Improving Language Understanding by Generative Pre-Training
今天阅读的是 OpenAI 2018 年的论文《Improving Language Understanding by Generative Pre-Training》,截止目前共有 600 多引用。
在这篇论文中,作者提出了一种半监督学习方法——Generative Pre-Training(以下简称 GPT),GPT 采用无监督学习的 Pre-training 充分利用大量未标注的文本数据,利用监督学习的 Fine-tuning 来适配具体的具体的 NLP 任务(如机器翻译),并在 12 个 NLP 任务中刷新了 9 个记录。

1. Introduction
NLP 领域中只有小部分标注过的数据,而有大量的数据是未标注,如何只使用标注数据将会大大影响深度学习的性能,所以为了充分利用大量未标注的原始文本数据,需要利用无监督学习来从文本中提取特征,最经典的例子莫过于词嵌入技术。
但是词嵌入只能 word-level 级别的任务(同义词等),没法解决句子、句对级别的任务(翻译、推理等)。出现这种问题原因有两个:
- 首先,是因为不清楚要下游任务,所以也就没法针对性的进行行优化;
- 其次,就算知道了下游任务,如果每次都要大改模型也会得不偿失。
为了解决以上问题,作者提出了 GPT 框架,用一种半监督学习的方法来完成语言理解任务,GPT 的训练过程分为两个阶段:Pre-training 和 Fine-tuning。目的是在于学习一种通用的 Representation 方法,针对不同种类的任务只需略作修改便能适应。
接下来我们详细介绍下 GPT。
2. GPT
GPT 训练过程分为两个阶段:第一个阶段是 Pre-training 阶段,主要利用大型语料库完成非监督学习;第二阶段是 Fine-tuning,针对特定任务在相应数据集中进行监督学习,通过 Fine-tuning 技术来适配具体任务。下图为 GPT 的架构图:

2.1 Pre-training
从上图我们可以看出,GPT 采用 Transformer 来代替 LSTM 作为特征提取器,并基于语言模型进行训练。这里只使用了 Transformer 的 Decoder 部分,并且每个子层只有一个 Masked Multi Self-Attention(768 维向量和 12 个 Attention Head)和一个 Feed Forward,共叠加使用了 12 层的 Decoder。
这里简单解释下为什么只用 Decoder 部分:语言模型是利用上文预测下一个单词的,因为 Decoder 使用了 Masked Multi Self-Attention 屏蔽了单词的后面内容,所以 Decoder 是现成的语言模型。又因为没有使用 Encoder,所以也就不需要 encoder-decoder attention 了。
对于给定的非监督语料库的 Token 序列
![]()
,基于语言模型的目标函数:

其中,k 是上下文窗口的大小,P 为条件概率,
Θ为条件概率的参数,参数更新采用 SGD。
GPT 输入文本和位置 Embedding(采用使用 one-hot 编码),经过 12 层的 Transformer 的 Decoder 后通过 Softmax 得到输出:

其中,
![]()
是当前单词的前面 k 个 Token,n 为神经网络的层数,
We是 Token 的 Embedding 矩阵,
Wp是位置编码的 Embedding 矩阵。
2.2 Fine-tuning
完成预训练后,我们会得到一个训练好的 Transformer 模型,接下来我们要用这个训练好的模型来完成特定的监督学习的任务。
假设我们有个带标签的数据集 C,即每一个 Token 序列x1,x2,...,xm都有一个标签 y。我们将 Token 序列输入,并通过 Transformer 模型得到输出的状态![]() ,然后叫这个加到线性层进行输出并预测标签 y:
,然后叫这个加到线性层进行输出并预测标签 y:
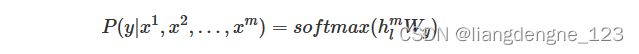
其中,
Wy是线性层的权重。
所以针对该监督学习,我们也有新的目标函数:

另外,将预训练好的语言模型作为辅助目标进行 Fine-tuning 不仅可以使监督模型更具泛化性,还可以加速收敛。于是我们有:
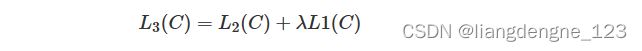
其中,λ为权重。
2.3 Task-specific input transformations
对于某些任务如文本分类等 word-level 的任务,我们可以像上述描述的方式来 Fine-tuning 模型;但是有些任务如问题回答等句子、句子对等结构化输入的任务需要稍作修改才能应用。
针对这种情况,作者提出了一种遍历式的方法(traversal-style),将结构化输入转换成预训练模型可以处理得有序序列。
对输入转换可以避免了兼容不同任务,防止对模型进行大量更改,所有的转换包括添加随机初始化的开始标记()和结束标记(

上图是对不同任务进行微调的输入转换。将所有的结构化输入转换为 Token 序列,然后使用预训练模型(Transformer)进行处理,最后使用线性和 Softmax 层完成特定的监督学习任务。
对于文本蕴涵(Text Entailment)来说,作者将前提 p 和假设 h 令牌序列连接起来,并使用分隔符($)分开。
文本蕴含是指两个文本片段有指向关系。当认为一个文本片段真实时,可以推断出另一个文本片断的真实性。也就是说一个文本片段蕴涵了另一个文本片段的知识,可以分别称蕴涵的文本为前提,被蕴涵的文本为假设。 ”
对于句子相似(Similarity)来说,为了消除两个句子之间的内在的顺序,作者以不同顺序合并了两个句子并以分隔符进行分割,然后独立地处理每一种顺序并得到两个句子的表征,对两个句子进行元素求和后送给 Linear 层。
对于问答和常识推理(Question Answering and Commonsense Reasoning)来说,有上下文文档 z 、问题 q 和可能答案的集合![]() ,作者将上下文和问题与每个可能的答案连接起来并在中间添加分隔符令牌
,作者将上下文和问题与每个可能的答案连接起来并在中间添加分隔符令牌![]()
。每个序列都将由模型独立处理,然后通过 Linear 层和 Softmax 层进,从而在可能的答案上产生一个输出分布。
3. Experinence
我们来简单看一下实验结果。
下图展示了推理任务的实验结果:
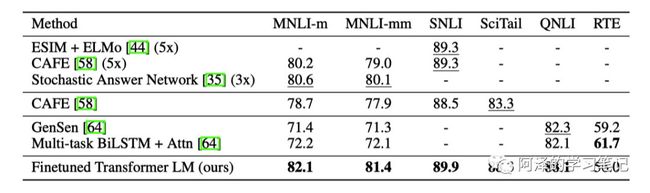
下图展示了问题回答和常识推理的实验结果:

下图展示了语义相似度和分类的实验结果:

下图左边展示的预训练语言模型中 Transformer 层数对结果的影响;右图展示了预训练不用 Fine-tuning 而直接使用预训练网络来解决多种类型任务的结果,横坐标为更新次数,纵坐标为模型相对表现:

4. Conclusion
总结:GPT 是一种半监督学习,采用两阶段任务模型,通过使用无监督的 Pre-training 和有监督的 Fine-tuning 来实现强大的自然语言理解。在 Pre-training 中采用了 12 层的修改过的 Transformer Decoder 结构,在 Fine-tuning 中会根据不同任务提出不同的分微调方式,从而达到适配各类 NLP 任务的目的
GPT 与 ELMo 有很多相似的地方,比如说都采用了预训练的方式,但是 ELMo 是针对某一任务定制了一个架构,而 GPT 的目的在于适配多种任务;此外 ELMo 使用了 2 层的双向的 LSTM 结构而 GPT 使用了 12 层单向的 Transformer Dncoder 结构,更大的深度也加强了模型的学习能力(ELMo 不是不想用更深的,而是再深的话就学不动了)。
5. References
- 《Improving Language Understanding by Generative Pre-Training》
- 《Improving Language Understanding with Unsupervised Learning》