 6 7 8 9]
2. 使用 ravel 函数将多维数组变成一维的数组
ravel()是NumPy中的一个函数,它用于将数组展平成一维数组。返回一个视图(view)或复制(copy),具体取决于原始数组的数据类型和内存布局。
当使用ravel()函数时,如果原始数组是C语言风格的连续数组,则返回一个视图;否则,它将返回一个复制。使用视图,任何对展平后的数组的修改都将反映在原始数组中;而使用复制,则不会影响原始数组。
【示例】使用ravel函数将多维数组转化为一维数组
a = np.array([[1, 2, 3], [4, 5, 6]]) # 创建一个二维数组
b = a.ravel() # 使用ravel()将数组展平成一维数组
print(b)
运行结果如下:
[1 2 3 4 5 6]
3. 使用 flatten函数将多维数组变成一维的数组
flatten()是NumPy数组对象的一个方法,用于将多维数组展平成一维数组。
与ravel()方法不同,flatten()方法总是返回数组的复制,而不是返回视图。这意味着展平后的数组是原始数组的副本,对展平后的数组的任何修改都不会影响原始数组。
【示例】使用 flatten函数将多维数组转化为一维数组
a = np.array([[1, 2, 3], [4, 5, 6]]) # 创建一个二维数组
b = a.flatten() # 使用flatten()将数组展平成一维数组
print(b)
运行结果如下:
[1 2 3 4 5 6]
注意:使用flatten()方法返回的是一个新的一维数组,原始数组保持不变。
1.8 数组的拼接
1.8.1 水平数组组合
通过 hstack 函数可以将两个或多个数组水平组合起来形成一个数组,那么什么叫做数组
的水平组合。现在有两个 2*3 的数组 A 和 B。

可以看到,数组 A 和数组 B 在水平方向首尾连接了起来,形成了一个新的数组。这就是数组的水平组合。多个数组进行水平组合的效果类似。但数组水平组合必须要满足一个条件,就是所有参与水平组合的数组的行数必须相同,否则进行水平组合会抛出异常。
1.8.2 垂直数组组合
通过 vstack 函数可以将两个或多个数组垂直组合起来形成一个数组,那么什么叫数组的
垂直组合呢?现在以两个 2*3 的数组 A 和 B 为例


numpy.concatenate 函数用于沿指定轴连接相同形状的两个或多个数组,格式如下:
numpy.concatenate((a1, a2, ...), axis)

【示例1】
a = np.array([[1, 2, 3], [4, 5, 6]])
print(a)
b = np.array([['a', 'b', 'c'], ['d', 'e', 'f']])
print(b)
print(np.concatenate([a, b]))
print('垂直方向拼接 相当于 vstack')
print(np.concatenate([a, b], axis=0))
print('水平方向拼接 相当于 hstack')
print(np.concatenate([a, b], axis=1))
运行结果如下:
[[1 2 3]
[4 5 6]]
[['a' 'b' 'c']
['d' 'e' 'f']]
[['1' '2' '3']
['4' '5' '6']
['a' 'b' 'c']
['d' 'e' 'f']]
垂直方向拼接 相当于 vstack
[['1' '2' '3']
['4' '5' '6']
['a' 'b' 'c']
['d' 'e' 'f']]
水平方向拼接 相当于 hstack
[['1' '2' '3' 'a' 'b' 'c']
['4' '5' '6' 'd' 'e' 'f']]
numpy.hstack 它通过水平堆叠来生成数组。
numpy.vstack 它通过垂直堆叠来生成数组。
【示例2】vstack 与 hstack
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.array([['a', 'b', 'c'], ['d', 'e', 'f']])
print('x 轴方向及垂直堆叠')
print(np.vstack([a, b]))
print('y 轴方向及水平堆叠')
print(np.hstack([a, b]))
运行结果如下:
x 轴方向及垂直堆叠
[['1' '2' '3']
['4' '5' '6']
['a' 'b' 'c']
['d' 'e' 'f']]
y 轴方向及水平堆叠
[['1' '2' '3' 'a' 'b' 'c']
['4' '5' '6' 'd' 'e' 'f']]
注意:如果拼接的行和列数目不同,则会报错。
【示例3】三维数组的拼接
aa = np.arange(1, 37).reshape(3, 4, 3)
print(aa)
bb = np.arange(101, 137).reshape(3, 4, 3)
print(bb)
print('axis=0' * 10)
print(np.concatenate((aa, bb), axis=0)) # 6,4,3
print('axis=1' * 10)
print(np.concatenate((aa, bb), axis=1)) # 3,8,3
print('axis=2' * 10)
print(np.concatenate((aa, bb), axis=2)) # 3,4,6
axis=0 可以使用 vstack 替换
axis=1 可以使用 hstack 替换
axis=2 可以使用 dstack 替换
1.9 数组的分隔
numpy.split 函数沿特定的轴将数组分割为子数组,格式如下:
numpy.split(ary, indices_or_sections, axis)

1. 水平分隔
分隔数组是组合数组的逆过程,与组合数组一样,分隔数组也分为水平分隔数组和垂直分隔数组。水平分隔数组与水平组合数组对应。水平组合数组是将两个或多个数组水平进行收尾相接,而水平分隔数组是将已经水平组合到一起的数组再分开。
使用 hsplit 函数可以水平分隔数组,该函数有两个参数,第 1 个参数表示待分隔的数组,第 2 个参数表示要将数组水平分隔成几个小数组,现在先来看一个例子。下面是一个 2*6的二维数组

很明显,将数组 X 分隔成了列数相同的两个数组。现在使用下面的代码重新对数组 X 进行分隔。

现在讲数组 X 分隔成了 3 个列数都为 2 的数组,但要是使用 hsplit(X,4)分隔数组 X 就会抛出异常,这是因为数组 X 是没有办法被分隔成列数相同的 4 个数组的,所以使用 hsplit函数分隔数组的一个规则就是第 2 个参数值必须可以整除待分隔数组的列数。
【示例】hsplit
grid=np.arange(16).reshape(4,4)
a,b=np.hsplit(grid,2)
print(a)
print(b)
运行结果如下:
[[ 0 1]
[ 4 5]
[ 8 9]
[12 13]]
[[ 2 3]
[ 6 7]
[10 11]
[14 15]]
2. 垂直分隔数组
垂直分隔数组是垂直组合数组的逆过程。垂直组合数组是将两个或多个数组垂直进行首尾相接,而垂直分隔数组是将已经垂直组合到一起的数组再分开。
【示例】vsplit
grid=np.arange(16).reshape(4,4)
a,b=np.vsplit(grid,[3])
print(a)
print(b)
print('-'*10)
a,b,c=np.vsplit(grid,[1,3])
print(a)
print(b)
print(c)
运行结果如下:
[[ 0 1 2 3]
[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]]
----------
[[0 1 2 3]]
[[ 4 5 6 7]
[ 8 9 10 11]]
[[12 13 14 15]]
【示例】split 分隔数组
# 分隔一维数组
x = np.arange(1, 9)
a = np.split(x, 4)
print(a)
print(a[0])
print(a[1])
print(a[2])
print(a[3])
# 分隔二维数组
a = np.array([[1, 2, 3], [4, 5, 6], [11, 12, 13], [14, 15, 16]])
print('axis=0 垂直方向 平均分隔')
r = np.split(a, 2, axis=0)
print(r[0])
print(r[1])
print('axis=1 水平方向 按位置分隔')
r = np.split(a, [2], axis=1)
print(r)
运行结果如下:
[array([1, 2]), array([3, 4]), array([5, 6]), array([7, 8])]
[1 2]
[3 4]
[5 6]
[7 8]
axis=0 垂直方向 平均分隔
[[1 2 3]
[4 5 6]]
[[11 12 13]
[14 15 16]]
axis=1 水平方向 按位置分隔
[array([[ 1, 2],
[ 4, 5],
[11, 12],
[14, 15]]), array([[ 3],
[ 6],
[13],
[16]])]
以上就是全部啦,如有错误或不解之处,请及时私信博主!
希望各位大佬点点赞,大家的支持就是对博主码字的最大支持!!!