【电子科技大学】计算机高级图形学总复习
第一章:绪论
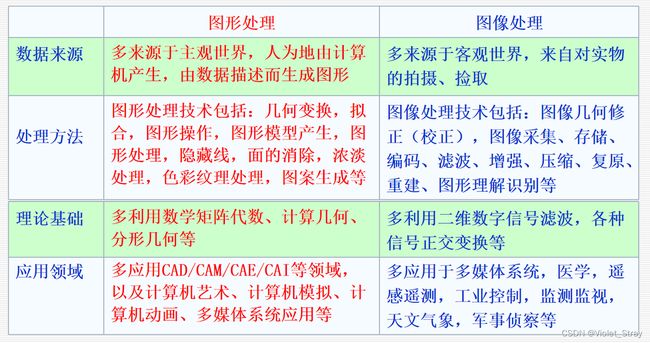
图形学和图像学
走样的原因和反走样
走样指的是:用离散量表示连续量引起的失真
反走样:为了提高图形的显示质量,需要减少或消除因走样带来的阶梯形或闪烁的效果,用于减少或消除这种效果的方法称为反走样。
反走样技术:
- 前滤波:以较高的分辨率显示对象
- 后滤波:加权区域取样
Bresenham算法
例题
第二章:颜色模型

RGB和CMY颜色模型比较

常用的HSV:

色调(Hue),饱和度(Saturation)和亮度(Value)
- 色调(Hue):想象一个彩虹色的圆圈,色调就是这个圆圈上的一个点,决定了颜色是红、黄、绿还是蓝等。它用角度来表示,从0到360度。红色是0度,绿色是120度,蓝色是240度。每个颜色的补色正好在圆圈上相差180度。
- 饱和度(Saturation):饱和度描述的是颜色的强烈程度,也就是颜色的“纯度”。它的范围从0%(完全不饱和,也就是灰色)到100%(完全饱和,最强烈的颜色)。在色盘上,饱和度从中心向边缘增加,中心是无色的,边缘是纯色的。
- 亮度(Value):亮度告诉我们颜色有多亮。它从0(完全黑暗)到1(最亮,也就是光的强度)。在HSV模型的圆锥表示中,亮度是从圆锥底部的黑色(V=0)到顶部的白色(V=1)。


各种颜色模型之间的转换算法:

RGB与CMY颜色模型之间转换算法:
RGB的取值通常是0~255的整数。
C = 255 – R
M = 255 – G
Y = 255 – B
RGB与HSV颜色模型之间转换算法:
查表法:
最可靠方法:
把RGB坐标转换为1931CIE-XYZ系统中的(x, y, Y)坐标
根据(x, y, Y)查找对应表,得到相应的(H, S, V)坐标
逆向操作则可以从HSV坐标转换到RGB坐标
xyY坐标与HSV坐标的对照表已由色度学实验得到[Newhall 1943]
这种方法需要依赖对照表,比较笨重。
数学公式:


RGB与CIE XYZ颜色模型之间转换算法:

CIE XYZ与CIE Lab*颜色模型之间转换算法:

RGB与CIE YUV颜色模型之间转换算法:

第三章:物体表示_多边形
两种坐标系的区别:
- 世界坐标系是用来定义所有物体在场景中的位置。就像房间坐标系一样,它是一个大范围内的参考,用来确定所有物体如何放置在这个虚拟“世界”中。
- 建模坐标系则是针对单个物体的。每个物体都是在它自己的坐标系中被创建和编辑的,就像是每件家具有自己的小平面图。这有助于设计者单独操作和调整每个模型,而不必担心其它模型或整个世界的坐标。
有多少种坐标系

三角形网格表示的数据结构BREP

BRep是什么:网格表示数据结构
BRep表示的两种类型:拓扑信息(网格之间的关系)、几何信息(网格坐标在哪,大小是多少)
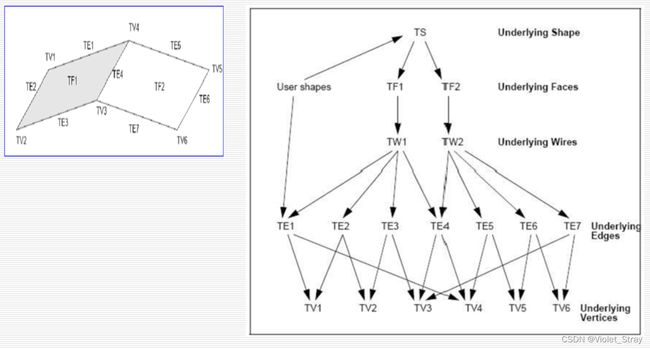
于是诞生了:
![[图片]](http://img.e-com-net.com/image/info8/40c49efad1a14898afa033b5894ac46e.jpg)
半边结构:是怎样的,记录的是什么

即使包含了面、顶点和边的邻接信息,数据结构的大小是固定的(没有使用动态数组)且紧凑的。

要掌握的例题:(其实没写完)

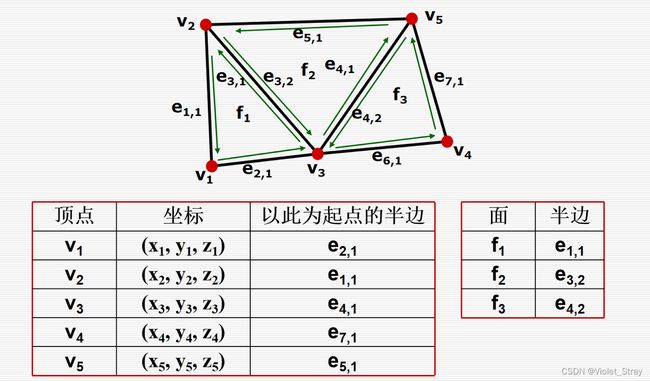
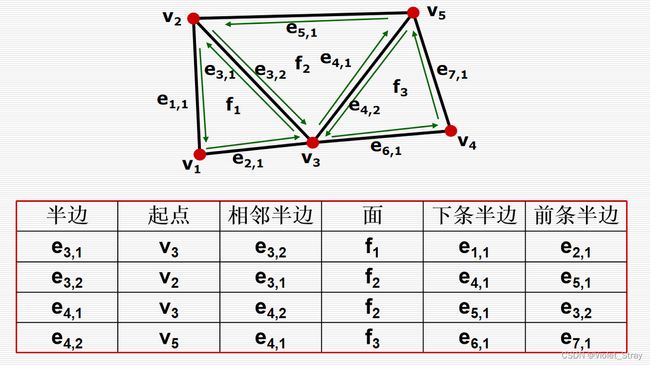
多边形表示方法:OBJ格式
OBJ文件是一种文本文件,包含了表示三维几何形状的数据。


纹理是指覆盖在三维模型表面的图像,它给模型增加了颜色和细节,让模型看起来更加真实和复杂。纹理可以是简单的颜色图案,也可以是高度复杂的图片,如照片或者绘画作品。
半边存顶点坐标,法向量、纹理也要存,要存光线、颜色、几何
真实的obj不考
多边形表示的优点:
表示简单
可以表示具有任意拓扑的物体
可以表示具有丰富细节的物体
大部分图形硬件支持多边形物体的加速绘制
多边形表示的不足:
逼近表示,难以满足交互时放大要求
难以用传统方法修改(编辑)物体外形
缺乏解析表达式,几何属性计算困难
在表示复杂拓扑和具有丰富细节的物体时,数据量庞大,建模、编辑、绘制、存储的负担重
第三章:物体表示_参数曲面
以前都没出过b样条的计算,这次要出b样条的计算
直线的参数方程
参数表示的数学原理:

参数表示的数学原理:曲线:曲线就是在原来的直线上面加了个点c

参数表示的优点:
- 参数表示是显式的
- 对每一个参数值,可以直接计算曲面上的对应点
- 参数表示的物体可以方便地转化为多边形逼近表示
- 曲面上的几何量计算简便(微分几何):法向、曲率、测地线、曲率线等
- 特殊形式的参数表示的外形控制十分直观
- Bézier、B-样条、NURBS (Non-Uniform Rational B-Spline, 非均匀有理B-样条)曲线/曲面
Bezier曲线定义:(函数大概了解,不用记下来)
这个函数代表计算机的一种计算方法(模拟曲线)

Bezier曲线性质:
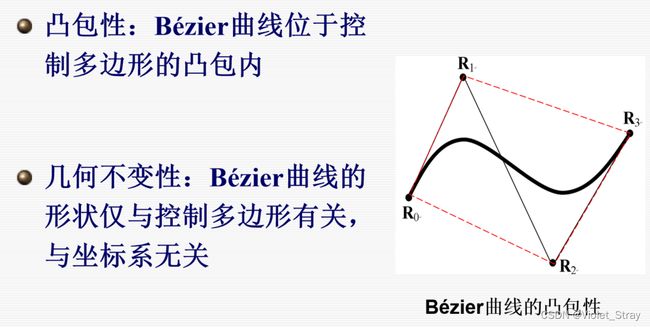
初始:(R0,R1,R2,R3)
然后每次选取中间(或者其他比例)的点
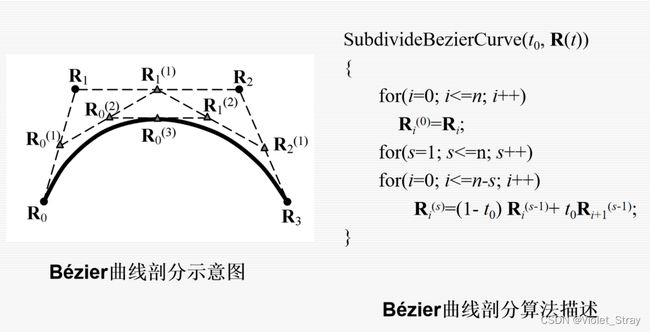
Bezier曲线的不足:(灵活性差、可以做细分)

例题:
下列有关Bezier曲线性质的叙述语句中,错误的结论为( B )
A Bezier曲线可用其特征多边形来定义;
B Bezier曲线不一定通过其特征多边形的各个顶点;(除了首尾两个控制点外,Bezier曲线不一定通过其特征多边形的其他顶点。)
C Bezier曲线两端点处的切线方向必须与其特征折线集(多边形)的相应两端线段走向一致;
D n次Bezier曲线,在端点处的r阶导数,只与r个相邻点有关。
B-样条曲线的定义:(在上面的函数上改成分段函数)

开放均匀的B-样条曲线:(例子,到时候把u给大家,求一次、二次b样条)
在两端的节点值重复d次,其他节点是均匀的
https://zhuanlan.zhihu.com/p/561065426

在图中,我们有一个由四个控制点定义的B样条曲线(因为 n=3 ,而控制点的数量总是n+1),并且这个曲线是三次的(因为 k=3)。这里提到的 u 是参数值,它定义了曲线上特定点的位置。
基函数的和在每一个参数值 u 上都是1。这是B样条曲线的一个重要性质,意味着所有基函数的加权和会构成曲线,并且保持曲线的连续性和平滑性。

B样条曲线的定义:
- k 是曲线的次数,它表示构成曲线的单个多项式段的最高次幂。例如,对于二次B样条曲线,k 是2,因为它使用的是二次多项式。
- n 是控制点数量减去1。所以如果你有 n+1 个控制点,那么 n 就是控制点的数量减去1。



B样条例题:



B样条的缺点:因为是分段函数,无法拟合圆形,分段还不够,所以要加权重(即NURBS)

B样条性质:
B-样条曲线具有凸包性和几何不变性。
当曲线的两个端节点的重复度是k+1时
B-样条曲线具有类似于Bézier曲线的性质
端点插值性质
端点导数与控制的起始边与终止边相切
当n=k+1时,B-样条曲线就是一条Bézier曲线
例如,三次(四阶)B-样条,则节点向量
{0,0,0,0,1,1,1,1}
引入NURBS曲线的原因:
给一个图形,用什么函数来模拟
B样条曲线是NURBS的特殊情形。


NURBS曲线表示圆:

曲线的进化
B样条曲线相较于Bézier曲线的优点:
B样条曲线具有局部控制性质。这意味着移动一个控制点只会影响曲线的一小部分,而不是整个曲线。相比之下,贝塞尔曲线的一个控制点的移动可能影响整条曲线的形状。
第三章:物体表示_subdivision surface
细分曲面的作用:
细分曲面会改两个东西:几何规则(因为点增加了)、拓扑规则(点之间的连接关系变了),其实就是算几何和拓扑之间怎么变

细分方法:
具体怎么细分的不要求大家知道,但要知道有哪些细分方法(Loop族的)

第三章:物体表示_隐式曲面

(主要考这个)物体的CSG树表示(几何物体的表示)

CSG树的缺点
绘制耗时
限制了物体外形的修改
改进:混合表示
将边界表示和布尔运算结合起来,形成一种界与边界表示和CSG实体表示之间的混合表示
分型:分型维数怎么算、(给你一个图形算分型维数),记Koch雪花、前面还有几种分型


一个L-系统实例,给一个文法,推出表示

有个练习
粒子系统不考
第四章:Pipeline
靠记忆
渲染3D场景:每层是干啥的

相机参数:内参、外参
pipeline:每一个步骤是干啥的
1.Model&Camera Parameters
- 位置:三个坐标定义了相机在3D空间中的确切位置。
- 眼睛位置(px, py, pz)
- 方向
- 视图方向(dx, dy, dz)指定了从相机位置指向观察目标的向量。
- 向上方向(ux, uy, uz)相机的“上”方向。在3D空间中,这有助于确定相机的倾斜。
- 光圈
- 视野(xfov, yfov)相机可见场景的范围。xfov和yfov分别代表水平和垂直视野角度。
- 胶片平面
- “注视”点。相机镜头所对准的点,通常位于视图方向上某一点。
- 视平面法线。胶片平面的法线向量,有助于确定平面的方向和相机视线的角度。
2.Rendering Pipeline
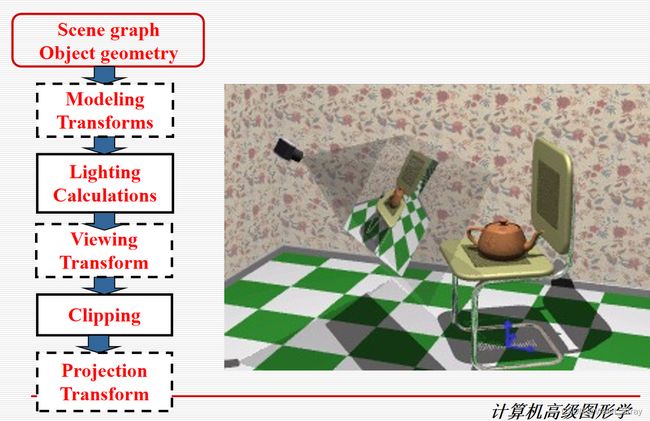
Scene graph Object geometry:
将场景中所有物体的顶点放置到一个共享的三维“世界”坐标系统中。
Modeling Transforms建模变换:建模坐标系->世界坐标系
渲染管线中的变换部分:
建模变换(Modeling Transforms):
建模变换是在建立或编辑三维模型时使用的。这些变换决定了模型的位置、旋转、缩放等,可以理解为是在虚拟世界中放置和调整模型的过程。比如,你可以将一座房子模型放在地面上,然后将它缩放到合适大小,或者旋转以面向正确的方向。
Lighting Calculations光照计算:所有几何体计算光线亮度
"光照计算(Lighting Calculations)"部分是渲染管线中的一个关键环节,它负责对场景中的所有几何图元进行照明处理,以模拟现实世界中的光照效果。
在这个过程中,需要考虑以下几个光照参数:
- 光源发射(Light source emission):这涉及到光源的颜色和强度,包括它是如何发射光线的,例如点光源、聚光灯或环境光。
- 表面反射率(Surface reflectance):每种材料都有不同的反射特性,这决定了光线击中表面时反射的量,以及光线反射的方式,例如漫反射或镜面反射。
- 大气衰减(Atmospheric attenuation):这是指光线在通过大气(或其他介质)时强度的减弱,可能由于雾、烟、灰尘或其他空气粒子。
- 相机响应(Camera response):这模拟了真实相机对光线的响应,如光线如何被相机感光元件捕获,并转换成图像。
在光照计算过程中,我们通常区分直接照明和全局照明: - 直接照明(Direct illumination):
- 光线投射(Ray casting):这是一个简化的光线追踪过程,计算从光源到物体的直线路径上的光照效果,但不考虑光线反射或折射。
- 多边形着色(Polygon shading):这是决定物体表面不同部分如何响应光照的过程,比如决定哪些部分更亮或更暗。
- 全局照明(Global illumination):
- 光线追踪(Ray tracing):这是一个更复杂的模拟过程,考虑了光线从光源出发后在场景中反射和折射的全过程,可以产生阴影、反射和透明等效果。
- 蒙特卡洛方法(Monte Carlo methods):这是一种统计模拟方法,用随机采样的方式来近似光照效果,尤其适用于复杂光照场景和材质的渲染。
- 辐射度方法(Radiosity methods):这种方法通过计算光线在表面间的能量交换来模拟间接照明,特别适用于模拟漫反射光。
Viewing Transform视图变换:3D场景转换到视窗/相机坐标系
“Viewing Transform” 即视图变换,其结果是:场景顶点位于3D“视图”或“相机”坐标系统中。
视图变换的步骤包括:
- 旋转和平移世界,使其直接位于相机前方。
1.1 通常将相机放置在原点。
1.2 通常使相机沿着-Z轴方向观看。 - 世界坐标变为视图坐标。
让我们通俗地解释一下:
在3D图形渲染中,视图变换是将整个3D场景的坐标变换到相机坐标系统中的过程。这样做的目的是为了模拟相机的视角,让渲染出的图像符合从这个特定视角看到的场景。 - 旋转和平移:想象你拿着一台相机,你可以移动相机到你想要的位置,然后旋转它直到你看到的场景是你想要拍摄的。在3D渲染中,我们通过数学变换来实现这一点,首先是旋转整个场景,使得你想要的视图面向相机。接下来是平移,将场景移动到相机前方的正确位置。
- 相机放置在原点:在3D渲染的数学模型中,为了简化计算,我们通常将相机放置在原点,这意味着在变换后的坐标系统中,相机位于(0, 0, 0)。
- 相机朝向-Z轴:同样为了简化计算,我们通常设置相机朝向-Z轴的负方向观看,这是因为在大多数图形软件中,-Z轴通常是指向屏幕里面的方向。
- 坐标转换:完成旋转和平移后,场景中每个物体的世界坐标(即它们在整个3D空间中的位置)就会被转换成视图坐标(即从相机的角度看它们的位置)。这个步骤是为了准备接下来的投影变换,即将3D场景投影到2D屏幕上。
简而言之,视图变换就是调整整个3D场景,使其符合相机的位置和朝向,就像在现实世界中移动和旋转相机一样。这样做的结果是,渲染出的图像会反映出从特定位置和角度观察到的场景。
Clipping裁剪:除去视窗外的几何物体部分
结果:移除视图之外的几何体。
通俗易懂的解释:
在三维图形渲染过程中,裁剪是一个重要的步骤,其目的是移除那些用户在当前视角下看不见的几何体。这样做的好处是可以提高渲染效率,因为不必处理那些最终不会出现在最终图像上的数据。
想象一下你用相机拍照,你的镜头只能捕捉到一定范围内的景象,这个范围就像是一个视野框。在三维渲染中,我们也有一个虚拟的“镜头”,它只能“看到”一定范围内的物体。裁剪的过程就是确定哪些物体在这个视野框内,哪些是在外面。在外面的物体就会被裁剪掉,因为它们无论如何都不会被渲染到最终的图像上。
在技术上,裁剪通常发生在将三维场景转换到二维图像之前的某个点,确保只有那些可能被用户看到的物体才会进入下一步渲染流程。这个过程不仅包括裁剪掉完全在视野外的物体,也可能涉及到将部分位于视野边缘的物体进行适当裁剪,使其与视野边界匹配。
Projection Transform投影变换:转为2D坐标系/图像坐标系
结果:裁剪后顶点的二维屏幕坐标。(三维转为二维)3D到2D的转换过程,它定义了物体在视图平面上的位置和形状。
通俗易懂的解释:
投影变换是三维渲染管线中的一个步骤,它的作用是将三维场景中的物体映射到二维屏幕上。这个过程类似于现实世界中,物体通过光线在我们眼前的幕布上形成影像。
在这个过程中,我们首先需要对三维坐标进行计算,以便它们能正确地反映在二维屏幕上。这涉及到两种主要的投影方式:
- 透视投影(Perspective Projection):这种方式会模拟人眼观察现实世界的效果,远处的物体看起来会更小。这样可以创建出深度感和远近感。
- 正交投影(Orthographic Projection):在这种方式中,所有的物体无论远近都保持相同的大小,这种投影通常用于工程图纸或建筑设计,因为它可以准确地保持物体的比例和角度。
一旦完成投影变换,每个顶点就会有相应的二维屏幕坐标,这些坐标决定了每个顶点在屏幕上的确切位置。这些二维坐标接下来将被用于绘制屏幕上的像素,生成最终图像。在投影变换之前进行的裁剪步骤确保了只有那些真正能够被用户看到的部分才会被投影到屏幕上,这样可以提高渲染效率,避免处理不必要的信息。
投影变换:
- 应用透视缩小效果
- 远处的物体看起来更小:这就是小孔相机模型
- 将视图坐标转换为屏幕坐标
通俗易懂的解释:
在3D图形渲染过程中,"投影变换"是将场景中的对象从三维空间转换到二维屏幕上的过程。 - 透视缩小效果:这是一种视觉效果,使得在观察者视线方向上距离较远的物体比近处的物体看起来更小,这样可以在二维屏幕上创建出三维空间的深度感。
- 小孔相机模型:这是一个用于解释透视效果的基础模型,它假设所有从场景中的点发出来的光线都通过一个点(相机的小孔)聚焦。这个模型说明了为什么远处的物体看起来更小——因为通过小孔的光线聚焦在较小的区域上。
- 视图坐标转换为屏幕坐标:在3D场景被透视投影到二维屏幕上之后,每个点的位置(现在被称为视图坐标)需要被进一步转换成屏幕坐标。屏幕坐标决定了每个点在屏幕上的具体位置,这样才能在显示设备上正确地绘制出来。这个转换涉及到计算视图坐标与屏幕像素坐标之间的关系,包括考虑屏幕的分辨率和视口的尺寸。
Rasterize光栅化:转换图像坐标系为像素和颜色
在渲染管线中,“光栅化(Rasterize)”负责将投影变换得到的2D图像转换为实际的像素(或点阵图)。并确定哪些像素将被渲染以及如何渲染。
- 转换屏幕坐标到像素颜色:这意味着确定由三维物体边缘定义的线条或曲面在屏幕上应该覆盖哪些像素点,并为这些像素点着色。
- 绘制直线和曲线:例如,图中显示了一个圆形,它是通过在网格上标记与圆形边缘最接近的像素点来绘制的。这包括了一种称为“8-way Symmetry”的技术,即利用圆的对称性来减少计算量,只计算圆的一部分然后将其镜像到其他部分。
- 处理斜率:图中还展示了处理不同斜率的直线时光栅化的例子。斜率大于1的情况下,线条在垂直方向上的增量大于水平方向,而斜率小于1时则相反。
通过光栅化,我们可以把三维场景中的物体转换为二维屏幕上的一系列像素点,这样就可以在显示设备上呈现出来。这一过程是实时渲染中的关键步骤,它直接影响到渲染出来的图像的质量和效率。
第五章:变换
齐次坐标系及其作用
齐次坐标就是n维空间中的物体可以用n+1维坐标空间来表示
作用:矩阵变换的统一表示、防止浮点数溢出
二维平移:

二维旋转:

二维放缩:

二维剪切变换:
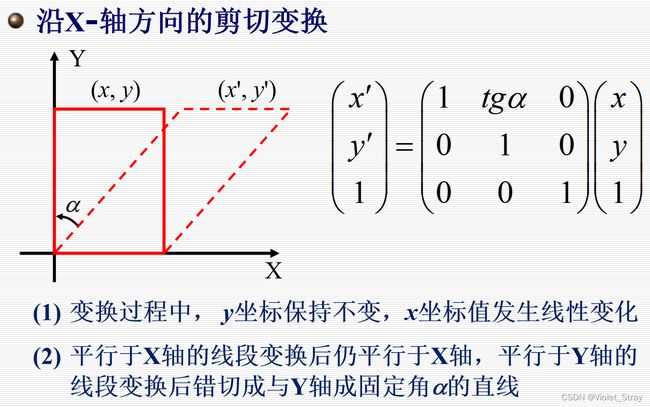
课堂练习:
给你一个变换矩阵,你要知道是干啥的,给一个结果,矩阵怎么求?


三维主要掌握投影变换
至多只能有三个主灭点,可以有无数个灭点
一点透视:


从以上结果可以看到:当Y值无限变大时,所有点经过变换后均集中于Y轴上的 1/q 处,于是所有平行于Y轴的直线将延伸相交于此点。 该点( 0,1/q ,0)称为灭点。形成一个灭点的透视称为一点透视。为了取得较好的效果,取 q0 。(让灭点位于Y轴的负半轴上)

两点透视(成角透视):


三点透视:

三维透视投影的齐次坐标表示

投影:是一个矩阵,不是三个矩阵,是用一个矩阵,带入的图形角度不一样,生成的矩阵自然不一样。投影怎么算的,要会。
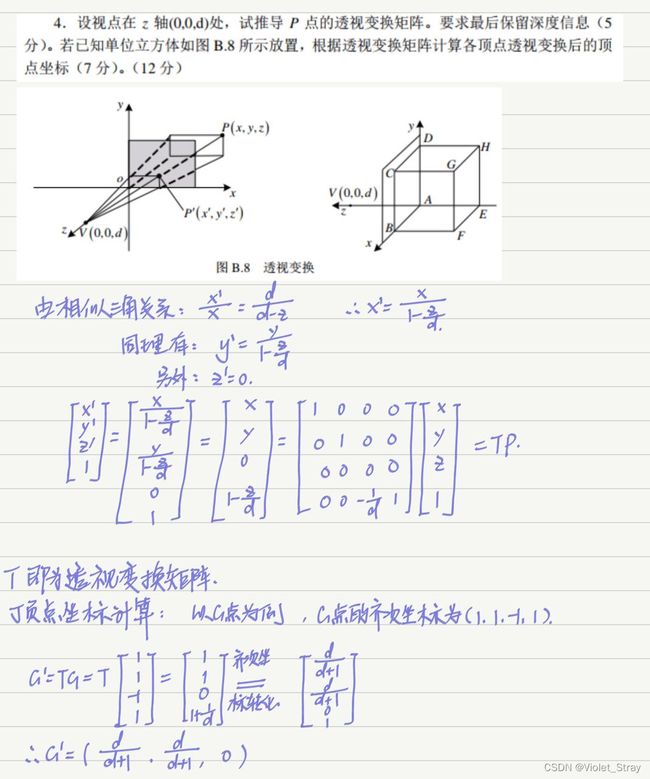
三维模型变换:放缩

三维模型变换:旋转

三维模型变换:平移

第六章:裁剪
三维变换流程图:剪裁算法出现在那些地方

各种坐标系:
- 局部坐标系(Local or Object Coordinates):
- 个体的私人空间,每个对象都有自己的参考点,通常是它的中心或一个角点。
- 一句话总结:局部坐标系是对象自己的坐标系统,用来定义它的形状和大小。
- 世界坐标系(World Coordinates):
- 共享的公共空间,所有对象都相对于一个共同的全局参考点来定位。
- 一句话总结:世界坐标系是一个统一的空间,用于确定多个对象在同一个环境中的位置和方向。
- 视点坐标系(View Coordinates or Camera Space):
- 相机的个人空间,所有对象都相对于观察者的视点来定位。
- 一句话总结:视点坐标系是以观察者或相机的位置和方向为参考的坐标系统。
- 图像坐标系(Image Coordinates):
- 在二维图像中,定义像素位置的坐标系统,通常与屏幕坐标系相关。
- 一句话总结:图像坐标系是二维图像上的坐标系统,用于定位像素点。
- 规格化坐标系(Normalized Device Coordinates, NDC):
- 均匀的标准空间,所有对象都被转换到一个标准化的立方体内,无论它们在世界空间中的实际大小或位置。
- 一句话总结:规格化坐标系是一个规范化的空间,所有对象的坐标都被转换到-1到1之间。
- 屏幕坐标系(Screen Coordinates):
- 显示设备的坐标系统,用于确定如何在屏幕上渲染对象。
- 一句话总结:屏幕坐标系是将对象映射到实际显示设备屏幕上的坐标系统。
各种变换:
- 建模变换/造型变换(Modeling Transformation):3D->3D
- 功能:调整和定位3D对象在场景中的位置、大小和方向。
- 一句话总结:将对象从它自己的局部坐标系转换到共同的世界坐标系中定位。
- 观察变换/取景变换(View Transformation):3D->3D
- 功能:设置和调整观察者(摄像机)在场景中的位置和朝向。
- 一句话总结:将世界坐标系中的对象转换到观察者的视点坐标系中。
- 投影变换(Projection Transformation):3D->2D
- 功能:将3D场景转换成2D视图,可以是透视投影(近大远小,模拟人眼视觉效果)或正交投影(保持物体大小不变形)。
- 一句话总结:将视点坐标系中的对象映射到一个二维视平面上,以创建三维效果的二维图像。
- 设备变换(Device Transformation):2D->像素
- 作用:将2D视图转换为特定显示设备(如计算机屏幕)的坐标系统。
- 解释:将归一化的坐标转换为具体设备的屏幕坐标,如像素位置。
- 视窗变换(Viewport Transformation):像素->显示窗口
- 功能:定义在屏幕上显示的区域,决定了3D场景如何映射到2D显示设备上。
- 一句话总结:将二维视平面上的图像调整到最终显示窗口的大小和位置。
直线裁剪算法:要掌握

Cohen-Sutherland,提出了一种空间编码

0(上)0(下)0(右)0(左)
比较流程:
![[图片]](http://img.e-com-net.com/image/info8/9ed328ec49f541d5a5f601ac15df9e72.jpg)
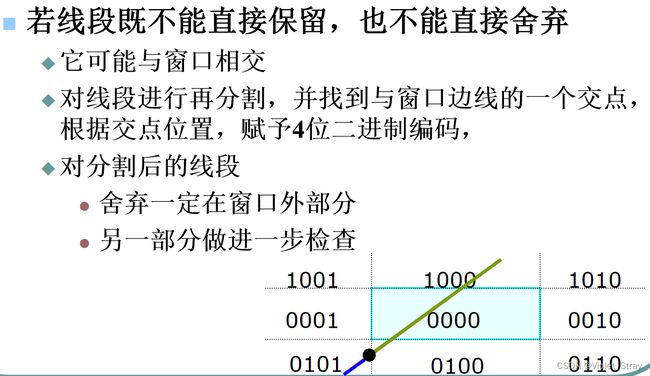
例题:



中点分割:解决了怎么计算交点

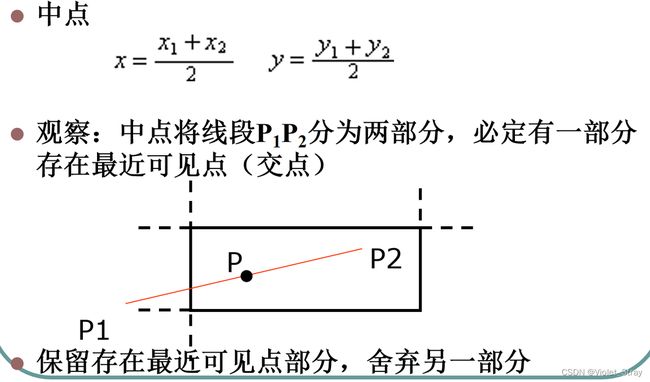

梁友栋——Barsky算法:p点在什么地方,

例题1
例题2

WA任意多边形裁剪算法步骤:掌握例子,d出去了,到的下一个是哪个点

第七章:光栅化
图形学中多边形的两种表示方式
顶点表示:用多边形的有序顶点序列表示多边形
点阵表示:用位于多边形内部的像素集合来表示多边形
点阵表示的区域填充:怎么填的、算法是怎么搞得(递归,四联通、八联通)

四联通和八联通:
四连通区域:区域内任意两个像素,从一个像素出发,可以通过上、下、左、右四种运动,到达另一个像素
八连通区域:区域内任意两个像素,从一个像素出发,可以通过水平、垂直、正对角线、反对角线八种运动,到达另一个像素
练习题:(ppt上的练习都是要考的)

递归弹出
内部表示区域种子填充算法:(左上右下的顺序)

连贯性:
逐点判断算法:
逐点判断算法:逐个像素判别其是否位于多边形内部
判断一个点是否位于多边形内部:射线法
从当前像素发射一条不经过顶点的射线,计算射线与多边形的交点个数
- 内部:奇数个交点
- 外部:偶数个交点
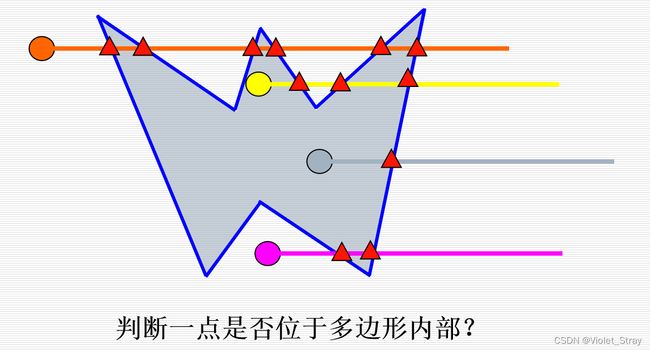
速度慢:几十万甚至几百万像素的多边形内外判断,大量的求交、乘除运算
没有考虑像素之间的联系
结论:逐点判断算法不可取!
区域连贯性:
梯形分为两类:多边形内部和多边形外部
结论:两类梯形在多边形内部相间排列(相邻的两个梯形必然有一个位于多边形内部,有一个在多边形外部)

推论:如果上述梯形属于多边形内(外),那么该梯形内所有点的均属于多边形内(外)。
效率提高的根源:逐点判断->区域判断
扫描线的连贯性:区域连贯性在一条扫描线上的反映
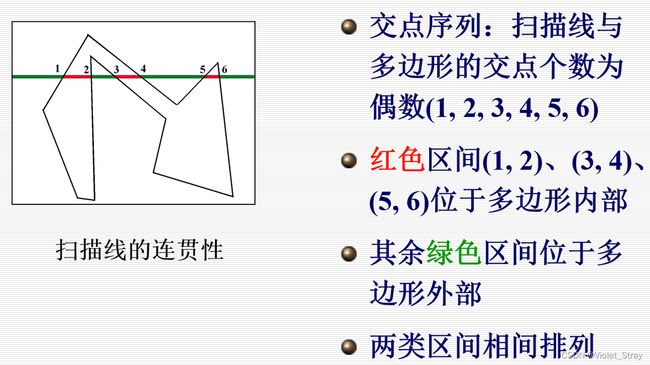
如果上述交点区间属于多边形内(外),那么该区间内所有点均属于多边形内(外)。
边的连贯性:直线的线性性质在光栅上的表现
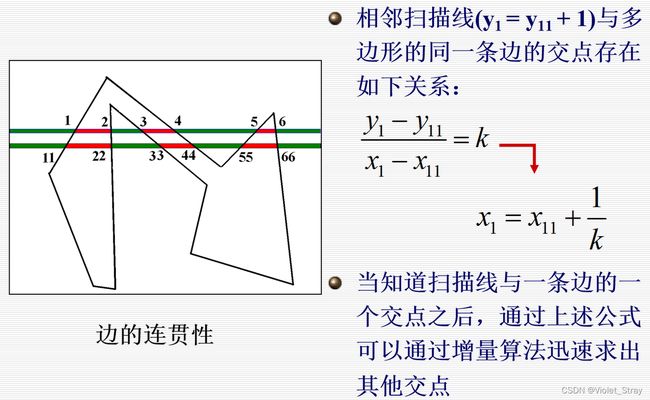
边的连贯性是连接区域连贯性和扫描线连贯性的纽带
扫描线连贯性+边连贯性=区域连贯性
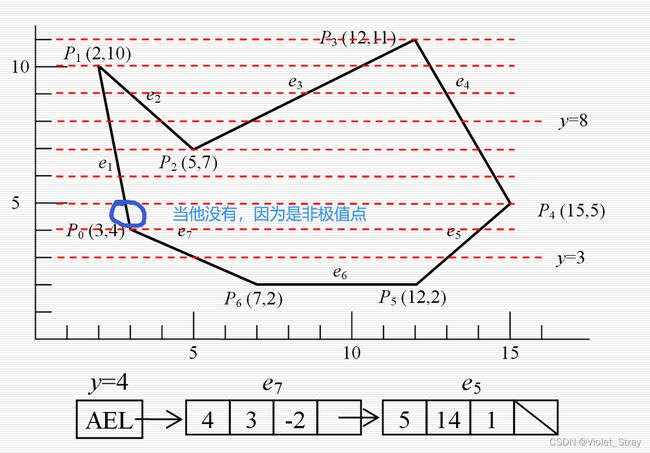
奇异点的处理

极值点(线都在同一侧)算两个交点
非极值点(线两侧都有)算一个交点
处理非极值点的奇异点:将扫描线上方线段截断一个单位,这样扫描线就只与多边形有一个交点。
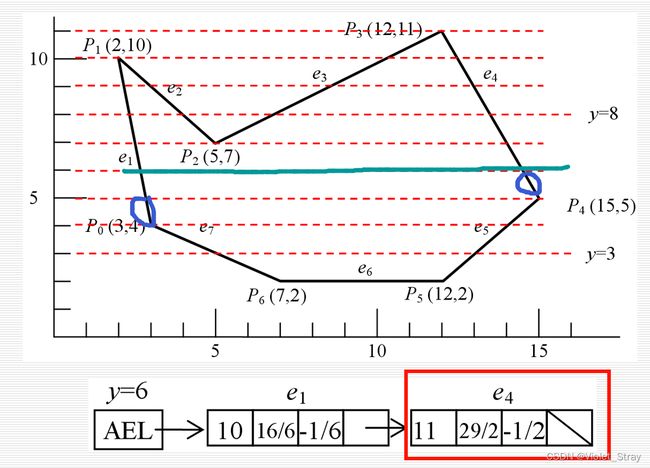
多边形扫描转换算法:
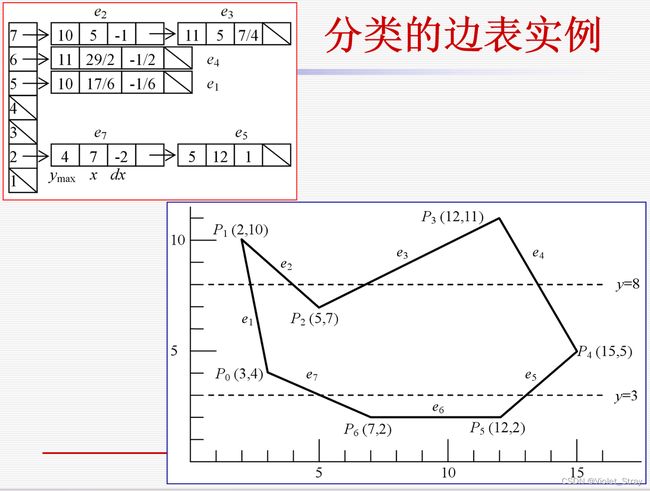
算法的数据结构与实现

分类的边表(ET)


例子:


极值点的处理:

第八章:消隐
了解这两种消隐不同的特性:图像空间、对象空间,算法特点、与什么相关的
图像空间消隐算法:(z-buffer、扫描线、光线跟踪)
算法框架:

- 遍历每个像素:算法会遍历图像中的每个像素点。
- 建立像素与视点的连接:对于每个像素点,算法会从视点(也就是相机或观察者的位置)到这个像素点建立一条射线。
- 寻找最近的物体:算法沿着建立的射线在场景中查找与射线相交的最近的物体。这个过程通常涉及到检测射线与场景中每个物体的交点,然后选择最近的交点所在的物体。
- 计算像素颜色:确定了最近物体之后,算法会计算该像素点的颜色值。这一步通常会考虑光照、物体材质、阴影等因素。
- 输出渲染结果:将计算出的颜色值赋予对应的像素点,最终所有像素点的颜色值确定后,形成最终的渲染图像。
算法特点:
受分辨率限制
时间复杂度 O(nN):
- 每个象素都需对物体排序(能否采用连贯性)
- n: polygons数
- N: 像素个数
算法:z-buffer, scan line algorithm
对象空间消隐算法:
算法框架:

- 遍历每个物体:算法会检查场景中的每个物体。
- 确定不被遮挡的部分:对于每个物体,算法会确定它的哪些部分是可见的,即没有被其他物体遮挡的部分。这通常涉及复杂的数学计算,如确定物体之间的相对位置和方向。
- 使用扫描转换算法找到像素:一旦确定了物体的可见部分,算法就使用扫描转换算法来计算这些可见部分在屏幕上的像素位置。扫描转换算法负责将物体的连续几何形状转换为像素网格上的离散点。
- 计算像素的颜色:最后,算法计算每个像素的颜色,这通常包括光照、阴影、材质属性等因素的计算。
算法特点:
适合于精密的CAD工程领域
复杂度 O(n2):
- n: 对象数
Back surface culling
(后向面剔除)
画家算法
(2D投影空间中操作,与其他的消隐算法的不同)
首先绘制最远的部分,然后逐渐绘制更靠近观察者的部分。通过这种方式,后绘制的物体会遮挡之前绘制的物体,从而解决了对象间的遮挡关系。
算法原理
- 排序:首先将所有要绘制的物体按照它们到观察者的距离进行排序,最远的物体排在最前面。(面片多时很耗时)
- 逐个绘制:按照排序的顺序,从最远到最近逐个绘制物体。因此,靠近观察者的物体会被绘制在远处物体的上面。
z-buffer算法:(重点掌握)

- 初始化颜色缓冲区(c-buffer):这是屏幕上每个像素的颜色存储区。初始时,它会被清空或设置为背景色。
- 初始化Z-buffer:这是一个与颜色缓冲区大小相同的数组,记录每个像素点的深度信息(即Z值,表示距离观察者的远近)。初始时,它会被设置为最大深度值,表示最远距离。
- 对每个多边形进行处理:
- 遍历多边形的每个像素(这个过程称为光栅化)。(任意顺序进行显示)
- 对每个像素计算它在3D空间中的深度Z值。
- 比较当前像素的Z值与Z-buffer中存储的Z值:
- 如果当前像素的Z值小于Z-buffer中的值(意味着它更靠近观察者),则更新c-buffer中该像素的颜色为当前多边形的颜色,并将Z-buffer中的值更新为当前像素的Z值。
- 如果当前像素的Z值不小于Z-buffer中的值,则不做任何操作,因为当前多边形在该像素位置被其他更近的表面遮挡。
z-buffer:如何计算z值
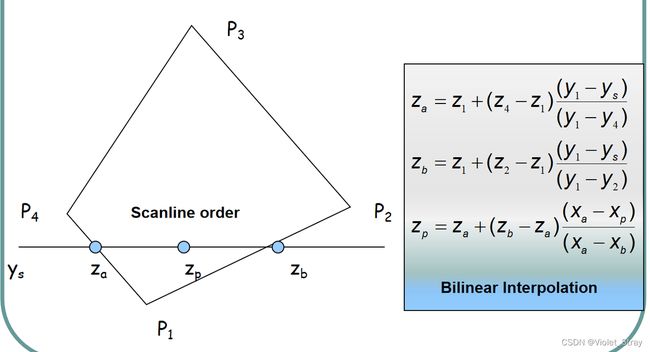
通过c-buffer计算z-buffer例子:
给大家一个c-buffer(颜色缓冲区)和一个z-buffer,给大家几个面片,要把最后的c-buffer和z-buffer都填充出来
1.第一步初始化。Zbuffer的每个像素初始化为正无穷。Cbuffer每个像素初始化为0
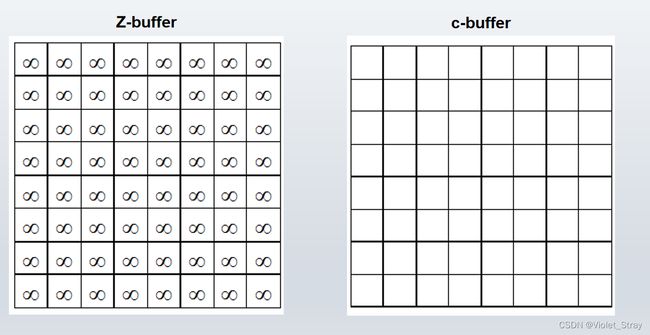
2.计算第一个多边形
[0,7,5]的意思是,x为0,y为7(从左下角到右上角,第一格为0),赋值为5
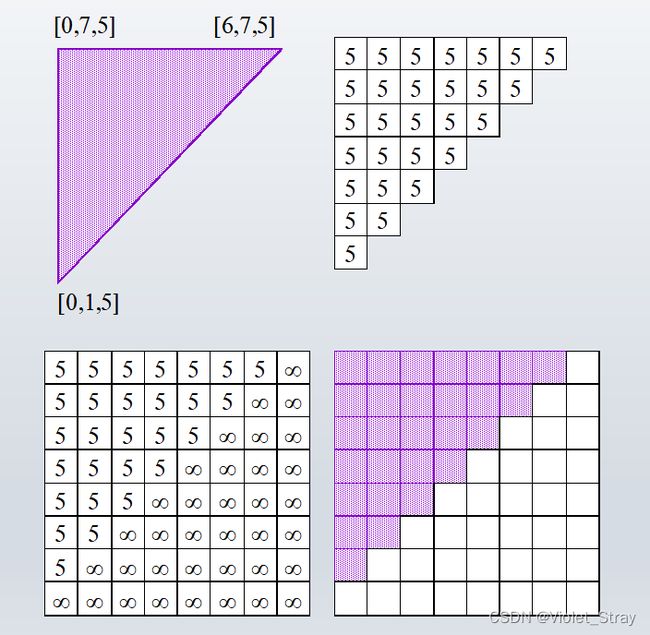
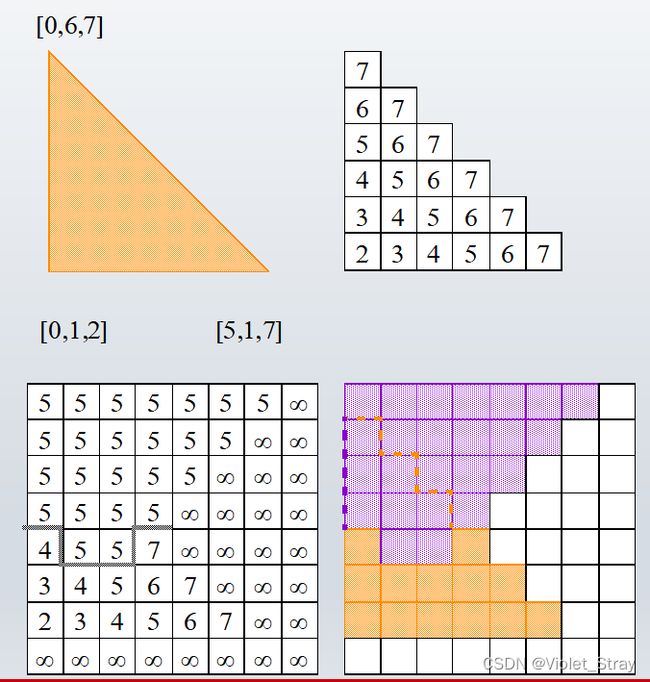
这里的赋值是递增的
不考:re-cosin
课堂练习:如何计算z值
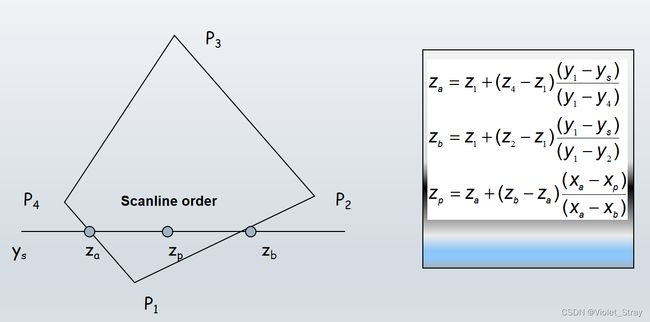
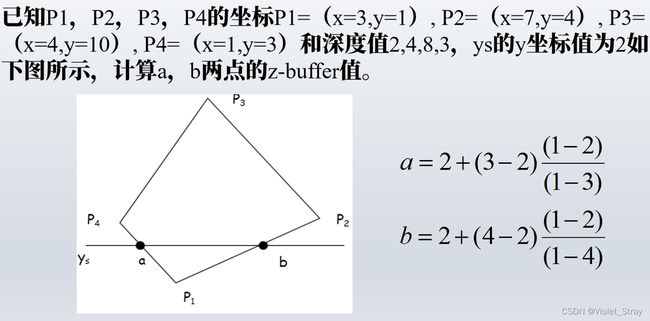
z-buffer优缺点:
缺点:(面片多的时候效率低)
- 内存消耗:
- Z-buffer需要为每个像素存储深度值,这在高分辨率渲染中会消耗大量内存资源。
- 精度问题:
- 深度值的精度受限于Z-buffer的位深。在某些情况下,比如非常远或非常近的物体,可能会出现深度冲突或精度不足的问题。
- 无法处理透明度:
- Z-buffer通常无法直接处理透明物体,因为它只记录了最近物体的深度信息,而透明度需要考虑后面物体的贡献。
- 过度绘制问题:
- 在Z-buffer中,即使某些像素最终会被遮挡,它们也可能被渲染,这导致了无谓的计算,尤其是在复杂场景中。
二叉空间剖分树:(BSP)(主要考)
构建:

二叉空间剖分树的另一种实例:
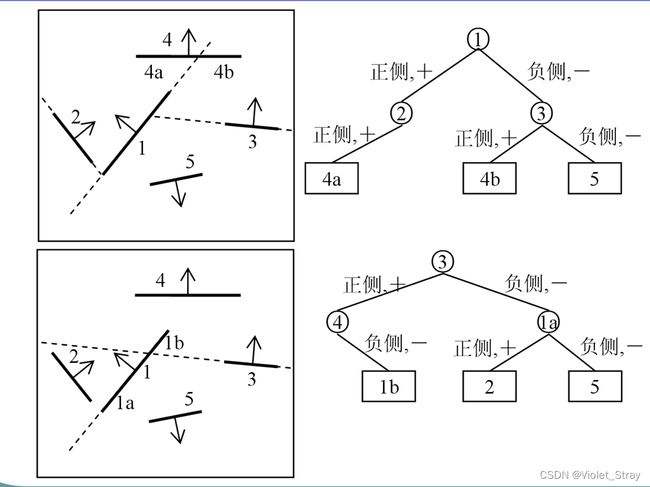
遍历:

位于正侧:左节点先的中序遍历
位于负侧:右节点先的中序遍历
有哪些加速状况?
扫描线算法(Scanline Algorithm):
按行逐像素处理屏幕,计算每一行上哪些像素是可见的。这种方法适用于多边形基的渲染。
课堂练习:
就把phong模型记下来,每个参数什么意思 刻画周围环境反射光对物体表面照明贡献 漫反射光是物体表面对入射光线朝各个方向的均匀反射。 假设给一个phong模型,算出一个derta角就可以了 对屏幕上每一像素,执行下述4个步骤: 求交不考 它不仅考虑到光源的光照,而且考虑到场景中各物体之间彼此反射的影响,因此显示效果十分逼真。 光线跟踪算法的缺点是计算量非常大,因此,显示速度极慢。 反走样处理方法: 为复杂的几何形状创建一个简单的外部容器或"盒子",这个盒子通常是矩形或正方形(二维情况下)或长方体(三维情况下)。在光线跟踪时,首先检测光线是否与这个简单的盒子相交。如果光线与盒子不相交,那么就可以确定光线也不可能与盒子内部的复杂几何形状相交,从而无需进行进一步计算。如果光线与盒子相交,才进行更详细的交点计算。这样就可以快速排除很多不可能的情况,只对有可能相交的光线进行详尽的交点计算。 这种技术将整个场景划分为许多小区域,并对每个区域内的对象进行管理。当光线穿过场景时,只需检查光线所经过的具体小区域内的对象,而不是场景中的每一个对象。这大大减少了需要检查的对象数量,提高了效率。当场景中的物体非常密集时,这种方法尤其有效。 纹理(texture)通常指物体的表面细节 欠采样问题。无论是纹理过小还是过大,在纹理采样时坐标之间的无法一一映射。 前置滤波方法 用区域均值作为一个点的采样值。 将屏幕像素P的四个角点分别映射到纹理空间,得到四个纹理像素值 预处理: 借助低精度模型和一个法向纹理,获得高精度模型的绘制效果 基本思想是:用纹理去修改物体的法向而不是颜色。改变物体表面接受光线的方式,但不改变物体的实际形状。 依据与表面上点所对应的纹理值,沿表面法向偏移该点的几何位置 辐射度算法就是:把场景细分到很细很细的面片(如1个像素那么大的三角形),分别计算它们接受和发出的光能,然后逐次递归,直到每个面片的光能数据不再变化(或者到一定的阀值)为止.因此,计算量很大(要计算很多次),而且难以并行(因为递归) 第一辐射光强。尽管我曾说过我们应该认为光源和普通物体是一样的,但场景中显然要有光发出的源头。在真实世界中,一些物体会辐射出光线,但有些不会。并且所有的物体会吸收某些波段的光。我们必须有某种方法区分出场景中那些能够辐射光线的物体。我们在辐射度算法中通过辐射光强来表述这一点 。我们认为,所有的面片都会辐射出光强,然而大多数面片辐射出的光强为0 。 均匀化网格分割。将场景分割为均匀大小的网格。 本影就是不被任何光源所照到的区域。 (失败+1,成功不变?) LOD是以固定分辨率离线创建的 优点: View-dependent LOD 解决了大物体渲染的问题 Hierarchical LOD 可以解决小物体渲染的问题 采用类似于三角形带或三角形扇这样的复合结构,将把处理与传输m个三角形的代价从3m个顶点降到(m+2)个顶点
A 深度缓存算法(Z-Buffer):这是实时渲染中常用的方法,因为它为每个像素独立执行,适合并行处理。每个像素的深度值被存储在Z缓冲区,并与新像素的深度值进行比较,以确定哪个像素在前面,因此不需要对整个场景的面片进行排序。
B 扫描线消隐算法:这种方法适用于将面片投影到屏幕上,并在每一条扫描线上确定哪些部分是可见的。虽然这种方法比深度排序算法快,但在面片数量非常大时,它通常比Z-Buffer算法慢,因为它需要处理和排序每条扫描线上的交点。
C 深度排序算法(画家算法):这种方法需要将所有面片按照它们离观察者的远近进行排序,然后从最远到最近绘制。在面片数量非常大时,排序过程本身就非常耗时,所以这是三者中最慢的方法
用时:C第九章:真实感图形_光照与明暗
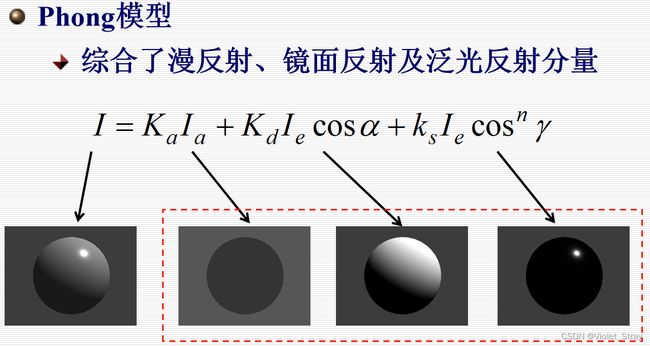
光照明模型
泛光模型:

Lambert漫反射模型:
大小只与入射光的光亮度和入射方向有关
与漫反射光的反射方向无关

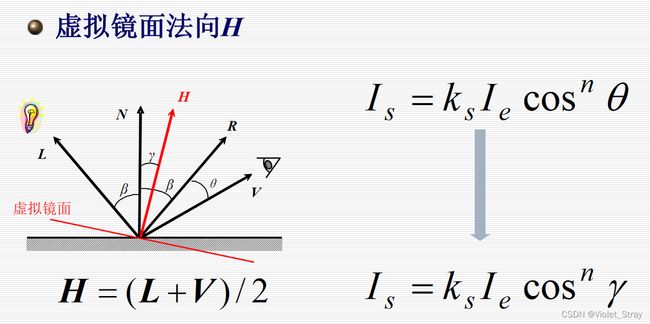
phong镜面反射模型:(重点)



Blinn-Phong模型:
Whitted模型:

基础的明暗处理模型:
Flat Shading:

Gouraud Shading:怎么做明暗的,双线差值
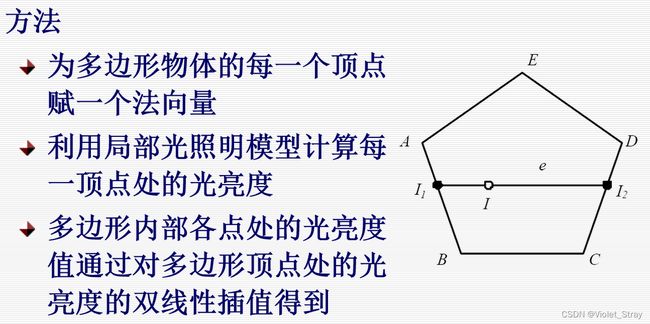
缺点:生成曲面体真实感图形效果差
计算量比phong shading小Phong Shading :直接差值法向

优点:可以产生高光改进的phong算法:

第九章:真实感图形_光线跟踪
建立光线树:


光线跟踪算法原理:
Step1:从视点出发通过该像素中心向场景发出一条光线R,并求出R与场景中物体的全部交点;获得离视点最近交点P;并依据局部光照明模型计算P处颜色值Ic (光线投射)
Step2:在P处沿着R镜面反射方向和透射方向各衍生一条光线
若点P所在表面非镜面或不透明体,则无需衍生出相应光线
Step3:分别对衍生出的光线递归地执行前面步骤,计算来自镜面反射和透射方向上周围环境对点P光亮度的贡献Is和It
Step4:依据Whitted光照明模型即可计算出点P处的光亮度,并将计算出的光亮度赋给该像素光线跟踪递归过程终止条件:

光线跟踪算法的伪语言描述:
main ( ) //主函数
{
for(需要计算颜色的每一像素pixel) {
确定通过视点V和像素pixel的光线R;
depth = 0; // 递归深度
ratio = 1.0; //当前光线的衰减系数,1.0表示无衰减
// color是经计算后返回的颜色值
RayTrace(R, ratio, depth, color);
置当前像素pixel的颜色为color;
}
}
RayTrace(R, ratio, depth, color) //说明:光线跟踪子函数
{
if(ratio < THRESHOLD) { //终止条件2
置color为黑色;
return;
}
if(depth > MAXDEPTH) { //终止条件3
置color为黑色;
return;
}
光线R与场景中的所有物体求交。若存在交点,找出离R起始点最近的交点P;
if(交点不存在) { //终止条件1
置color为黑色;
return;
}
用局部光照明模型计算交点P处的颜色值,并将其存入local_color;
依照Whitted模型合成最终的颜色值,即:
color = local_color + ks*reflected_color + kt*transmitted_color;
return;
}
小结:光线跟踪中的四类光线:

光线跟踪方法的优缺点:
有消隐功能:采用光线跟踪方法,在显示的同时,自动完成消隐功能。
有影子效果:光线跟踪能完成影子的显示,
该算法具有并行性质:每条光线的处理过程相同,结果彼此独立,因此可以大并行处理的硬件上快速实现光线跟踪算法。

C反走样:
引起走样的原因:光线跟踪算法本质上是对画面的点采样
超采样:超采样是一种直接而有效的方法,它通过在一个像素内部取多个样本点,计算这些样本点的颜色值,然后将这些颜色值平均化以得到最终的像素颜色。简单来说,就是以比屏幕分辨率更高的分辨率来渲染图像,然后将这个高分辨率的图像缩小以适应屏幕分辨率,这样每个像素的颜色都是由多个更小单元的颜色混合而成,从而减少了锯齿效果。
自适应超采样:只在图像中那些可能出现走样的区域(例如边缘)进行超采样处理,而不是对整个图像进行超采样。它会先检测图像的哪些部分可能产生走样,然后只对这些部分进行多个样本的颜色值计算和平均化处理。加速光线跟踪的技术:
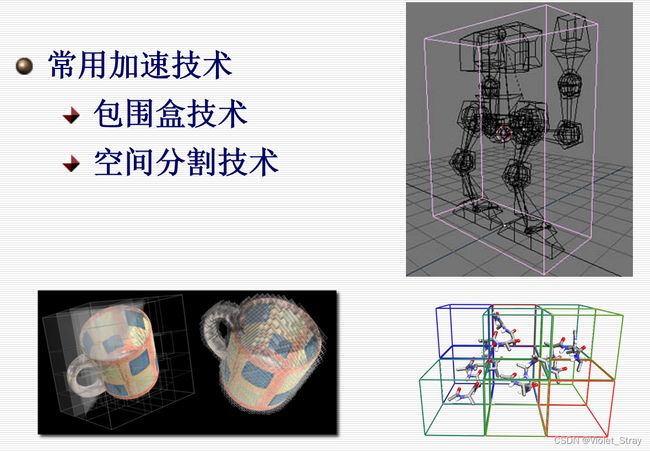
包围盒技术:

空间分割技术:

包含阴影计算的Phong模型:

第九章:真实感图形_纹理映射
纹理分类:
根据定义域:
根据纹理的表现形式:
如何映射:

纹理扫描:

像素次序扫描:

像素次序扫描将一个像素映射到物体表面一个区域,再投影到纹理数据的一个区域获得具体的颜色数据。具体的运算就是前面已经讲过的投影变换,坐标系变换,因此这里不再详述映射过程。
“将一个像素映射到物体表面一个区域”这句话描述的是纹理映射过程中的一个步骤,即确定屏幕上的一个像素点在3D物体的表面上对应的具体区域。纹理反走样:
原因:
常用纹理反走样方法:
超采样方法
Mipmap方法前置滤波方法:
确定屏幕像素P上可见的景物表面区域A
将区域A直接映射到纹理空间区域T
取区域T内的所有纹理像素颜色值的平均作为景物表面区域A的平均纹理颜色
代入光照明模型,计算出像素P应显示的光亮度值超采样方法:
将上述四个纹理颜色值取平均作为像素P所对应的可见表面区域的纹理颜色。
缺点:计算量太大、内存占用多Mipmap方法:
生成一个由不同分辨率图像构成的纹理图像序列
从原始纹理图像出发,生成一个其分辨率为原始图像1/4的新的纹理图像版本
新版本中的每一个像素值取为原始图像中相对应的四个像素颜色值的平均
类似地基于所得到的新纹理图像版本生成一个更低分辨率的、尺寸更小的纹理图像版本
这一过程一直持续到最后生成的纹理图像仅包含一个像素为止
[图片]
映射阶段:
屏幕上的每一像素内的可见表面区域被映射到原始纹理图像上的一块区域。
估计该区域所覆盖的原始纹理图像中像素的个数并以此作为选取适当分辨度的纹理图像版本的一种测度。
从预先构造的纹理图像序列中找出其压缩率最接近当前纹理像素与屏幕像素比率的两个纹理图像。
在相邻分辨率的两纹理图像上计算当前屏幕像素映射点的纹理颜色值。
根据两纹理图像对原始图像的压缩率在所得到的两个纹理颜色值间取加权平均,作为当前屏幕像素可见表面区域的颜色值。三维/几何纹理:怎么做的,什么效果

凹凸和法向都没有改变物体宏观,位移改变了宏观。法向映射:
先计算高精度模型的法向,将其保存在法向纹理中,再将法向纹理映射到低精度模型上进行光照计算凹凸映射:
物体表面的几何法向保持不变,我们仅仅改变光照明模型计算中的法向。位移映射:
能产生很强的深度感
计算代价大(与凹凸映射、法向映射相比)第九章:真实感图形_辐射度方法
辐射度系统方程:方程组怎么建立,怎么求解
辐射度计算中的几个定义。
这个面片的属性称为辐射光强(Emmision) 。这里一个面片的表面的辐射光强等于面片的辐射度值乘以面片面积。
第二反射率。当光线击中表面时,一些光线被吸收并且转化为热能,剩下的则被反射开去。我们称反射出去的光强比例为反射率(Reflectance) 。
第三入射和出射光强。在每一次遍历的过程中,记录另外两个东西是有必要的: 有多少光强抵达一个面片,
有多少光强因反射而离开面片。我们把它们称为入射光强和出射光强。出射光强是面片对外表现的属性。当我们观看某个面片时,其实是面片的出射光被我们看见了。







示例: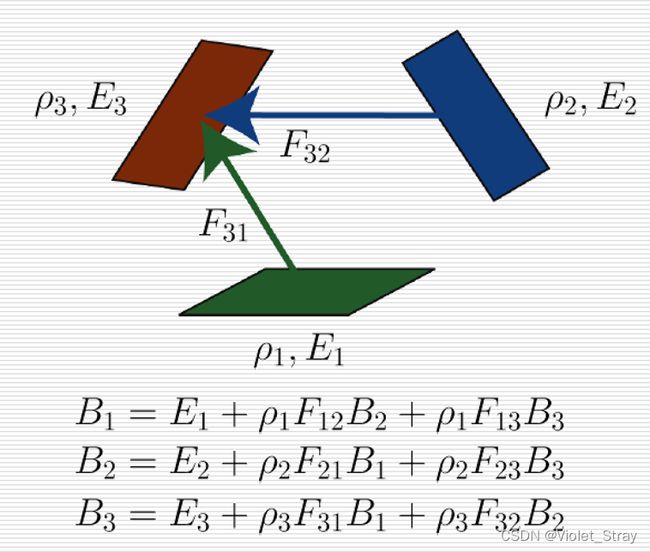

辐射度算法:网格怎么分割,形状因子怎么算(掌握理念)

辐射度算法:表面分割

改进:自适应网格化辐射度算法:形状因子计算
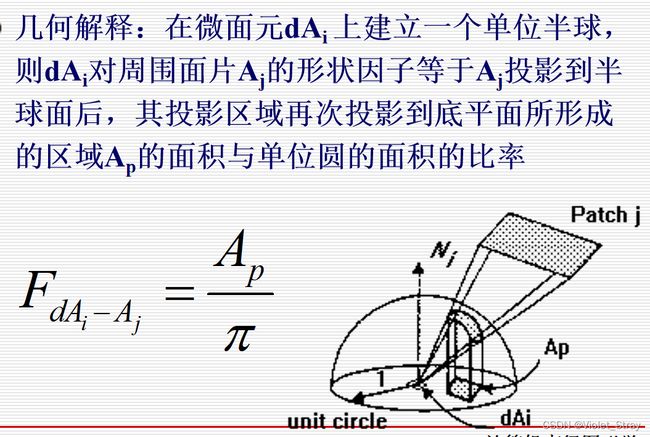


辐射度算法:方程求解

辐射度算法


第九章:真实感图形_阴影
本影和半影:
半影是指只有部分光线到达的区域

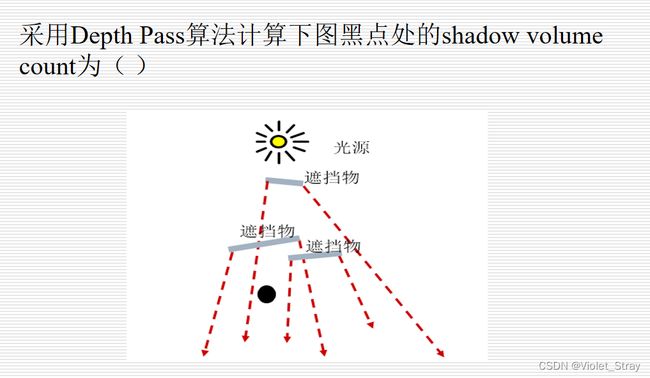
Depth Pass算法计算shadow volume count:

关注位置之前的视线与光线的交点,与正面交+1,与背面交-1
z-pass问题:
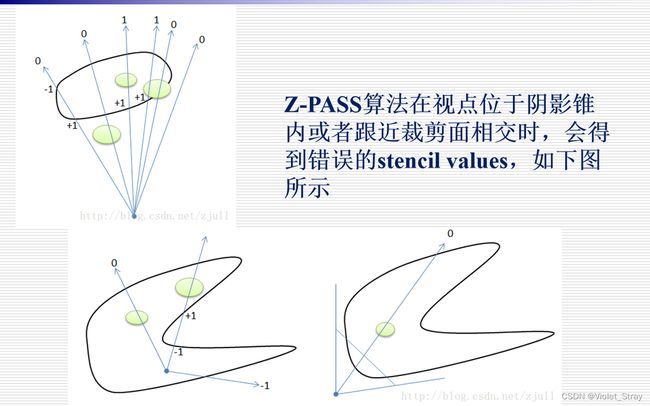
先后渲染阴影体的正面和背面,视线经过正面时深度测试通过则模板值 加1,经过背面时深度测试通过则模板值减1。
最后模板值不为0的片元就在阴影体中。
但是,z-pass算法的致命缺点是当视点在阴影中时,得到的模板值会导致错误的结果。
先后渲染阴影体的背面和正面,视线经过背面时深度测试失败则模板值 加1,经过正面时深度测试失败则模板值减1。
这样一来,即使在阴影体中,也能得到正确的模板值。与前者正好相反。也叫Carmack’s Reverse(Carmack给Mark Kilgard的mail中提出的)
但是,该算法还需要一个闭合的volume,并且令前后的两边都为背面。这样也就增加了计算量,因此应根据实际情况来选择算法。zfail怎么写:

我们分辨看物体位于shadow volum 中和外时通过zfail计算的stencil值。为了方便这里我们对两个vlolum进行了编号1和2。假设物体位于A处,那么先对后面进行检测,第1个volume后面检测失败stencil加1,为1.第2个volume后面检测失败加1,stencil为2.然后检查前面,第一个volume检测成功,stencil值不变。第二个volume检测失败,stencil减1.最终stencil值为1.
这里看下物体C。由于物体C的深度值位于volume1和2的后面。因此volume1和2的后面和前面深度检测均成功,stencil值不变为0
一个简单方法:画出视线与光线的交点,只看在位置A后面的视线,若交点是与背后相交,则标为+1,若与正面相交,则标为-1,然后统计就可以了。第十章:实时绘制加速技术
基本问题:了解LOD(简化远处)

离散LOD:
优点:
缺点:大型对象的问题连续LOD:
更好的粒度->更好的保真度
LOD是精确计算的,而不是从几个预先创建的选项中选择的
因此,对象使用的多边形不超过所需数量,这将为其他对象释放多边形
最终结果:更好的资源利用率,导致更好的整体保真度/多边形
更好的粒度->平滑过渡
在传统LOD之间切换会引入视觉“冲击”效果
连续LOD可以逐步增量调整细节,减少视觉冲击View-Dependent LOD:
Hierarchical LOD:
网络压缩传输技术


如果应用程序的瓶颈为填充率时,很难使用这种方法提高系统性能
填充率:每秒可填充的像素数量