数据结构学习日记三:树
五、树
1、静态查找
1.1 顺序查找:O(n)
哨兵的好处是,可以只靠自然的循环顺序进行查找,实现当碰到哨兵自动退出循环的效果。无哨兵的时候,循环的条件需要多一条分支判断,防止数组访问越界。
int Search(List L, ElementType K){
//在L[1]到L[n]中查找k
int i;
L->Data[0] = K; //建立哨兵
for(i = L->Length; L->Data[i] != K; i--);
return i; //找到返回下标i,否则返回0
}
1.2 二分查找
适用于有序的数组里的查找。
int BinarySearch(List L, ElementType K){
int left, right, mid, NoFound = -1;
//初始化左右边界
left = 1;
right = L->Length;
while(left <= right){
mid = (left + right)/2; //计算中间坐标
if(K < L->Data[mid]) right = mid - 1;
else if(K > L->Data[mid]) left = mid + 1;
else return mid; //查找成功
}
return NoFound; //查找不成功,返回-1
}
2、树的性质
- 子树是不相交的;
- 除了根结点外,每个结点有且仅有一个父结点;
- 一棵N个结点的树有N-1条边。
3、二叉树的重要性质
- 二叉树第 i 层的最大结点数为:2i-1,i >=1。
- 深度为 k 的二叉树有最大结点总数为:2k-1,k>=1。
- 对于任何非空二叉树,若 n0 表示叶结点的个数、n2 是度为2的非叶子结点个数,那么两者满足关系 n0 = n2 + 1。
4、二叉树的存储结构
4.1 顺序存储结构
完全二叉树: 它的结点的编号刚好是顺着的,按从上到下,从左到右排列。

性质:
假设序号从1开始。
- 非根节点 i 的父结点的序号是【i/2】;
- i 结点的左孩子结点的序号是【2i】
- 要保证 2i <= n,否则没有左孩子;
- i 结点的右孩子结点的序号是【2i+1】
- 要保证 2i+1<=n,否则没有右孩子。
4.2 链表存储
左右孩子表示法。
typedef struct TreeNode* BinTree;
typedef BinTree Position;
struct TreeNode{
ElementType Data;
BinTree Left;
BinTree Right;
}
5、二叉树的遍历
5.1 先序遍历
//根 左 右
void PreOrderTraversal(BinTree BT){
if(BT){
printf("%d",BT->Data);
PreOrderTraversal(BT->Left);
PreOrderTraversal(BT->Right);
}
}

先根,也就是A。然后遍历左子树(先根B,然后遍历左子树(先根D,因为无左右子树,所以回退到B),接着遍历右子树F)。。。同理
先序遍历:A (B D F E) (C G H I)
5.2 中序遍历
//左 根 右
void InOrderTraversal(BinTree BT){
if(BT){
InOrderTraversal(BT->Left);
printf("%d",BT->Data);
InOrderTraversal(BT->Right);
}
}
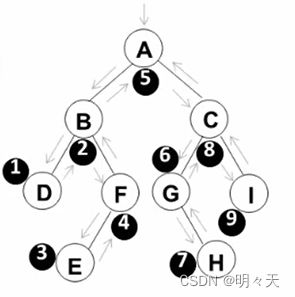
先遍历A的左子树(先遍历B的左子树(遍历D,然后回退到B),遍历根B,遍历右子树(遍历左子树E,回退遍历F)),回退遍历根结点A,然后遍历右子树。。。同理。
中序遍历:(D B E F)A (G H C I)
中序遍历的非递归遍历算法
void InOrderTraversal(BinTree BT){
BinTree T = BT;
Stack S = CreateStack(MaxSize); //创建并初始化堆栈
while(T || !IsEmpty(S)){
while(T){ //一直把左孩子压栈
Push(S,T);
T = T->Left;
}
if(!IsEmpty(S)){
T = Pop(S); //弹栈,
printf("%5d", T->Data); //打印数据
T = T->Right; //转向右结点
}
}
}
对于先序、中序、后序,其实遍历路径是一样的,就是输出值的时机不一样。先序是在第一次碰到结点的时候就输出,中序是第二次,后序是第三次。
反映到非递归,使用堆栈实现的时候就是:
第一次碰到结点:压栈的时候。输出放到压栈Push(S)前
第二次碰到结点:弹栈的时候。输出放到Pop(S)后。
5.3 后序遍历
//左 右 根
void PostOrderTraversal(BinTree BT){
if(BT){
PostOrderTraversal(BT->Left);
PostOrderTraversal(BT->Right);
printf("%d",BT->Data);
}
}
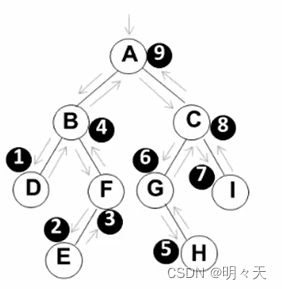
后序遍历:(D E F B) (H G I C) A
后序遍历的非递归算法
实现流程:先把根结点压栈;
如果有左孩子,就压栈,并移动当前结点为左孩子;
如果没有左孩子,就考虑有没有右孩子:
如果有右孩子,就把右孩子压栈,并且当前结点指向右孩子,然后从步骤1重复。
如果没有右孩子,就输出该结点,并且考虑是否为下一个栈顶元素的右孩子:
- 如果是右孩子,说明对于当前栈顶元素,其左右孩子都遍历完了,可以输出该栈顶元素。
- 如果是左孩子,就还要考虑是否有右孩子,然后从步骤1重复。
void PostOrderTraversal(BinTree BT){
if(NULL == BT) return; //空树
Stack S = CreateStack(MaxSize); //创建和初始化堆栈
BinTree currentNode = BT; //存储当前访问结点
BinTree visitedNode = BT; //存储上一个访问结点
//当前结点非空,或者栈非空时
while(currentNode || !IsEmpty(S)){
//当前结点非空,就沿着左子树方向入栈
while(currentNode){
Push(currentNode,S);
currentNode = currentNode->Left;
}
currentNode = Top(S); //获取当前栈顶元素
//如果栈顶元素有右子树,且未被访问
if(currentNode->Right && currentNode->Right != visitedNode){
currentNode = currentNode->Right;
}
else{
//子树为空或被访问过
printf("%d ",currentNode->Data);//访问结点数据
visitedNode = currentNode; //记录当前访问的结点
currentNode = NULL; //当前结点置为NULL,防止重复访问左子树
Pop(S);//出栈
}
}
}
5.4 层序遍历
void LevelOrderTraversal(BinTree BT){
Queue Q;
BinTree T;
if(!BT) return; //空树直接返回
Q = CreateQueue(MaxSize); //创建并初始化队列
AddQ(Q, BT);
while(!IsEmptyQ(Q)){
T = DeleteQ(Q);
printf("%d\n", T->Data); //访问结点
if(T->Left) AddQ(Q, T->Left); //把左右孩子塞入队列
if(T->Right) AddQ(Q, T->Right);
}
}
6、遍历二叉树的应用
输出二叉树中的叶子结点
void fun(BinTree BT){
if(BT){
if(!BT->Left && !BT->Right)
printf("%d",BT->Data);
PreOrderTraversal(BT->Left);
PreOrderTraversal(BT->Right);
}
}
求二叉树的高度
递归,想象一下就是求 MAX(左子树的高度,右子树的高度)+1。
int PostOrderGetHeight(BinTree BT){
int HL,HR,MaxH;
if(BT){
HL = PostOrderGetHeight(BT->Left);
HR = PostOrderGetHeight(BT->Right);
MaxH = (HL > HR) ? HL : HR;
return (MaxH + 1);
}
else return 0; //递归的终止条件,空树深度为0
}
二元运算表达式树及其遍历
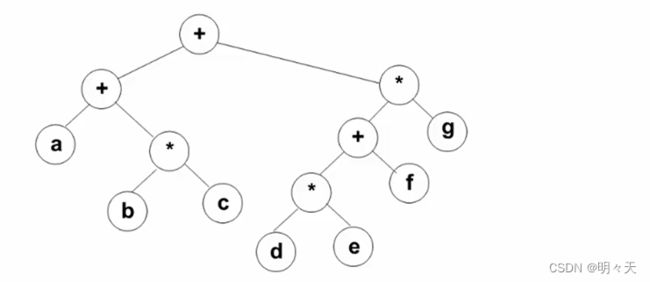
该树特点: 叶子是运算数,非叶子结点是运算符。
对该树前序遍历得到前缀表达式,中序遍历得到中缀表达式,后序遍历得到后缀表达式。
输出中缀表达式的时候,会受到运算符优先级的影响,所以应该在输出左子树的时候先输出左括号,输出完左子树,加上右括号。
由两种遍历序列确定二叉树
必须要有中序遍历才行。
1. 先序和中序确定二叉树
- 先序的第一个结点是根结点;
- 拿着根结点,把中序遍历序列划分成左右两个子序列;
- 然后在上一个先序序列里数出和左子序列相同数量的结点,就得到当前左子序列对应的先序序列,然后就可以拿着新的左子树的先序序列和中序序列求解。右子序列同样解法。
7、二叉搜索树
二叉搜索树(BST,Binary Search Tree)也称二叉排序树或二叉查找树。
性质:
- 非空左子树的所有键值小于其根结点的键值;
- 非空右子树的所有键值大于其根结点的键值;
- 左右子树都是二叉搜索树。
二叉搜索树操作的特别函数:
(1、查找任意元素;2、查找最小元素;3、查找最大元素。)并返回地址。4、插入;5、删除。
7.1 查找操作Find
Position Find(ElementType X, BinTree BST){
if(!BST) return NULL; //查找失败
if(X > BST->Data)
return Find(X, BST->Right);
else if(X < BST->Data)
return Find(X, BST->Left);
else
return BST; //查找成功,返回结点地址
}
因为上述递归是“尾递归”,所以可以改成循环,提高效率。
Position Find(ElementType X, BinTree BST){
while(BST){
if(X > BST->Data)
BST = BST->Right;
else if(X < BST->Data)
BST = BST->Left;
else
return BST; //查找成功,返回结点地址
}
return NULL;
}
7.2 查找最大和最小元素
查找最小元素的递归函数
Position FindMin(BinTree BST){
if(!BST) return NULL;
else if(!BST->Left)
return BST; //找到最左叶结点并返回
else
return FindMin(BST->Left); //沿着左子树继续查找
}
查找最大元素的迭代函数
Position FindMax(BinTree BST){
if(BST)
while(BST->Right) BST = BST->Right;
//找到最右结点
return BST;
}
7.3 二叉搜索树的插入
BinTree Insert(ElementType X,BinTree BST){
if(!BST){
//若原树为空,就生成只有一个结点的二叉搜索树返回
//第二种情况:找到插入位置了,生成新结点,然后返回地址给父亲结点
BST = (BinTree)malloc(sizeof(struct TreeNode));
BST->Data = X;
BST->Left = BST->Right = NULL;
} else{
//寻找插入的位置
if(X < BST->Data)
BST->Left = Insert(X,BST->Left);
else if(X > BST->Data)
BST->Right = Insert(X,BST->Right);
//if x已经在树中存在,什么都不做
}
return BST;
}
递归太霸道了,少年你把握不住啊!
滑到插入位置,生成新结点,放在其左孩子或右孩子,然后原路返回。
7.4 二叉搜索树的删除
三种情况:
- 删除的是叶结点:直接删除叶结点,修改父亲结点的相应指向为NULL;
- 删除的是只有一个孩子的结点:将其父结点的指针指向要删除结点的孩子结点;
- 删除的是有左右子树的结点:用了一个结点替代被删除结点,右子树的最小元素或者左子树的最大元素。(因为这个结点完美满足搜索树的左小右大原则)
BinTree Delete(ElementType X, BinTree BST){
Position Tmp;
if(!BST) printf("未找到要删除的元素");
else if(X < BST->Data)
BST->Left = Delete(X, BST->Left);//我滑
else if(X > BST->Data)
BST->Right = Delete(X, BST->Right);//我滑
else{
//找到要删除的结点
if(BST->LEft && BST->Right){ //左右子树都有
Tmp = FindMin(BST->Right);//找右子树最小结点
BST->Data = Tmp->Data;//替换删除结点的值
//斩草除根,把右子树上的替换结点删掉
BST->Right = Delete(BST->Data, BST->Right);
} else{
//被删除结点有一个或无子结点
Tmp = BST;
if(!BST->Left) //有右孩子或无孩子
BST = BST->Right;
else if(!BST->Right) //有左孩子或无孩子
BST = BST->Left;
free(Tmp);
}
}
return BST;
}
8、平衡二叉树
平衡二叉树首先是个搜索树,满足左小右大。
8.1 概念和性质
“平衡因子”(Balance Factor,简称BF):BF(T) = hL-hR。
其中hL和hR分别为T的左、右子树的高度。
平衡二叉树(AVL树)
空树,或者任意结点左右子树高度差的绝对值不超过1,即 |BF(T)|<=1
设nh是高度为h的平衡二叉树的最小结点数 => nh = nh-1 + nh-2 + 1
n0 = 1; n1 = 2; …以此类推
或者根据斐波那契数列推导:1 1 2 3 5 8 13…
为 nh = Fh+2 - 1 , (h>=0)
给定结点数为 n 的AVL树的最大高度为 O(log2n)。
8.2 平衡二叉树的调整
调整应该调整最开始导致不平衡的地方,这样上层的不平衡自然就解决了。
选择解决方式关键是:找出被破坏者和破坏者,然后分析关系是左左,右右,左右还是右左。
8.2.1 RR旋转(右单旋)

如上图所示,本身平衡的树,因为右子树的右子树插入结点,导致不平衡。
不平衡的“发现者”是 A ,“麻烦结点” BR 在发现者右子树的右子树上,所以叫RR插入,需要RR旋转(右单旋)。
此时把B 提高,把A当做B的左孩子,麻烦结点降低,发现者升高,解决了不平衡,然后因为搜索树左小右大,BL比B小,比A大,所以刚好放在A的右边。
8.2.2 LL旋转(左单旋)
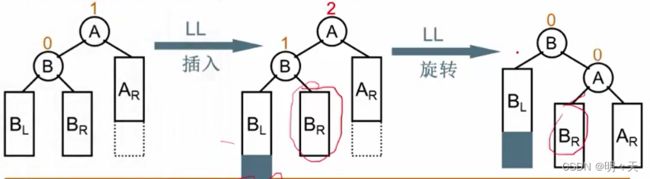
如上图所示,本身平衡的树,因为左子树的左子树插入结点,导致不平衡。
不平衡的“发现者”是 A ,“麻烦结点” BL 在发现者左子树的左子树上,所以叫LL插入,需要LL旋转(左单旋)。
此时把B 提高,把A当做B的右孩子,麻烦结点降低,发现者升高,解决了不平衡,然后因为搜索树左小右大,BR比B大,比A小,所以刚好放在A的左边。
8.2.3 LR旋转

如上图所示,本身平衡的树,因为左子树的右子树插入结点,导致不平衡。
不平衡的“发现者”是 A ,“麻烦结点” C 在发现者左子树的右子树上,所以叫LR插入,需要LR旋转。
此时把ABC变成CBA,B不动,C变最顶上,A变成C的右孩子,C的孩子左边归B,右边归A。
8.2.4 RL旋转
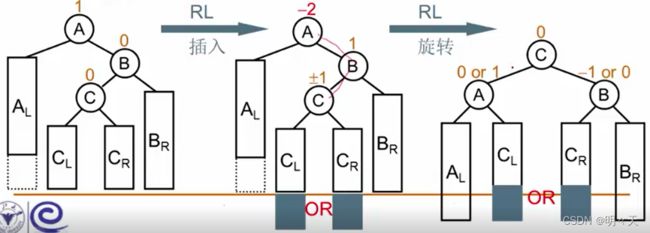
六、堆
1、优先队列
特殊的队列,元素是按照优先权大小排序,不是按照进入队列的先后顺序。
需要新的数据结构,实现快捷对最大或最小值删除操作的结构,也就是堆。
2、堆
2.1 堆的特性
结构性:用数组表示的完全二叉树。
有序性:任一结点的关键字是其自述所有结点的最大值(或最小值)。
- 最大堆(MaxHeap),大顶堆;
- 最小堆(MinHeap),小顶堆。
2.2 最大堆的实现
typedef struct HeapStruct* MaxHeap;
struct HeapStruct{
ElementType* Elements; //存储堆元素的数组
int Size; //堆的当前元素个数
int Capacity; //堆的最大容量
};
//最大堆的创建
MaxHeap Create(int MaxSize){
MaxHeap H = malloc(sizeof(struct HeapStruct));
H->Elements = malloc((MaxSize+1) * sizeof(ElementType));
H->Size = 0;
H->Capacity = MaxSize;
H->Elements[0] = MaxData;
//定义哨兵为大于堆中所有可能元素的值,便于以后更快操作
return H;
}
//最大堆的插入
void Insert(MaxHeap H, ElementType item){
int i;
if(IsFull(H)){
printf("最大堆已满");
return;
}
i = ++H->Size; //i指向插入后堆中的最后一个元素的位置
for(; H->Elements[i/2] < item; i/=2)
H->Elements[i] = H->Elements[i/2];
//已知如果结点序号从1开始,那么i结点的父亲结点是i/2
//堆的处理是自下而上的,最开始假设数组末尾值是item
//每次循环都是i结点和父亲作比较,也就是item和父亲值比较
//假设i结点插入的值是item,比父亲大,就往上爬。
//直到所有比i小的都下移,就空出了item应该插入的位置
//为什么不怕越界,因为哨兵啊,o( ̄▽ ̄)d
//当然你要是怕的话,就加一句i>1
H->Elements[i] = item; //将item插入空出来的位置
}
//最大堆删除
ElementType DeleteMax(MaxHeap H){
//堆的最大值是根结点,所以删除根结点
int Parent,Child;
ElementType MaxItem, temp;
if(IsEmpty(H)){
printf("最大堆已空");
return;
}
MaxItem = H->Elements[1]; //取出根结点的最大值
//用最大堆中最后一个元素从根结点开始向上过滤下层结点。
temp = H->Elements[H->Size--];
//跟插入相反,这里假设末尾值是最大值,所以从根结点开始考虑
//自上而下
for(Parent = 1; Parent*2 <= H->Size; Parent = Child){
Child = Parent * 2;
if((Child != H->Size)&&
(H->Elements[Child] < H->Elements[Child+1]))
Child++; //Child指向左右子结点的较大者
//因为这是最大堆,只要和大的比较
if(temp >= H->Elements[Child]) break;
else //大的排上面
H->Elements[Parent] = H->Elements[Child];
}
H->Elements[Parent] = temp;
return MaxItem;
}
2.3 最大堆的建立
将N个元素按最大堆的要求存放在一维数组里。
方法一:通过插入操作,将N个元素插入初始为空的堆中。时间复杂度是O(NlogN)。
方法二:线性时间复杂度下建立最大堆。
- 将N个元素按输入顺序存入,先满足完全二叉树的结构特性;
- 调整各个结点位置,来满足最大堆的有序特性。
void PercDown( MaxHeap H, int p )
{
/* 下滤:将H中以H->Data[p]为根的子堆调整为最大堆 */
int Parent, Child;
ElementType X;
X = H->Data[p]; /* 取出根结点存放的值 */
for( Parent=p; Parent*2<=H->Size; Parent=Child ) {
Child = Parent * 2;
if( (Child!=H->Size) && (H->Data[Child]<H->Data[Child+1]) )
Child++; /* Child指向左右子结点的较大者 */
if( X >= H->Data[Child] ) break; /* 找到了合适位置 */
else /* 下滤X */
H->Data[Parent] = H->Data[Child];
}
H->Data[Parent] = X;
}
void BuildHeap( MaxHeap H )
{
int i;
//只要保证堆的每一个小堆,满足最大堆性质。
//自下而上,自然就得到整体的最大堆。
for( i = H->Size/2; i>0; i-- )
PercDown( H, i );
}
3、哈夫曼树与哈夫曼编码
3.1 哈夫曼树
哈夫曼树的理念降低加权路径和。
typedef struct TreeNode* HuffmanTree;
struct TreeNode{
int weight;
HuffmanTree Left, Right;
};
HuffmanTree Huffman(MinHeap H){
int i; HuffmanTree T;
BuildMinHeap(H); //将堆按权值大小调整成最小堆
for(i = 1; i < H->Size; i++){ //需要size-1次合并
T = malloc(sizeof(struct TreeNode));//建立新的结点
//选两个最小的结点拼成一个哈夫曼
T->Left = DeleteMin(H);
T->Right = DeleteMin(H);
T->Weight = T->Left->Weight + T->Right->Weight;
Insert(H,T); //将新结点插入最小堆
}
T = DeleteMin(H); //堆顶的元素就是最终的哈夫曼树
return T;
}
哈夫曼树的特点:
- 没有度为1的结点;
- n 个叶子结点的哈夫曼树共有2n-1个结点;
- 哈夫曼树的任意非叶结点的左右子树交换后仍是哈夫曼树。
- 同一份权值,可能有多颗哈夫曼树,但是加权路径和是一样的。
3.2 哈夫曼编码
利用哈夫曼树实现,编码左0右1,符合前缀码,实现不等长编码,从而节省空间。
4、集合
把集合想象成树结构。
4.1 并查集
可以合并集合;可以查看某元素属于什么集合。
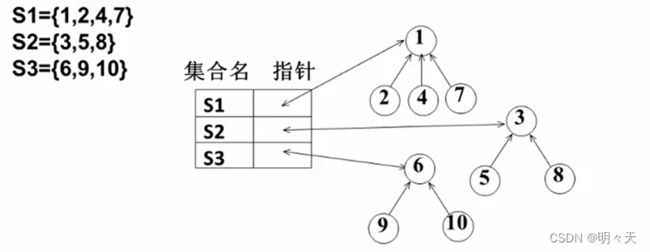
双亲表示法:孩子指向双亲。
采用数组存储:
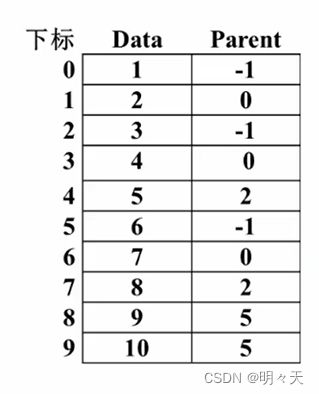
Data存数据,Parent存父亲结点在数组中的下标,父亲结点的Parent为-1。
typedef struct{
ElementType Data;
int Parent;
}SetType;
//查找某个元素所在的集合
int Find(SetType S[], ElementType X){
int i;
for(i = 0; i < MaxSize && S[i].Data != X; i++);
//查找X
if(i >= MaxSize) return -1; //未找到X,返回-1
for( ; S[i].Parent >=0; i = S[i].Parent);
//顺着X,向上爬,找到最终的集合根
return i; //返回树根结点在数组中下标
}
//集合的合并
void Union(SetType S[], ElementType X1, ElementType X2){
int Root1, Root2;
Root1 = Find(S, X1);
Root2 = Find(S, X2);
if(Root1 != Root2)
S[Root2].Parent = Root1;
//合并的意思,就是强迫其中一位认父,o( ̄▽ ̄)d
}
更简化版集合,集合的下标是数据,集合的内容是集合根结点的下标。
按秩归并和路径压缩,加倍快乐!!!!!
typedef int ElementType; //默认元素用非负整数表示
typedef int SetName; //默认用根结点的下标作为集合名称
typedef ElementType SetType[MaxSize];//集合
SetName Find(SetType S, ElementType X){
if(S[X] < 0) //找到集合的根
return X;
else
return S[X] = Find(S, S[X]);
//Find函数:找到根结点下标,并返回
//Find函数的效果,会导致,查找路径上的集合元素的父亲直接变成根结点
//完成了路径压缩,而不是每次都从最底下往上找
//最后才是返回根结点
//传说中的第一次没啥区别,第2次开始超级快。
}
//按秩归并
//集合树型结构,如果只是简单的合并,会导致树的高度变高,查找路径变得很长
//但如果通过按秩归并,来降低树的高度。
//增强合并,加强查找效率
void Union(SetType S, SetName Root1, SetName Root2){
//默认Root1和Root2是不同集合的根结点
//实际需要判断两个根结点的大小,小的集合并到大的集合,
//集合的根结点保存的是负数,数值代表集合元素的个数。
if ( S[Root2] < S[Root1] ) {//集合2大
S[Root2] += S[Root1];
S[Root1] = Root2;
}
else { //集合1大
S[Root1] += S[Root2];
S[Root2] = Root1;
}
}