揭秘Elasticsearch:一文读懂分布式搜索与分析引擎的核心概念
Elasticsearch 是一个开源、分布式、实时搜索和分析引擎,专门用于处理大规模数据的快速检索与分析。它建立在 Apache Lucene 的基础上,但提供了比 Lucene 更为丰富的功能和友好的RESTful API 接口,使得开发者能够轻松地进行全文搜索、结构化搜索以及对海量数据进行复杂的聚合操作。
Elasticsearch 目前被广泛用于互联网多种领域中。一是搜索领域,相对于 solr,成为很多搜索的不二之选。二是 Json 文档数据库,相对于 MongoDB,读写性能更佳,而且支持更丰富的地理位置查询以及数字、文本的混合查询。三是时序数据分析处理,目前在日志处理、监控数据存储、分析和可视化方面做的非常好。
一、Elasticsearch与Lucene关系
Lucene 只是一个库,想要使用它必须Java语言来作为开发语言并将其直接集成到你的项目中,更糟糕的事,Lucene 非常复杂,需要摄入了解检索知识来理解它是如何工作的
Elasticsearch 也是使用 Java 开发并且使用 Lucene 作为其核心来实现所有索引和搜索功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文检索变的简单。
二、倒排索引
首先看下什么是正排索引,正排索引指的是文档 ID 到文档内容的索引,简单讲就是通过 ID找内容。
倒排索引(Inverted Index)是根据文档内容找文档,是一种常见的索引结构,他在信息检索领域有重要作用。与传统的正排索引不同,倒排索引以词项为基础,将文档内容映射到词项上,提供了更高效的文本检索和搜索能力。
倒排索引是不可变的,有分段的概念,查询时,所有已知的段按顺序被查询。段是不能被改变的,所以既不能把文档从旧的段中移除,也不能修改旧的段来进行更新。删除数据时并不是真正的删除,而是做上删除标记。
当倒排索引过多时,段是可以进行合并的,当合并段时,就会将有删除标记的文档进行物理删除。
倒排索引主要包含两个核心部分:
单词词典(Lexicon):记录了文本集合中出现过的所有不重复的单词(或者其它可作为查询单位的术语),并为每个单词提供一个唯一的标识符(通常是整数)。这个部分相当于一个字典,可以迅速找到与给定单词相关的倒排列表。
倒排文件(Posting List 或 Inverted List):对于词典中的每个单词,倒排文件包含了所有包含该单词的文档列表及其在文档中的位置信息(有时还包括频率信息,如TF-IDF权重等)。这意味着,当你想要查找包含特定单词的所有文档时,可以直接通过倒排索引迅速定位到相应的文档列表,而不需要逐个检查文档。
假设有两个文档

为了创建倒排索引,我们首先将每个文档的content域拆分成单独的词(称为词条或tokens),创建一个包含所有不重复词条的列表,然后列出每个词条出现在哪个文档。

Elasticsearch 为了能很快速找到某个 term,将所有的 term 排个序,二分法查找 term,LogN 的查找效率,就像通过字典查找一样,这就是 Term Dictionary。似乎和传统数据库通过 B-Tree 的方式类似。
B-Tree通过减少磁盘寻道次数来提升查询性能,Elasticsearch也是同样的思路,直接通过内存来查找Term,不读磁盘,但是如果Term太多,Term Dictionary也会很大,放内存不现实,于是有了Term Index,就像字典里的索引页一样,A开头的有哪些term,分别在哪几页,可以理解Term Index是一棵树。

这棵树不会包含所有的Term,他包含的是Term的一些前缀。通过Term Index可以快速定位到term dictionary的某个offset,然后从这个位置再往后顺序查找。
所以 term index 不需要存下所有的 term,而仅仅是他们的一些前缀与Term Dictionary之间的映射关系,再结合FST(Finite State Transducers)的压缩技术,可以使term index缓存到内存中。从term index查到对应的term dictionary的block位置之后,再去磁盘上找term,大大减少了磁盘随机读的次数。
三、Elasticsearch关键概念
首先看下Elasticsearch的架构图,下面分别介绍一下其核心概念。
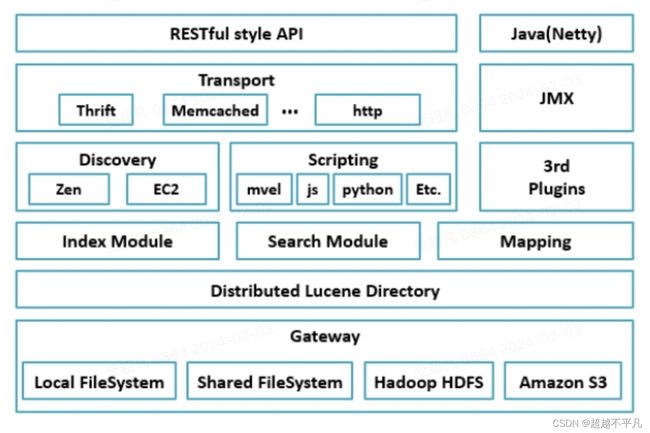
- Cluster:代表一个集群,集群中有多个节点,其中一个是主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的,es 的概念是去中心化,因此从外部来看 es 集群,在逻辑上是一个整体。
- 节点(Node):物理概念,一个运行的 Elasticsearch 实例,一般是一台机器上的一个进程。
- 索引(INdex):逻辑概念,索引是文档的容器,每个索引都有自己的Mapping定义,用于定义包含文档的字段名和字段类型,另一个重要的概念是setting,定义的是数据的不同分布。一个索引的数据文件可能分布于一台机器上,也有可能分布于多台机器上。索引的另外一层意思是倒排索引文件。
- Dynamic Mapping:Mapping 可以简单的理解为数据库的 schema,用于定义索引中字段的名称、类型、倒排索引、指定字段使用何种分词器等。Dynamic Mapping 意思就是在我们创建文档的时候,如果索引不存在,就会自动的创建索引,同时自动的创建 Mapping,ElasticSearch 会自动的帮我们推算出字段的类型,当然,也会存在推算不准确的时候,就需要我们手动的设置。
- 类型(type):5.x 支持多种 type。6.x 只有一种 type。在 7.0 之前,一个 Index 可以创建多个Type。之后只能一个 Index 对应一个Type。
- 文档(Document):一个文档是一个可被索引的基础单元,也是一条数据。文档以JSON(JavaScript Object Notation) 格式表示。
- 分片(Shard):相当于关系型数据库的分表。为了支持更大量的数据,索引一般会按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理,一个节点(Node)会管理多个分片,这些分片可能是属于同一份索引,也有可能指向不同索引,但是为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。分片有两种,主分片和副本分片。分片的作用:
- 允许水平分割,水平扩展容量
- 允许在分片上进行分布式、并行操作,进而提高性能/吞吐量
注意:分片数据在索引创建时就已经确定下来了,是不能被修改的。
- 副本(Replica):同一个分片(Shard)的备份数据,一个分片可能会有 0 个或多个副本,这些副本中的数据保证强一致或最终一致,提高可用性,提升性能/吞吐量。分片数不能修改,但是副本数是可以修改的。
- recovery:代表数据恢复或叫数据重新分布,es 在有节点加入或退出时会根据机器负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
- river:代表 es 一个数据源,也是其他存储方式同步数据到 es 的一个方法。它是以插件方式存在的一个 es 服务,通过读取 river 中的数据并把他索引到 es 中,常见的有 couchDB、RabbitMQ 等,在es2.0之后取消了。
- gateway:代表 es 索引快照的存储方式,es 默认是先把索引存储到内存中,当内存满了在持久化到本地磁盘。gateway 对索引快照进行存储,当这个 es 集群关闭在重新启动时就从gateway 中读取索引备份数据。es 支持多种类型的 gateway,有本地文件系统、分布式系统、云服务存储。
- Transport:代表 es 内部节点或集群与客户端的交互方式,默认内部是 tcp 协议进行交互,同时支持 http、thrift、servlet 等传输协议。
关于Elasticsearch相关概念就介绍到这里,后边继续介绍相关的功能。