Flink关系型API解读:Table API 与SQL
AI 前线导读:
\本篇文章主要介绍 Flink的关系型 API,整个文章主要分为下面几个部分来介绍:
\一、 什么是 Flink 关系型 API
\二、 Flink 关系型 API 的各版本演进
\三、 Flink 关系型 API 执行原理
\四、 Flink 关系型 API 目前适用场景
\五、 Table\u0026amp;SQL API 介绍
\六、 Table\u0026amp;SQL API 举例
\七、 动态表
\八、 总结
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
一、什么是 Flink 关系型 API
\\当我们在使用 Flink 做流式和批式任务计算的时候,往往会想到几个问题:
\\- 需要熟悉两套 API : DataStream/DataSetAPI,API 有一定难度,开发人员无法 focus on business\\t
- 需要有 Java 或 Scala 的开发经验\\t
- Flink 同时支持批任务与流任务,如何做到 API 层的统一\
Flink 已经拥有了强大的 DataStream/DataSetAPI,满足流计算和批计算中的各种场景需求,但是关于以上几个问题,我们还需要提供一种关系型的 API 来实现 Flink API 层的流与批的统一,那么这就是 Flink 的 Table \u0026amp; SQL API。
\\首先 Table \u0026amp; SQL API 是一种关系型 API,用户可以像操作 mysql 数据库表一样的操作数据,而不需要写 java 代码完成 Flink Function,更不需要手工的优化 java 代码调优。另外,SQL 作为一个非程序员可操作的语言,学习成本很低,如果一个系统提供 SQL 支持,将很容易被用户接受。
\\总结来说,关系型 API 的好处:
\\- 关系型 API 是声明式的\\t
- 查询能够被有效的优化\\t
- 查询可以高效的执行\\t
- “Everybody” knows SQL \
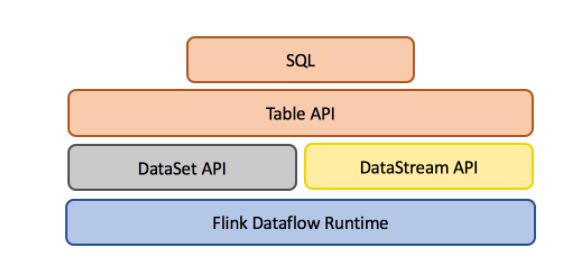
Table\u0026amp;SQL API 是流处理和批处理统一的 API 层,如下图。Flink 在 runtime 层是统一的,因为 Flink 将批任务看做流的一种特例来执行,然而在 API 层,Flink 为批和流提供了两套 API(DataSet 和 DataStream)。所以 Table\u0026amp;SQL API 就统一了 Flink 的 API 层,批数据上的查询会随着输入数据的结束而结束并生成 DataSet,流数据的查询会一直运行并生成结果流。Table\u0026amp;SQL API 做到了批与流上的查询具有同样的语法语义,因此不用改代码就能同时在批和流上执行。
\\
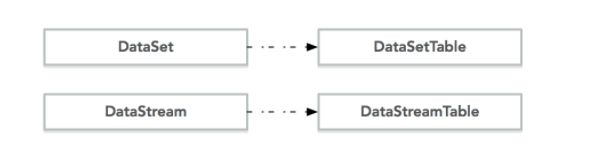
关于 DataSet API 和 DataStream API 对应的 Table 如下图:
\\
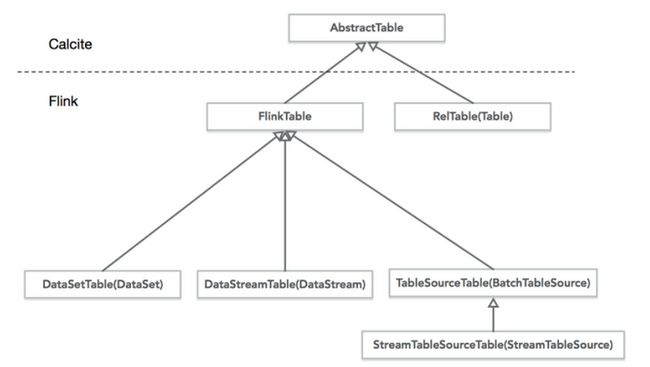
二、Flink 关系型 API 的各版本演进
\\关于 Table\u0026amp;SQL API,Flink 在 0.9 版本的时候,引进了 Table API,支持 Java 和 Scala 两种语言,是一个类似于 LINQ 模式的 API。用于对关系型数据进行处理。这系列 Table API 的操作对象就是能够进行简单的关系型操作的结构化数据流。结构如下图。然而 0.9 版本的 Table\u0026amp;SQL API 有着很大的局限性,0.9 版本 Table API 不能单独使用,必须嵌入到 DataSet 或者 DataStream 的程序中,对于批处理表的查询并不支持 outer join、order by 等操作。在流处理 Table 中只支持 filters、union,不支持 aggregations 以及 joins。并且,这个转化处理过程没有查询优化。整体来说 0.9 版本的 Flink Table API 还不是十分好用。
\\
在后续的版本中,1.1.0 引入了 SQL,因此在 1.1.0 版本以后,Flink 提供了两个语义的关系型 API:语言内嵌的 Table API(用于 Java 和 Scala)以及标准 SQL。这两种 API 被设计用于在流和批的任务中处理数据 在 API 层的统一,这意味着无论输入是批处理数据还是流数据,查询产生完全相同的结果。
\\在 1.20 版本之后逐渐增加 SQL 的功能,并对 Table API 做了大量的 Enhancement 了。在 1.2.0 版本中,Flink 的关系 API 在数据流中,支持关系操作包括投影、过滤和窗口聚合。
\\在 1.30 版本中开始支持各种流上 SQL 操作,例如 SELECT, FROM, WHERE,UNION、aggregation 和 UDF 能力。在 2017 年 3 月 2 日进行的 Flink Meetup 与 2017 年 5 月 24 日 Strata 会议,Flink 都有相应的 topic 讨论,未来在 Flink SQL 方面会支持更细粒度的 join 操作和对 dynamic table 的支持。
\\三、Flink 关系型 API 执行原理
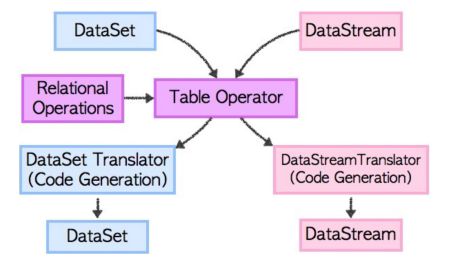
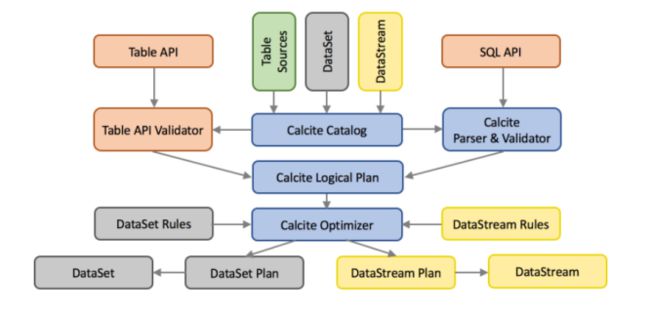
\\Flink 使用基于 Apache Calcite 这个 SQL 解析器做 SQL 语义解析。利用 Calcite 的查询优化框架与 SQL 解释器来进行 SQL 的解析、查询优化、逻辑树生成,得到 Calcite 的 RelRoot 类的一颗逻辑执行计划树,并最终生成 Flink 的 Table。Table 里的执行计划会转化成 DataSet 或 DataStream 的计算,经历物理执行计划优化等步骤。但是,Table API 和 SQL 最终还是基于 Flink 的已有的 DataStream API 和 DataSet API,任何对于 DataStream API 和 DataSet API 的性能调优提升都能够自动地提升 Table API 或者 SQL 查询的效率。这两种 API 的查询都会用包含注册过的 Table 的 catalog 进行验证,然后转换成统一 Calcite 的 logical plan。再利用 Calcite 的优化器优化转换规则和 logical plan。根据数据源的性质 (流和批) 使用不同的规则进行优化。最终优化后的 plan 转传成常规的 Flink DataSet 或 DataStream 程序。结构如下图:
\\
3.1 Translation to Logical Plan
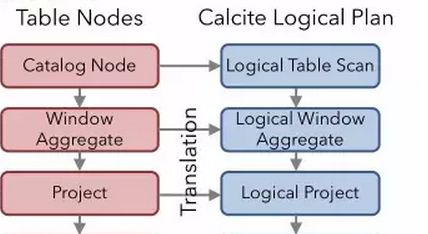
\\每次调用 Table\u0026amp;SQL API,就会生成 Flink 逻辑计划的节点。比如对 groupBy 和 select 的调用会生成节点 Project、Aggregate、Project,而 filter 的调用会生成节点 Filter。这些节点的逻辑关系,就会组成下图的一个 Flink 自身数据结构表达的一颗逻辑树 ; 根据这个已经生成的 Flink 的 logical Plan,将它转换成 calcite 的 logical Plan,这样我们才能用到 calcite 强大的优化规则。Flink 由上往下依次调用各个节点的 construct 方法,将 Flink 节点转换成 calcite 的 RelNode 节点。
\\
3.2 Translation to DataStream Plan
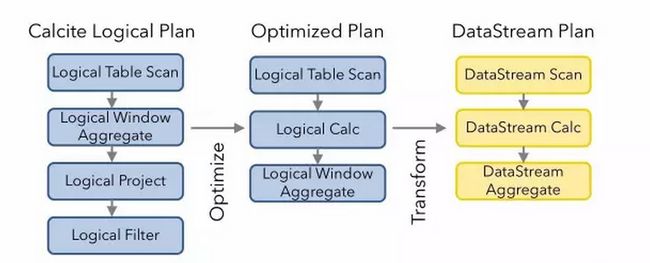
\\优化逻辑计划并转换成 Flink 的物理计划,Flink 的这部分实现统一封装在 optimize 方法里头。这部分涉及到多个阶段,每个阶段都是用 Rule 对逻辑计划进行优化和改进。声明定义于派生 RelOptRule 的一个类,然后再构造函数中要求传入 RelOptRuleOperand 对象,该对象需要传入这个 Rule 将要匹配的节点类型。如果这个自定义的 Rule 只用于 LogicalTableScan 节点,那么这个 operand 对象应该是 operand(LogicalTableScan.class, any())。通过以上代码对逻辑计划进行了优化和转换,最后会将逻辑计划的每个节点转换成 Flink Node,既可物理计划。
\\
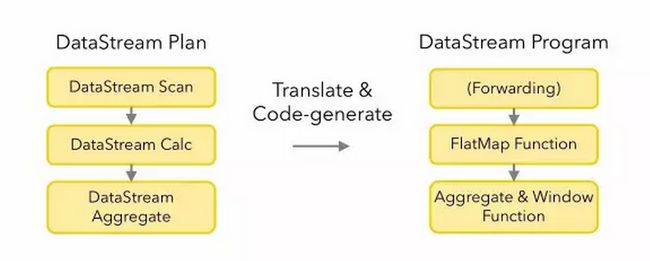
3.3 Translation to Flink Program
\\
四、Flink 关系型 API 目前适用场景
\\4.1 目前支持范围
\\Batch SQL \u0026amp; Table API 支持:
\\- Selection, Projection, Sort, Inner \u0026amp; Outer Joins, Set operations\\t
- Windows for Slide, Tumble, Session\
Streaming Table API 支持:
\\- Selection, Projection, Union\\t
- Windows for Slide, Tumble, Session\
Streaming SQL:
\\- \\t
Selection, Projection, Union, Tumble
\\t\
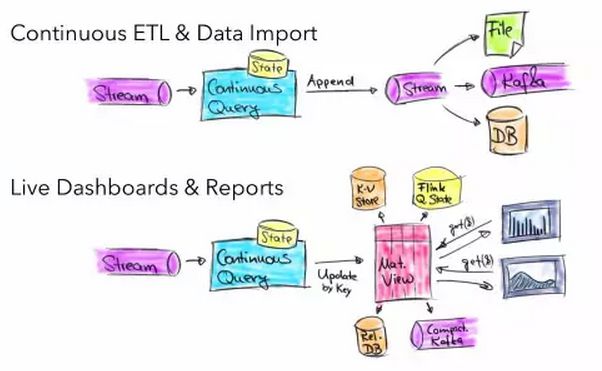
4.2 目前使用场景
\\
五、Table\u0026amp;SQL API 介绍
\\Table API 一般与 DataSet 或者 DataStream 紧密关联,可以通过一个 DataSet 或 DataStream 创建出一个 Table,再用类似于 filter, join, 或者 select 关系型转化操作来转化为一个新的 Table 对象。最后将一个 Table 对象转回一个 DataSet 或 DataStream。从内部实现上来说,所有应用于 Table 的转化操作都变成一棵逻辑表操作树,在 Table 对象被转化回 DataSet 或者 DataStream 之后,转化器会将逻辑表操作树转化为对等的 DataSet 或者 DataStream 操作符。
\\5.1 Table\u0026amp;SQL API 的简单介绍
\\1. Create a TableEnvironment
\\TableEnvironment 对象是 Table API 和 SQL 集成的一个核心,支持以下场景:
\\- 注册一个 Table\\t
- 注册一个外部的 catalog\\t
- 执行 SQL 查询\\t
- 注册一个用户自定义的 function\\t
- 将 DataStream 或 DataSet 转成 Table\
一个查询中只能绑定一个指定的 TableEnvironment,TableEnvironment 可以通过来配置 TableConfig 来配置,通过 TableConfig 可以自定义查询优化以及 translation 的进程。
\\TableEnvironment 执行过程如下:
\\(1)TableEnvironment.sql() 为调用入口
\\(2)Flink 实现了个 FlinkPlannerImpl,执行 parse(sql),validate(sqlNode),rel(sqlNode) 操作
\\(3)生成 Table
\\其中,LogicalRelNode 是 Flink 执行计算树里的叶子节点。
\\源码如下图:
\\

2. Register a Table
\\(1)将一个 Table 注册给 TableEnvironment
\\
(2)将一个 TableSource 注册给 TableEnvironment, 这里的 TableSource 指的是将数据存储系统的作为 Table,例如 mysql,hbase,CSV,Kakfa,RabbitMQ 等等。
\\(3)将一个外部的 Catalog 注册给 TableEnvironment,访问外部系统的数据或文件。
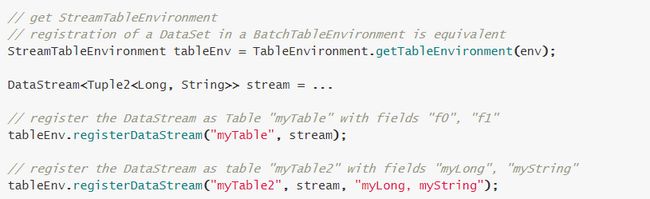
\\(4)将 DataStream 或 DataSet 注册为 Table
\\
3. Query a Table
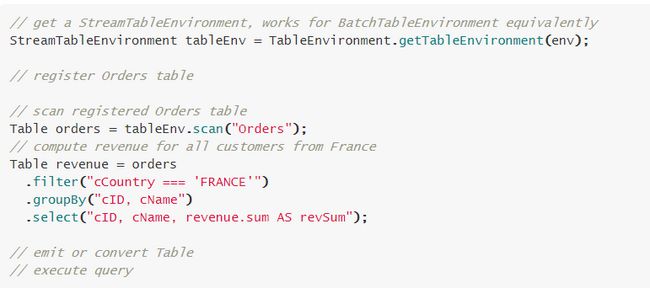
\\(1) Table API
\\Table API 是一个 Scala 和 Java 的集成查询序言。与 SQL 不同的是,Table API 的查询不是一个指定的 sql 字符串,而是调用指定的 API 方法。Table API 中的每一个方法输入都是一个 Table,输出也是一个新的 Table。
\\通过 table API 来提交任务的话,也会经过 calcite 优化等阶段,基本流程和直接运行 sql 类似:
\\- table API parser: Flink 会把 table API 表达的计算逻辑也表示成逻辑树,用 treeNode 表示 ;\\t
- 在这棵树上的每个节点的计算逻辑用 Expression 来表示。\\t
- Validate: 会结合 catalog 将树的每个节点的 Unresolved Expression 进行绑定,生成 Resolved Expression;\\t
- 生成 Logical Plan: 依次遍历数的每个节点,调用 construct 方法将原先用 treeNode 表达的节点转成成用 calcite 内部的数据结构 relNode 来表达。即生成了 LogicalPlan, 用 relNode 表示 ;\\t
- 生成 optimized Logical Plan: 先基于 calcite rules 去优化 logical Plan,\\t
- 再基于 Flink 定制的一些优化 rules 去优化 logical Plan;\\t
- 生成 Flink Physical Plan: 这里也是基于 Flink 里头的 rules 将,将 optimized LogicalPlan 转成成 Flink 的物理执行计划;\\t
- 将物理执行计划转成 Flink Execution Plan: 就是调用相应的 tanslateToPlan 方法转换。\
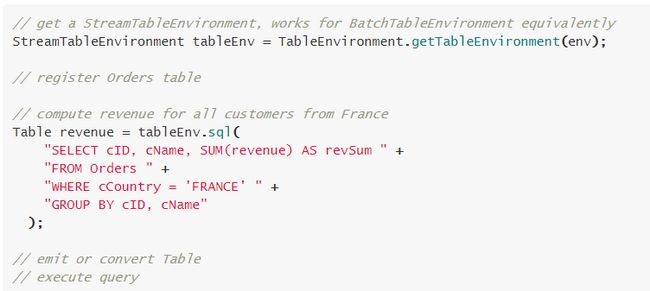
(2) SQL
\\Flink SQL 是基于 Apache Calcite 的实现的,Calcite 实现了 SQL 标准解析。SQL 查询是一个完整的 sql 字符串来查询。一条 stream sql 从提交到 calcite 解析、优化最后到 Flink 引擎执行,一般分为以下几个阶段:
\\- Sql Parser: 将 sql 语句解析成一个逻辑树, 在 calcite 中用 SqlNode 表示逻辑树 ;\\t
- Sql Validator: 结合 catalog 去验证 sql 语法;\\t
- 生成 Logical Plan: 将 sqlNode 表示的逻辑树转换成 Logical Plan, 用 relNode 表示 ;\\t
- 生成 optimized Logical Plan: 先基于 calcite rules 去优化 logical Plan,\\t
- 再基于 Flink 定制的一些优化 rules 去优化 logical Plan;\\t
- 生成 Flink Physical Plan: 这里也是基于 Flink 里头的 rules 将,将 optimized Logical Plan 转成成 Flink 的物理执行计划;\\t
- 将物理执行计划转成 Flink Execution Plan: 就是调用相应的 tanslateToPlan 方法转换。\
(3)Table\u0026amp;SQL API 混合使用
\\Table API 和 SQL 查询可以很容易的混合使用,因为它们的返回结果都是 Table 对象。一个基于 Table API 的查询可以基于一个 SQL 查询的结果。同样地,一个 SQL 查询可以被定义一个 Table API 注册 TableEnvironment 作为 Table 的查询结果。
\\4. 输出 Table
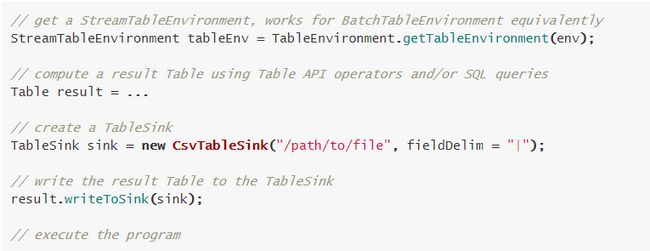
\\为了将 Table 进行输出,我们可以使用 TableSink。TableSink 是一个通用的接口,支持各种各样的文件格式 (e.g. CSV, Apache Parquet, Apache Avro),也支持各种各样的外部系统 (e.g., JDBC, Apache HBase, Apache Cassandra, Elasticsearch),同样支持各种各样的 MQ(e.g., Apache Kafka, RabbitMQ)。
\\批数据的导出 Table 使用 BatchTableSink, 流数据的导出 Table 使用的是 AppendStreamTableSink,RetractStreamTableSink 和 UpsertStreamTableSink.
\\
5. 解析 Query 并执行
\\Table\u0026amp;SQL API 查询被解析成 DataStream 或 DataSet 程序。一次查询就是一个 logical query plan,解析这个 logical query plan 分为两步:
\\- 优化 logical plan,\\t
- 将 logical plan 转为 DataStream 或 DataSet\
一旦 Table\u0026amp;SQL API 解析完毕, Table\u0026amp; SQL API 的查询就会被当做普通 DataStream 或 DataSet 被执行。
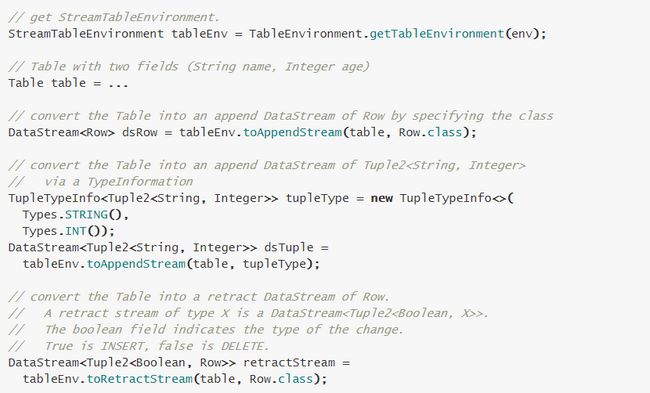
\\5.2 Table 转为 DataStream 或 DataSet
\\
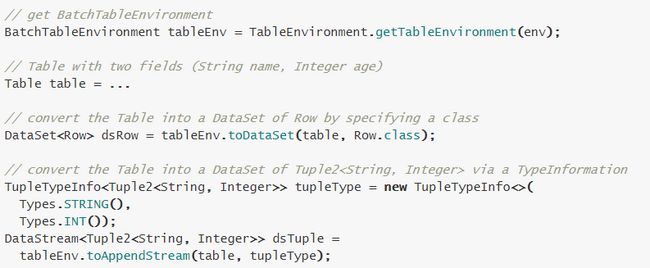
5.3 Convert a Table into a DataSet
\\
5.4 Table\u0026amp;SQL API 与 Window
\\Window 种类
\\- tumbling window (GROUP BY)\\t
- sliding window (window functions)\
(1) Tumbling Window
\\\SELECT STREAM TUMBLE_END(rowtime, INTERVAL '1' HOUR) AS rowtime,\productId,\COUNT(*) AS c,\SUM(units) AS units\FROM Orders\GROUP BY TUMBLE(rowtime, INTERVAL '1' HOUR), productId;\\\
(2) Sliding Window
\\\SELECT STREAM rowtime,\productId,\units,\SUM(units) OVER (ORDER BY rowtime RANGE INTERVAL '1' HOUR PRECEDING) unitsLastHour\FROM Orders;\\\
5.5 Table\u0026amp;SQL API 与 Stream Join
\\\Joining streams to streams:\SELECT STREAM o.rowtime, o.productId, o.orderId, s.rowtime AS shipTime\FROM Orders AS o\JOIN Shipments AS s\ON o.orderId = s.orderId\AND s.rowtime BETWEEN o.rowtime AND o.rowtime + INTERVAL '1' HOUR\\\
六、Table\u0026amp;SQL API 举例
\\首先需要引入 Flink 关系型 api 和 scala 的相关 jar 包:
\\\\u0026lt;dependency\u0026gt;\ \u0026lt;groupId\u0026gt;org.apache.flink\u0026lt;/groupId\u0026gt;\ \u0026lt;artifactId\u0026gt;flink-table_2.10\u0026lt;/artifactId\u0026gt;\ \u0026lt;version\u0026gt;1.3.2\u0026lt;/version\u0026gt;\\u0026lt;/dependency\u0026gt;\\u0026lt;dependency\u0026gt;\ \u0026lt;groupId\u0026gt;org.apache.flink\u0026lt;/groupId\u0026gt;\ \u0026lt;artifactId\u0026gt;flink-scala_2.10\u0026lt;/artifactId\u0026gt;\ \u0026lt;version\u0026gt;1.3.2\u0026lt;/version\u0026gt;\\u0026lt;/dependency\u0026gt;\\u0026lt;dependency\u0026gt;\ \u0026lt;groupId\u0026gt;org.apache.flink\u0026lt;/groupId\u0026gt;\ \u0026lt;artifactId\u0026gt;flink-streaming-scala_2.10\u0026lt;/artifactId\u0026gt;\ \u0026lt;version\u0026gt;1.3.2\u0026lt;/version\u0026gt;\\u0026lt;/dependency\u0026gt;\\\
6.1 批数据的相关代码
\\\List\u0026lt;DataPackage\u0026gt; data = new ArrayList\u0026lt;DataPackage\u0026gt;();\\t\tdata.add(new DataPackage(1L, \"Effy\