PySpark(三)RDD持久化、共享变量、Spark内核制度,Spark Shuffle
目录
RDD持久化
RDD 的数据是过程数据
RDD 缓存
RDD CheckPoint
共享变量
广播变量
累加器
Spark 内核调度
DAG
DAG 的宽窄依赖和阶段划分
内存迭代计算
Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用?
Spark为什么比MapReduce快?
Spark并行度
Spark Shuffle
Hash Shuffle
Sort Shuffle
RDD持久化
RDD 的数据是过程数据
RDD之间进行相互迭代计算(Transformation的转换),当执行开启后,新RDD的生成,代表老RDD的消失
RDD的数据是过程数据,只在处理的过程中存在,一旦处理完成,就不见了
这个特性可以最大化的利用资源,老旧RDD没用了 就从内存中清理,给后续的计算腾出内存空间.
例如下面这个例子,生成rdd4的时候, rdd3已经被销毁了,然后下面rdd5需要调用rdd3的时候,只能从rdd->rdd2->rdd3再重新生成一次rdd3
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)
rdd2 = rdd.map(lambda x:(x[0],x[1]+2))
rdd3 = rdd2.distinct()
rdd4 = rdd3.filter(lambda x:x[1]>5)
print(rdd4.collect())
# [('a', 8)]
rdd5 = rdd3.glom()
print(rdd5.collect())
# [[('a', 5), ('a', 8)], [('a', 3), ('b', 4)], [('b', 3), ('c', 3)]]RDD 缓存
RDD的缓存技术:Spark提供了缓存AP1,可以让我们通过调用AP1,将指定的RDD数据保留在内存或者硬盘上缓存的API
最开始要引入:from pyspark.storagelevel import StorageLevel

缓存技术可以将过程RDD数据,持久化保存到内存或者硬盘上
但是,这个保存在设定上是认为不安全的,缓存的数据在设计上是 认为 有丢失风险的
所以,缓存有一个特点就是: 其保留RDD之间的血缘(依赖)关系
一旦缓存丢失可以基于血缘关系的记录重新计算这个RDD的数据
缓存如何丢失:
在内存中的缓存是不安全的,比如断电计算任务内存不足把缓存清理给计算让路硬盘中因为硬盘损坏也是可能丢失的
RDD缓存采用的是分散存储,也就是每一个executor都会将其处理的部分RDD存放在自己的内存或硬盘中
RDD CheckPoint
CheckPoint技术也是将RDD的数据保存起来,但是它仅支持硬盘存储
并且:它被设计认为是安全的,不保留 血缘关系
checkPoint存储RDD数据,是集中收集各个分区数据进行存储而缓存是分散存储,也就是说先将executor中的数据收集起来(比如收集到hdfs),然后再进行存储
缓存和CheckPoint的对比
- CheckPoint不管分区数量多少,风险是一样的,缓存分区越多,风险越高
- CheckPoint支持写入HDFS,缓存不行HDFS是高可靠存储,checkPoint被认为是安全的.
- checkPoint不支持内存缓存可以缓存如果写内存性能比checkPoint要好一些
- CheckPoint因为设计认为是安全的,所以不保留血缘关系,而缓存因为设计上认为不安全,所以保留
sc.setCheckpointDir("hdfs://node1:8020/checkpoint")
#设置存储位置
rdd = sc.parallelize([('a',1),('a',3),('a',6),('b',1),('b',2),('c',1)],3)
rdd2 = rdd.map(lambda x:(x[0],x[1]+2))
rdd3 = rdd2.distinct()
rdd3.checkpoint()共享变量
广播变量
假如有下面一个场景,需要根据stu_ifo将score_ifo中的数字替换为名字,注意这里是本地数据stu_ifo与RDD数据联合处理
stu_ifo = [(1,'lmx'),(2,'lby'),(3,'lxl')]
score_ifo = sc.parallelize([
(1,'math',100),
(2,'english',87),
(1,'english',80),
(3,'chinese',98),
(2, 'chinese', 68),
(1, 'chinese', 88)]
)
def func(data):
for i in stu_ifo:
if data[0] == i[0]:
return (i[1],data[1],data[2])
get = score_ifo.map(func)
print(get.collect())一般情况下, 如果一个executor里面有多个分区的情况,那么每个分区都要向driver申请一份本地数据,然而由于executor内部的数据是共享的,这样就会多申请了一份stu_ifo
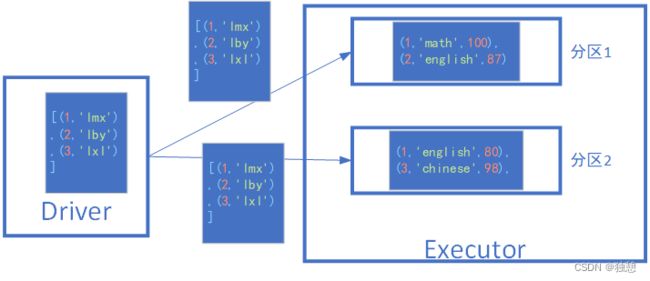
只需要将stu_ifo标记为广播变量,就可以解决这个问题。只会向一个executor发送一次数据
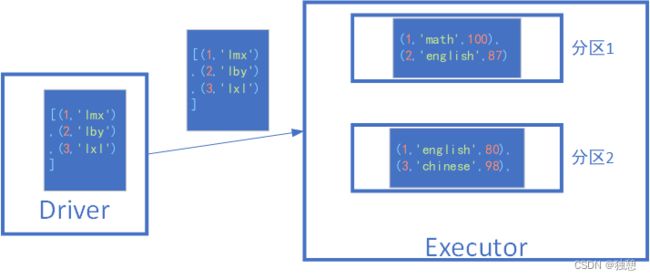
只需要在之前声明:
stu_if_breadcast = sc.broadcast(stu_ifo)然后使用的时候:
stu_if_breadcast.value使用这个方法,可以节省IO次数以及executor内存
上述代码变为:
stu_ifo = [(1,'lmx'),(2,'lby'),(3,'lxl')]
stu_if_breadcast = sc.broadcast(stu_ifo)
score_ifo = sc.parallelize([
(1,'math',100),
(2,'english',87),
(1,'english',80),
(3,'chinese',98),
(2, 'chinese', 68),
(1, 'chinese', 88)]
)
def func(data):
for i in stu_if_breadcast.value:
if data[0] == i[0]:
return (i[1],data[1],data[2])
get = score_ifo.map(func)
print(get.collect())累加器
针对下面这种场景,我希望每map一次,我的num加1:
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],2)
def countt(data):
global num
num+=1
print(num)
return data
print(rdd.map(countt).collect())
print(num)
# 1
# 2
# 3
# 4
# 5
# 1
# 2
# 3
# 4
# 5
# [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 0观察结果,由于分区的情况,在每个executor内num都加到了5,但是最后的num却还是0
因为加1操作只会发生在 executor 中,而最后打印的是driver中的num,所以还是0
这里可以使用spark的累加器变量:
num = sc.accumulator(0) #累加器
rdd = sc.parallelize([1,2,3,4,5,6,7,8,9,10],2)
def countt(data):
global num
num+=1
return data
rdd.map(countt).collect()
print(num)
# 10Spark 内核调度
DAG
DAG:有向无环图
在spark中,每一个 action算子都会将前面的一串rdd依赖链条执行起来,这些执行链条其实就是DAG
有多少个action算子,就有多少个执行链条(JOB),就有多少个DAG
如果一个代码中,写了n个Action,那么这个代码运行起来产生n个JOB,每个JOB有自己的DAG个代码运行起来,在Spark中称之为: Application
spark中数据都是分区的,所以实际上每一个job都是带有分区关系的DAG

DAG 的宽窄依赖和阶段划分
RDD的前后关系分为 宽依赖和窄依赖
窄依赖:父RDD的一个分区,全部 将数据发给子RDD的一个分区
宽依赖:父RDD的一个分区将数据发给子RDD的多个分区
宽依赖还有一个别名: shuffle
对于Spark来说会根据DAG,按照宽依赖划分不同的DAG阶段
划分依据:从后向前,遇到宽依赖 就划分出一个阶段称之为stage
 可以看到,在阶段内都是 窄依赖,这有助于构建内存迭代管道
可以看到,在阶段内都是 窄依赖,这有助于构建内存迭代管道
内存迭代计算
在执行上图的程序时,最优的方式肯定是task1,2,3,4,5,6都在独立且单独的线程中完成(还存在另外一种情况,比如b1->p1,p1->下一个p1是不同的线程,那可能会在线程中存在网络IO调用,影响性能)
task1 中rdd1rdd2 rdd3 的选代计算,都是由一个task(线程完成),这一阶段的这一条线,是纯内存计算.如上图,task1 task2 task3,就形成了三个并行的内存计算管道
Spark默认受到全局并行度的限制,除了个别算子有特殊分区情况,大部分的算子,都会遵循全局并行度的要求,来规划自己的分区数如果全局并行度是3,其实大部分算子分区都是3
注意:Spark一般推荐只设置全局并行度,不要再算子上设置并行度除了一些排序算子外,计算算子就让他默认开分区就可以了.
Spark是怎么做内存计算的? DAG的作用?Stage阶段划分的作用?
- Spark会产生DAG图
- DAG图会基于分区和宽窄依赖关系划分阶段
- 一个阶段的内部都是 窄依赖,窄依赖内,如果形成前后1:1的分区对应关系就可以产生许多内存选代计算的管道
- 这些内存迭代计算的管道,就是一个个具体的执行Task
- 一个Task是一个具体的线程,任务跑在一个线程内,就是走内存计算了
Spark为什么比MapReduce快?
- Spark的算子丰富,MapReduce算子匮乏(Map和Reduce),MapReduce这个编程模型,很难在一套MR中处理复杂的任务.很多的复杂任务,是需要写多个MapReduce进行串联多个MR串联通过磁盘交互数据
- Spark可以执行内存迭代,算子之间形成DAG 基于依赖划分阶段后,在阶段内形成内存选代管道.但是MapReduce的Map和Reduce之间的交互依旧是通过硬盘来交互的
Spark并行度
Spark的并行: 在同一时间内, 有多少个task在同时运行
并行度:并行能力的设置
比如设置并行度6,其实就是要6个task并行在跑在有了6个task并行的前提下,rdd的分区就被规划成6个分区了
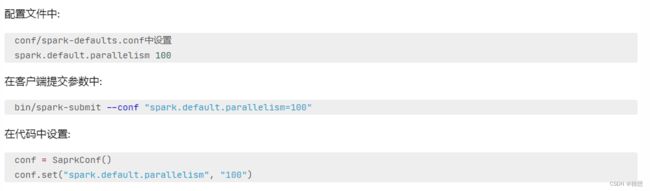
优先级从高到低:
代码中
客户端提交参数中
配置文件中
默认(1,但是不会全部以1来跑,多数时候基于读取文件的分片数量来作为默认并行度)
 集群如何规划并行度?
集群如何规划并行度?
结论:设置为CPU总核心的2~10倍
为什么要设置最少2倍?
CPU的一个核心同一时间只能干一件事情所以,在100个核心的情况下,设置100个并行,就能让CPU 100%出力这种设置下如果task的压力不均衡,某个task先执行完了就导致某个CPU核心空闲
所以,我们将Task(并行)分配的数量变多,比如800个并行,同一时间只有100个在运行,700个在等待.但是可以确保某个task运行完了.后续有task补上,不让cpu闲下来,最大程度利用集群的资源
Spark Shuffle
Spark在DAG调度阶段会将一个Job划分为多个Stage,上游Stage做map工作,下游Stage做reduce工作,其本质上 还是MapReduce计算框架。Shuffle是连接map和reduce之间的桥梁,它将map的输出对应到reduce输入中,涉及 到序列化反序列化、跨节点网络IO以及磁盘读写IO等。
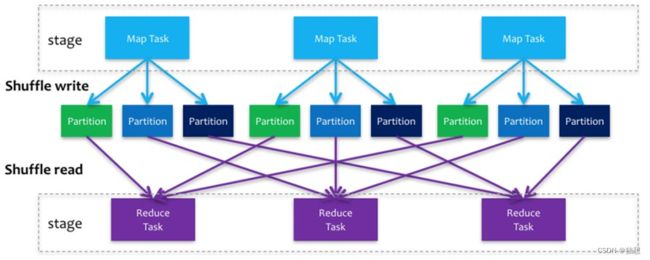
Spark的Shuffle分为Write和Read两个阶段,分属于两个不同的Stage,前者是Parent Stage的最后一步,后者是 Child Stage的第一步。
在Spark的中,负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。ShuffleManager随着 Spark的发展有两种实现的方式,分别为HashShuffleManager和SortShuffleManager,因此spark的Shuffle有Hash Shuffle和Sort Shuffle两种。
Hash Shuffle
未经优化的hashShuffleManager:
HashShuffle是根据task的计算结果的key值的hashcode%ReduceTask来决定放入哪一个区分,这样保证相同的数据 一定放入一个分区,根据下游的task决定生成几个文件,先生成缓冲区文件在写入磁盘文件,再将block文件进行合并。
一个task内部会根据hash分类,然后将不同类的数据放入不同的磁盘文件,未经优化的shuffle write操作所产生的磁盘文件的数量是极其惊人的,也就是下图所产生的的block file

优化的hashShuffleManager:
在shuffle write过程中,task就不是为下游stage的每个task创建一个磁盘文件了。此时会出现shuffleFileGroup的概 念,每个shuffleFileGroup会对应一批磁盘文件,每一个Group磁盘文件的数量与下游stage的task数量是相同的。
其实说到底就是其在executor内部就会进行数据的汇合操作,大大减少了磁盘文件的生成

Sort Shuffle
(1)该模式下,数据会先写入一个内存数据结构中(默认5M),此时根据不同的shuffle算子,可能选用不同的数据结构。如果是reduceByKey这种聚合类的shuffle算子,那么会选用Map数据结构,一边通过Map进行聚合,一边写入内 存;如果是join这种普通的shuffle算子,那么会选用Array数据结构,直接写入内存。
(2)接着,每写一条数据进入内存数据结构之后,就会判断一下,是否达到了某个临界阈值。如果达到临界阈值的话 ,那么就会尝试将内存数据结构中的数据溢写到磁盘,然后清空内存数据结构。
(3)排序 在溢写到磁盘文件之前,会先根据key对内存数据结构中已有的数据进行排序。 (4)溢写 排序过后,会分批将数据写入磁盘文件。默认的batch数量是10000条,也就是说,排序好的数据,会以每批1万条数 据的形式分批写入磁盘文件。
(5)merge 一个task将所有数据写入内存数据结构的过程中,会发生多次磁盘溢写操作,也就会产生多个临时文件。最后会将之 前所有的临时磁盘文件都进行合并成1个磁盘文件,这就是merge过程。 由于一个task就只对应一个磁盘文件,也就意味着该task为Reduce端的stage的task准备的数据都在这一个文件中, 因此还会单独写一份索引文件,其中标识了下游各个task的数据在文件中的start offset与end offset。
说到底最大的区别就是,一个task只会生成一个磁盘文件和一个索引文件,大大降低了磁盘占有和网络IO数量

Sort Shuffle bypass机制
bypass运行机制的触发条件如下:
1)shuffle map task数量小于spark.shuffle.sort.bypassMergeThreshold=200参数的值。
2)不是map combine聚合的shuffle算子(比如reduceByKey有map combie)(这种算子不需要排序)
此时task会为每个reduce端的task都创建一个临时磁盘文件,并将数据按key进行hash,然后根据key的hash值, 将key写入对应的磁盘文件之中。当然,写入磁盘文件时也是先写入内存缓冲,缓冲写满之后再溢写到磁盘文件的 。最后,同样会将所有临时磁盘文件都合并成一个磁盘文件,并创建一个单独的索引文件。
该过程的磁盘写机制其实跟未经优化的HashShuffleManager是一模一样的,因为都要创建数量惊人的磁盘文件, 只是在最后会做一个磁盘文件的合并而已。因此少量的最终磁盘文件,也让该机制相对未经优化的 HashShuffleManager来说,shuffle read的性能会更好。
而该机制与普通SortShuffleManager运行机制的不同在于:
第一,磁盘写机制不同;
第二,不会进行排序。也就是说,启用该机制的最大好处在于,shuffle write过程中,不需要进行数据的排序操作, 也就节省掉了这部分的性能开销。