13.scala高阶函数定义及使用
目录
- 概述
- 实践
-
- map
- flatten
- reduce
- fold
- zip
- groupBy
- mapValues
- 排序
- 单词统计
- 结束
概述
高阶算子
实践
map
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
testMap
}
private def testMap = {
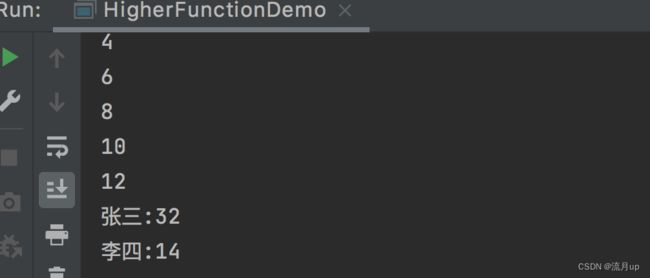
val list = List(1, 2, 3, 4, 5, 6)
list.map(_ * 2).foreach(println _)
val array = List(Array(("张三", 30)), Array(("李四", 12)))
array.map(x => x.map(y => (y._1, y._2 + 2))).foreach(m => m.foreach(cc => println(cc._1 + ":" + cc._2)))
}
}
执行结果如下:
flatten
扁平化
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
testFlatten
}
private def testFlatten = {
// flatten:扁平化
val list = List(List(1, 2, 3), List(4, 5))
list.flatten.foreach(print _)
val strings = List("hello one", "hello two", "hello three")
println("---")
strings.map(_.split(" ")).flatten.foreach(print _)
// flatMap: flatten + map
list.flatMap(_.map(_ * 2)).foreach(print _)
println("---")
strings.flatMap(_.split(" ")).foreach(print _)
}
}
执行结果如下:

reduce
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
// reduce
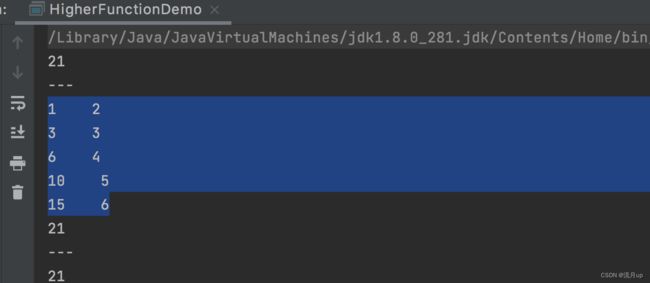
val list = List(1, 2, 3, 4, 5, 6)
println(list.reduce(_ + _))
println("---")
println(list.reduceLeft((x, y) => {
println(s"$x $y")
x + y
}))
println("---")
println(list.reduceRight(_ + _))
}
}
执行结果如下:
fold
在 reduce 基础上有了个初始值,而且
fold这个函数 还柯里化了。
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
// fold
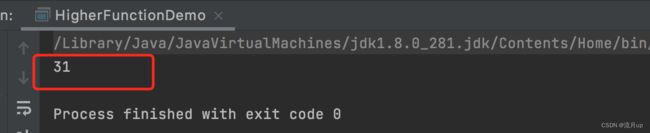
val list = List(1, 2, 3, 4, 5, 6)
// def fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 = foldLeft(z)(op)
println(list.fold(10)(_ + _))
}
}
执行结果如下:
zip
zip:合并/拉链
拉相同位置的元素,如果元素个数不对等,只会拉对等的元素,多的省略掉。
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
// zip:合并/拉链
val a = List(1, 2, 3, 4)
val b = List("A", "B", "C", "D")
println(a.zip(b))
val c = List("A", "B", "C", "D", "E")
println(a.zip(c))
println(a.zipAll(c, "-", "~"))
println(c.zipWithIndex)
}
}
执行结果如下:

groupBy
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
// 高阶算子详解 groupBy
val list = List(1, 2, 3, 4, 5, 6, 8)
println(list.groupBy(x => if (x % 2 == 0) "偶数" else "奇数"))
// 按 key 分组
val arr = Array(("a", 100), ("b", 10), ("a", 190), ("d", 10))
println(arr.groupBy(_._1))
}
}

mapValues
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
// mapValues 一定是使用在kv的数据结构上
val strings = List("hello one", "hello two", "hello three")
println(strings.flatMap(_.split(" ")).groupBy(x => x).mapValues(_.size))
}
}
执行结果如下:

排序
object HigherFunctionDemo {
def main(args: Array[String]): Unit = {
/**
* 排序:
* sorted 字符串按字典排序、数值类型按升序
*
*/
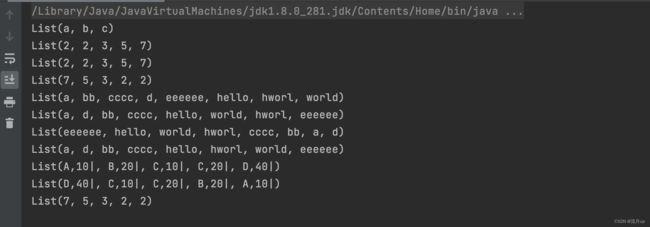
val list = List("c", "a", "b")
println(list.sorted)
val list2 = List(3, 2, 5, 2, 7)
println(list2.sorted)
println(list2.sortBy(x => x))
println(list2.sortBy(x => -x))
val list3 = List("cccc", "a", "bb", "d", "eeeeee", "hello", "world","hworl")
println(list3.sortBy(x => x))
println(list3.sortBy(_.length))
println(list3.sortBy(-_.length))
// 长度相等,按字典顺序排
println(list3.sortBy(x => (x.length, x)))
class Person( val name:String,val age:Int){
override def toString: String = s"$name,$age|"
}
val persons = List(new Person("A", 10), new Person("D", 40), new Person("C", 20), new Person("B", 20), new Person("C", 10))
println(persons.sortBy(x => (x.name, x.age)))
println(persons.sortBy(x => (x.name, x.age))(Ordering.Tuple2(Ordering.String.reverse, Ordering.Int)))
println(list2.sortWith(_ > _))
}
}
执行结果如下:
单词统计
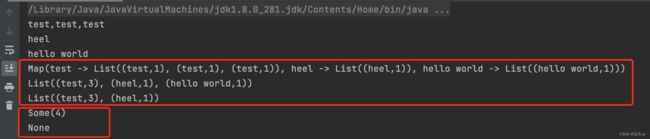
object WordCountDemo {
def main(args: Array[String]): Unit = {
val strings = Source.fromFile("data/wc.data", "utf-8").getLines()
for (line <- strings) {
println(line)
}
val list = Source.fromFile("data/wc.data", "utf-8").getLines().toList
println(list.flatMap(_.split(",")).map((_, 1)).groupBy(_._1))
val map = list.flatMap(_.split(",")).map((_, 1)).groupBy(_._1).mapValues(_.size)
println(map.toList.sortBy(-_._2))
println(map.toList.sortBy(-_._2).take(2))
val list2 = List(1, 2, 3, 4, 5, 6)
println(list2.find(_ > 3))
println(list2.find(_ > 7))
}
}
执行结果如下:
结束
scala高阶函数定义及使用 至此结束,如有疑问,欢迎评论区留言。