spring三级缓存
spring三级缓存
- 什么是循环依赖?
- 如何检测是否存在循环依赖?
- 如何解决循环依赖?
- 多例的情况下,循环依赖问题为什么无法解决?
- 单例的情况下,虽然可以解决循环依赖,是否存在其他问题?
- 为什么采用三级缓存解决循环依赖?如果直接将早期bean丢到二级缓存可以么?
什么是循环依赖?
这个很好理解,多个bean之间相互依赖,形成了一个闭环。
比如:A依赖于B、B依赖于C、C依赖于A。
代码中表示:
public class A{
B b;
}
public class B{
C c;
}
public class C{
A a;
}
如何检测是否存在循环依赖?
检测循环依赖比较简单,使用一个列表来记录正在创建中的bean,bean创建之前,先去记录中看一下自己是否已经在列表中了,如果在,说明存在循环依赖,如果不在,则将其加入到这个列表,bean创建完毕之后,将其再从这个列表中移除。
Spring如何解决循环依赖的问题
spring创建bean主要的几个步骤:
- 步骤1:实例化bean,即调用构造器创建bean实例
- 步骤2:填充属性,注入依赖的bean,比如通过set方式、@Autowired注解的方式注入依赖的bean
- 步骤3:bean的初始化,比如调用init方法等。
从上面3个步骤中可以看出,注入依赖的对象,有2种情况:
- 通过步骤1中构造器的方式注入依赖
- 通过步骤2注入依赖
先来看构造器的方式注入依赖的bean,下面两个bean循环依赖
@Component
public class ServiceA {
private ServiceB serviceB;
public ServiceA(ServiceB serviceB) {
this.serviceB = serviceB;
}
}
@Component
public class ServiceB {
private ServiceA serviceA;
public ServiceB(ServiceA serviceA) {
this.serviceA = serviceA;
}
}
构造器的情况比较容易理解,实例化ServiceA的时候,需要有serviceB,而实例化ServiceB的时候需要有serviceA,构造器循环依赖是无法解决的,大家可以尝试一下使用编码的方式创建上面2个对象,是无法创建成功的!
再来看看非构造器的方式注入相互依赖的bean,以set方式注入为例,下面是2个单例的bean:serviceA和serviceB:
@Component
public class ServiceA {
private ServiceB serviceB;
@Autowired
public void setServiceB(ServiceB serviceB) {
this.serviceB = serviceB;
}
}
@Component
public class ServiceB {
private ServiceA serviceA;
@Autowired
public void setServiceA(ServiceA serviceA) {
this.serviceA = serviceA;
}
}
如果我们采用硬编码的方式创建上面2个对象,过程如下:
//创建serviceA
ServiceA serviceA = new ServiceA();
//创建serviceB
ServiceB serviceB = new ServiceB();
//将serviceA注入到serviceB中
serviceB.setServiceA(serviceA);
//将serviceB注入到serviceA中
serviceA.setServiceB(serviceB);
由于单例bean在spring容器中只存在一个,所以spring容器中肯定是有一个缓存来存放所有已创建好的单例bean;获取单例bean之前,可以先去缓存中找,找到了直接返回,找不到的情况下再去创建,创建完毕之后再将其丢到缓存中,可以使用一个map来存储单例bean,比如下面这个
Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
下面来看一下spring中set方法创建上面2个bean的过程
1.spring轮询准备创建2个bean:serviceA和serviceB
2.spring容器发现singletonObjects中没有serviceA
3.调用serviceA的构造器创建serviceA实例
4.serviceA准备注入依赖的对象,发现需要通过setServiceB注入serviceB
5.serviceA向spring容器查找serviceB
6.spring容器发现singletonObjects中没有serviceB
7.调用serviceB的构造器创建serviceB实例
8.serviceB准备注入依赖的对象,发现需要通过setServiceA注入serviceA
9.serviceB向spring容器查找serviceA
10.此时又进入步骤2了
卧槽,上面过程死循环了,怎么才能终结?
可以在第3步后加一个操作:将实例化好的serviceA丢到singletonObjects中,此时问题就解决了。
spring中也采用类似的方式,稍微有点区别,上面使用了一个缓存,而spring内部采用了3级缓存来解决这个问题,我们一起来细看一下。
3级缓存对应的代码:
/** 第一级缓存:单例bean的缓存 */
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
/** 第二级缓存:早期暴露的bean的缓存 */
private final Map<String, Object> earlySingletonObjects = new HashMap<>(16);
/** 第三级缓存:单例bean工厂的缓存 */
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);
下面来看spring中具体的过程,我们一起来分析源码
//allowEarlyReference:是否允许从三级缓存singletonFactories中通过getObject拿到bean
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
//1.先从一级缓存中找
Object singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
//2.从二级缓存中找
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
//3.二级缓存中没找到 && allowEarlyReference为true的情况下,从三级缓存中找
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
//三级缓存返回的是一个工厂,通过工厂来获取创建bean
singletonObject = singletonFactory.getObject();
//将创建好的bean丢到二级缓存中
this.earlySingletonObjects.put(beanName, singletonObject);
//从三级缓存移除
this.singletonFactories.remove(beanName);
}
}
}
}
return singletonObject;
}
捋一捋整个过程:
1.从容器中获取serviceA
2.容器尝试从3个缓存中找serviceA,找不到
3.准备创建serviceA
4.调用serviceA的构造器创建serviceA,得到serviceA实例,此时serviceA还未填充属性,未进行其他任何初始化的操作
5.将早期的serviceA暴露出去:即将其丢到第3级缓存singletonFactories中
6.serviceA准备填充属性,发现需要注入serviceB,然后向容器获取serviceB
7.容器尝试从3个缓存中找serviceB,找不到
8.准备创建serviceB
9.调用serviceB的构造器创建serviceB,得到serviceB实例,此时serviceB还未填充属性,未进行其他任何初始化的操作
10.将早期的serviceB暴露出去:即将其丢到第3级缓存singletonFactories中
11.serviceB准备填充属性,发现需要注入serviceA,然后向容器获取serviceA
12.容器尝试从3个缓存中找serviceA,发现此时serviceA位于第3级缓存中,经过处理之后,serviceA会从第3级缓存中移除,然后会存到第2级缓存中,然后将其返回给serviceB,此时serviceA通过serviceB中的setServiceA方法被注入到serviceB中
13.serviceB继续执行后续的一些操作,最后完成创建工作,然后会调用addSingleton方法,将自己丢到第1级缓存中,并将自己从第2和第3级缓存中移除
14.serviceB将自己返回给serviceA
15.serviceA通过setServiceB方法将serviceB注入进去
16.serviceA继续执行后续的一些操作,最后完成创建工作,然后会调用addSingleton方法,将自己丢到第1级缓存中,并将自己从第2和第3级缓存中移除
循环依赖无法解决的情况
只有单例的bean会通过三级缓存提前暴露来解决循环依赖的问题,而非单例的bean,每次从容器中获取都是一个新的对象,都会重新创建,所以非单例的bean是没有缓存的,不会将其放到三级缓存中。
那就会有下面几种情况需要注意。
还是以2个bean相互依赖为例:serviceA和serviceB
情况1
条件
serviceA:多例
serviceB:多例
结果
此时不管是任何方式都是无法解决循环依赖的问题,最终都会报错,因为每次去获取依赖的bean都会重新创建。
情况2
条件
serviceA:单例
serviceB:多例
结果
若使用构造器的方式相互注入,是无法完成注入操作的,会报错。
若采用set方式注入,所有bean都还未创建的情况下,若去容器中获取serviceB,会报错,为什么?我们来看一下过程:
1.从容器中获取serviceB
2.serviceB由于是多例的,所以缓存中肯定是没有的
3.检查serviceB是在正在创建的bean名称列表中,没有
4.准备创建serviceB
5.将serviceB放入正在创建的bean名称列表中
6.实例化serviceB(由于serviceB是多例的,所以不会提前暴露,必须是单例的才会暴露)
7.准备填充serviceB属性,发现需要注入serviceA
8.从容器中查找serviceA
9.尝试从3级缓存中找serviceA,找不到
10.准备创建serviceA
11.将serviceA放入正在创建的bean名称列表中
12.实例化serviceA
13.由于serviceA是单例的,将早期serviceA暴露出去,丢到第3级缓存中
14.准备填充serviceA的属性,发现需要注入serviceB
15.从容器中获取serviceB
16.先从缓存中找serviceB,找不到
17.检查serviceB是在正在创建的bean名称列表中,发现已经存在了,抛出循环依赖的异常
探讨:为什么需要用3级缓存
问题
如果只使用2级缓存,直接将刚实例化好的bean暴露给二级缓存出是否可以否?
先下个结论吧:不行。
原因
这样做是可以解决:早期暴露给其他依赖者的bean和最终暴露的bean不一致的问题。
若将刚刚实例化好的bean直接丢到二级缓存中暴露出去,如果后期这个bean对象被更改了,比如可能在上面加了一些拦截器,将其包装为一个代理了,那么暴露出去的bean和最终的这个bean就不一样的,将自己暴露出去的时候是一个原始对象,而自己最终却是一个代理对象,最终会导致被暴露出去的和最终的bean不是同一个bean的,将产生意向不到的效果,而三级缓存就可以发现这个问题,会报错。
单例bean解决了循环依赖,还存在什么问题?
循环依赖的情况下,由于注入的是早期的bean,此时早期的bean中还未被填充属性,初始化等各种操作,也就是说此时bean并没有被完全初始化完毕,此时若直接拿去使用,可能存在有问题的风险。
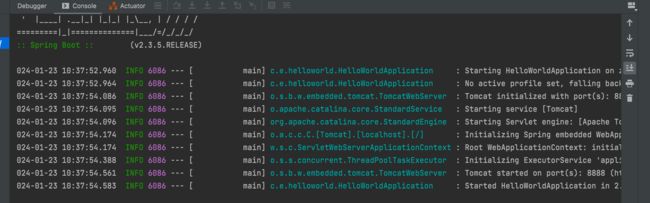
注意 在2.6.0之前,Spring Boot会自动处理循环依赖的问题,而2.6.0版本以上开始检查循环依赖,存在该问题则会报错。
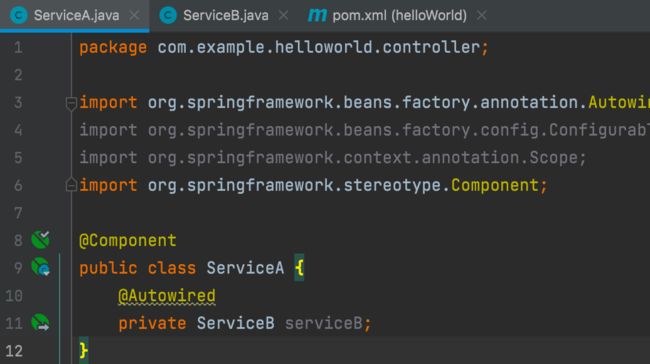
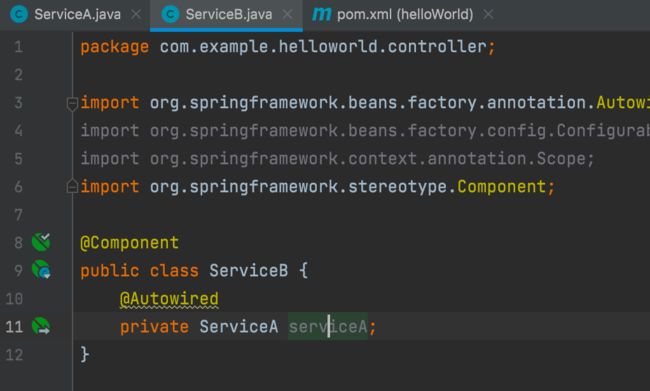
2.6之前版本
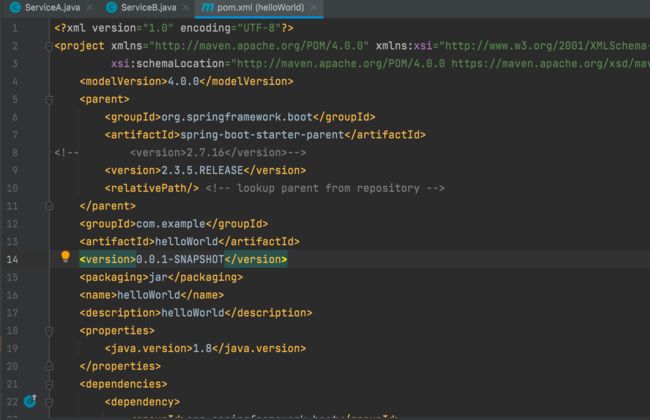
启动成功
改成2.7版本
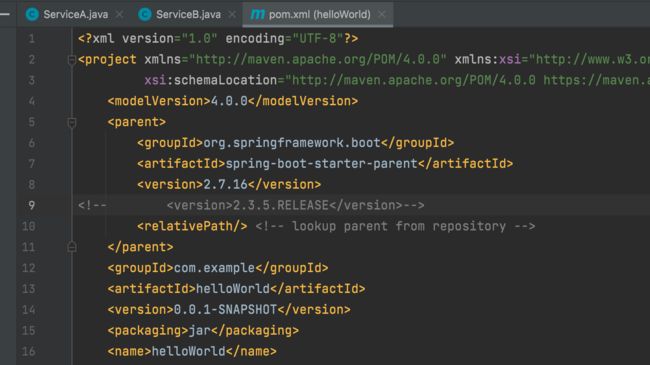
报错