linux下Elasticsearch和Logstash的安装和使用
文章目录
-
-
- Elasticsearch
-
- 第一步 下载并解压文件
- 第二步 修改配置文件
- 第三步 安装前用户和环境设置
-
- 1、修改虚拟内存区域数量
- 2、新建es用户
- 3、设置es用户的环境变量
- 4、安装运行
- 5、关闭和启动
- 第四步 使用
- Logstash
-
- 第一步 下载并解压文件
- 第二步 下载数据库驱动
- 第三步 新建和编辑配置文件
- 第四步 目录权限和其他配置
- 第五步 运行
-
Elasticsearch
由于是初次安装和使用es,对es的运行环境和安装过程不了解,做了很多无用的事。
比如我安装的是es7.15,这个版本的es不需要要安装java环境,因为他自带java JDK。
下面是具体的安装步骤
第一步 下载并解压文件
我们在官网下载好tar.gz文件后,把文件解压到/usr/local目录后,修改es目录为自己想要的名字,我把解压后的目录修改为elasticsearch-7.15
第二步 修改配置文件

打开配置文件后,按如下配置
# ---------------------------------- Cluster -----------------------------------
cluster.name: my-application
# ------------------------------------ Node ------------------------------------
node.name: node-1
# ----------------------------------- Paths ------------------------------------
path.data: /usr/local/elasticsearch-7.15/data
path.logs: /usr/local/elasticsearch-7.15/logs
# ---------------------------------- Network -----------------------------------
network.host: 0.0.0.0
http.port: 9200
#
# For more information, consult the network module documentation.
#
http.cors.allow-origin: "*"
http.cors.enabled: true
http.cors.allow-headers : X-Requested-With,X-Auth-Token,Content-Type,Content-Length,Authorization
http.cors.allow-credentials: true
# --------------------------------- Discovery ----------------------------------
discovery.seed_hosts: ["127.0.0.1", "[::1]"]
cluster.initial_master_nodes: ["node-1"]
以上配置为单机配置,需要集群配置的话,需要修改相关条件,以后再议
第三步 安装前用户和环境设置
1、修改虚拟内存区域数量
默认情况下,vm.max_map_count=65530
此时运行es,会报错,如下
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
在root账户下,执行
sudo vim /etc/sysctl.conf
在文件末尾添加如下配置,直接把虚拟内存虚拟数量提高10倍
vm.max_map_count=655360
保存后退出,查看配置是否生效,执行
sudo sysctl -p
生效的话,可以看到我们刚添加的配置
2、新建es用户
es需要在非root账户下运行,在root用户下报如下错误
could not find java in bundled jdk at /usr/local/elasticsearch-7.15/jdk/bin/java
我们需要新建es用户,并把es文件的目录授权给es用户,依次执行如下命令
1、新建用户:sudo adduser es
2、设置es用于密码:sudo passwd es
3、把es的文件目录授权给es用户:sudo chown -R es:es /usr/local/elasticsearch-7.15
3、设置es用户的环境变量
切换到es用户
su es
通过修改.bashrc文件:root用户需要加上sudo
vim ~/.bashrc
//在最后一行添上:
export PATH=/usr/local/elasticsearch-7.15/bin:$PATH
生效方法:(有以下两种)
1、关闭当前终端窗口,重新打开一个新终端窗口就能生效
2、执行“source ~/.bashrc”命令,立即生效
3、查看环境变量:echo $PATH
有效期限:永久有效
用户局限:仅对当前用户
4、安装运行
执行 elasticsearch,显示如下

启动es时,有时候需要等几分钟才能在浏览器中访问到。
在浏览器打开:http://localhost:9200,显示如下,说明安装成功

5、关闭和启动
前台启动:elasticsearch
前台关闭:ctrl+c
后台启动:elasticsearch -d
后台关闭:
查看elasticseatch进程号
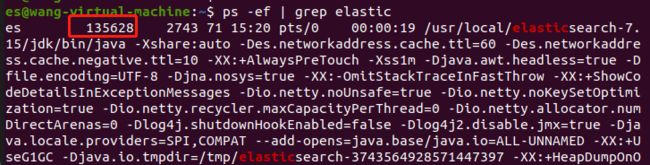
杀死进程
kill -9 135628
第四步 使用
es提供了一系列的接口,进行查询筛选添加等操作,一般使用中,代码框架的db模型都集成了es的相关查询接口,很少需要直接通过api接口去es取数据。
这里仅展示一些简单的接口,需要了解更详细的内容,可在es官网查看
#检测集群是否健康
curl 'localhost:9200/_cat/health?v'
#获取集群的节点列表
curl 'localhost:9200/_cat/nodes?v'
#列出所有索引
curl 'localhost:9200/_cat/indices?v'
#删除指定索引,customer
curl -XDELETE 'localhost:9200/customer'
#查询指定索引index1数据
curl 'localhost:9200/index1/_search'
#查询索引index1中,name=wang的数据
curl -X POST"localhost:9200/index1/_search?pretty" -H 'Content-Type: application/json' -d'
{
"query" : {
"constant_score" : {
"filter" : {
"term" : {
"name" : "wang"
}
}
}
}
}
'
Logstash
es安装成功后,是没有数据的,如果通过es提供的api去插入数据,比较麻烦,也不容易维护。logstash就是为了完成向es中插入数据而诞生的。
第一步 下载并解压文件
为了让ws和lg完美的兼容,要保持他们两个的版本一致,我es使用的是7.15,所有lg也下载的7.15。下载后,同样把lg解压至/usr/local目录下
第二步 下载数据库驱动
我需要从mysql数据库同步数据到es,所以我下载是mysql的驱动,驱动名称和版本为
mysql-connector-java_8.0.26-1ubuntu21.04_all.jar
新建/usr/local/sync目录,该目录下用于存放配置相关文件。我们把数据驱动包放置到sync目录下。
第三步 新建和编辑配置文件
lg可以把数据库中的数据同步到es中,主要就是靠在配置文件中设置数据库的链接和es索引的相关内容,所以配置好lg的配置文件很重要
新建db.con文件,该文件作为主配置文件使用如下
input {
file {
#设置日志文件的路径
path => ["/usr/local/logstash-7.15/logs/run_error.log"]
type => "error"
start_position => "beginning"
}
jdbc {
# 设置 MySql/MariaDB 数据库url以及数据库名称
jdbc_connection_string => "jdbc:mysql://127.0.0.1:3306/www_vmw_web1_com?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true"
# 用户名和密码
jdbc_user => "root"
jdbc_password => "123456"
#处理中文乱码问题,暂时没有用到
#codec => plain { charset => "UTF-8"}
# 数据库驱动所在位置,可以是绝对路径或者相对路径
jdbc_driver_library => "/usr/local/logstash-7.15/sync/mysql-connector-java-8.0.26.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
# 开启分页
jdbc_paging_enabled => "true"
# 分页每页数量,可以自定义
jdbc_page_size => "10000"
# 执行的sql文件路径
statement_filepath => "/usr/local/logstash-7.15/sync/index1.sql"
# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务
schedule => "* * * * *"
# 索引类型,该参数可理解为mysql中的表名,
type => "type1"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件
use_column_value => true
# 记录上一次追踪的结果值
last_run_metadata_path => "/usr/local/logstash-7.15/sync/track_time"
# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间
#比如上次数据库有 10000 条记录,查询完后该文件中就会有数字 10000 这样的记录,下次执行 SQL 查询可以从 10001 条处开始.
#我们只需要在 SQL 语句中 WHERE id > :last_sql_value 即可. 其中 :last_sql_value 取得就是该文件中的值(10000).
tracking_column => "id"
# tracking_column 对应字段的类型,如果为日期必须声明为timestamp
tracking_column_type => "numeric"
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run => false
# 数据库字段名称大写转小写
lowercase_column_names => false
}
}
output {
#input中可配置多个jdbc,每个jdbc记录mysql中一个表的值
#然后在此处判断,并设置每个表的索引名称,自增id等字段
if [type]=="type1" {
elasticsearch {
# es地址
hosts => ["127.0.0.1:9200"]
# 同步的索引名
index => "index1"
# 设置文档的自增id,取msyql表的自增id
document_id => "%{id}"
}
}
if [type]=="type2" {
elasticsearch {
# es地址
hosts => ["127.0.0.1:9200"]
# 同步的索引名
index => "index2"
# 设置_docID和数据相同
document_id => "%{aid}"
}
}
# 日志输出
stdout {
codec => json_lines
}
}
在sync目录新建index1.sql文件,代码如下
select * from index1 where id >= :sql_last_value
第四步 目录权限和其他配置
我们需要新建配置文件中指定的日志目录
/usr/local/logstash-7.15/logs
把logs目录权限设置为777
把目录/usr/local/logstash-7.15/data 权限也设置为777
把文件/usr/local/logstash-7.15/config/jvm.options中的
8-13:-XX:+UseConcMarkSweepGC
改为
8-13:-XX:+UseG1GC
否则会如下错误

第五步 运行
首先在es用下,开启elasticsearch
然后在root用户下,把usr/local/logstash-7.15/bin加入到环境变量。
执行命令
Logstash -f /usr/local/logstash-7.15/sync/db.conf
执行成功后,会出现要sql中查询的数据,如下
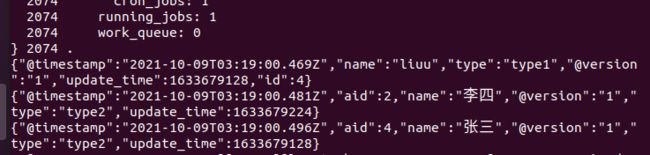
执行成功后,可使用es的api接口查看索引数据。
也可以安装Kibana图形工具查看