Hadoop2的HA安装(high availability):nfs+zookeeper
前面介绍过hadoop的简单安装和FA安装,在这里将介绍几种hadoop2中HA(高可用性)安装,HA技术使hadoop不再存在单点namenode的故障。
先来第一种:nfs+zookeeper
Hadoop 版本:2.2.0
OS 版本: Centos6.4
Jdk 版本: jdk1.6.0_32
环境配置
| 机器名 |
Ip地址 |
功能 |
| Hadoop1 |
192.168.124.135 |
NameNode, DataNode, ResourceManager, NodeManager Zookeeper Zkfc |
| Hadoop2 |
192.168.124.136 |
NameNode DataNode, NodeManager Zookeeper Zkfc |
| Hadoop3 |
192.168.124.137 |
DataNode, NodeManager Zookeeper Zkfc Nfs server |
安装zookeeper
使用 FileZilla上传zookeeper-3.4.5.tar.gz
解压缩 tar xzvf zookeeper-3.4.5.tar.gz
配置zookeeper
Vi conf/zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/hadoop/repo1/zookeeper
# the port at which the clients will connect
clientPort=2181
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
在hadoop1, hadoop2, hadoop3, 修改 /home/hadoop/repo1/zookeeper/myid
按照下面的表哥填写myid
| Hadoop1 |
1 |
| Hadoop2 |
2 |
| Hadoop3 |
3 |
nfs安装
在hadoop3上安装
yum install nfs-utils
vi /etc/exports
/home/hadoop/repo3/nfs 192.168.124.0/24(rw,sync,no_root_squash)
启动
service rpcbind restart
service nfs restart
在hadoop1和hadoop2运行mount命令
mount -t nfs hadoop3:/home/hadoop/repo3/nfs /home/hadoop/repo3/nfs
配置hadoop
vi etc/hadoop/hadoop-env.sh 修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/mapred-env.sh修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/yarn-env.sh修改jdk位置
export JAVA_HOME=/home/hadoop/jdk1.6.0_32
vi etc/hadoop/core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/repo3/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/hadoop/repo3/journal</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
</configuration>
vi etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/repo3/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/repo3/data</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>hadoop1,hadoop2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.hadoop1</name>
<value>hadoop1:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.hadoop1</name>
<value>hadoop1:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.hadoop2</name>
<value>hadoop2:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.hadoop2</name>
<value>hadoop2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>file:///home/hadoop/repo3/nfs</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
vi etc/hadoop/yarn-site.xml
<configuration>
<property>
<description>the valid service name</description>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<description>The hostname of the RM.</description>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
</property>
</configuration>
vi etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
vi etc/hadoop/slaves
hadoop1
hadoop2
hadoop3
格式化namenode和failovercontroler
failovercontroler也需要格式化: bin/hdfs zkfc -formatZK
bin/hdfs namenode -format -clusterid mycluster
在hadoop2节点上的namenode信息需要与hadoop1节点同步,不能通过简单的格式化做到,hadoop2节点上的namenode需要向hadoop1的namenode发送数据请求。因此我们还需要启动hadoop1上的namenode.
在hadoop1上运行: bin/hdfs namenode
在hadoop3上运行:bin/hdfs namenode -bootstrapStandby
最后关闭hadoop1上的namenode,然后启动整个hadoop集群。
启动hadoop集群
cd /home/hadoop/hadoop-2.2.0
sbin/start-all.sh
从图上可以看出,先启动namenode,再启动datanode, 再启动ZK failover controller, 再启动resourcemanger, 最后启动nodemanager。
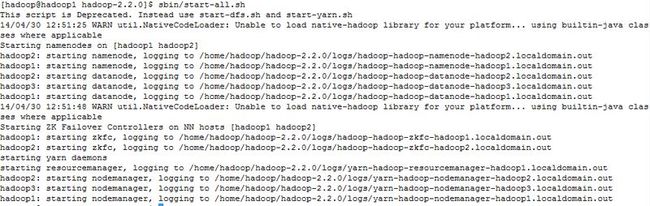
使用jps查看启动的进程
在hadoop1上运行jps

在hadoop2上运行jps

在hadoop3上运行jps

查看namenode的状态
bin/hdfs haadmin -getServiceState hadoop1
![]()
bin/hdfs haadmin -getServiceState hadoop2
![]()
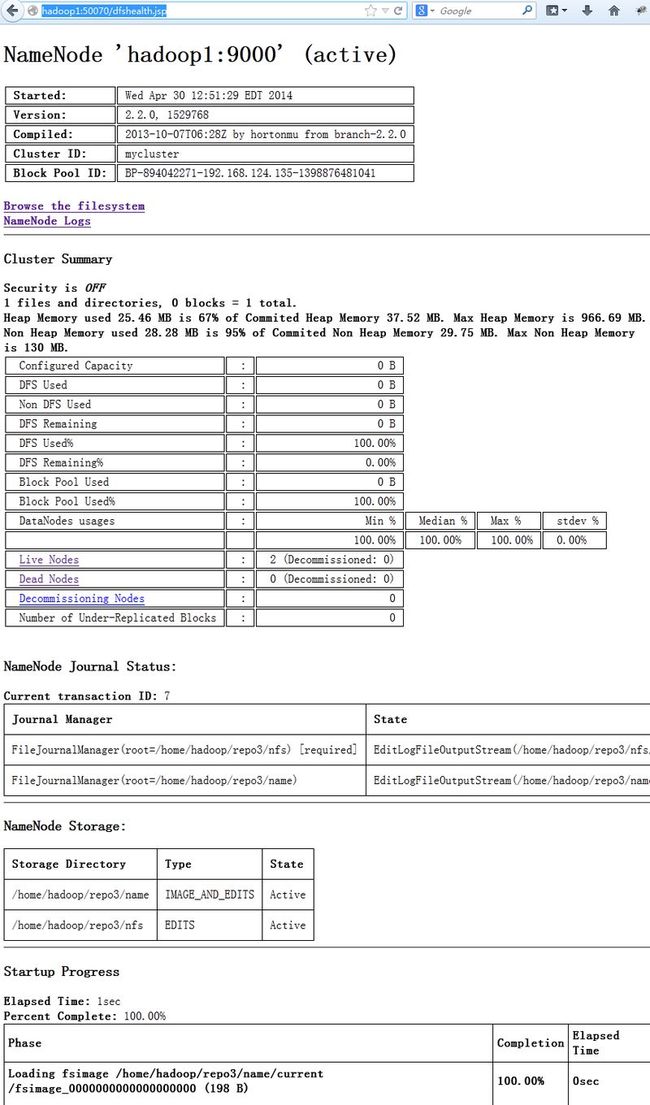
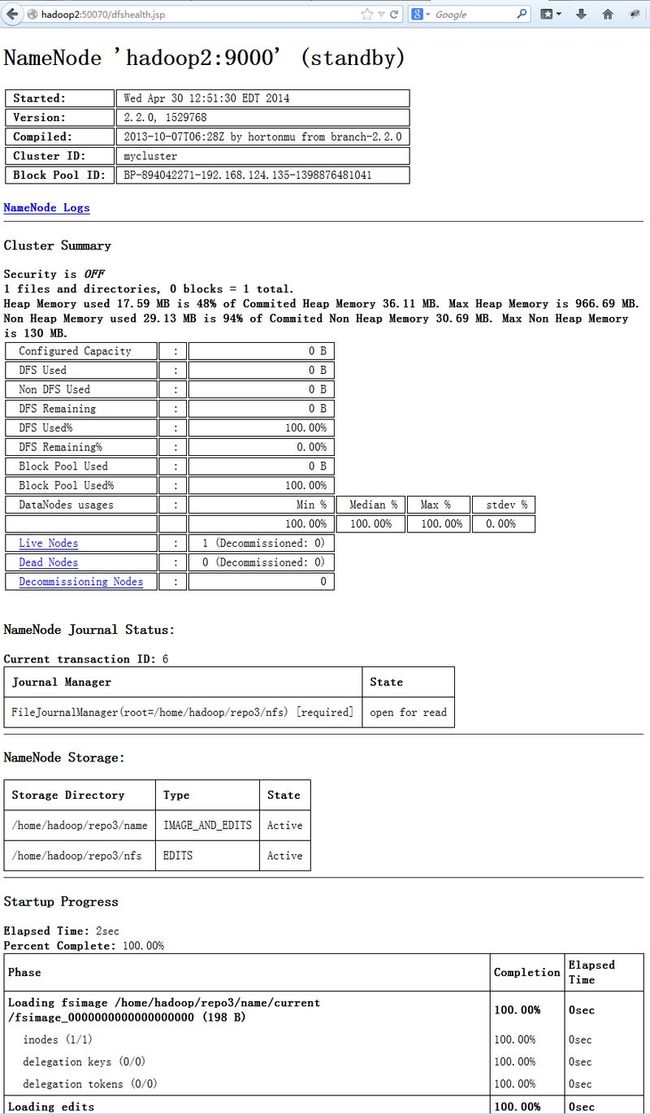
从图上可以看出hadoop2上的namenode处于standby状态,而hadoop1上的namenode处于active状态
这些信息也可以通过Hadoop的web界面得到。
在浏览器里输入:http://hadoop1:50070
在浏览器里输入:http://hadoop2:50070
Failover 测试
从图上我们可以看出hadoop1节点上的namenode处于active状态,hadoop2上的节点处于standby状态,我们现在杀死hadoop1节点上的namenode,然后看hadoop2上的节点会自动变为active状态
在hadoop1上使用jps查看启动的进程

找到NameNode的进程,然后杀死它
Kill -9 11146,发现namenode消失了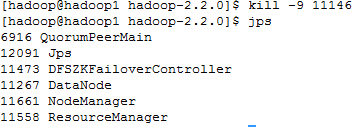
查看一下hadoop2节点的状态 bin/hdfs haadmin -getServiceState hadoop2

查看hadoop1节点的状态 bin/hdfs haadmin -getServiceState hadoop1

启动hadoop1节点上的namenode bin/hdfs namenode后
再查看hadoop1节点的状态 bin/hdfs haadmin -getServiceState hadoop1

很显然,hadoop1节点上namenode为standby状态,hadoop已经很好的解决了single namenode的问题,在不停机的条件下 备用节点成功的接管了主节点的任务。
尽管namenode可以很好的完成failover工作,但是他们之间使用nfs来存储变量的数据。nfs也会存在单点问题,也有可能停机导致整个集群的失败。Hadoop还提供了一种叫做jornalnode的技术,解决nfs的问题。