用 10 万条微信记录和 280 篇文章,我拿 AI「克隆」了自己
除了开飞机,做出完美的烤肋排,获得 6 块腹肌以及让公司赚大钱之外,我一直以来也想做成的一件事,是实现一个聊天机器人。
和多年前简单通过关键词匹配来回复的小黄鸡,到现在已经堪比人类智慧的 ChatGPT,聊天 AI 一直在进步,但他们和我想的都有一些区别。
我在微信上和很多人聊天,有的人聊得多,有的人聊得少,我在群里也会说话,我还会写博客和公众号,我会在很多地方留下评论,我也会发微博,这些是我在网络世界留下的痕迹,某种程度上这些东西构成了世界对我的认知,从这个角度上,也就构成了我。将这些数据——我对不同消息的回复,我写的每一篇文章,每一句话,我发过的每一条微博等,全部汇入一个神经网络模型之中,去更新其中的参数,理论上就可以获得一个我的数字拷贝。
从原理上,这和对 ChatGPT 说「请扮演一个叫小王的人,他的经历是XXX」不同,虽然以 ChatGPT 的智慧,这样的扮演毫不费力且可能以假乱真,但其实 ChatGPT 的参数并没有改变,这更像是「扮演」而非「重塑」,ChatGPT 的上千亿个参数并没有改变一个,它从你之前的文本中获取一些信息,然后用它的智慧来应对你。

我喜欢在文章里写一些没有太大用处的比喻,并喜欢在最后做一些总结,跟人聊天的时候,我喜欢用「可以的」来敷衍,同时用卧槽来表示惊讶,我某些时候少言寡语,另一些时候则滔滔不绝。
这是我自己能够感知的一些特点,此外还有更多我自己都无法察觉的固定习惯,但这些微妙又模糊的东西,我无法告诉 ChatGPT。这就像你做自我介绍,可以介绍的很丰富,但和真正的你,依然差之千里,甚至有时候截然相反,因为当我们意识到自己的存在的时候,我们其实是在表演自己,只有在我们没有意识到自己的存在,而融入生活的时候,我们才是真正的自己。
在 ChatGPT 发布之后基于兴趣去学习文本大模型的技术原理,有一种 49 年入国军的感觉,因为对个人爱好者来说,做出在任何方面或再细小的垂直领域超越 ChatGPT 的可能性已经不存在了,同时它又不开源,除了使用,没有别的可打的主意。
但最近 2 个月出现的一些开源文本预训练模型,例如大名鼎鼎的 llama 和 chatglm6b,让我那个克隆自己的想法又开始蠢蠢欲动起来,上周,我准备试试看。
首先我需要数据,足够多且全部都由我产生的数据,最简单的数据来源是我的微信聊天记录和博客,因为没有完全清空微信聊天记录,从 2018 年到现在,我手机里的微信占了 80G 的储存空间,对此我一直有一种家里被人强占一块地儿的感觉,现在如果能把这里的数据利用起来,我会和这 80G 冰释前嫌。

我在几年前曾经备份过我的微信聊天记录,我又找到了当年使用的工具,是一个在 github 开源的工具,叫做 WechatExporter,使用这个工具,可以实现在 Windows 电脑上备份 iPhone 中的手机微信的所有聊天记录,并导出成纯文本格式。这是一个需要耐心的操作,因为首先需要将整个手机备份在电脑上,然后这个工具会从备份文件中读取到微信的记录,并导出。
我大概花了 4 个小时备份,然后很快导出了我所有的微信聊天记录,其按照聊天对象,被导出到了许多个文本文件中。

这里面包括了群聊和一对一的聊天
然后我开始做数据清洗,大多数群我都是潜水比较多,我筛选出一些我比较活跃的群,此外还筛出了一些和个人的聊天记录,我和他们聊天很多,同时他们也愿意我把聊天记录拿来这么做,最后大概 50 个聊天的文本文件够我使用。
我写了一个 python 脚本,遍历这些文本文件,找出我的所有发言,以及上一句,做成对话的格式,然后存入 json,这样,我就拥有了一个我自己的微信聊天数据集。

此时我也让同事用爬虫爬取了我自己的所有博客文章,他爬完发给我之后我才想起来,我其实可以用博客后台内置的导出功能直接导出。博客数据虽然也很干净,但我一开始并不知道如何利用,因为我要训练的是聊天的模型,而博客文章是一大段一大段的话,并不是聊天,所以我第一次训练,只用了微信的这些纯聊天记录。
我选择了 chatglm-6b 作为预训练模型,一方面它的中文效果已经被训练的足够好了,另一方面它的参数是 60 亿,我的机器能不太费力的跑起来,还有个原因是,在 github 已经有好几个对其进行微调训练的方案了。
考虑到我的微信聊天数据最终可用大约 10 万条,我设置了比较低的学习率,同时增加了epoch,在几天前的一个晚上,睡前,我写完训练脚本,并开始运行,然后我就开始睡觉,希望睡醒之后能跑完,但那个晚上我差不多每隔一个小时就醒一次。
早上起来之后,模型训练完了,遗憾的是 loss 下降的并不好,也就意味着 12 个小时训练出来的模型,并不算好,但我是个深度学习的菜鸡,能跑完不报错我已经谢天谢地了,所以我并没有感到失望,而是开始用这个模型来跑对话。
为了增加一点仪式感,我不想用 jupyter 笔记,或在黑黢黢的终端里去聊天,我找了个开源的前端聊天页面,略做修改,然后把模型部署起来,封装了 API ,然后用前端页面去调用这个 API,于是就可以实现比较像那么回事的聊天了。
请不笑话我,我用自己的 10 万条微信聊天记录,训练出的模型,以下是我和他(或者它?)的第一次对话

我又试了下,结果依然不是很好,我不是那种不优化到极致就不好意思拿出手的人,因此我毫不害羞的直接发给了几个朋友,他们给我的反馈是,有点像你,同时他们给我返了对话截图。

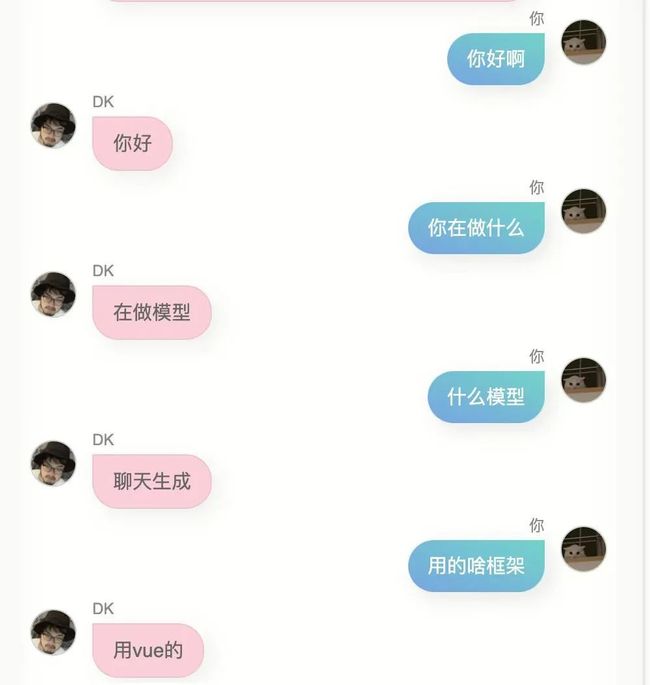

左右滑动查看更多
第一个版本,这个模型确实具备某些跟我比较类似的点,我说不好,但有一点这种感觉。
如果你问它,你哪里读的大学,或者你老家是哪里,它并不会回答出准确的信息,并且肯定说的是错的,因为我的聊天记录中并不会有很多人这么问我,从某种角度上,这个模型并不了解我,它像是一个克隆。
当我收到一条微信消息,内容为 A,我回复了 B,那么这里是有一些原因的,这些原因中的一部分,储存在我物理脑袋的七八十亿个神经元里,理论上,如果我产生的数据足够多,也许几千亿条,那么一个参数够大的人工智能模型,就能非常接近我的脑子,10 万条也许少了一些,但也足以让模型的 60 亿个参数里改变一部分,使其相较于原始的预训练模型,更接近我一点。
此外它还有个更大的缺点,就是蹦不出来几个字,回答非常简略,这虽然符合我很多时候的微信聊天风格,但并不是我想要的,我想要它说更多话。
此时我忽然想到了我的博客,如何能把这些博客转换为问答呢,我想到了 ChatGPT ,在我精心构造的 prompt 之下,它成功把我博客文章的一段文本,变成了多个对话形式的问答:
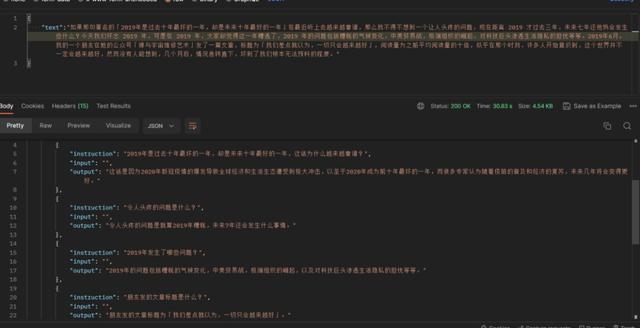
某些时候 ChatGPT 会返回一些不符合格式的内容,所以我写了一个校对脚本,来将各种不符合规则的返回,统统修改为标准的json,且字段名不变。
然后我将其封装为一个接口,放在了香港的服务器上,并在我的电脑上写了一个脚本,把我的博客文章按照 500 字划分,拿去批量转成问答,受限于 ChatGPT 的接口速度,我差不多又花了一晚上,才把我的两百多篇博文,转换成了差不多 5000 个对话数据集。
此时我面临一个选择,如果将博客对话加到微信对话数据集里去训练,那么博客对话占比太低,可能影响会非常小,也就是说跟之前的模型差别不大;另一个选择是单纯用文章的这些数据,去训练一个新模型。
我向 6pen 的算法老哥寻求帮助,在确定模型权重可以融合并想办法从他那顺到融合脚本后,采用了后一种方式。
5000 个问答,训练速度很快,一两个小时就够了,下午我一边写文档一边瞅一眼训练进度,下班之前训练完毕,我开始进行模型的融合,让之前的用微信聊天记录训练的模型,和用我的博客训练的模型进行融合。
两个模型的权重可以自由配置,我尝试了多种不同的比例,考虑到模型收敛过程中 loss 还有一些反弹,我还尝试了不同步数的模型版本
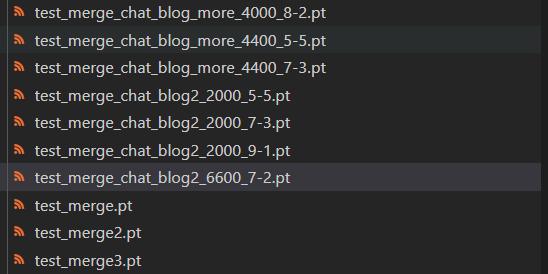
我整晚整晚和这些模型对话,找到效果最好的,但我发现,我似乎很难找出来,这些模型,有一些不同的表现,有的会比较暴躁,有的像舔狗一样,有些特别高冷,有些则很热情,然后我意识到,某种程度上,这或许是我的不同面,这么理解虽然肯定会让搞深度学习,并对其中原理烂熟于胸的人嗤之以鼻,但不失一些浪漫。

最终我发现,聊天和文章两个模型,权重比为 7 比 2 ,且采用第 6600 步保存的模型,融合效果在更多时候,都要更好一点,当然也可能是那个时候已经半夜两点,我的判断力有所下降,但无论如何,我就把他确定为最终模型了。
我和他聊了很多。








很明显,他和 ChatGPT 差得极远,没办法帮我写代码,或者写文案,也不够聪明,因为训练用的数据不包含多轮对话,所以多轮对话的理解力更差,与此同时,他对我也不算特别了解,除了知道自己的名字(也就是我的名字),我的其他很多信息,他其实并不能准确回答,但是,他经常会说一些简单的几个字,让我有一种熟悉的感觉,也可能是错觉,谁知道呢。
总的来说,现在存在的所有广为人知的文本大模型,都是用海量的数据训练的,训练过程会尽可能包含全人类所产生的所有信息,这些信息让模型的亿万参数得以不断优化,例如第 2043475 个参数增加 4,第 9047113456 个参数减少 17,然后得到更聪明的神经网络模型。
这些模型变得越来越聪明,但它们更像是人类的,而非个体的,当我用我自己的这些数据去重新训练模型时,我能得到完全不一样的东西,一个更靠近个体的模型,虽然无论是我产生的数据量,还是我采用的预训练模型的参数量和结构,可能都无法支撑起一个能够和我的脑子差不多的模型,但对此进行的尝试,依然非常有意思。
我将这个网页重新部署了一下,并在中间加了一层 serverless 做保护,因此,现在所有人都可以去试试和这个我的数字版聊天,服务由我的祖传 V100 服务器提供,并且只有一台,所以如果人多的话,可能会有各种问题,链接我会放在最下面。
积极的,发自内心的产出更多的数据,就越有可能在未来获得更接近你的数字拷贝,这或许会有一些道德,甚至伦理问题,但这是大概率会发生的事情,之后我的数据积累的更多,或有更好的预训练模型,训练方式,我可能随时都会重新再次尝试训练,这不会是一个盈利,或任何跟商业沾边的项目,这某种程度上算是我自己追寻自己的一种方式。
这样一想,人生似乎都少了一些孤独感