进程控制(Linux)
进程控制
- 一、进程创建
-
- 1. 再识fork
- 2. 写时拷贝
- 二、进程终止
-
- 前言——查看进程退出码
- 1. 退出情况
-
- 正常运行,结果不正确
- 异常退出
- 2. 退出码
-
- strerror和errno
- 系统中设置的错误码信息
- perror
- 异常信息
- 3. 退出方法
-
- exit和_exit
- 三、进程等待
-
- 1. 解决等待的三个问题
- 2. 系统调用
-
- wait
-
- 参数为NULL
- 使用status参数
- 小结
- waitpid
- 3. 阻塞和非阻塞等待
- 4. 进程等待的原理
- 四、进程替换
-
- 1. 概念
- 2. exec函数族
-
- ①execl
- ②execlp
- ③execle
- ④execv
- ⑤execvp
- ⑥execvpe
- 小结
- 3. 系统调用——execve
- 4. 总结
一、进程创建
1. 再识fork
在初始进程这篇博客中,浅谈了fork这个函数,在进程地址空间这篇中,也解释了一些关于fork返回值的问题。在这里再认识一下fork函数。
fork函数: 在Linux中,fork可以从已存在的进程中创建一个新的进程,新进程为子进程,原进程为父进程。
#include 来一段代码测试:
#include 上述代码运行结果:

fork运行的逻辑结构:
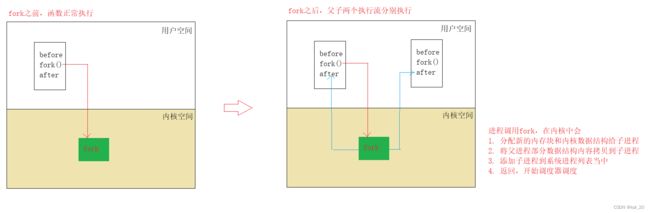
结论: fork之前,父进程独立执行。fork之后,父子进程两个执行流分别执行。那个进程先执行由调度器决定
fork常规用法:
- 父进程希望复制自己,使父子进程同时执行不同的代码段。eg:父进程等待客户端请求,生成子进程处理请求。
- 一个进程要执行一个不同的程序。(进程替换,后面讲)
2. 写时拷贝
在进程地址空间这篇博客中也对写时拷贝进行了说明
OS为了提高效率,在创建子进程时会使用写时拷贝。本质就是按需申请,不会浪费系统资源
通过触发页表的可读权限,后续判断写入错误,发生写时拷贝,并更改权限
二、进程终止
前言——查看进程退出码
程序在执行完,无论正不正确都有一个退出码,可以查看
查看方式:
echo $?这个命令的意思就是查看 ? 的内容。
注:
- 查看最近一个进程或是命令运行结束的退出码,退出码保存在 ? 中。
- 先看程序是否异常,异常结束的退出码无意义
先实践一下:
#include 查看退出码:
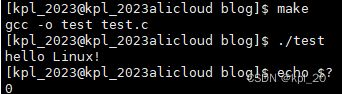
退出码是0,程序正常运行结束
1. 退出情况
- 正常运行,结果正确
- 正常运行,结果不正确
- 代码异常终止
第一种情况就不再实验
正常运行,结果不正确
先看程序是否异常,如果没有异常再看退出码。
#include 查看退出码:

退出码是12,可见结果不正确。我们也打印了错误信息Cannot allocate memory
异常退出
退出码无意义。
进程出现异常,本质是我们的进程收到对应的信号
#include 查看运行结果:

注: 第二次执行echo $? 发现结果是0。原因是上一次echo $?也是程序,并且是正常运行得到正常结果
在前面也说程序没有执行完就结束,是因为OS对进程发送了异常的信号。
测试一下:
#include 测试结果:

对3330进程发送了11号信号,所以左边的会话弹出段错误,并且程序结束。
2. 退出码
父进程和用户可能会关心这个进程的运行结果,如果出错,那就要了解原因,而退出码对应着错误原因。退出码是程序执行结果和错误类型的一种有效表示方式。
C语言提供了两个函数和一个全局变量显示程序的错误信息。
strerror和errno
- strerror:查看系统对应的错误码信息
- errno:全局变量,strerror想要查看错误码信息,需要的错误码就是从errno来,程序出现结果不正确,错误码被设置,也就是errno被设置。
- 我们也可以自己设计一套对应的退出码
头文件:#include
函数声明:char* strerror(int errnum)
参数:错误码(全局变量errno存放的就是错误码)
返回值:错误码对应的信息
代码:
#include 运行结果:

系统中设置的错误码信息
一共133个非常多
测试代码:
#include 运行结果: (注:没有全部截下来,太长了)

perror
测试代码:
#include 测试结果:
![]()
直接打印出错误信息。
可以这样理解:strerror+errno+printf == perror
异常信息
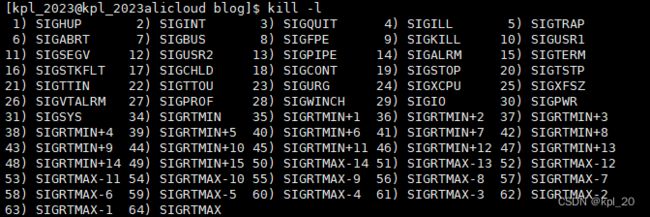
kill -l查看信号
kill -[信号编号] [进程PID]对指定进程发生信号
查看所有信号:
SIGHUP:挂起信号,通常由终端关闭或网络连接中断引起。用于通知进程重新加载配置文件或进行清理操作。
SIGINT:中断信号,通常由终端用户通过键盘输入Ctrl+C发送。用于请求进程终止。
SIGQUIT:退出信号,通常由终端用户通过键盘输入Ctrl+\发送。与SIGINT类似,但会生成核心转储文件。
SIGILL:非法指令信号,表示进程执行了一个非法的机器指令。
SIGTRAP:跟踪陷阱信号,用于调试目的。
SIGABRT:异常终止信号,通常由调用abort函数引起。
SIGBUS:总线错误信号,表示进程访问了无效的内存地址。
SIGFPE:浮点异常信号,表示进程执行了一个非法的浮点运算。
SIGKILL:强制终止信号,用于立即终止进程。不能被忽略或捕获。
SIGUSR1:用户自定义信号。
SIGSEGV:段错误信号,表示进程访问了无效的内存段。
SIGUSR2:用户自定义信号。
SIGPIPE:管道破裂信号,表示进程向一个已关闭的管道写入数据。
SIGALRM:闹钟信号,用于定时器操作。
SIGTERM:终止信号,用于请求进程正常终止。
SIGSTKFLT:协处理器栈错误信号。
SIGCHLD:子进程状态改变信号,用于通知父进程子进程的状态发生了改变。
SIGCONT:继续信号,用于恢复被SIGSTOP或SIGTSTP暂停的进程的执行。
SIGSTOP:停止信号,用于暂停进程的执行。
SIGTSTP:终端停止信号,通常由终端用户通过键盘输入Ctrl+Z发送。用于请求进程暂停。
SIGTTIN:后台读取信号,表示后台进程试图从终端读取数据。
SIGTTOU:后台写入信号,表示后台进程试图向终端写入数据。
SIGURG:紧急条件信号,表示进程收到了一个紧急数据。
SIGXCPU:CPU时间限制信号,表示进程超过了CPU时间限制。
SIGXFSZ:文件大小限制信号,表示进程试图创建一个超过文件大小限制的文件。
SIGVTALRM:虚拟定时器信号。
SIGPROF:性能分析器定时器信号。
SIGWINCH:窗口大小改变信号,表示终端窗口大小发生了改变。
SIGIO:异步I/O信号。
SIGPWR:电源故障信号。
SIGSYS:无效系统调用信号,表示进程执行了一个无效的系统调用。
信号部分,再进行介绍
3. 退出方法
exit和_exit
- exit
#include 代码运行结果:

- _exit
#include 代码运行结果:

结论:通过结果发现exit刷新了缓冲区,_exit没有刷新缓冲区
exit和_exit的底层关系:

总结:
- exit是库函数,_exit是系统调用接口
- exit会刷新缓冲区,_exit不会刷新缓冲区
- C语言的exit的实现底层封装系统调用接口_exit
- 系统调用接口不刷新缓冲区,所以得出缓冲区不在内核中,在用户空间
注: exit和return的区别
- exit是直接退出进程,而return是函数的返回值
- 在main函数中的return与exit的作用相同。在其它函数return和exit作用不同
三、进程等待
1. 解决等待的三个问题
- 是什么?
通过系统调用wait/waitpid,对子进程进行状态检测与回收功能
- 为什么?
- 僵尸进程无法被kill -9杀死(因为僵尸进程已经死了),需要通过进程等待来杀掉它,进而解决内存泄漏问题。
- 可以通过进程等待,获取子进程的退出情况,可以了解子进程的任务完成情况。
- 总而言之,父进程可以通过等待,回收子进程资源,获取子进程退出信息,无论父进程是否关心这个信息。
- 怎么办?
父进程通过调用wait/waitpid进行子进程回收。
2. 系统调用
wait
头文件:
1. #include <sys/types.h>
2. #include <sys/wait.h>
函数声明:
pid_t wait(int *status);
参数:输出型参数,执行结束status会带出进程的退出状态(包括错误信息和异常信息)
返回值:成功返回所等待进程的pid,失败返回-1
参数为NULL
eg1:(简单使用)
#include 预期结果:创建子进程,子进程执行完代码先等待三秒,然后父进程等待五秒,其中差额的两秒子进程进入僵尸状态,然后父进程休眠完之后等待成功,再等待三秒结束进程。
实验结果: (符合预期结果)
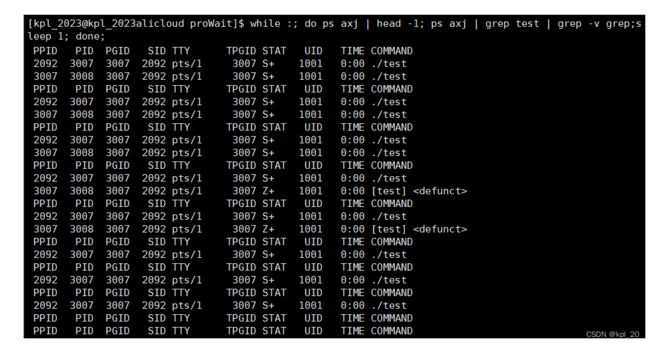
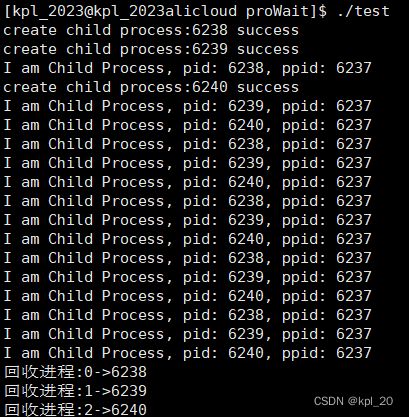
eg2:(多个子进程进行等待)
#include 实验结果:在回收子进程的过程中,等到谁就释放谁
也可以使用
while :; do ps axj | head -1; ps axj | grep test | grep -v grep;sleep 1; done;查看进程状态
使用status参数
使用输出型参数status的原因:
- 因为进程间的独立性,所以父进程不能直接访问子进程
- 通过返回值返回的信息成功要返回子进程pid,无法再返回别的信息。
status:
- 该参数可以不设置,就如同上面直接用NULL,表示不关心子进程的退出状态信息。
- 正常设置该参数,OS会根据该参数,将子进程的退出信息反馈父进程。
- status也不能用简单的整型看待,要从位图看待(只研究低16位)
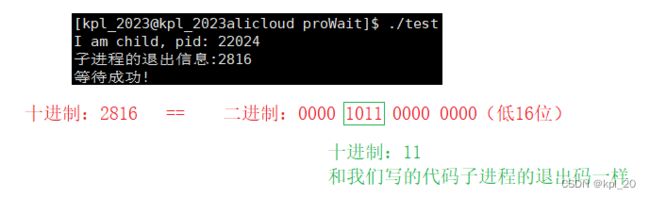
退出信息位分布:(低16位)

来两个小demo测试一下:
正常终止:
#include 运行结果:
异常终止:
#include 运行结果:

小结
根据上文的测试:大致可以观察到测试结果和退出信息的位分布结果是一致的。
如何从位中获得具体的退出状态或者终止信号
- 退出状态:(status >> 8) & 0xFF
- 终止信号:(status & 0x7F)
系统也提供了一些宏,来帮助获取退出状态与终止信号
- 判断是否正常退出:WIFEXITED
获取退出状态:WEXITSTATUS- 判断是否被信号终止:WIFSIGNALED
获取信号信息:WTERMSIG
根据上面的小结,再做一些小实验:
#include 运行结果:

注: 这个测试,只是测试了异常终止的代码,正常结束的程序就不再赘述了。
waitpid
头文件:
1. #include <sys/types.h>
2. #include <sys/wait.h>
函数声明:
pid_t waitpid(pid_t pid, int *status, int options);
参数:
pid:
1. pid = -1,等待任意一个子进程。与wait的作用一样
2. pid > 0。等待与pid相等的子进程
status:(该参数在wait部分已经详细介绍)
WIFEXITED:正常终止的子进程,则为真。(查看进程是否正常退出)
WEXITSTATUS:WEXITSTATUS不为0,提取子进程退出码。(查看进程的退出码)
options:
WNOHANG:若pid指定的子进程没有结束,则waitpid()函数返回0,不进行等待。若正常结束,则返回该子进程pid
0:进行阻塞等待
WUNTRACED:如果子进程进入暂停状态就立刻返回。
返回值:
1. 当正常返回的时候waitpid返回的是收集到子进程的PID
2. 如果设置了第三个参数WNOHANG,而调用waitpid发现没有已退出的子进程可收集,则返回0
3. 调用出错,则返回-1,errno也会被设置
注: 在这里就不再对waitpid进行实验,在下一节内容顺带实验
3. 阻塞和非阻塞等待
阻塞等待:
#include 运行结果:

非阻塞等待:
#include 代码运行结果:
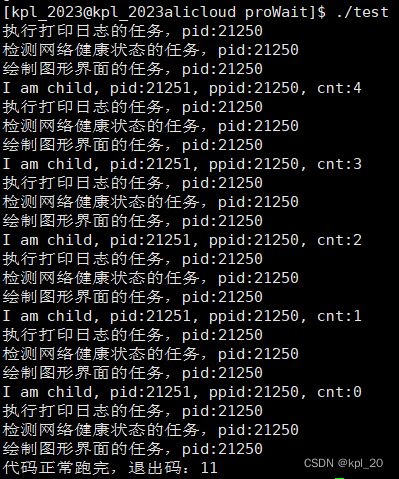
总结: 阻塞等待和非阻塞等待
- 阻塞等待:直到子进程被等待成功,才会继续执行,否则就一直处于阻塞状态
- 非阻塞等待:无论能不能等待到子进程都进行返回,等待成功返回子进程pid,失败返回0
- 非阻塞等待相比阻塞等待,可以在子进程没结束的时候,做一些自己的事情。所以也称作非阻塞轮询
- wait函数就是阻塞等待,子进程不结束,就一直等
4. 进程等待的原理
- 子进程运行结束,父进程没有等待之前,子进程是为僵尸状态,其代码和数据先被释放,PCB保留在OS。
- 称为僵尸进程的子进程的PCB中有这样的两个变量,
int exit_code, exit_signal- 父进程调用系统调用wait进行等待,因为进程间的独立性,实际由OS获取这个两个变量,并写入输出型参数当中。

四、进程替换
1. 概念
进程替换:进程替换需要通过调用exec系列的函数,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。注:不会创建新的进程,会更新PCB,但是如进程的PID值这样的不会改变。很像是被小说中的大能夺舍,变得是灵魂,不变的是肉体。
2. exec函数族
exec系列函数:
头文件:#include <unistd.h>
返回值:
1. 函数调用成功,则加载新的程序,开始执行代码,不返回
2. 替换失败,返回-1.按照原先的代码继续运行。错误码被设置
①execl
函数声明:
int execl(const char *path, const char *arg, ...);
参数:
1. path:指的是所要打开文件具体的路径
2. arg:所要打开的文件名
3. ...:可变参数列表,传的是具体选项,且以NULL结尾
测试:
#include 测试结果: (进程替换成功)

②execlp
函数声明:
int execlp(const char *file, const char *arg, ...);
参数:
1. file:指的是所要打开文件的路径,若不加路径,可以在当前路径和PATH环境变量下的路径寻找
2. arg:所要打开的文件名
3. ...:可变参数列表,传的是具体选项,且以NULL结尾
测试:
#include 测试结果:

③execle
函数声明:
int execle(const char *path, const char *arg, ..., char *const envp[]);
参数:
1. path:指的是所要打开文件具体的路径
2. arg:所要打开的文件名
3. ...:可变参数列表,传的是具体选项,且以NULL结尾
4. envp:新的环境变量数组,即新执行程序的环境变量
测试:
#include 替换的程序:
#include 测试结果:

注意:因为一次编译了两个程序,所以我们在编译makefile时,要借用为目标,让其推到自己编译好两个程序
makefile文件:
.PHONY:ALL
ALL:test process
process:process.cpp
g++ -o $@ $^
test:test.c
gcc -o $@ $^ -std=c99
.PHONY:clean
clean:
rm -f test process
④execv
函数声明:
int execv(const char *path, char *const argv[]);
参数:
1. path:替换程序的路径
2. argv[]:保存的是参数列表,将可执行文件和参数保存到字符串数组中,最后以NULL结尾。
测试:
#include 测试结果:
⑤execvp
函数声明:
int execvp(const char *file, char *const argv[]);
参数:
1. file:所要打开的文件路径(绝对和相对路径)。也可以在PATH环境变量下寻找
2. argv:保存的是参数列表,将可执行文件和参数保存到字符串数组中,最后以NULL结尾。
测试:
#include 测试结果:
⑥execvpe
该函数接口是GNU扩展,所以在使用的时候要加上
#define _GNU_SOURCE
函数声明:
int execvpe(const char *file, char *const argv[], char *const envp[]);
参数:
1. file:指的是所要打开文件的路径,也可在环境变量PATH下寻找
2. argv:指的是所要打开文件的名及选项
3. envp:要传入的环境变量数组
测试代码:(test进程,其中子进程替换成process进程)
#include process:
#include 测试结果比较长,这里就不展示了。前面再介绍execle函数时,也说了如何编译多个程序
小结
上面我们介绍了exec系列的六种函数接口。这六个函数接口都包含在库文件中,而在这六个接口的底层,无疑调用了系统调用,这个系统调用接口就是execve。
六个函数的命名理解:
l (list):表示参数采用列表
v (vector):参数用数组
p (path):有p自动搜索环境变量PATH
e (env):表示自己维护环境变量
| 函数接口 | 参数格式 | 是否带路径 | 是否使用当前环境变量 |
|---|---|---|---|
| execl | 列表 | 不是 | 是 |
| execlp | 列表 | 是 | 是 |
| execle | 列表 | 不是 | 需要自己组装环境变量 |
| execv | 数组 | 不是 | 是 |
| execvp | 数组 | 是 | 是 |
| execvpe | 数组 | 是 | 需要自己组装环境变量 |
| execve(系统调用) | 数组 | 不是 | 需要自己组装环境变量 |
代码:
#include 六个函数的关系图:(去掉了GNU扩展的那个函数)

3. 系统调用——execve
函数声明:
int execve(const char *path, char *const argv[], char *const envp[]);
参数:
1. path:替换程序的路径
2. argv:保存的是参数列表,可执行文件和参数保存到字符串数组中,以NULL结尾
3. envp:新的环境变量数组
测试:
#include 测试结果:

4. 总结
- 子进程被进程替换之后,不会影响父进程。
虽然说父子进程共享代码和数据,而进程替换也是替换代码和数据,但是本质是由OS再开一块物理空间,将页表的映射关系更改即可
- C代码可以替换C++程序是因为:操作系统对于正在运行的程序来说,无论是什么语言编写的,它们最终都会被操作系统视为进程来执行。最终都会被编译成机器码,以二进制形式存储在可执行文件中,当操作系统加载可执行文件并创建进程时,它会将这些机器码加载到内存中,并按照指令的顺序执行。
- 环境变量:子进程默认继承父进程的环境变量,但是进程的独立性,所以父子进程的环境变量也是相互独立的,子进程环境变量的修改不会影响父进程。eg:Shell的环境变量就是在用户登陆时从配置文件.bash_profile中加载
- 进程的入口:Linux形成的可执行程序是有格式的ELF格式,ELF格式定义了可执行文件的结构和布局。可执行程序被加载到内存时,OS会先读取可执行文件的表头。表头中包含程序的入口地址(程序开始执行的第一个指令的内存地址)
小知识:讲这个的原因,是因为说到了C代码可以替换C++程序,所以进行扩展
test.sh --> 全称.Shell --> Shell脚本
Shell脚本就是把Linux命令放到一个文件
开头-->#!(shebang-->用于指定脚本文件的解释器。作用就是告诉OS用那个解释器执行脚本文件) 所以要紧跟脚本语言对应的解释器。
-----------------------------------
test.py:
#!/usr/bin/python3
print("hello Python!")
-----------------------------------
test.sh:
#!/usr/bin/bash
function myfun()
{
cnt=1
while [ $cnt -le 10]
do
echo "hello $cnt"
let cnt++
done
}
echo "hello 1"
ls -a -l
myfun
-----------------------------------
替换上面的程序:
execl("/usr/bin/bash", "bash", "test.sh", NULL);
execl("/usr/bin/python3", "python3", "test.py", NULL);