卷积神经网络之优化参数(人马分类)
构造神经元网络模型时,我们一定会考虑需要几个卷积层,需要有几个过滤器,全连接层需要几个神经元?
在下面中我们将解决这个问题
在CV2中我们已经通过CNN成功的完成了人马识别的例子,但是识别的效果并不算很好。在CV3中我们将对其参数做优化。
目录
一.优化参数的三个方法
1.手动修改
2.for循环调参
3.Keras Tunner自动调参工具
介绍
1.安装
2.准备训练数据和加载的库
3.创建HyperParameters对象
4.创建Hyperband对象
4.开始优化
5.获取最佳模型
6.结果显示
二.注释
1.为什么二次调参无效,不起作用?(避坑)
一.优化参数的三个方法
有以下三个方法
1.手动修改
我们可以有最原始的办法,就是手动修改参数,然后观察训练的效果(损失和精确度),从而判断参数的设置是否合理,但是这样很麻烦。
2.for循环调参
还有一个办法就是,那就是编程写for循环来调参,但是也有点麻烦。
3.Keras Tunner自动调参工具
在这里我们可以借助这款自动调参工具来实现我们参数的优化,优点是不容易出错,效果也比较好。
介绍
keras Tunner是一个可以自动搜索模型训练参数的库,它的基本思路是在需要调整参数的地方插入一个特殊的对象(可指定参数范围),然后调用类似训练那样的search方法。
1.安装
依赖
- python 3.6
- TensorFlow 2.0
安装命令:
pip install -U keras-tuner2.准备训练数据和加载的库
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.optimizers import RMSprop
#创建两个数据生成器,指定scaling范围0~1
train_datagen = ImageDataGenerator(rescale=1/255)
validataion_datagen = ImageDataGenerator(rescale=1/255)
#指向训练数据文件夹
train_generator = train_datagen.flow_from_directory(
'F:/deeplearning/tmp/horse-or-human',
target_size=(150,150),
batch_size=32,
class_mode='binary')
#指向测试数据文件夹
validation_generator = train_datagen.flow_from_directory(
'F:/deeplearning/tmp/validation-horse-or-human',
target_size=(150,150),
batch_size=32,
class_mode='binary')
from kerastuner.tuners import Hyperband
from kerastuner.engine.hyperparameters import HyperParameters3.创建HyperParameters对象
先创建HyperParameters对象。进而我们定义一个模型,然后在模型中插入Choice以及int等调参用的对象。该函数返回一个编译好的模型。
hp=HyperParameters()#声明一个变量,类型为HyperParameters,等会通过hp来调
#将创建模型的代码作为函数
def build_model(hp):
#构建模型
model = tf.keras.models.Sequential()
#用Choice是判断有几个filter比较合适
model.add(tf.keras.layers.Conv2D(hp.Choice('num_filters_top_layer', #随便起的名字,训练好之后他会把数值直接和这个名字对应起来
values=[16,64],#指定取值范围
default=16),#默认值
(3,3),
activation='relu',input_shape=(150,150,3)))
model.add(tf.keras.layers.MaxPooling2D(2,2))
#再看Conv应该有几层(因为我们也不知道应该有多少层卷积层)[只注意只for循环卷积层]
for i in range(hp.Int('num_conv_layers',1,3)):#这里默认step是1,数值不能太大,Max Pooling以后会越来越小,输出尺寸会越来越小,小到出现负数了这个训练就走不下去了
model.add(tf.keras.layers.Conv2D(hp.Choice(f'num_filters_layer{i}',#加f表示在字符串内支持大括号内的Python表达式
values=[16,64],
default=16),
(3,3),activation='relu'))
model.add(tf.keras.layers.MaxPooling2D(2,2))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(hp.Int('hidden_units',128,512,step=32),#给出范围和搜索步长
activation='relu'))
model.add(tf.keras.layers.Dense(1,activation='sigmoid'))
model.compile(loss='binary_crossentropy', # 注意模型必须先编译
optimizer=RMSprop(lr=0.001),
metrics=['accuracy'])
return model4.创建Hyperband对象
进而我们再创建Hyperband对象,这是keras tuner支持的四种方法的其中一种。
tuner=Hyperband(#生成一个tunner对象,输入Hyperband
build_model,#函数的名字,告诉他用哪个函数生成这个模型
objective='val_accuracy',#目标使用val_accuracy,以测试集的accuracy为目标
max_epochs=15,#猜最多几次可以达到会聚
directory='horse_human_params', #请看注释一(避坑),调参的过程会把数据加到本地,需要指定一个本地目录加名称,其他都是自动的,
hyperparameters=hp,#告诉他是用这个变量
project_name='my_horse_human_project' #存储的时候随便取的名字
)4.开始优化
搜索过程:通过调用模型构建函数,使用hp跟踪的超参空间(搜索空间)中的参数配置,多次构建模型。优化器逐渐探索超参空间,记录每种配置的评估结果。
#接下来搜一下参数,search和fit差不多的
tuner.search(train_generator,epochs=10,validation_data=validation_generator)5.获取最佳模型
搜索到最优参数之后,可通过下面的程序,用tunner对象提取最优参数构建神经元网络模型。并调用summary方法观察优化后的网络结构。
#优化完参数后可以通过这个方法看到结果
best_hps=tuner.get_best_hyperparameters(1)[0]#可以用到这个办法读到它的参数
model=tuner.hypermodel.build(best_hps)#可以用这些参数把模型构建出来
model.summary()
tuner.results_summary()#可打印结果综述6.结果显示
结果:
Search: Running Trial #30
Hyperparameter |Value |Best Value So Far
num_filters_top...|16 |64
num_conv_layers |3 |2
num_filters_layer0|16 |64
hidden_units |224 |416
num_filters_layer1|16 |16
num_filters_layer2|16 |16
tuner/epochs |15 |15
tuner/initial_e...|0 |0
tuner/bracket |0 |0
tuner/round |0 |0
Epoch 1/15
33/33 [==============================] - 12s 333ms/step - loss: 0.6235 - accuracy: 0.6292 - val_loss: 0.9375 - val_accuracy: 0.7539
Epoch 2/15
33/33 [==============================] - 11s 342ms/step - loss: 0.2492 - accuracy: 0.8954 - val_loss: 0.6282 - val_accuracy: 0.8789
Epoch 3/15
33/33 [==============================] - 9s 270ms/step - loss: 0.1137 - accuracy: 0.9480 - val_loss: 1.7960 - val_accuracy: 0.8008
Epoch 4/15
33/33 [==============================] - 12s 355ms/step - loss: 0.1907 - accuracy: 0.9303 - val_loss: 1.0514 - val_accuracy: 0.8242
Epoch 5/15
33/33 [==============================] - 12s 363ms/step - loss: 0.0539 - accuracy: 0.9819 - val_loss: 1.0656 - val_accuracy: 0.7734
Epoch 6/15
33/33 [==============================] - 10s 309ms/step - loss: 0.0648 - accuracy: 0.9747 - val_loss: 1.1672 - val_accuracy: 0.8672
Epoch 7/15
33/33 [==============================] - 12s 372ms/step - loss: 0.0260 - accuracy: 0.9938 - val_loss: 0.8903 - val_accuracy: 0.8828
Epoch 8/15
33/33 [==============================] - 11s 321ms/step - loss: 0.0907 - accuracy: 0.9804 - val_loss: 1.1295 - val_accuracy: 0.8828
Epoch 9/15
33/33 [==============================] - 9s 273ms/step - loss: 0.0054 - accuracy: 0.9996 - val_loss: 1.5149 - val_accuracy: 0.8633
Epoch 10/15
33/33 [==============================] - 9s 263ms/step - loss: 0.1649 - accuracy: 0.9708 - val_loss: 1.0031 - val_accuracy: 0.8828
Epoch 11/15
33/33 [==============================] - 9s 259ms/step - loss: 0.0141 - accuracy: 0.9975 - val_loss: 0.8392 - val_accuracy: 0.8867
Epoch 12/15
33/33 [==============================] - 9s 271ms/step - loss: 0.0031 - accuracy: 1.0000 - val_loss: 1.3648 - val_accuracy: 0.8828
Epoch 13/15
33/33 [==============================] - 9s 257ms/step - loss: 0.0169 - accuracy: 0.9917 - val_loss: 2.4052 - val_accuracy: 0.8359
Epoch 14/15
33/33 [==============================] - 9s 281ms/step - loss: 0.0276 - accuracy: 0.9928 - val_loss: 1.5494 - val_accuracy: 0.8867
Epoch 15/15
33/33 [==============================] - 9s 271ms/step - loss: 4.4481e-04 - accuracy: 1.0000 - val_loss: 1.9674 - val_accuracy: 0.8594
Trial 30 Complete [00h 02m 35s]
val_accuracy: 0.88671875
Best val_accuracy So Far: 0.9140625
Total elapsed time: 00h 53m 12s
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 148, 148, 64) 1792
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 74, 74, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 72, 72, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 36, 36, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 34, 34, 16) 9232
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 17, 17, 16) 0
_________________________________________________________________
flatten (Flatten) (None, 4624) 0
_________________________________________________________________
dense (Dense) (None, 416) 1924000
_________________________________________________________________
dense_1 (Dense) (None, 1) 417
=================================================================
Total params: 1,972,369
Trainable params: 1,972,369
Non-trainable params: 0
_________________________________________________________________
发现了没有我们的结果其实还不是很理想,出现了过拟合的现象,在这里我们参数都已经优化了,训练集的样本也足够多了,那是哪里出了问题呢?我们查看一下我们的搜索结果,发现val_accuracy还不够高,这说明可能我们的搜索迭代参数还不够多,于是我们增加了搜索迭代的次数,得到下面的结果。这个结果还是能够接受的。
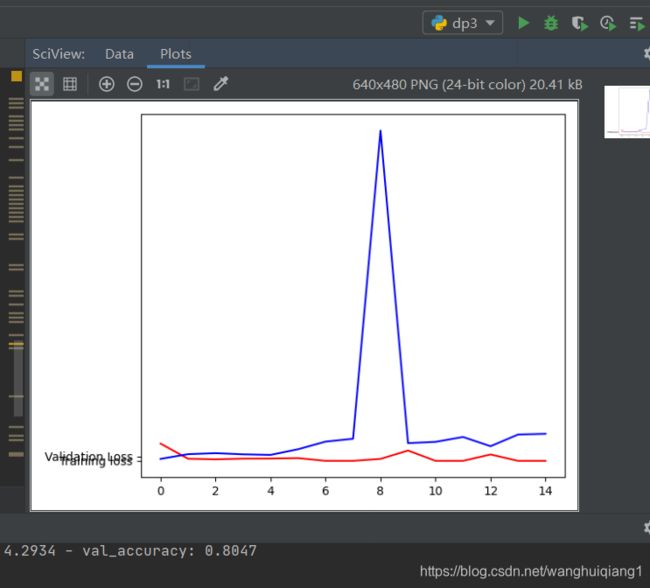
二.注释
1.为什么二次调参无效,不起作用?(避坑)
是因为第一次调参之后把调参之后的结果存储在directory里面了,二次调参需要把那个文件夹删了才会重新优化。