G6-CycleGAN
本文为365天深度学习训练营 中的学习记录博客
原作者:K同学啊|接辅导、项目定制
我的环境:
1.语言:python3.7
2.编译器:pycharm
3.深度学习框架Pytorch 1.8.0+cu111
一、CycleGan的核心思想与损失函数
假设两类数据集X与Y分别存放真实图像与油画图像,我们希望训练出一个生成器G,学习一张X类的图像生成一张Y类的图像。实现![]() ;我们还希望构建另一个生成器F,学习一张Y类的图像生成一张X类的图像,实现
;我们还希望构建另一个生成器F,学习一张Y类的图像生成一张X类的图像,实现![]() 。训练两个判别器
。训练两个判别器![]() 和
和![]() 分别判断生成器生成的图片质量。
分别判断生成器生成的图片质量。

当我们固定住生成器的参数训练判别器时,判别器便能学到更好的判别技巧,当我们固定住判别器参数训练生成器时,生成器为了骗过现在更厉害的判别器,被迫产生出更好质量的图片。两者便在这迭代学习的过程中逐步进化,最终达到动态平衡。
CycleGAN中用进化生成器与判别器的Loss为![]()
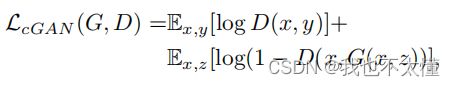
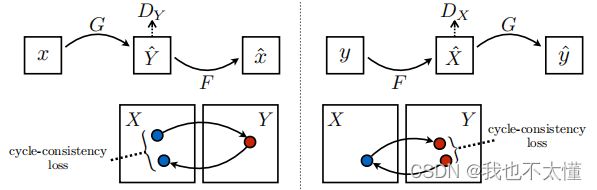
为了实现在风格转换中图片的内容物体保持不变我们要再将 放入生成器F中,即
放入生成器F中,即![]() ,使得产生的新图片
,使得产生的新图片 与
与 要尽可能相似。即
要尽可能相似。即![]() 要尽可能小。
要尽可能小。

除此之外程序中还引入了![]() ,它希望
,它希望![]() 生成的图像与y要尽可能接近;
生成的图像与y要尽可能接近; 生成的图像与x要尽可能接近。
生成的图像与x要尽可能接近。
import argparse
import os
from tkinter import Image
import numpy as np
import math
import itertools
import datetime
import time
import torchvision.transforms as transforms
from torchvision.utils import save_image, make_grid
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
from models import *
from datasets import *
from utils import *
import torch.nn as nn
import torch.nn.functional as F
import torch
from PIL import Image
from torchvision.transforms import InterpolationMode
#优化器参数
lr = 0.0004
b1 = 0.5
b2 = 0.999
#图片尺寸
img_height = 256
img_width = 256
channels = 3
#数据文件夹名称
dataset_name = 'facades'
#使用的残差块数量
n_residual_blocks = 3
n_cpu = 2
batch_size = 1
#损失权重
cyc_w = 10.0
ide_w = 5.0
#训练轮数
n_epochs = 10
sample_interval = 100
## 创建文件夹
os.makedirs("images/%s" % dataset_name, exist_ok=True)
os.makedirs("save/%s" % dataset_name, exist_ok=True)
## input_shape:(3, 256, 256)
input_shape = (channels, img_height, img_width)
## 创建生成器,判别器对象
G_AB = Generator(input_shape,n_residual_blocks)
G_BA = Generator(input_shape,n_residual_blocks)
D_A = Discriminator(input_shape)
D_B = Discriminator(input_shape)
#损失函数
## MES 二分类的交叉熵
criterion_GAN = torch.nn.MSELoss() #均方误差损失函数
criterion_cycle = torch.nn.SmoothL1Loss() # realA generate fakeB generate fakeA 与 trueA loss
criterion_identity = torch.nn.SmoothL1Loss() #G_BA(realA) 与 realA之间的损失
## 如果有显卡,都在cuda模式中运行
if torch.cuda.is_available():
G_AB = G_AB.cuda()
G_BA = G_BA.cuda()
D_A = D_A.cuda()
D_B = D_B.cuda()
criterion_GAN.cuda()
criterion_cycle.cuda()
criterion_identity.cuda()
#模型参数初始化
G_AB.apply(weights_init)
G_BA.apply(weights_init)
D_A.apply(weights_init)
D_B.apply(weights_init)
#定义优化器
optimizer_G = torch.optim.Adam(
itertools.chain(G_AB.parameters(), G_BA.parameters()), lr=lr, betas=(b1, b2)
)
optimizer_D_A = torch.optim.Adam(D_A.parameters(), lr=lr, betas=(b1, b2))
optimizer_D_B = torch.optim.Adam(D_B.parameters(), lr=lr, betas=(b1, b2))
## 生成图像的样本的缓冲区
fake_A_buffer = ReplayBuffer()
fake_B_buffer = ReplayBuffer()
二、模型训练
def train():
prev_time = time.time() #开始时间
for now_e in range(0, n_epochs): ## for epoch in (0, 5)
for i, batch in enumerate(dataloader):
## 读取数据集中的真图片
## 将tensor变成Variable放入计算图中,tensor变成variable之后才能进行反向传播求梯度
real_A = Variable(batch["A"]).cuda() ## 真图像A
real_B = Variable(batch["B"]).cuda() ## 真图像B
## 全真,全假的标签
valid = Variable(torch.ones((real_A.size(0), *D_A.output_shape)),
requires_grad=False).cuda() ## 定义真实的图片每个元素均为1 ones((1, 1, 16, 16))
fake = Variable(torch.zeros((real_A.size(0), *D_A.output_shape)),
requires_grad=False).cuda() ## 定义假的图片的label每个元素均为0 zeros((1, 1, 16, 16))
## Train Generator
## 原理:目的是希望生成的假的图片被判别器判断为真的图片,
## 在此过程中,将判别器固定,将假的图片传入判别器的结果与真实的label对应,
## 反向传播更新的参数是生成网络里面的参数,
## 这样可以通过更新生成网络里面的参数,来训练网络,使得生成的图片让判别器以为是真的, 这样就达到了对抗的目的
G_AB.train()
G_AB.train()
output_G_BA = G_BA(real_A)
print("Output shape of G_BA:", output_G_BA.shape)
print("Input shape of real_A:", real_A.shape)
## Identity loss
## A风格的图像 放在 B -> A 生成器中,生成的图像也要是A风格
loss_id_A = criterion_identity(G_BA(real_A),real_A)
## loss_id_A就是把图像A1放入 B to A 的生成器中,
# 那当然生成图像A2的风格也得是A风格,要让A1,A2的差距很小
loss_id_B = criterion_identity(G_AB(real_B), real_B)
loss_identity = (loss_id_A + loss_id_B) / 2
## GAN loss
fake_B = G_AB(real_A) ## 用真图像A生成的假图像B
loss_GAN_AB = criterion_GAN(D_B(fake_B), valid)
## 用B鉴别器鉴别假图像B,训练生成器的目的就是要让鉴别器以为假的是真的,假的太接近真的让鉴别器分辨不出来
fake_A = G_BA(real_B) ## 用真图像B生成的假图像A
loss_GAN_BA = criterion_GAN(D_A(fake_A), valid)
## 用A鉴别器鉴别假图像A,训练生成器的目的就是要让鉴别器以为假的是真的,假的太接近真的让鉴别器分辨不出来
loss_GAN = (loss_GAN_AB + loss_GAN_BA) / 2
# Cycle loss 循环一致性损失
recov_A = G_BA(fake_B)
## 之前中realA 通过 A -> B 生成的假图像B,再经过 B -> A ,使得fakeB 得到的循环图像recovA,
loss_cycle_A = criterion_cycle(recov_A, real_A)
## realA和recovA的差距应该很小,以保证A,B间不仅风格有所变化,而且图片对应的的细节也可以保留
recov_B = G_AB(fake_A)
loss_cycle_B = criterion_cycle(recov_B, real_B)
loss_cycle = (loss_cycle_A + loss_cycle_B) / 2
# Total loss ## 就是上面所有的损失都加起来
loss_G = loss_GAN + cyc_w * loss_cycle + ide_w * loss_identity
optimizer_G.zero_grad() ## 在反向传播之前,先将梯度归0
loss_G.backward() ## 将误差反向传播
optimizer_G.step() ## 更新参数
## Train Discriminator A
## 分为两部分:1、真的图像判别为真;2、假的图像判别为假
## -----------------------
## 真的图像判别为真
loss_real = criterion_GAN(D_A(real_A), valid)
## 假的图像判别为假(从之前的buffer缓存中随机取一张)
fake_A_ = fake_A_buffer.push_and_pop(fake_A)
loss_fake = criterion_GAN(D_A(fake_A_.detach()), fake)
#detach操作生成一个与fake_A_共享相同数据的新张量,目的是不影响原始张量的梯度计算
# Total loss A
loss_D_A = (loss_real + loss_fake) / 2
optimizer_D_A.zero_grad() ## 在反向传播之前,先将梯度归0
loss_D_A.backward() ## 将误差反向传播
optimizer_D_A.step() ## 更新参数
## Train Discriminator B
loss_real = criterion_GAN(D_B(real_B),valid)
fake_B_ = fake_B_buffer.push_and_pop(fake_B)
loss_fake = criterion_GAN(D_B(fake_B_.detach()),fake)
#Total loss B
loss_D_B = (loss_real + loss_fake) / 2
optimizer_D_B.zero_grad() ## 在反向传播之前,先将梯度归0
loss_D_B.backward() ## 将误差反向传播
optimizer_D_B.step() ## 更新参数
loss_D = (loss_D_A + loss_D_B) / 2
## 确定剩下的大约时间 假设当前 epoch = 5, i = 100
batches_done = now_e * len(dataloader) + i ## 已经训练了多长时间 5 * 400 + 100 次
batches_left = n_epochs * len(dataloader) - batches_done ## 还剩下 50 * 400 - 2100 次
time_left = datetime.timedelta(
seconds=batches_left * (time.time() - prev_time))
## 还需要的时间 time_left = 剩下的次数 * 每次的时间
prev_time = time.time()
#Print log
sys.stdout.write(
"\r[Epoch %d/%d] [Batch %d/%d] [D loss: %f] [G loss: %f, adv: %f, cycle: %f, identity: %f] ETA: %s"
% (
now_e,
n_epochs,
i,
len(dataloader),
loss_D.item(),
loss_G.item(),
loss_GAN.item(),
loss_cycle.item(),
loss_identity.item(),
time_left,
)
)
G_losses.append(loss_G.item())
D_losses.append(loss_D.item())
## 训练结束后,保存模型
torch.save(G_AB.state_dict(), "save/%s/G_AB_%d.pth" % (dataset_name, now_e))
torch.save(G_BA.state_dict(), "save/%s/G_BA_%d.pth" % (dataset_name, now_e))
torch.save(D_A.state_dict(), "save/%s/D_A_%d.pth" % (dataset_name, now_e))
torch.save(D_B.state_dict(), "save/%s/D_B_%d.pth" % (dataset_name, now_e))
print("save my model finished !!")
生成器的总损失为![]() +
+![]() *
*![]() +
+ ![]() *
* ![]() 与为损失权重分别为5.0、10.0
与为损失权重分别为5.0、10.0
鉴别器损失分为真实样本损失(鉴别真图像的损失)与生成样本损失(鉴别生成图像的损失)。其中生成图像的选取引入了缓冲池的概念,缓冲池用来保存生成器生成的历史图片,以增强模型的训练稳定性和生成样本的多样性。
- 稳定性: 缓冲区可以用于平滑训练过程,尤其是在训练初期,生成器的输出可能会有较大的波动。通过在缓冲区中保存之前生成的图像,可以提供更稳定的样本,有助于训练的收敛和稳定性。
- 多样性: 缓冲区在一定程度上增加了生成器的输入多样性。当缓冲区中的图像数量较小时,生成器更有可能选择之前生成的图像进行再次训练,从而增加生成样本的多样性。这有助于生成更广泛的图像变换,而不仅仅是过拟合到当前训练数据的特定样本。
- 防止模式崩溃: 在训练过程中,生成器可能陷入某种模式崩溃,即生成相似的图像。通过引入缓冲区,可以防止这种情况的发生,因为缓冲区中存储了不同的样本,减缓了模型陷入重复生成的风险。
真实样本损失:
这一部分损失衡量鉴别器对真实样本的判别能力。它使得鉴别器趋向于将真实样本分类为真实,最小化这一损失可以促使鉴别器在真实样本上取得好的分类性能。
生成样本损失:
这一部分损失衡量鉴别器对生成样本(生成器生成的样本)的判别能力。它使得鉴别器趋向于将生成样本分类为假的,最小化这一损失可以促使鉴别器在生成样本上取得好的分类性能。
在上述的生成器与判别器的模型参数每一轮通过Adam优化器完成更新后,使用torch.save()保存每一轮模型的参数。
##残差块
class ResidualBlock(nn.Module):
def __init__(self, in_features):
super(ResidualBlock, self).__init__()
self.block = nn.Sequential(
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
nn.ReLU(inplace=True),
nn.ReflectionPad2d(1),
nn.Conv2d(in_features, in_features, 3),
nn.InstanceNorm2d(in_features),
)
def forward(self, x):
return x + self.block(x)
class Generator(nn.Module):
def __init__(self, input_shape, num_residual_blocks): ## (input_shape = (3, 256, 256), num_residual_blocks = 9)
super(Generator, self).__init__()
channels = input_shape[0]
model = [
nn.ReflectionPad2d(channels),
nn.Conv2d(channels, 64, 7),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True),
# 下采样
nn.Conv2d(64, 128, 3, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 256, 3, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.ReLU(inplace=True),
]
##加入残差块
for _ in range(num_residual_blocks):
model += [ResidualBlock(256)]
##上采样
model += [
nn.Upsample(scale_factor=2),
nn.Conv2d(256, 128, 3, stride=1, padding=1),
nn.InstanceNorm2d(128),
nn.ReLU(inplace=True),
nn.Upsample(scale_factor=2),
nn.Conv2d(128, 64, 3, stride=1, padding=1),
nn.InstanceNorm2d(64),
nn.ReLU(inplace=True),
]
# 输出层
model += [
nn.ReflectionPad2d(channels),
nn.Conv2d(64, channels, 7),
nn.Tanh()
]
self.model = nn.Sequential(*model)
def forward(self, x): ## 输入为一张图像
return self.model(x) ## 输出为图像加上网络的残差输出
class Discriminator(nn.Module):
def __init__(self, input_shape):
super(Discriminator, self).__init__()
channels, height, width = input_shape
self.output_shape = (1, height // 2 ** 4, width // 2 ** 4)
self.model = nn.Sequential(
nn.Conv2d(channels, 64, 4, stride=2, padding=1),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(64, 128, 4, stride=2, padding=1),
nn.InstanceNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(128, 256, 4, stride=2, padding=1),
nn.InstanceNorm2d(256),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(256, 512, 4, stride=2, padding=1),
nn.InstanceNorm2d(512),
nn.LeakyReLU(0.2, inplace=True),
nn.ZeroPad2d((1, 0, 1, 0)),
nn.Conv2d(512, 1, 4, padding=1)
)
def forward(self, img):
return self.model(img)
使用ReflectionPad2d保存边界信息。反射填充是一种填充策略,它通过在输入的边界上对像素进行反射,以模拟边界上的镜像效果。这有助于在卷积等操作中保持输入和输出的大小一致。
采用InstanceNorm2d而不采用BatchNorm2d来进行归一化,因为InstanceNorm2d对每个样本进行归一化,不受小批量内的样本差异影响。而BatchNorm2d利用整个小批量内的样本计算均值和方差,对样本的整体分布更敏感,适用于大批量。
利用Upsample替代ConvTranspose2d进行上采样,没有学习的参数,减小计算开销。
nn.LeakyReLU用于引入非线性性质到神经网络中。和 ReLU 不同的是,LeakyReLU 在输入值小于零时引入了一个小的斜率。这样可以避免 ReLU在负值区间上输出恒定的零梯度,导致部分神经元“死亡”。
nn.ZeroPad2d((1, 0, 1, 0)): 这是一个零填充层,用于在输入的二维特征图的左、右、上、下四个边界进行填充,将特征图的大小调整为 (height + 1, width + 1)。
损失函数:
criterion_GAN = torch.nn.MSELoss()
criterion_cycle = torch.nn.SmoothL1Loss()
criterion_identity = torch.nn.SmoothL1Loss()- MSELoss()表示均方误差损失函数,用于度量生成器生成的假样本(fakeB)和真实样本(trueB)之间的差异。它通过最小化生成器生成的样本与真实样本之间的均方误差来推动生成器生成更逼真的样本。
- criterion_cycle: 这个损失函数用于计算GAN模型中的循环一致性损失。SmoothL1Loss()表示平滑L1损失函数,用于度量生成器在进行循环转换时生成的样本和原始输入样本之间的差异。它通过最小化生成器生成的样本与原始输入样本之间的平滑L1损失来促使生成器学习到一个具有循环一致性的映射。
- criterion_identity: 这个损失函数用于计算GAN模型中的身份损失。SmoothL1Loss()同样表示平滑L1损失函数,用于度量生成器将原始输入样本映射回自身时的差异。它通过最小化生成器将原始输入样本映射回自身的平滑L1损失来鼓励生成器保持原始输入样本的身份特征。
数据增强:
transforms_ = [
transforms.Resize(int(img_height * 1.12)), ## 图片放大1.12倍
transforms.RandomCrop((img_height, img_width)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)),
]- transforms.Resize(int(img_height * 1.12)):将图像按照指定的尺寸进行缩放。这里将图像的高度放大1.12倍,宽度会按照相同的比例进行调整。
- transforms.RandomCrop((img_height, img_width)): 这个操作会随机裁剪图像为指定的尺寸(256,256)。通过随机裁剪,可以提取图像中的不同部分,增加模型的泛化能力。
- transforms.RandomHorizontalFlip():随机水平翻转图像。通过随机翻转,可以增加数据的多样性,使模型对图像的左右关系不敏感。
- transforms.ToTensor(): 这个操作将图像转换为PyTorch张量的格式。PyTorch张量是PyTorch框架中用于表示图像数据的数据类型。
- transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)): 这个操作对图像进行正则化处理。通过减去均值并除以标准差,可以将图像的像素值归一化到均值为0,标准差为1的范围内。这有助于提高模型的训练效果。
三、模型性能
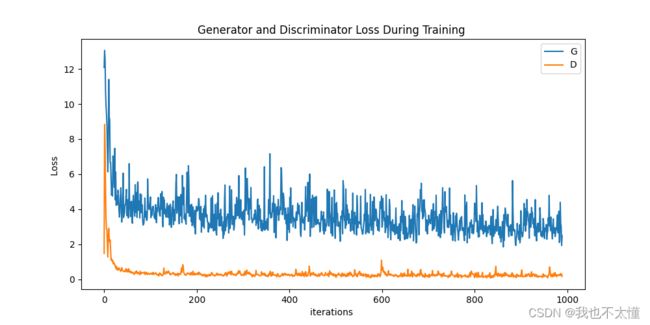
所有轮数的平均损失
G_losses_mean 3.5824863247197083
D_losses_mean 0.3232916407512896
SSIM: 0.21936448497611116
四、总结
由于GPU内存不够,我删减了一些原代码网络结构中的残差块。学会利用GAN网络实现图像风格转换的任务。在项目实现的过程中,我们对网络结构进行了多次优化,绘制出不用网络结构下的损失函数曲线图,找到最优的网络结构用于实现任务。