MongoDB系列之WiredTiger引擎
概述
关系型数据库MySQL有InnoDB存储引擎,存储引擎很大程度上决定着数据库的性能。
在MongoDB早期版本中,默认使用MMapV1存储引擎,其索引就是一个B-树(也称B树)。
从MongoDB 3.0开始引入WiredTiger(以下简称WT)存储引擎,在性能及稳定性上都有明显的提升。从MongoDB 3.2开始,WT作为默认的引擎,在索引和集合的检索上借鉴B+树。
WT是一个优秀的单机数据库存储引擎,拥有诸多特性,支持BTree、LSM Tree索引,支持行存储和列存储,实现ACID级别事务、支持大到4G的记录。
现代计算机近20年来CPU的计算能力和内存容量飞速发展,但磁盘的访问速度并没有得到相应的提高,WT就是在这样的一个情况下研发出来,充分利用CPU并行计算的内存模型的无锁并行框架,使得WT引擎在多核CPU上的表现优于其他存储引擎。针对磁盘存储特性,WT实现一套基于BLOCK/Extent的磁盘友好访问算法,使得WT在数据压缩和磁盘I/O访问上优势明显。实现基于snapshot技术的ACID事务,snapshot技术大大简化WT的事务模型,摒弃传统的事务锁隔离又同时能保证事务的ACID。WT根据现代内存容量特性实现一种基于Hazard Pointer的LRU cache模型,充分利用内存容量的同时又能拥有很高的事务读写并发。
WiredTiger存储引擎在数据检索性能上做了许多优化,基于内存的二级的缓存提供高速读取数据能力,在写方面则是根据磁盘I/O的特点做缓冲式写入,这是基于空间、时间因素权衡的一种择优设计。
MongoDB在写入更新记录时使用基于version的乐观锁模式,当写冲突产生(尝试更新失败)时,WiredTiger内部会产生WT_ROLLBACK结果,MongoDB检测到该状态之后会抛出WriteConflictException,最终由写入的执行线程捕获该异常并重试。
WiredTiger对事务的支持同时包含:未提交读、提交读、快照一致性读。MongoDB事务采用快照一致性读。
原理
读缓存
理想情况下,MongoDB可提供近似内存式的读写性能。WiredTiger引擎实现数据的二级缓存,第一层是操作系统层级的页面缓存,第二层则是引擎提供的内部缓存:

读取数据时的流程:
- 数据库发起Buffer I/O读操作,由操作系统将磁盘数据页加载到文件系统的页缓存区
- 引擎层读取页缓存区的数据,进行解压后存放到内部缓存区
- 在内存中完成匹配查询,将结果返回给应用。
如果数据已经被存储在内部缓存中,MongoDB则可以发挥最佳的读性能。稍差的情况是内部缓存中找不到,但数据仍然被存储在操作系统的页缓存中,此时需要花费一些数据解压缩的开销。直接从磁盘加载数据时,性能是最差的。因此MongoDB为了尽可能保证业务查询的热点数据能快速被访问,其内部缓存的默认大小达到内存的一半,该值由wiredTigerCacheSize参数指定,其默认计算公式: w i r e d T i g e r C a c h e S i z e = M a t h . m a x ( ( R A M − 1 G B ) , 256 M B ) wiredTigerCacheSize=Math.max((RAM-1GB),256MB) wiredTigerCacheSize=Math.max((RAM−1GB),256MB)
写缓冲
当数据发生写入时,MongoDB并不会立即持久化到磁盘上,而是先在内存中记录这些变更,随后通过CheckPoint机制将变化的数据写入磁盘。即,非实时持久化。
采用延迟持久化方案,则避不开可靠性问题。
MongoDB单机下保证数据可靠性的机制包括以下两个部分:
- CheckPoint机制:快照(snapshot)描述某一时刻(point-in-time)数据在内存中的一致性视图,而这种数据的一致性是WiredTiger通过MVCC(多版本并发控制)实现的。当建立CheckPoint时,WiredTiger会在内存中建立所有数据的一致性快照,并将该快照覆盖的所有数据变化一并进行持久化(fsync)。成功之后,内存中数据的修改才得以真正保存。MongoDB默认每60s建立一次CheckPoint,在检查点写入过程中,上一个检查点仍然是可用的。这样可以保证一旦出错,仍能恢复到上一个检查点。
- Journal日志:一种预写式日志(write ahead log)机制,主要用来弥补CheckPoint机制的不足。如果开启Journal日志,那么WiredTiger会将每个写操作的redo日志写入Journal缓冲区,该缓冲区会频繁地将日志持久化到磁盘上。默认情况下,Journal缓冲区每100ms执行一次持久化。此外,Journal日志达到100MB,或是应用程序指定journal:true,写操作都会触发日志的持久化。一旦MongoDB发生宕机,重启程序时会先恢复到上一个检查点,然后根据Journal日志恢复增量的变化。由于Journal日志持久化的间隔非常短,数据能得到更高的保障,如果按照当前版本的默认配置,则其在断电情况下最多会丢失100ms的写入数据。
结合CheckPoint和Journal日志,数据写入的内部流程图:

步骤:
- 应用向MongoDB写入数据(插入、修改或删除)
- 数据库从内部缓存中获取当前记录所在的页块,如果不存在则会从磁盘中加载(Buffer I/O)
- WiredTiger开始执行写事务,修改的数据写入页块的一个更新记录表,此时原来的记录仍然保持不变
- 如果开启Journal日志,在写数据同时会写入一条Journal日志(Redo Log)。该日志在最长不超过100ms之后写入磁盘
- 数据库每隔60s执行一次CheckPoint操作,此时内存中的修改会真正刷入磁盘。
Journal日志采用的是顺序I/O写操作,频繁地写入对磁盘的影响并不是很大。在MongoDB 3.4及以下版本中,当Journal日志达到2GB时同样会触发CheckPoint行为。如果应用存在大量随机写入,则CheckPoint可能会造成磁盘I/O的抖动。在磁盘性能不足的情况下,问题会更加显著,此时适当缩短CheckPoint周期可以让写入平滑一些。
缓存页管理
WiredTiger仍然使用Page(页)作为数据存取的单元。其中,内存和磁盘中的页结构是不同的,Block Manager被用于处理这些差异。
页块在内存中以类B+树的结构进行组织,中间节点用于存放key,而叶子节点则存放key和value:
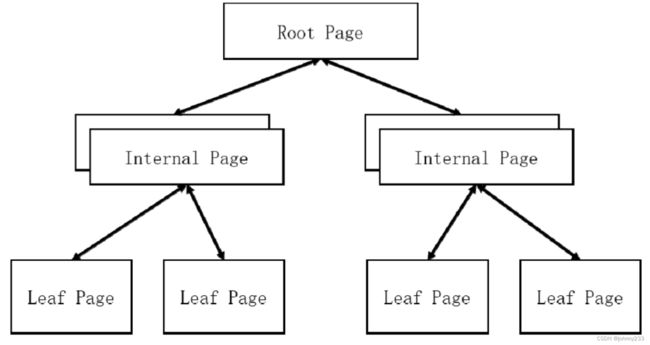
与传统B+树结构稍微不同的是,叶子节点(Leaf Page)通过父级指针(Parent Pointer)来实现范围遍历操作(避免并发写产生DeadLock)。当读取数据时,会先通过B+树索引找到对应的叶节点页面,而在页内则使用二分查找来查找记录。
当叶节点产生数据写入时,这些更新记录会被写入节点的一块独立区域,此时该节点被标记为脏页:

Inserts和Updates是单独的跳跃表(skiplist)结构,分别存放插入和修改操作,删除操作也被认为是一种修改(状态变更为删除)。如果存在修改,则读取时还会从跳跃表中做合并查找。
在CheckPoint时,引擎会通过Block Manager发起Reconciliation过程。此时,CheckPoint线程会遍历内存中的全部页并找到所有的脏页进行持久化,为了不阻塞读,使用Copy-On-Write方式。
对于脏页的处理并不是就地更新,而是为需要变更的页块生成新的节点(包括其父级节点),每次CheckPoint都会产生一个新的根节点(Root Page)。当持久化工作完成后,由这个新的根节点接管操作,淘汰不用的节点。
CheckPoint时,WiredTiger需要将BTree修改过的PAGE都进行持久化存储,每个BTree对应磁盘上一个物理文件,BTree的每个PAGE以文件里的extent形式(由文件offset + size标识)存储,一个CheckPoint包含如下元数据:
- root page地址:地址由文件offset,size及内容的checksum组成
- alloc extent list地址:存储从上次checkpoint起新分配的extent列表
- discard extent list地址:存储从上次checkpoint起丢弃的extent列表
- available extent list地址:存储可分配的extent列表,只有最新的CheckPoint包含该列表
- file size:如需恢复到该CheckPoint状态,将文件truncate到file size即可
在Reconciliation过程中,BlockManager需要将内存中的页块转换为磁盘上的页,内存页要比磁盘页大一些:
- memory_page_max:内部缓存页大小的最大值,默认是5MB
- internal_page_max:磁盘中间页大小的最大值,默认是4KB
- leaf_page_max:磁盘叶节点页大小的最大值,默认是32KB
- allocation_size:磁盘文件的存储单元,默认是4KB,internal_page_max、leaf_page_max必须是它的整数倍
其中,memory_page_max的取值会影响写入延迟。这个值如果太小,则会导致频繁地分裂和淘汰(阻塞写入),如果太大则会导致每次产生阻塞的时间变长。internal_page_max存储的是B+树的索引,因此它会影响树的深度。在需要大量扫描磁盘记录的场景中leaf_page_max需要加大,可减少I/O次数,而在特别关注读写时延的场景中则需要适当减小。allocation_size则需要与操作系统的页缓存大小对齐,以达到最好的效率。
触发Reconciliation的条件:
- CheckPoint
- 缓存中的页超过最大值(存在大量的修改),产生分裂,此时会触发evict命令并持久化
- 缓存中的脏数据比例达到一定阈值,触发缓存淘汰(evict)。
缓存淘汰策略
WiredTiger基于LRU算法来实现缓存淘汰,常态下会由后台的evict线程来负责淘汰页面。如果内存非常紧张,则用户线程也会加入缓存淘汰的工作中,此时表现出读写请求有一定阻塞。WiredTiger存储引擎eviction策略的4个可配置参数:
| 参数 | 默认值 | 解释 |
|---|---|---|
| eviction_target | 80 | 当cache used超过eviction_target时,后台evict线程开始淘汰Clean Page |
| eviction_trigger | 95 | 当cache used超过eviction_trigger时,用户线程也开始淘汰Clean Page |
| eviction_dirty_target | 5 | 当cache dirty超过eviction_dirty_target时,后台evict线程开始淘汰Dirty Page |
| eviction_dirty_trigger | 20 | 当cache dirty超过eviction_dirty_trigger时,用户线程也开始淘汰Dirty Page |
数据
里一个典型的WiredTiger数据库存储布局大致如下:
$tree
.
├── journal
│ ├── WiredTigerLog.0000000003
│ └── WiredTigerPreplog.0000000001
├── WiredTiger
├── WiredTiger.basecfg
├── WiredTiger.lock
├── WiredTiger.turtle
├── admin
│ ├── table1.wt
│ └── table2.wt
├── local
│ ├── table1.wt
│ └── table2.wt
└── WiredTiger.wt
文件解释:
WiredTiger.basecfg:存储基本配置信息WiredTiger.lock:用于防止多个进程连接同一个WiredTiger数据库table*.wt:存储各个tale(数据库中的表)的数据WiredTiger.wt:特殊Table,用于存储所有其他Table的元数据信息WiredTiger.turtle:存储WiredTiger.wt的元数据信息journal:存储Write ahead log
压缩
默认情况下,WiredTiger对集合使用块压缩,对索引使用前缀压缩。当页面被写入磁盘时执行压缩,而从磁盘中读入缓存时对页面进行解压。持久化的Journal日志也会采用Snappy压缩算法(块压缩的一种)
内部缓存和磁盘中的数据有着不同的格式:
- 磁盘中的数据和文件系统的缓存是一致的,这些都是经过压缩的。文件系统缓存是操作系统层的机制,这是为了减少磁盘I/O而做出的优化
- 集合数据在内部缓存中是未经过压缩的(方便直接读写),而在磁盘和页缓存中则保持压缩的格式
- 索引在磁盘和页面缓存中均保持前缀压缩的形态,其在内部缓存中是另外一种结构,但同样利用前缀压缩算法
参数
storage.journal.commitIntervalMs:Journal日志的刷新周期。3.4及以下版本默认值50ms,3.6版本之后调整到100msstorage.syncPeriodSecs:CheckPoint刷新周期,默认60s。storage.wiredTiger.collectionConfig.blockCompressor:用于指定集合数据的压缩算法,选项如下:- None:不启用压缩
- Snappy:默认,谷歌开源的强大而稳定的压缩算法,最高可达30%以下的压缩比,性价比较好
- Zlib:相比Snappy来说压缩率更好,但需要消耗更多的CPU
- Zstd:Facebook提供的新型高速压缩算法,能以较低的CPU消耗实现更高的压缩比。MongoDB 4.2版本开始支持
storage.wiredTiger.indexConfig.prefixCompression:用于指定是否启用索引前缀压缩(key prefix compression),默认true。前缀压缩对于CPU的消耗很小,平均可达到近50%的压缩率。
参考
- MongoDB进阶与实战:微服务整合、性能优化、架构管理
- https://mongoing.com/archives/5367