kubeadm部署kubernetes1.29.0版本集群
文档持续更新中,请关注账号。
简介:
本次部署使用三台宿主机,一台master节点两台worker节点。使用Kubeadm工具快速部署,部署过程分为四个部分,第一部分,kubernetes集群节点准备,第二部分 docker-ce及cri-docker准备,第三部分,kubernetes1.29.0集群部署,第四部分,kubernetes集群可用性验证。
版本信息汇总如下:kubernetes1.29.0,calico3.27.0,centos7.9,kernel-lt-5.4.264 。
一、Kubernetes集群节点准备
主机信息规划
| 主机IP |
主机名称 |
主机角色 |
| 50.50.100.101 |
050050100101-master |
master |
| 50.50.100.102 |
050050100102-node01 |
node01 |
| 50.50.100.103 |
050050100103-node02 |
node02 |
主机名
所有节点需要运行。
# 50.50.100.101 运行
hostnamectl set-hostname 050050100101-master
# 50.50.100.102 运行
hostnamectl set-hostname 050050100102-node01
# 50.50.100.103 运行
hostnamectl set-hostname 050050100103-node02主机解析
没有dns环境解析需要执行这一步,有dns环境解析就可跳过这一步。如果执行的话 所有节点需要运行。
cat >> /etc/hosts << EOF
50.50.100.101 050050100101-master
50.50.100.102 050050100102-node01
50.50.100.103 050050100103-node02
EOFmachine-id
克隆出来的主机需要检查,物理机器的宿主机不用查看这一步可以跳过。如果执行的话 所有节点需要运行。
这里一般情况下企业会使用模版机器进行克隆主机快速部署机器。这里对每一台克隆出来的主机查看machine-id
# 检查现有id值
cat /etc/machine-id
# 重新生成id值
rm -f /etc/machine-id && systemd-machine-id-setup防火墙
从实际需求出发,如果个人学习Kubernetes关闭防火墙是可以的,但是如果是公司生产环境个人建议打开即可,放行需要通信的内网ip地址。所有节点需要运行。
查看防火墙状态
# 防火墙有两台状态,running是打开状态,no running是关闭状态
~]# firewall-cmd --state
running关闭防火墙
# 关闭防火墙并设置开机自动关闭
systemctl disable --now firewalld
打开防火墙
# 打开防火墙并且开机自启动
systemctl enable --now firewalld
# 配置防火墙规则:放行网段或是IP地址
# 示例
firewall-cmd --add-rich-rule="rule family="ipv4" source address="网段" accept" --permanent
# 案例放行50.50.100.0/24网段
firewall-cmd --add-rich-rule="rule family="ipv4" source address="50.50.100.0/24" accept" --permanent
# 配置完成后热重启防火墙
firewall-cmd --reload
# 查看当前的防火墙规则
firewall-cmd --list-all
public (active)
## 省略
## 省略
## 看到下面这句话就证明防火墙规则添加成功了,50.50.100.0/24网段的机器互相之间可以正常网络通信
rich rules:
rule family="ipv4" source address="50.50.100.0/24" accept免秘钥
从实际需求出发,如果后期有传输文件或远程执行命令的需求可以配置,如果公司有安全规则需要使用统一的跳板机或其它运维工具 这里不建议做,会打破规则引发安全问题。
配置免秘钥只需要在一台机器即可,只在master节点运行。
# 这里用master节点生成秘钥和私钥,这里不用默认的rsa算法,使用ed25519算法,这种算法配置的秘钥连接更快更安全。
ssh-keygen -t ed25519
# 公钥传递给每个节点
for i in 102 103 ; do ssh-copy-id [email protected].$i; done
# 验证ssh免密是否成功 输出每个节点的主机名及ssh免密配置成功
for i in 102 103 ; do ssh [email protected].$i "hostname"; done
swap分区
社区v1.28.0版本中提及可以开启swap分区,但是这个功能还在验证测试阶段,个人实际测试过程中也遇到了很多问题,这里还是建议关闭swap分区。所有节点需要运行。
有两种情况 一个是已有机器关闭swap分区,另一个是新创建机器关闭swap分区。
已有机器关闭swap分区
# 检测是否开启swap分区
swapon -s
文件名 类型 大小 已用 权限
/dev/dm-1 partition 4063228 0 -2
# 临时禁用
swapoff -a
# 永久禁用
sed -i 's/.*swap.*/#&/g' /etc/fstab新创建机器关闭swap分区(阿里云平台的机器创建好是没有swap分区配置的,所以这里只是讲在私有云的情况下如果新建机器就关闭swap)
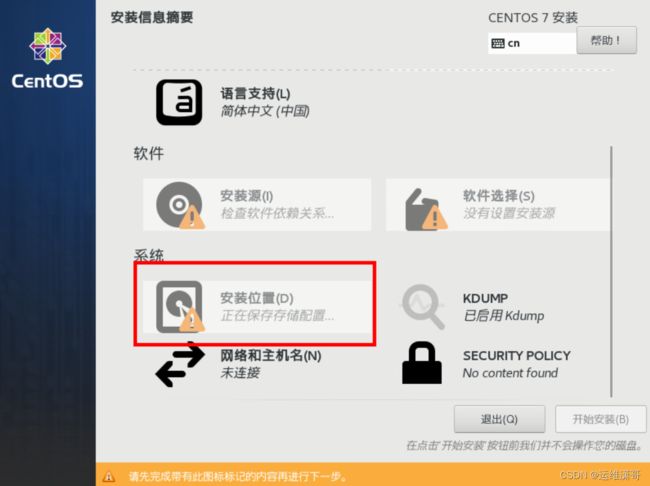
1、安装位置
2、配置分区
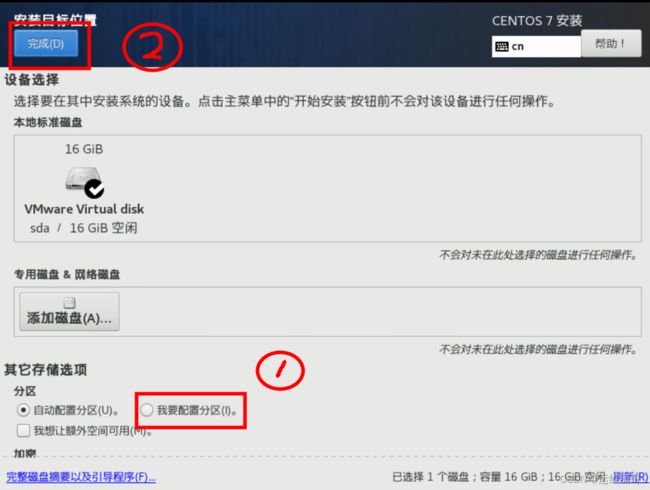
自动创建分区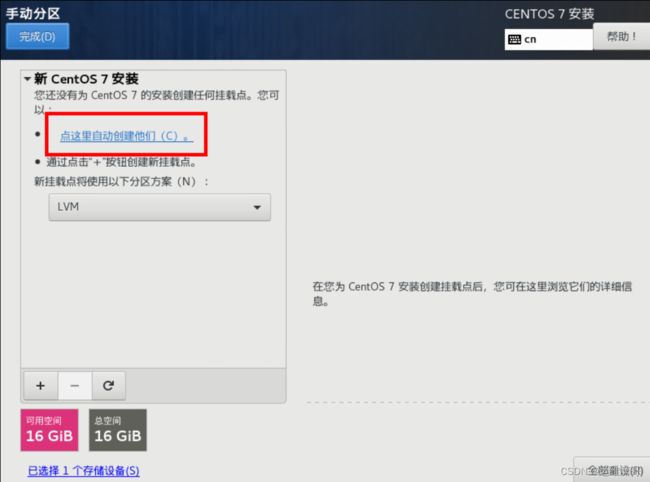
3、删除swap分区配置
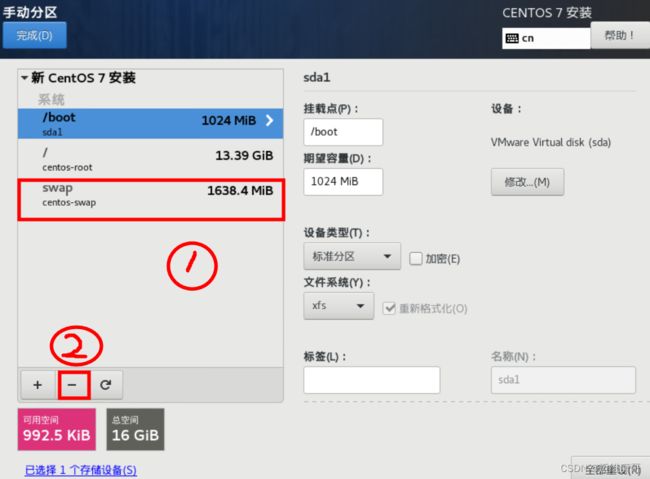

保存后安装完成的系统就不会再有swap分区了。
登录验证查看系统是否有swap。如下图验证成功。


selinux
所有节点需要运行。
建议关闭selinux配置
# 查询是否关闭。Enforcing,Permissive和Disabled。Enforcing表示SELinux正在执行强制访问控制策略,Permissive表示只有当偏离策略时才执行警告,Disabled表示SELinux已被完全禁用。
getenforce
# 配置永久关闭 && 临时关闭
sed -i 's/enforcing/disabled/' /etc/selinux/config && setenforce 0内核参数调整
所有节点需要运行。
配置参数
cat >> /etc/sysctl.d/k8s.conf << EOF
vm.swappiness=0
EOF
cat >> /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF参数生效
# 加载模块
modprobe br_netfilter; modprobe overlay;
# 更新配置
# 第一种方式
sysctl -p /etc/sysctl.d/k8s.conf
# 第二种方式
sysctl --system系统内核
这里使用的系统内核是Kernel 5.4.264版本。个人不建议使用太高的内核版本,之前使用过6.6.8的内核版本,会在calico运行中calico-node出现报错Ipset和内核不兼容的问题,目前退到Kernel 5.4.xxx版本才得以解决。注意目前有些kubernetes插件是需要内核6版本以上的,所以使用几版本需要查看软件的具体情况。考虑到大家的网络环境这里分为在线安装和离线安装。所有节点需要运行。
在线安装
# 导入gpg key
rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
# 变更elrepo yum源仓库
yum -y install https://www.elrepo.org/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
# 安装lt长期维护版本
yum --enablerepo="elrepo-kernel" -y install kernel-lt.x86_64
(ml为长期稳定版本,lt为长期维护版版本)
# 设置grub2默认引导为0
grub2-set-default 0
# 重新生成grub2引导文件
grub2-mkconfig -o /boot/grub2/grub.cfg重启系统内核生效,uname -r 查看现在系统运行的内核版本
# 重启
init 6
# 查看内核
uname -r
5.4.264-1.el7.elrepo.x86_64离线安装
下载的rpm包进行安装
内核官网地址
清华大学源-内核地址
下载两个包上传到服务器上即可。
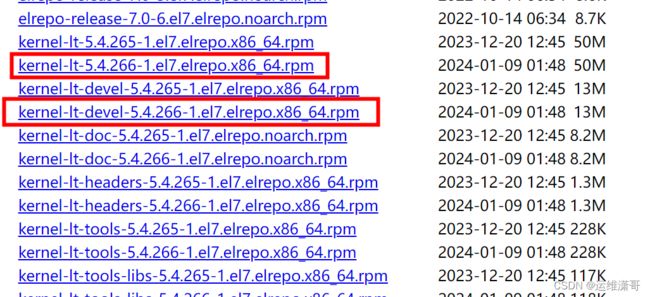
# 在包的目录位置运行
yum -y localinstall *.rpm
# 变更引导
grub2-set-default 0 && grub2-mkconfig -o /etc/grub2.cfg
# 重启
init 6
# 查看内核
uname -r系统引导文件有两个 /etc/grub2.cfg /boot/grub2/grub.cfg 只需要改一个即可
安装ipset及ipvsadm
实际生产中需要讲 用ipvs替换掉Iptalbs。所有节点需要运行。
# 添加内核脚本
cat > /etc/sysconfig/modules/ipvs.modules <时间同步
这里使用chrony服务,暂不考虑ntp服务,chrony目前是centos7系统使用的时间同步服务,比ntp更加稳定高效。所有节点需要运行。
设置时区
# 查看时区
timedatectl
#设置上海时区
timedatectl set-timezone Asia/Shanghai配置chronyd服务
# 安装chronyd服务 一般默认安装完centos7就会有这个服务,一般都会有,所以一般不用Yum
yum -y install chrony
# 变更配置文件 在最后一行添加阿里云时间服务器
sed -i '$a\server ntp1.aliyun.com iburst' /etc/chrony.conf
# 启动服务
systemctl enable --now chronyd
# 验证
~]# chronyc tracking
Reference ID : 00000000 ()
Stratum : 0
Ref time (UTC) : Thu Jan 01 00:00:00 1970
System time : 0.000000000 seconds slow of NTP time
Last offset : +0.000000000 seconds
RMS offset : 0.000000000 seconds
Frequency : 8.652 ppm slow
Residual freq : +0.000 ppm
Skew : 0.000 ppm
Root delay : 1.000000000 seconds
Root dispersion : 1.000000000 seconds
Update interval : 0.0 seconds
Leap status : Not synchronised
# 手工强制同步
chronyc -a makestep
二、Docker-ce及cri-dockerd准备
这个章节所有步骤所有节点需要运行。
安装Docker-ce
kubernetes从1.24版本后开始默认是containerd容器。抛弃对接docker-sim,如果想要把docker作为kubernetes的容器环境需要安装cri-docker。考虑到网络环境分为在线安装和离线安装。所有节点需执行。
在线安装(这里默认安装了最新版的docker-ce 24版本)
阿里云docker-ce开源站点
# step 1: 安装必要的一些系统工具
sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# Step 2: 添加软件源信息
sudo yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# Step 3
sudo sed -i 's+download.docker.com+mirrors.aliyun.com/docker-ce+' /etc/yum.repos.d/docker-ce.repo
# Step 4: 更新并安装Docker-CE
sudo yum makecache fast
sudo yum -y install docker-ce
# Step 4: 开启Docker服务
sudo systemctl enable --now docker
# step 5: 查看容器镜像版本
docker]# docker -v
Docker version 24.0.7, build afdd53b
# 注意:
# 官方软件源默认启用了最新的软件,您可以通过编辑软件源的方式获取各个版本的软件包。例如官方并没有将测试版本的软件源置为可用,您可以通过以下方式开启。同理可以开启各种测试版本等。
# vim /etc/yum.repos.d/docker-ce.repo
# 将[docker-ce-test]下方的enabled=0修改为enabled=1
#
# 安装指定版本的Docker-CE:
# Step 1: 查找Docker-CE的版本:
# yum list docker-ce.x86_64 --showduplicates | sort -r
# Loading mirror speeds from cached hostfile
# Loaded plugins: branch, fastestmirror, langpacks
# docker-ce.x86_64 17.03.1.ce-1.el7.centos docker-ce-stable
# docker-ce.x86_64 17.03.1.ce-1.el7.centos @docker-ce-stable
# docker-ce.x86_64 17.03.0.ce-1.el7.centos docker-ce-stable
# Available Packages
# Step2: 安装指定版本的Docker-CE: (VERSION例如上面的17.03.0.ce.1-1.el7.centos)
# sudo yum -y install docker-ce-[VERSION]
离线安装
官网rpm下载站点

# 在下载好的rpm当前目录运行
yum -y localinstall *.rpm
# 启动并加入开机自启
systemctl enable --now docker-ce配置Docker-ce
cgroup driver调整( "exec-opts": ["native.cgroupdriver=systemd"] 这句话是告诉cgroup应该是由谁来管理)
# 添加配置文件
cat >> /etc/docker/daemon.json << EOF
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn"
],
"insecure-registries": ["私有仓库地址.com"],
"exec-opts": ["native.cgroupdriver=systemd"]
}
EOF
# 重启docker
systemctl restart docker验证配置是否生效
]# docker info
# 省略
Insecure Registries:
私有仓库.com
127.0.0.0/8
Registry Mirrors:
https://docker.mirrors.ustc.edu.cn/
Live Restore Enabled: false变更Docker-ce的存储位置
个人认为这里是需要做一个存储位置变更的,如果根目录只有50G的话,容器镜像文件长期使用会把硬盘占满,这里建议大家更换存储位置。这是一个选择题看你的选择。只需要提前准备好硬盘,并在配置文件中加入一行,重启docker即可,( "data-root": "/data/dockerdb/docker")记得提前把/var/lib/docker的文件复制到新的目录里。
# 24版本之前在
# 配置文件中/usr/lib/systemd/system/docker.service 添加 --graph=/data/dockerdb/docker即可
# 24版本开始在
# 配置文件中 /etc/docker/daemon.json 添加字段 "data-root": "/data/dockerdb/docker"
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn"
],
"insecure-registries": ["私有仓库地址.com"],
"exec-opts": ["native.cgroupdriver=systemd"],
"data-root": "/data/dockerdb/docker"
}
# 验证
- ]# docker info | grep data
Docker Root Dir: /data/dockerdb/docker安装cri-dockerd
# 下载好包 https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.8/cri-dockerd-0.3.8-3.el7.x86_64.rpm
# 在包的当前目录运行
yum -y localinstall cri-dockerd-0.3.8-3.el7.x86_64.rpm
# 启动并开机启动
systemctl enable --now cri-docker
Created symlink from /etc/systemd/system/multi-user.target.wants/cri-docker.service to /usr/lib/systemd/system/cri-docker.service.
# 查看运行状态
# 查看running
systemctl status cri-docker
● cri-docker.service - CRI Interface for Docker Application Container Engine
Loaded: loaded (/usr/lib/systemd/system/cri-docker.service; enabled; vendor preset: disabled)
Active: active (running)
# 查看active
systemctl is-active cri-docker
active配置cri-dockerd
这里需要指定cri-dockerd从哪里获取镜像,这里也可以改为私有仓库。
# 需要变更的配置文件
cat /usr/lib/systemd/system/cri-docker.service
# 在ExecStart=/usr/bin/cri-dockerd 后面新增配置这里如果网络可以就用国外的 --pod-infra-container-image=registry.k8s.io/pause:3.9
# 网络不方便使用国外的阿里源 --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
# 新增配置文件的位置
ExecStart=/usr/bin/cri-dockerd --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9 --container-runtime-endpoint fd://
# 重启cri-dockerd
systemctl daemon-reload && systemctl restart cri-docker
三、kuberneter 1.29.0集群部署
kubeadm,kubelet和kubectl软件安装
所有节点需要运行。
# 之前google的源已经不能用了,换成社区的源才可以安装
cat > /etc/yum.repos.d/ kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/
enabled=1
gpgcheck=1
gpgkey=https://pkgs.k8s.io/core:/stable:/v1.29/rpm/repodata/repomd.xml.key
EOF
# 查看软件是否存在
]# yum list | grep kubeadm
kubeadm.x86_64 1.29.0-150500.1.1 kubernetes
]# yum list | grep kubectl
kubectl.x86_64 1.29.0-150500.1.1 kubernetes
]# yum list | grep kubelet
kubelet.x86_64 1.29.0-150500.1.1 kubernetes
# 安装软件
yum -y install kubeadm kubectl kubelet
# 查询安装指定版本
yum list kubeadm.x86_64 --showduplicates | sort -r
yum list kubelet.x86_64 --showduplicates | sort -r
yum list kubectl.x86_64 --showduplicates | sort -r配置kubelet
(为了实现docker使用的cgroupdriver与kubelet使用的cgroup的一致性)
cat /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS="--cgroup-driver=systemd"kubelet指定配置文件位置,版本不同有可能会在初始化的时候报错找不到。
# add配置文件在ExecStart后增加 --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml
]# cat /lib/systemd/system/kubelet.service
[Unit]
Description=kubelet: The Kubernetes Node Agent
Documentation=https://kubernetes.io/docs/
Wants=network-online.target
After=network-online.target
[Service]
ExecStart=/usr/bin/kubelet --kubeconfig=/etc/kubernetes/kubelet.conf --config=/var/lib/kubelet/config.yaml
Restart=always
StartLimitInterval=0
RestartSec=10
[Install]
WantedBy=multi-user.targetKubelet服务配置好 加入开启自启动就好了,其它的不用处理。
# 这里不要启动。这里如果启动,kubeadm初始化集群的时候会报错端口占用。
systemctl enable kubelet镜像下载
只需要在master节点运行。
# 列出需要的镜像文件,这里是国外的镜像,国内下载不到,需要换成阿里源
kubeadm config images list
registry.k8s.io/kube-apiserver:v1.29.0
registry.k8s.io/kube-controller-manager:v1.29.0
registry.k8s.io/kube-scheduler:v1.29.0
registry.k8s.io/kube-proxy:v1.29.0
registry.k8s.io/coredns/coredns:v1.11.1
registry.k8s.io/pause:3.9
registry.k8s.io/etcd:3.5.10-0
# 下载镜像用阿里源下载
kubeadm config images pull --cri-socket unix:///var/run/cri-dockerd.sock --image-repository registry.aliyuncs.com/google_containers --kubernetes-version=v1.29.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-apiserver:v1.29.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-controller-manager:v1.29.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-scheduler:v1.29.0
[config/images] Pulled registry.aliyuncs.com/google_containers/kube-proxy:v1.29.0
[config/images] Pulled registry.aliyuncs.com/google_containers/coredns:v1.11.1
[config/images] Pulled registry.aliyuncs.com/google_containers/pause:3.9
[config/images] Pulled registry.aliyuncs.com/google_containers/etcd:3.5.10-0注意:
1、默认地址需要访问国外地址,登录google账号下载。
2、下载文件获取不到,这里指定1.29.0版本就不会报错了。添加参数 --kubernetes-version=v1.29.0。
]# kubeadm config images pull --cri-socket unix:///var/run/cri-dockerd.sock --image-repository registry.aliyuncs.com/google_containers
W0103 17:29:09.594951 2511 version.go:104] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get "https://cdn.dl.k8s.io/release/stable-1.txt": context deadline exceeded (Client.Timeout exceeded while awaiting headers)
W0103 17:29:09.595113 2511 version.go:105] falling back to the local client version: v1.29.0
初始化集群
只需要在master节点运行。
kubeadm init --kubernetes-version=v1.29.0 --pod-network-cidr=30.244.0.0/16 --apiserver-advertise-address=50.50.100.100 --cri-socket unix:///var/run/cri-dockerd.sock --image-repository registry.aliyuncs.com/google_containers 参数解读
| 参数 | 解读 |
| kubeadm init | 集群初始化 |
| --kubernetes-version=v1.29.0 | 指定初始化集群版本 |
| --pod-network-cidr=30.244.0.0/16 | 指定pod地址网段 |
| --apiserver-advertise-address=50.50.100.100 | apiserver的ip地址 |
| --cri-socket unix:///var/run/cri-dockerd.sock | 指定docker做为容器 |
| --image-repository registry.aliyuncs.com/google_containers | 指定从阿里源下载镜像 |
这个是可选参数可以加
--ignore-preflight-errors=all
运行完初始化命令后观察日志,看到这句话就说明初始化成功了。
Your Kubernetes control-plane has initialized successfully!
输出日志记得保存到文本文件,这里只是截取了部分日志内容。
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 50.50.100.100:6443 --token 4bel49.8eioqjsiohuqnz1m \
--discovery-token-ca-cert-hash sha256:8028ebfc4639eb2411de1511b3xxxxxxxxxx958bf7b976c598c 只需要在master节点运行。
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
注意:这一步必须要做,无法下一步
验证初始化是否成功,能看到下面有一个节点是noready状态的就说明初始化成功了。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
050050100100-master-cm5 NotReady control-plane 2m39s v1.29.0worker节点加入
只需要在worker节点运行。
加入前的最后检查,如果机器的这两个值相同请参照前面的内容把id值变更。
# 如果这样就不会有问题,如果是克隆出来的节点会有mac地址重复的问题。注意
# 机器A
]# cat /sys/class/dmi/id/product_uuid
c6bc1f42-c659-8ba8-ef6d-7b31be3f34e5
# 机器B
]# cat /sys/class/dmi/id/product_uuid
ea0f1f42-f48f-2215-c427-f9d54facce76准备就绪开始加入worker节点(这里是复制初始化时让保存的文本文件的最后一行,每个人的不同,根据初始化内容复制即可,这里需要加一句话 --cri-socket unix:///var/run/cri-dockerd.sock 这里指明了是使用cri-dockerd也就是docker做为容器)。
kubeadm join 50.50.100.100:6443 --token 29kak1.hsfh1nz7cyzvkul9 \
--discovery-token-ca-cert-hash sha256:08847660fabf86ad8549c9793xxxxxxxxxxxxx0dd5b9cf7be4a1c --cri-socket unix:///var/run/cri-dockerd.sock注意:
1、这里需要加上 --cri-socket unix:///var/run/cri-dockerd.sock 让集群知道是docker容器,不然会报错。
2、复制语句要检查看一下是否有复制到空格,很容易会导致错误,下面的错误就是复制到了空格。
accepts at most 1 arg(s), received 3
To see the stack trace of this error execute with --v=5 or higher
只需要在master节点运行。
验证节点是否加入成功。如果看到多两个节点,这就算是worker节点加入成功了。
# kubectl get nodes
NAME STATUS ROLES AGE VERSION
050050100100-master NotReady control-plane 2m39s v1.29.0
050050100101-node01 NotReady 2m39s v1.29.0
050050100102-node02 NotReady 2m39s v1.29.0 网络插件calico
calico网络插件分为离线安装和在线安装。只需要在master节点运行。
离线安装
calico的github下载地址
这个包里包含了脚本和容器镜像,在下面点击更多可查看到
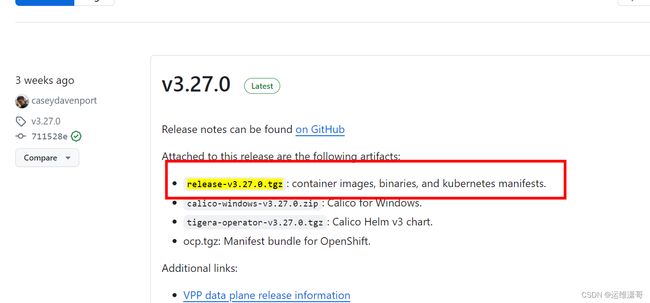
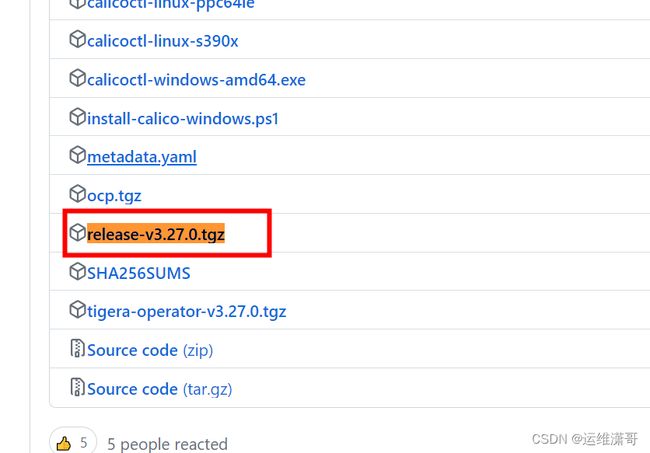
下载镜像,把镜像导出到服务器上
# 解压
tar xf release-v3.27.0.tgz
# 进入目录查看文件
cd release-v3.27.0
bin images manifests
# 变更目录名称
mv release-v3.27.0 Calico-v3.27.0
# 进入镜像文件导入到docker里
images]# ls
calico-cni.tar calico-flannel-migration-controller.tar calico-node.tar calico-typha.tar
calico-dikastes.tar calico-kube-controllers.tar calico-pod2daemon.tar
# 批量循环导入镜像文件
for file in *.tar ; do docker load -i "$file"; done创建calico服务
# cd切换到这个目录里
manifests]# pwd
/root/Calico-v3.27.0/manifests
# 这个不需要变更直接运行即可
]# kubectl create -f tigera-operator.yaml
namespace/tigera-operator created
# 这个需要变更 文件内的192.168.0.0/16修改为初始化kubernetes内的30.244.0.0/16
kubectl create -f custom-resources.yaml
# 新增两个地方
# 变更1 这里变更成自己的pod网段
cidr: 30.244.0.0/16
# 变更2 这里变更成自己的网卡信息
nodeAddressAutodetectionV4:
interface: ens*
# custom-resources.yaml 配置文件示例
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
# Note: The ipPools section cannot be modified post-install.
ipPools:
- blockSize: 26
cidr: 30.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
nodeAddressAutodetectionV4:
interface: ens*
---
# This section configures the Calico API server.
# For more information, see: https://docs.tigera.io/calico/latest/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
创建资源后查看pod的实时运行状态
watch kubectl get pods -n calico-system
在线安装
在线安装会遇到一个无法解析和网络不通的问题,需要自行解决
~]# kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/tigera-operator.yaml
The connection to the server raw.githubusercontent.com was refused - did you specify the right host or port?
# 这里网络不通
~]# vim /etc/hosts
# 添加解析地址
185.199.108.133 raw.githubusercontent.com
~]# kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/tigera-operator.yaml
namespace/tigera-operator created
customresourcedefinition.apiextensions.k8s.io/bgpconfigurations.crd.projectcalico.org created
customresourcedefinition.apiextensions.k8s.io/bgpfilters.crd.projectcalico.org created
###
###
###
io/imagesets.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/installations.operator.tigera.io created
customresourcedefinition.apiextensions.k8s.io/tigerastatuses.operator.tigera.io created
serviceaccount/tigera-operator created
clusterrole.rbac.authorization.k8s.io/tigera-operator created
clusterrolebinding.rbac.authorization.k8s.io/tigera-operator created
deployment.apps/tigera-operator created
查看是否安装成功tigera服务。
# 查询所有命名空间
kubectl pod ns
##
tigera-operator Active 4m17s
##
# 查看Tigera是否安装成功
# kubectl get pods -n tigera-operator
NAME READY STATUS RESTARTS AGE
tigera-operator-55585899bf-52zsv 1/1 Running 0 6m36s
下载custom-resources.yaml文件进行变更再进行运行。
# 下载到本地
# wget https://raw.githubusercontent.com/projectcalico/calico/v3.27.0/manifests/custom-resources.yaml
# custom-resources.yaml 配置示例
s section includes base Calico installation configuration.
# For more information, see: https://projectcalico.docs.tigera.io/master/reference/installation/api#operator.tigera.io/v1.Installation
apiVersion: operator.tigera.io/v1
kind: Installation
metadata:
name: default
spec:
# Configures Calico networking.
calicoNetwork:
# Note: The ipPools section cannot be modified post-install.
ipPools:
- blockSize: 26
# cidr: 192.168.0.0/16
cidr: 30.244.0.0/16
encapsulation: VXLANCrossSubnet
natOutgoing: Enabled
nodeSelector: all()
---
# This section configures the Calico API server.
# For more information, see: https://projectcalico.docs.tigera.io/master/reference/installation/api#operator.tigera.io/v1.APIServer
apiVersion: operator.tigera.io/v1
kind: APIServer
metadata:
name: default
spec: {}
检查好变更的配置文件创建资源,再次查看集群整体的Node的状态,如果为ready证明集群运行良好。
# 创建资源
~]# kubectl create -f custom-resources.yaml
installation.operator.tigera.io/default created
apiserver.operator.tigera.io/default created
# 查询集群的运行状态
~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8smaster Ready control-plane 165m v1.29.0
node1 Ready 142m v1.29.0
node2 Ready 124m v1.29.0
# status 状态 ready及正常运行 kube-proxy模式为IPVS模式
kube-proxy默认采用iptables作为代理,而iptables的性能有限,不适合生产环境,需要改为IPVS模式。只需要在master节点运行。
]# kubectl get pods -n kube-system | grep 'kube-proxy'
kube-proxy-4895q 1/1 Running 0 41h
kube-proxy-9gfbv 1/1 Running 0 41h
kube-proxy-lcrfr 1/1 Running 0 41h
kube-proxy-zkk8j 1/1 Running 0 41hkube-proxy修改为IPVS的前提
需要安装ipset和ipvsadm,并加载ipvs模块,本文安装kubernetes时已经设置,这里未安装的需要查看前面的文档进行安装。只需要在master节点运行。
# 进入热加载edit模式
kubectl edit configmap kube-proxy -n kube-system
# 找到 mode: ""#原配置此处为空,需要修改为mode: "ipvs"
# 省略 1.29 大约在57行,需要根据实际情况变更
mode: "ipvs"#原配置此处为空,
# 省略重启kube-proxy组件
kubectl rollout restart daemonset kube-proxy -n kube-system 检查kube-proxy运行模式,重启kube-proxy进程后容器Pods会销毁并重新创建,看到日志中有输出
- ]# kubectl get pods -n kube-system | grep 'kube-proxy'
kube-proxy-2lghf 1/1 Running 0 1s
kube-proxy-4895q 1/1 Terminating 0 41h
kube-proxy-56nhb 1/1 Running 0 3s
# 查询一台pod日志即可
- ]# kubectl logs -n kube-system kube-proxy-2lghf
# 这里就不过多输出了,看到下面两句话已经使用了IPVS
# 省略
s.go:236] "Using ipvs Proxier"
## 省略
I0105 03:30:53.524802 1 proxier.go:409] "IPVS scheduler not specified, use rr by default"四、kuberneter集群可用性验证
集群验证
只需要在master节点运行。
]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
050050100101-master Ready control-plane 3h41m v1.29.0
050050100102-node1 Ready 3h36m v1.29.0
050050100103-node2 Ready 3h36m v1.29.0
~]# kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy ok 创建Pod验证节点互相访问ClusterIP
只需要在master节点运行。
创建一个nginx的pod,三个节点之间访问一下是否可以访问nginx欢迎页,如可以访问到就证明集群正常。在master创建一个存放yaml的目录创建一个文件nginx-test.yaml。
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-apps03
spec:
replicas: 1
selector:
matchLabels:
app: nginx03
template:
metadata:
labels:
app: nginx03
spec:
containers:
- name: nginxapps
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-apps
spec:
type: ClusterIP
selector:
app: nginx03
ports:
- protocol: TCP
port: 80
targetPort: 80查看验证
# 查看刚创建的资源
~]# kubectl get deployment
NAME READY UP-TO-DATE AVAILABLE AGE
nginx-apps03 1/1 1 1 40s
# 查看svc资源
~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 3h49m
nginx-apps ClusterIP 10.102.71.126 80/TCP 45s 在任意一台节点访问10.102.71.126:80查看是否可以出来nginx欢迎页。
~]# curl 10.102.71.126
# 省略
Welcome to nginx!
# 省略创建Pod验证节点集群外访问nodeport
创建一个nginx资源和网络nodeport,并验证访问。同上创建一个资源文件。
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-apps03
spec:
replicas: 1
selector:
matchLabels:
app: nginx03
template:
metadata:
labels:
app: nginx03
spec:
containers:
- name: nginxapps
image: nginx:latest
imagePullPolicy: IfNotPresent
ports:
- containerPort: 80
---
---
apiVersion: v1
kind: Service
metadata:
name: nginx-apps
spec:
type: NodePort
selector:
app: nginx03
ports:
- protocol: TCP
port: 80
targetPort: 80创建资源验证访问
]# kubectl create -f nginx.yaml
deployment.apps/nginx-apps03 created
service/nginx-apps created
~]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 443/TCP 3h53m
nginx-apps NodePort 10.100.192.117 80:32192/TCP 4s 可以访问到宿主机的网络环境内,浏览器打开输入任意一个节点ip地址,输入端口号即可访问。
http://50.50.100.102:32192/
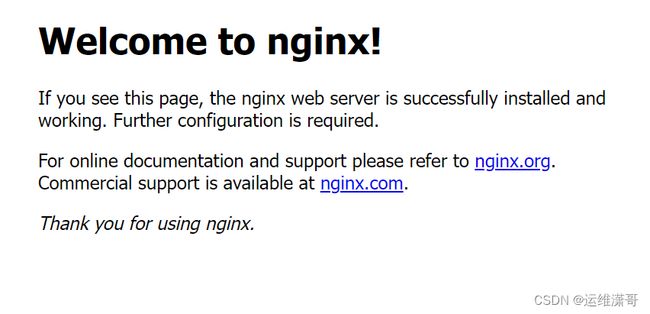
至此kubernetes 1.29.0集群搭建完成并验证完成。
结束语:
感谢大家一致以来的支持,大家多多点赞收藏支持一下哈。