Low-Light Image Enhancement with Normalizing Flow
基础理论知识点:
李宏毅flow-model: 参考博客、flow-model视频
Flow-model参考博客
3 Methodology
在本节中,首先介绍以往基于像素级重建损失的微光增强方法的局限性。然后,介绍了图2中我们的框架的总体范式。最后,我们提出的框架的两个组成部分分别说明。
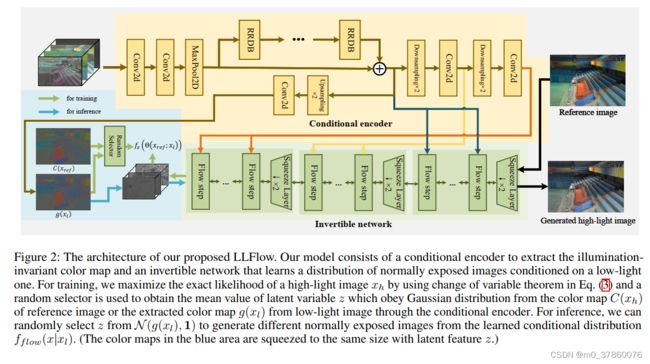
微光图像增强的目标是用微光图像 x l x_l xl生成具有正常曝光 x h x_h xh的高质量图像。配对样本 ( x l ; x r e f ) (x_l;x_{ref}) (xl;xref)通常通过最小化l1重构损失来训练模型Θ,方法如下:
a r g m i n R [ l 1 ( θ ( x l ) , x r e f ) ] = a r g m a x E [ l o g f ( θ ( x l ) ∣ x r e f ) ] argminR[l_1(\theta(x_l),x_{ref})] = argmaxE[logf(\theta(x_l)|x_{ref})] argminR[l1(θ(xl),xref)]=argmaxE[logf(θ(xl)∣xref)]
其中 Θ ( x l ) Θ(x_l) Θ(xl)是由模型生成的法线光图像,f是基于参考图像 x r e f x_{ref} xref的概率密度函数,定义如下:
f ( x ∣ x r e f ) = 1 2 b e x p ( − ∣ x − x r e f ∣ b ) f(x|x_{ref}) = \frac{1}{2b}exp(-\frac{\left| x - x_{ref}\right |}{b}) f(x∣xref)=2b1exp(−b∣x−xref∣)
其中b为与学习率相关的常数。然而,这种训练范式有一个局限性,即预定义的图像分布(如公式2中的分布)不够强,无法区分生成的真实正常曝光的图像和带有噪声或伪影的图像,如图1中的示例。

3.2 Framework
作者建议使用一种归一化流对正曝光图像的复杂分布进行建模,使正曝光图像的条件PDF(概率密度函数)可以表示为 f f l o w ( x ∣ x l ) f_{flow}(x|x_l) fflow(x∣xl)。更具体地说,一个条件归一化流Θ用于将弱光图像本身和/或其特征作为输入,并将正常暴露的图像x映射到与x具有相同维数的潜在代码z,例如 z = Θ ( x ; x l ) z = Θ(x;x_{l}) z=Θ(x;xl)。利用变分定理,可以得到 f f l o w ( x ∣ x l ) f_{flow}(x|x_l) fflow(x∣xl)与 f z ( z ) f_{z}(z) fz(z)之间的关系如下:
f f l o w ( x ∣ x l ) = f z ( Θ ( x r e f ; x l ) ) ∣ d e t ∂ Θ ∂ x r e f ( x r e f ; x l ) ∣ f_{flow}(x|x_l) = f_{z}(Θ(x_{ref};x_{l}))\left|det\frac{\partial Θ}{\partial x_{ref}}(x_{ref};x_{l}) \right| fflow(x∣xl)=fz(Θ(xref;xl))∣∣∣∣det∂xref∂Θ(xref;xl)∣∣∣∣
为了使模型更好地刻画高质量正常曝光图像的特性,我们采用极大似然估计方法对参数Θ进行估计。特别地,我们最小化负对数似然(NLL)而不是 l 1 l_{1} l1损失来训练模型。
L ( x l , x r e f ) = − l o g f f l o w ( x r e f ∣ x l ) = − l o g f z ( θ ( x r e f ; x l ) ) − ∑ n = 0 N − 1 l o g ∣ d e t ∂ θ n ∂ z n ( z n ; g n ( x l ) ) ∣ L(x_{l},x_{ref})=-logf_{flow}(x_{ref}|x_{l})=-logf_{z}(\theta(x_{ref};x_{l})) - \sum_{n=0}^{N-1} log\left| det\frac{\partial \theta^{n}}{\partial z^{n}}(z^n;g^n(x_{l})) \right| L(xl,xref)=−logfflow(xref∣xl)=−logfz(θ(xref;xl))−n=0∑N−1log∣∣∣∣det∂zn∂θn(zn;gn(xl))∣∣∣∣
其中可逆网络Θ分为N个可逆层序列{ θ 0 , θ 1 , . . . , θ N − 1 {\theta^0,\theta^1,...,\theta^{N-1}} θ0,θ1,...,θN−1}和 h i + 1 = θ i ( h i ; g i ( x l ) ) h^{i+1} = \theta^i(h^i;g^i(x_l)) hi+1=θi(hi;gi(xl))是层 θ i \theta^i θi (i范围为0到N-1)的输出, h 0 = x r e f h^0=x_{ref} h0=xref和 z = h N ⋅ g n ( x l ) z = h^N\cdot g^{n}(x_l) z=hN⋅gn(xl)是编码器g的潜在特征,与层 θ n \theta^n θn具有相容的形状。 f z f_z fz是潜在特征z的PDF。
总之,作者提出的框架包括两个组成部分:
- 编码器g,它以弱光图像 x l x_l xl作为输入和输出照明不变的彩色地图 g ( x l ) g(x_l) g(xl)(可以看作是受Retinex理论启发的反射率地图)
- 可逆网络,将正常曝光的图像映射到潜在代码z。
Encoder for illumination invariant color map(编码器g)
为了生成鲁棒的、高质量的光照不变的彩色地图,首先对输入图像进行处理以提取有用的特征,然后将提取的特征连接起来,作为由残差密集块(RRDB)构建的编码器的输入的一部分。各构件的可视化如图3所示,具体如下

一:输入数据
1)直方图均衡化图像 h ( x l ) h(x_l) h(xl):直方图均衡化,增加微光图像的全局对比度。直方图均衡化后的图像可以看作是一种更具有光照不变性的图像。通过将直方图均衡化图像作为网络输入的一部分,网络可以更好地处理太暗或太亮的区域。
2)颜色地图C(x):受Retinex理论的启发,我们提出对图像x的颜色地图计算如下:
C ( x ) = x m e a n c ( x ) C(x) = \frac{x}{mean_c(x)} C(x)=meanc(x)x
其中, m e a n c mean_c meanc计算RGB通道中每个像素的平均值。由微光图像和参考图像得到的彩色地图与经编码器 g g g微调后的彩色地图的对比如图4所示。可以看到,在不同光照下,颜色图 C ( x l ) C(x_l) C(xl)和 C ( x r e f ) C(x_ref) C(xref)在一定程度上是一致的,所以可以把它们看作是类似于反射率图的表示,在 C ( x l ) C(x_l) C(xl)中被强噪声降解。我们还可以发现,编码器g可以生成高质量的彩色地图,在一定程度上抑制了强噪声,并保留了颜色信息。

3)噪声映射 N ( x l ) N(x_l) N(xl):为了去除 C ( x l ) C(x_l) C(xl)中的噪声,我们估计了一个噪声映射 N ( x l ) N(x_l) N(xl),并将其作为注意映射输入编码器。对噪声图 N ( x l ) N(x_l) N(xl)估计如下:
N ( x ) = m a x ( a b s ( ∇ x C ( x ) ) , a b s ( ∇ y C ( x ) ) ) N(x) = max(abs(\nabla_xC(x)),abs(\nabla_yC(x))) N(x)=max(abs(∇xC(x)),abs(∇yC(x)))
其中 ∇ x \nabla_x ∇x、 ∇ y \nabla_y ∇y为x、y方向上的梯度图,其中 m a x ( x , y ) max(x,y) max(x,y)是在像素通道级别返回x和y之间的最大值的操作。
二:模型结构
由输入数据所属,作者将原图 x l x_l xl, h ( x l ) h(x_l) h(xl)和 N ( x l ) N(x_l) N(xl)进行通道合并输入至g中。
g的模型结构如图:

Invertible network
与编码器学习一对一映射来提取可视为物体固有不变属性的光照不变颜色映射不同,可逆网络旨在学习一对多关系,因为对于相同的场景,光照可能是不同的。我们的可逆网络由三层组成,每层有一个挤压层和12个流动步骤。
根据我们的假设,归一化流旨在学习正常曝光的图像的条件分布,以微光图像/光照不变的颜色映射为条件,归一化流应该在g(xl)和C(xref)上都工作良好,因为这两个映射预计是相似的。
根据作者的假设,归一化流旨在学习正常曝光的图像的条件分布,以微光图像/光照不变的颜色映射为条件,归一化流应该在 g ( x l ) g(x_l) g(xl)和 C ( x r e f ) C(x_{ref}) C(xref)上都工作良好,因为这两个映射预计是相似的。为此,我们对整个框架(包括编码器和可逆网络)进行如下训练:
L ( x l , x r e f ) = − l o g f z ( θ ( x r e f ; x l ) ) − ∑ n = 0 N − 1 l o g ∣ d e t ∂ θ n ∂ z n ( z n ; g n ( x l ) ) ∣ L(x_l,x_{ref})=-logf_z(\theta(x_{ref};x_l)) - \sum_{n=0}^{N-1} log \left| det\frac{\partial \theta^{n}}{\partial z^{n}}(z^n;g^n(x_{l})) \right| L(xl,xref)=−logfz(θ(xref;xl))−n=0∑N−1log∣∣∣∣det∂zn∂θn(zn;gn(xl))∣∣∣∣
其中 f z f_z fz是潜在特征z的PDF,定义如下:
f z ( z ) = 1 2 π e x p ( − ( x − r ( C ( x r e f ) , g ( x l ) ) 2 2 ) f_z(z) = \frac{1}{\sqrt{2\pi}}exp(\frac{-(x-r(C(x_ref),g(x_l))^2}{2}) fz(z)=2π1exp(2−(x−r(C(xref),g(xl))2)
r ( a , b ) r(a,b) r(a,b)是一个随机选择函数,定义如下
r ( a , b ) = { a , α > p b , α ≤ p , p ∼ U ( 0 , 1 ) r(a,b)=\left\{ \begin{aligned} a ,\alpha>p\\ b ,\alpha \le p\\ \end{aligned} ,p \sim U(0,1) \right. r(a,b)={a,α>pb,α≤p,p∼U(0,1)
其中p为超参数,所有实验均设p为0.2。如图4所示,即使没有像素重建损失的帮助,编码器g也可以学习到与参考图像相似的颜色地图。
利用微光图像生成正常曝光的图像,首先将微光图像通过编码器提取彩色地图 g ( x l ) g(x_l) g(xl),然后利用编码器的潜在特征作为网络可逆的条件。对于z的抽样策略,可以从 N ( g ( x L ) , 1 ) N(g(x_L),1) N(g(xL),1)分布中随机选择z的一个批次;1)获得不同的输出,然后计算生成的正常曝光图像的平均值,以获得更好的性能。为了加快推理的速度,我们直接选择 g ( x l ) g(x_l) g(xl)作为输入z,我们的经验发现它可以达到足够好的结果。所以对于所有的实验,如果没有指定的话,我们只使用平均值g(x_l)作为条件归一化流的潜在特征z。
总结
未完。。。