分享一个600块钱的Python私活单,金融Excel数据清洗
分享一个今年一月份接的一个价值600元的Python数据清洗的金融数据私单,细节确实是接单以来最为复杂的一个案例。废话不多说,给大家分享下整个案例的需求和实现过程。
【业务需求】
首先是客户提供给我11个表格,这些表格的数据大体相似,但是具体细节每个表格都不一样,因此在具体处理时,需要挨个验证如何实现目标。
最终输出表格样式:
所有的原始数据表格经过处理,都要产出相同的三个表格,格式如下:
表1:
表2:
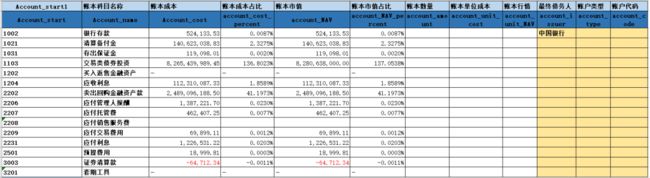
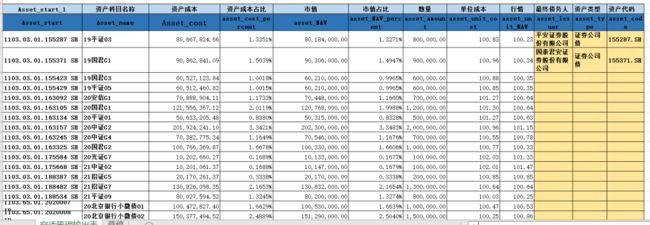
表3:
【代码实现分析】
结果表分析:
对于最终输出结果表1,2因为字段固定,因此我的策略就是这两个表格只要在原始数据中提取对应的数据即可,而表3因为数据时灵活多样的,但是它们的共同规律时资产编码均已1103开头,且《单位成本》列不能为0或者空,因此可以通过这两个条件进行定位。
原始数据表分析
以输入1原始数据表为例,表1,2中的汇总数据主要在《科目代码》这列里面,而表3的具体证券名称和金额在《科目名称》和《市值》《市值占比》等数据列

【代码实现】
我将所有需要用的数据路径放在了第一个代码块:
#文件路径
final_form = Path(r'D:\Working\私活\数据清洗\21-12-30表格清洗需求\穿透管理输出表v3终版.xlsx')
folder_path = Path(r'D:\Working\私活\数据清洗\21-12-30表格清洗需求\输入结果')
qiong_form = Path(r'D:\Working\私活\数据清洗\基金穷举v4.xlsx')
由于结果表格式固定,我将它们全部提取出来,并做了相应的预处理,表1,表2保留需要的字段,不需要的数据项全部设置为空值NaN,表3基本只能保留表头:
# 提前读取输出结果的三个表,用于填充数据
df_final1 = pd.read_excel(final_form,header=[0,1]).iloc[:19,:6]
df_final2 = pd.read_excel(final_form,header=[22,23]).iloc[:16,:]
df_final3 = pd.read_excel(final_form,header=[41,42])
然后读取原始数据表,通过pathlib读取文件夹路径下的所有excel表格,然后根据数据开始的行、列将每个原始数据表格限定为一个dataframe对象
#读取各表数据
file_list = folder_path.glob('输入*.xls')
pathlist = list(file_list)
df1 = pd.read_excel(pathlist[2],header=4).iloc[1:,:]
df2 = pd.read_excel(pathlist[3],header=4).iloc[2:,:]
df3 = pd.read_excel(pathlist[4],header=1)
df4 = pd.read_excel(pathlist[5],header=3)
df4 = df4.drop(index=[df4.shape[0]-1,df4.shape[0]-2])
df5 = pd.read_excel(pathlist[6],header=4).iloc[2:,:]
df6 = pd.read_excel(pathlist[7],header=4).iloc[2:,:]
df7 = pd.read_excel(pathlist[8],header=3)
df7 = df7.drop(index=df7.shape[0]-1)
df9 = pd.read_excel(pathlist[9],header=3)
df10 = pd.read_excel(pathlist[0],header=3).iloc[1:,:]
df11 = pd.read_excel(pathlist[1],header=3).iloc[1:,:]
接下来就是根据11个表的共同特征生成4个相同的数据清洗方法,用于处理结果表1,2:
清洗方法1:
def data_wash1(df_form,df_final,ori_col,form_col,form_col_eng,capital1,capitalP,value1,valueP,s_value):
l = []
y = []
j = []
q = []
z = []
for i in range(df_final.shape[0]):
df2 = df_form[df_form[ori_col]==df_final.loc[i,form_col][form_col_eng]]
if i<5:
list1 = df2[capital1].tolist()
if len(list1)==0:
list1.append(np.nan)
list2 = df2[capitalP].tolist()
if len(list2)==0:
list2.append(np.nan)
list3 = df2[value1].tolist()
if len(list3)==0:
list3.append(np.nan)
list4 = df2[valueP].tolist()
if len(list4)==0:
list4.append(np.nan)
l.append(list1[0])
y.append(list2[0])
j.append(list3[0])
q.append(list4[0])
if i >=5:
list5 = df2[s_value].tolist()
if len(list5)==0:
list5.append(np.nan)
z.append(list5[0])
return l,y,j,q,z
清洗方法2:
def data_wash2(df_form,df_final,ori_col,form_col,form_col_eng,capital1,capitalP,value1,valueP):
l = []
y = []
j = []
q = []
for i in range(df_final.shape[0]):
df2 = df_form[df_form[ori_col]==df_final.loc[i,form_col][form_col_eng]]
list1 = df2[capital1].tolist()
if len(list1)==0:
list1.append(np.nan)
list2 = df2[capitalP].tolist()
if len(list2)==0:
list2.append(np.nan)
list3 = df2[value1].tolist()
if len(list3)==0:
list3.append(np.nan)
list4 = df2[valueP].tolist()
if len(list4)==0:
list4.append(np.nan)
l.append(list1[0])
y.append(list2[0])
j.append(list3[0])
q.append(list4[0])
return l,y,j,q
清洗方法3:
def data_wash3(df_form,df_final,ori_col,form_col,form_col_eng,capital1,capitalP,value1,valueP,s_value):
l = []
y = []
j = []
q = []
z = []
df_form[ori_col] = df_form[ori_col].str.replace(':','')
for i in range(df_final.shape[0]):
df2 = df_form[df_form[ori_col]==df_final.loc[i,form_col][form_col_eng]]
if i<5:
list1 = df2[capital1].tolist()
if len(list1)==0:
list1.append(np.nan)
if capitalP.find('%')!=-1:
list2 = (df2[capitalP]*0.01).tolist()
if len(list2)==0:
list2.append(np.nan)
else:
list2 = df2[capitalP].tolist()
if len(list2)==0:
list2.append(np.nan)
list3 = df2[value1].tolist()
if len(list3)==0:
list3.append(np.nan)
if valueP.find('%')!=-1:
list4 = (df2[valueP]*0.01).tolist()
if len(list4)==0:
list4.append(np.nan)
else:
list4 = df2[valueP].tolist()
if len(list4)==0:
list4.append(np.nan)
l.append(list1[0])
y.append(list2[0])
j.append(list3[0])
q.append(list4[0])
if i >=5:
list5 = df2[s_value].tolist()
if len(list5)==0:
list5.append(np.nan)
z.append(list5[0])
return l,y,j,q,z
清洗方法4:
def data_wash4(df_form,df_final,ori_col,form_col,form_col_eng,capital1,capitalP,value1,valueP):
l = []
y = []
j = []
q = []
df_form[ori_col] = df_form[ori_col].str.replace(':','')
for i in range(df_final.shape[0]):
df2 = df_form[df_form[ori_col]==df_final.loc[i,form_col][form_col_eng]]
list1 = df2[capital1].tolist()
if len(list1)==0:
list1.append(np.nan)
if capitalP.find('%')!=-1:
list2 = (df2[capitalP]*0.01).tolist()
if len(list2)==0:
list2.append(np.nan)
else:
list2 = df2[capitalP].tolist()
if len(list2)==0:
list2.append(np.nan)
list3 = df2[value1].tolist()
if len(list3)==0:
list3.append(np.nan)
if valueP.find('%')!=-1:
list4 = (df2[valueP]*0.01).tolist()
if len(list4)==0:
list4.append(np.nan)
else:
list4 = df2[valueP].tolist()
if len(list4)==0:
list4.append(np.nan)
l.append(list1[0])
y.append(list2[0])
j.append(list3[0])
q.append(list4[0])
return l,y,j,q
清洗方法主要使用的是list表,主要是新改版的pandas似乎在数据提取方面不是很自如,比如通过df[‘列名’]=‘new_value’修改字段数据并不能达到预期,因此我改用列表来处理,虽然有点麻烦,但是结果还是比较准确的。
接下来就是依次处理每个表格的具体清洗函数,这里不做全部代码的呈现,给大家看表格1和表格2的处理函数吧:
《输入1》
def df_form1(df1,df_final1,df_final2,df_final3):
df_deal= df1[df1['科目代码'].str.startswith('1103')&df1['单位成本'].notnull()]
df_deal.reset_index(drop=True,inplace=True)
df_final3.iloc[:,:]=np.nan
df_final3.drop(index=range(df_deal.shape[0],df_final3.shape[0]),axis=0,inplace=True)
df_final3['Asset_start_1']=df_deal['科目代码']
df_final3['资产科目名称']=df_deal['科目名称']
df_final3['资产成本']=df_deal['成本']
df_final3['资产成本占比']=df_deal['成本占比']
df_final3['市值']=df_deal['市值']
df_final3['市值占比']=df_deal['市值占比']
df_final3['数量']=df_deal['数量']
df_final3['单位成本']=df_deal['单位成本']
df_final3['行情']=df_deal['行情']
df_final3.fillna('NA',inplace=True)
df_final3 = df_final3.append({('Asset_start_1','Asset_start'):'Asset_End',('资产科目名称','Asset_name'):'NA',('资产成本','Asset_cost'):'NA',('资产成本占比','asset_cost_percent'):'NA',('市值','asset_NAV'):'NA',('市值占比','asset_NAV_percent'):'NA',('数量','asset_amount'):'NA',('单位成本','asset_unit_cost'):'NA',('行情','asset_unit_NAV'):'NA',('最终债务人','asset_issuer'):'NA',('资产类型','asset_type'):'NA',('资产代码','asset_code'):'NA'},ignore_index=True)
#读取穷举表对应1表,并修改为结果表项目名称
qiong_std1 = pd.read_excel(qiong_form,usecols='A:B',header=2).iloc[:16,:]
qiong_std2 = pd.read_excel(qiong_form,usecols='A:B',header=19)
qiong_std2 = qiong_std2.reset_index()
df_qiong1 = pd.read_excel(qiong_form,usecols='D:E',header=2).iloc[:16,:]
df_qiong2 = pd.read_excel(qiong_form,usecols='D:E',header=19)
df_qiong2 = df_qiong2.reset_index()
df_qiong2.rename({'(二)基金信息.1':"科目代码"},inplace=True,axis=1)
# 处理科目名称
for i in range(1,df1.shape[0]):
if df1.loc[i,'科目名称'] in list(df_qiong1['科目名称.1']):
index1 = list(df_qiong1['科目名称.1']).index(df1.loc[i,'科目名称'])
df1.loc[i,'科目名称'] = list(qiong_std1['科目名称'])[index1]
#处理科目代码
df_qiong2.dropna(inplace=True)
for i in range(1,df1.shape[0]):
if df1.loc[i,'科目代码'] in list(df_qiong2['科目代码']):
index1 = list(df_qiong2['科目代码']).index(df1.loc[i,'科目代码'])
df1.loc[i,'科目代码'] = list(qiong_std2['Unnamed: 1'])[index1]
#处理表1
df_final1.loc[:4,('基金成本','Fund_cost')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[0]
df_final1.loc[:4,('基金成本占比','fund_cost_percent')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[1]
df_final1.loc[:4,('基金市值','fund_NAV')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[2]
df_final1.loc[:4,('基金市值占比','fund_NAV_percent')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[3]
df_final1.loc[5:,('基金成本','Fund_cost')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[4]
df_final1.loc[5:,('基金成本占比','fund_cost_percent')]='NA'
df_final1.loc[5:,('基金市值','fund_NAV')]='NA'
df_final1.loc[5:,('基金市值占比','fund_NAV_percent')]='NA'
df_final1.fillna('NA',inplace=True)
#处理表2
df_final2['账本成本'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比',)[0]
df_final2['账本成本占比'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比')[1]
df_final2['账本市值'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比')[2]
df_final2['账本市值占比'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比')[3]
df_final2.iloc[:,6:12] = np.nan
df_final2.fillna('NA',inplace=True)
#输出
app = xw.App(visible=False,add_book=False)
wb = app.books.add()
wb.sheets[0].range('A1').value = df_final1
wb.sheets[0].range(f'A{df_final1.shape[0]+4}').value = df_final2
wb.sheets[0].range(f'A{df_final1.shape[0]+4+df_final2.shape[0]+3}').value = df_final3
wb.sheets[0].range('A:A').delete()
wb.sheets[0].range('A1').expand('table').autofit()
wb.save('res_form1.xlsx')
wb.close()
app.quit()
主要是需要调整各个字段的具体设置,比如有%的字段,你需要将该字段的数值乘以0.01才能是最终结果。
《输入2》:
def df_form2(df2,df_final1,df_final2,df_final3):
#生成表3
df_deal= df2[df2['科目代码'].str.startswith('1103')&df2['单位成本'].notnull()]
df_deal.reset_index(drop=True,inplace=True)
df_final3.iloc[:,:]=np.nan
df_final3.drop(index=range(df_deal.shape[0],df_final3.shape[0]),axis=0,inplace=True)
df_final3['Asset_start_1']=df_deal['科目代码']
df_final3['资产科目名称']=df_deal['科目名称']
df_final3['资产成本']=df_deal['成本']
df_final3['资产成本占比']=df_deal['成本占比']
df_final3['市值']=df_deal['市值']
df_final3['市值占比']=df_deal['市值占比']
df_final3['数量']=df_deal['数量']
df_final3['单位成本']=df_deal['单位成本']
df_final3['行情']=df_deal['行情']
df_final3.fillna('NA',inplace=True)
df_final3 = df_final3.append({('Asset_start_1','Asset_start'):'Asset_End',('资产科目名称','Asset_name'):'NA',('资产成本','Asset_cost'):'NA',('资产成本占比','asset_cost_percent'):'NA',('市值','asset_NAV'):'NA',('市值占比','asset_NAV_percent'):'NA',('数量','asset_amount'):'NA',('单位成本','asset_unit_cost'):'NA',('行情','asset_unit_NAV'):'NA',('最终债务人','asset_issuer'):'NA',('资产类型','asset_type'):'NA',('资产代码','asset_code'):'NA'},ignore_index=True)
#读取穷举表对应1表,并修改为结果表项目名称
qiong_std1 = pd.read_excel(qiong_form,usecols='A:B',header=2).iloc[:16,:]
qiong_std2 = pd.read_excel(qiong_form,usecols='A:B',header=19)
qiong_std2 = qiong_std2.reset_index()
df_qiong1 = pd.read_excel(qiong_form,usecols='G:H',header=2).iloc[:16,:]
df_qiong2 = pd.read_excel(qiong_form,usecols='G:H',header=19)
df_qiong2 = df_qiong2.reset_index()
df_qiong2.rename({'(二)基金信息.2':"科目代码"},inplace=True,axis=1)
# 处理科目名称
for i in range(2,df2.shape[0]+2):
if df2.loc[i,'科目名称'] in list(df_qiong1['科目名称.2']):
index1 = list(df_qiong1['科目名称.2']).index(df2.loc[i,'科目名称'])
df2.loc[i,'科目名称'] = list(qiong_std1['科目名称'])[index1]
#处理科目代码
df_qiong2.dropna(inplace=True)
for i in range(2,df2.shape[0]+2):
if df2.loc[i,'科目代码'] in list(df_qiong2['科目代码']):
index1 = list(df_qiong2['科目代码']).index(df2.loc[i,'科目代码'])
df2.loc[i,'科目代码'] = list(qiong_std2['Unnamed: 1'])[index1]
#生成表1
df_final1.loc[:4,('基金成本','Fund_cost')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[0]
df_final1.loc[:4,('基金成本占比','fund_cost_percent')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[1]
df_final1.loc[:4,('基金市值','fund_NAV')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[2]
df_final1.loc[:4,('基金市值占比','fund_NAV_percent')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[3]
df_final1.loc[5:,('基金成本','Fund_cost')]=data_wash1(df1,df_final1,'科目代码','基金科目名称','Fund_subject','成本','成本占比','市值','市值占比','科目名称')[4]
df_final1.loc[5:,('基金成本占比','fund_cost_percent')]='NA'
df_final1.loc[5:,('基金市值','fund_NAV')]='NA'
df_final1.loc[5:,('基金市值占比','fund_NAV_percent')]='NA'
df_final1.fillna('NA',inplace=True)
#生成表2
df_final2['账本成本'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比')[0]
df_final2['账本成本占比'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比')[1]
df_final2['账本市值'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比')[2]
df_final2['账本市值占比'] = data_wash2(df1,df_final2,'科目名称','账本科目名称','Account_name','成本','成本占比','市值','市值占比')[3]
df_final2.iloc[:,6:12] = np.nan
df_final2.fillna('NA',inplace=True)
#写入文件
app = xw.App(visible=False,add_book=False)
wb = app.books.add()
wb.sheets[0].range('A1').value = df_final1
wb.sheets[0].range(f'A{df_final1.shape[0]+4}').value = df_final2
wb.sheets[0].range(f'A{df_final1.shape[0]+4+df_final2.shape[0]+3}').value = df_final3
wb.sheets[0].range('A:A').delete()
wb.sheets[0].range('A1').expand('table').autofit()
wb.save('res_form2.xlsx')
wb.close()
app.quit()
生成完所有表格的函数后,就可以调用对应的函数来生成对应表格的最终结果集了:
df_form1(df1,df_final1,df_final2,df_final3)
# df_form2(df2,df_final1,df_final2,df_final3)
# df_form3(df3,df_final1,df_final2,df_final3)
# df_form4(df4,df_final1,df_final2,df_final3)
# df_form5(df5,df_final1,df_final2,df_final3)
# df_form6(df6,df_final1,df_final2,df_final3)
# df_form7(df7,df_final1,df_final2,df_final3)
# df_form9(df9,df_final1,df_final2,df_final3)
# df_form10(df10,df_final1,df_final2,df_final3)
# df_form11(df11,df_final1,df_final2,df_final3)
这里做了一个简单的注释,如果需要那个表格,只需要取消注释,运行该行代码就会生成对应列表的结果集了。
学习资源推荐
学习资源是学习质量和速度的保证,因此找到高质量的学习资源对我们来说也是非常重要的。以下列出的学习资源不分排名,都是好资源:
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。
四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。
四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码【免费获取】。
