音乐数据集+大模型相关(一)
文章目录
- 音乐数据集介绍
-
- MusicCaps
- YouTube8M-MusicTextClips
- MusicNet
- FMA
- MTG-Jamendo
- MagnaTagATune
- 音乐模型介绍
-
- 简介
- MUSICGEN: mate新推出的音乐生成模型 2023
- MusicLM:用文本生成高保真音频音乐
- llark 音乐多模态大模型
- 参考
音乐数据集介绍
下图来自 llark论文。

MusicCaps
数据集包含了 5,521 个音乐示例,每个示例都标有一个英语方面列表和一个由音乐家撰写的自由文本描述cpations。
举例如下:
列表的例子是“流行,尖锐的高音钹,柔和的钢琴旋律,高音女声旋律,持续脉冲音乐合成器引导音”,而描述由多个关于音乐的句子组成,例如“一个低沉的男声在快节奏的鼓声中念着说唱,贝斯伴随着一种像吉他的旋律。这个录音的音质很差。背景中可以听到笑声。这首歌可能正在酒吧播放。”
这些文本仅关注描述音乐的声音,而不是元数据,如艺术家姓名。
标记的示例是来自于 AudioSet 数据集的 10s 的音乐片段 (评估集 2,858 个和训练集 2,663 个)
使用此数据集时,请引用相应的论文: http://arxiv.org/abs/2301.11325 (DOI:10.48550/arXiv.2301.11325)
数据集结构:
ytid
指向 YouTube 视频,其中包含标记的音乐片段。您可以通过打开 https://youtu.be/watch?v={ytid}&start={start_s} 来收听该片段。
start_s
音乐开始的 YouTube 视频中的位置。
end_s
音乐结束的 YouTube 视频中的位置。所有片段都是 10 秒长。
audioset_positive_labels
该片段来自 AudioSet( https://research.google.com/audioset/ )数据集的标签。
aspect_list
描述音乐的方面列表。
caption
描述音乐的多句自由文本描述。
author_id
通过作者将样本进行分组的整数。
is_balanced_subset
如果该值为 true,则该行是平衡流派的 1k 子集的一部分。
is_audioset_eval
如果该值为 true,则该片段来自 AudioSet 的评估集。否则,它来自 AudioSet 的训练集。
YouTube8M-MusicTextClips
YouTube8M-MusicTextClips数据集由YouTube8M数据集的视频拆条中4k高质量的音乐人类文本描述组成。
对于每个选定的YouTube音乐视频,在视频中间提取10秒的片段进行注释。只向注释器提供与该剪辑对应的音频。因此,文本注释仅描述音频,而不是剪辑的视觉内容。
数据集注释分为训练和测试拆分文件。由于数据集主要用于评估,因此测试集中有3169个带注释的剪辑,而训练集中只有1000个带注释的剪辑。
每个文件都包含每个样本的以下信息:
video_id:包含带注释剪辑的视频对应的YouTubeID
start:视频中带注释剪辑的开始时间(以秒为单位)
end:视频中带注释剪辑的结束时间(以秒为单位)
text:描述带注释剪辑中音乐的文本注释
使用数据集请引用:
McKee, D., Salamon, J., Sivic, J., & Russell, B. (2023). Language-Guided Music Recommendation for Video via Prompt Analogies. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023).
MusicNet
MusicNet是330个免费授权的古典音乐录音的集合,以及超过100万的注释标签,指示每个录音中每个音符的精确时间、播放每个音符的乐器以及音符在作曲韵律结构中的位置。标签是从通过动态时间规整与录音对齐的乐谱中获取的。标签由训练有素的音乐家验证;我们估计标签错误率为4%。我们向机器学习和音乐社区提供MusicNet标签,作为训练模型的资源和比较结果的通用基准。
该存储库由3个级别的文件组成:
musicnet. tar.gz-此文件包含MusicNet数据集本身,由PCM编码的音频波文件(.wav)和相应的CSV编码的音符标签文件(.csv)组成。数据根据“监督音乐转录的不变性和数据增强”中描述和使用的训练/测试拆分进行组织。
musicnet_metadata. csv-此文件包含有关MusicNet中包含的录音的轨道级信息。数据和标签文件以MusicNet ID命名,您可以使用该ID与此元数据文件交叉索引数据和标签。
musicnet_midis. tar.gz-此文件包含用于构建MusicNet标签的参考MIDI文件。
musicnet_metadata:(名称、含义、举例)
id
composer 作曲家 Schubert
composition 曲名《A大调钢琴五重奏》 Piano Quintet in A major
movement 速度 2. Andante,3. Scherzo: Presto, 4. Andantino - Allegretto
ensemble 演奏类型 Piano Quintet,Solo Piano
source 来源 European Archive, Museopen
transcriber
catalog_name
FMA
音乐信息检索的数据集,
音乐信息检索领域模型的提取特征和端到端的设计受到大型音频数据集有限可用性的限制。FMA旨在克服这一障碍,提供917千兆字节和343天的知识共享许可音频,来自16,341名艺术家的106,574首曲目和14,854张专辑,按161种流派的分层分类排列。它提供全长和高质量的音频、预计算功能,以及轨道和用户级的元数据、标签和传记等自由格式文本。我们在这里描述数据集及其创建方式,提出训练/验证/测试拆分和三个子集,讨论一些合适的MIR任务,并评估流派识别的一些基线。
Paper: arXiv:1612.01840 (latex and reviews)
Slides: doi:10.5281/zenodo.1066119
Poster: doi:10.5281/zenodo.1035847
github:https://github.com/mdeff/fma
track.csv:所有106,574首曲目的每个曲目元数据,如ID、标题、艺术家、流派、标签和播放次数。(音轨,在整个专辑或碟片里的编号)
genres.csv:所有163个带有名称和父类的流派(用于推断流派层次结构和顶级流派)。(风格)
features.csv:使用librosa提取的常见特征。
echonest. csv:Echonest(现为Spotify)为13,129首曲目的子集提供的音频功能。



MTG-Jamendo
github:https://mtg.github.io/mtg-jamendo-dataset/
Metadata files in data
raw. tsv(56,639)-没有后处理的原始文件
raw_30s. tsv(55,701)-持续时间超过30秒的曲目
raw_30s_cleantags. tsv(55,701)-根据tag_map.json合并标签
raw_30s_cleantags_50artists. tsv(55,609)-带有至少有50个独特艺术家的标签
tag_map. json-我们合并的地图标签
tags_top50. txt-50大标签列表
autotagging. tsv=raw_30sec_cleantags_50artists.tsv-用于辅助标记的基本文件(在所有后处理之后,195个标签)
Subsets
autotagging_top50tags. tsv(54,380)-仅根据标签频率在曲目方面排名前50的标签
autotagging_genre. tsv(55,215)-只有带有流派标签的曲目(95个标签),并且只有那些标签
autotagging_instrument. tsv(25,135)-仪器标签(41标签)
autotagging_moodtheme. tsv(18,486)-心情/主题标签(59标签)
Splits
Splits文件夹包含autoagking. tsv和子集的训练/验证/测试集


MagnaTagATune
MagnaTagATune数据集包含25,863个音乐片段。每个片段是属于5223首歌曲、445张专辑和230位艺术家之一的29秒长的摘录。这些片段跨越了广泛的流派,如古典、新时代、电子、摇滚、流行、世界、爵士、布鲁斯、金属、朋克等。每个音频片段都提供了188个标签的二进制注释向量。这些注释是由人类玩双人在线TagATune游戏获得的。在这个游戏中,两个玩家要么被呈现相同的音频片段,要么被呈现不同的音频片段。随后,他们被要求为他们的特定音频片段想出标签。之后,玩家查看彼此的标签,并被要求决定他们是否被呈现相同的音频片段。只有当两个以上的玩家同意时,才会分配标签。注释包括“歌手”、“无歌手”、“小提琴”、“鼓”、“古典”、“爵士乐”等标签。前50个最受欢迎的标签通常用于评估,以确保每个标签有足够的训练数据。有16个部分,研究人员通常使用第1-12部分进行训练,第13部分进行验证,第14-16部分进行测试。
音乐模型介绍
简介
对于音频领域,Mubert和Riffusion是近期热门的两个文本到音乐的生成模型。Mubert是一个文本到音乐的演示界面,能够根据输入的文本生成高质量的音频音乐。不过由于所有的声音都是由音乐家和声音设计师事先创造的,因此Mubert更像是在生成声音的组合,而不是音乐。Riffusion使用与Stable Diffusion相同的模型,从文本中生成频谱图,然后将其转换为音频片段。
在线链接分别如下:
https://link.zhihu.com/?target=https%3A//huggingface.co/spaces/Mubert/Text-to-Music
https://link.zhihu.com/?target=https%3A//www.riffusion.com/
MUSICGEN: mate新推出的音乐生成模型 2023
论文:https://arxiv.org/pdf/2306.05284.pdf
MUSICGEN,一种简单且可控的音乐生成模型,它能够在给定文本描述的情况下生成高质量的音乐。
MUSICGEN 包含一个基于自回归变压器的解码器 [Vaswani et al., 2017],以文本或旋律表示为条件。模型基于来自 EnCodec [Défossez et al., 2022] 音频分词器的量化单元,它从低帧率离散表示提供高保真度重建。 [Défossez et al., 2022, Zeghidour et al., 2021] 等压缩模型采用残差矢量量化 (RVQ),从而产生多个并行流。在此设置下,每个流都由源自不同学习密码本的离散令牌组成。之前的工作提出了几种建模策略来处理这个问题 [Kharitonov et al., 2022, Agostinelli et al., 2023, Wang et al., 2023]。
MusicLM:用文本生成高保真音频音乐
MusicLM是一个以文本为条件的音频生成模型,可以从文本描述中生成高保真的音乐。
llark 音乐多模态大模型
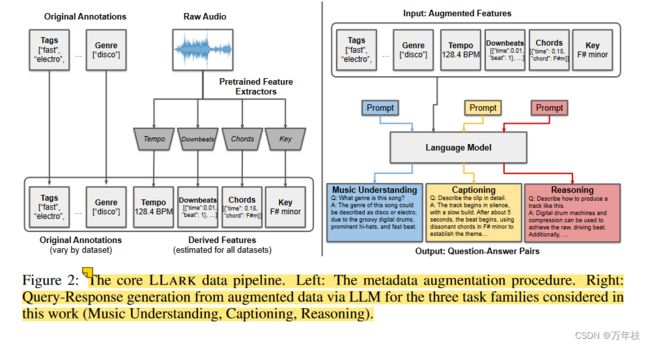
LLark是个12B的开源音乐大模型,在音乐理解(Music Understanding)、音乐字幕(Music Captioning)及音乐推理(Music Reasoning)三方面进行了初步的尝试。音乐理解主要涉及到节拍(Tempo,如125拍每分钟)、曲调(Key,如F调),类型(Genre,如古典音乐、爵士等),乐器(instruments,比如吉他、钢琴等乐器),这是模型处理的最基本内容,和音乐信息获取(Musical Information Retrieval,MIR)息息相关(从音乐数据集的标注信息获得)。音乐字幕主要涉及总结和提取音乐的内容,这更多是多模态大模型和来自音乐社区内容的贡献;音乐推理这要通过总结音乐的多方面知识,结合外部知识,推理出如何通过乐器和演奏技巧展示出巴洛克风格,或者这音乐适合在什么场合演奏(舞会、宴会等)。由此可见,利用LLark模型,我们可以基于问答的方式理解音乐的节拍、曲调、乐器、音乐风格和音乐内容或者音乐适用的场合等。
instruction data generation 指令数据生成
文章提取了四个特征:速度(以每分钟节拍数或 BPM 为单位)、全局键和模式(例如“F# 小调”)、带时间戳的和弦和节拍网格(带有时间戳的强拍发生位置标记,以及节拍“数字”的数字指示器,例如 1、2、3、4 表示 4/4 拍中的歌曲)。
Instruction-Tuning Generation via Language Model
我们将给定剪辑的元数据作为原始 JSON 提供,并附有系统提示。
我们对三个任务系列中的每一个都使用不同的提示,但总体过程是相同的。每个提示都描述了 JSON 中的一些元数据(并非所有字段都进行了描述,因为某些数据集包含 150 多个注释),以及语言模型要生成的所需问答对类型。我们使用 ChatGPT 的变体(GPT3.5-turbo、GPT3.5-turbo-16k、GPT4)来生成训练示例。除了现有的字幕数据集(MusicCaps、YouTube8M-MusicTextClips)之外,我们还为 MusicNet 生成了字幕,这是我们研究中唯一提供音符级元数据的数据集。作为此步骤的结果,我们为每个输入示例获取一个或多个查询-响应对。然后,这些查询-响应对将进行数据过滤步骤,在该步骤中,我们删除包含某些关键字的对,这些关键字表明我们的指令未被遵循。我们的管道最终从最初的 164, 000 个轨道中产生大约 1.2M 个训练样本。
task families
音乐理解:我们将“音乐理解”定义为需要识别音乐片段的单一全局属性的任务。这包括:速度、调性、流派、乐器等。这些是我们的模型处理的最低级别的任务。这些任务主要与音乐信息检索 (MIR) 社区的先前工作有关。
字幕(描述,caption):音乐字幕与图像字幕类似,涉及用语言总结一段音频的内容。这项任务越来越受到多模态和音乐社区的兴趣,2 并且有许多可能的应用,包括可访问性和音乐摘要。
高级推理:我们将“高级推理”(或简称为“推理”)任务定义为“高级推理”,这些任务需要 (a) 结合轨道多个方面的知识,或 (b) 推理该轨道的各个方面如何与外部知识相结合关于世界。这可能包括推理乐器和演奏技巧如何展示巴洛克作曲风格,或确定曲目的哪些方面使其适合某些环境(例如晚宴、学习或舞蹈俱乐部)。每个任务都包括一个在指令数据创建时使用的单独系统提示,以及在测试时使用的一组不同的评估(在第 6 节中)。
通过 Llama 2 参数化语言模型(Touvron 等人,2023 年)。具体来说,我们使用 Llama2-7b-chat 变体,这是一个 7B 参数语言模型,通过人类反馈强化学习 (RLHF) 针对聊天应用程序进行了微调。
我们通过 Jukebox-5B 对音频编码器 A 进行参数化(Dhariwal 等人,2020 年)。与用于许多其他多模态应用的编码器相比,其中对比训练模型(例如,用于图像/文本的 CLIP;CLAP for audio)经常使用,Jukebox是一种生成模型。先前的研究表明,Jukebox的表示可以成为特定任务线性分类器的有效特征。我们假设生成模型可以创建音频的表示,这些表示不仅仅是分类,并且足够通用,可以由单个模型使用,以同时有效地表示音乐的许多属性(我们的消融研究验证了这一决定;参见第 6.5 节,F)。继 Castellon 等人 (2021) 之后,我们使用点唱机编码器第 36 层的输出。自动点唱机以 345Hz 的频率对 4800 维向量中的音频进行编码,这意味着 25s 音频剪辑的嵌入包含超过 4.14 ∗ 107 个浮点值。Castellon et al. (2021) 在时间维度上取平均值。相比之下,我们平均将自动点唱机嵌入在 100 毫秒帧内,将嵌入下采样到 10Hz 的频率和 1.2 × 106 的大小,用于 25 秒的音频剪辑,同时保留时间信息。我们注意到,这大约是许多多模态视觉模型中使用的 CLIP ViT-L14 模型嵌入大小的 6×。
提示 GPT-4 比较来自测试数据集的 1, 000 个样本的随机子集的模型输出的音乐细节,用于四个数据集。
参考
https://zhuanlan.zhihu.com/p/639813236
https://zhuanlan.zhihu.com/p/601360520
https://www.zhihu.com/question/625923742/answer/3248337781