调用本地大模型实现聊天机器人ChatBot
AWS Instance本地部署大模型
AWS上申请带GPU的instance,例如g4dn系列,申请instance后安装CUDA的driver,driver安装完成后,就可以在带gpu的instance上部署开源的大模型了。如果想了解在aws上部署本地模型细节,可以阅读我的这两篇博客。
AWS instance上本地部署大模型
Fastchat本地部署大模型
这里为了能在ChatBot上调用本地模型,使用FastChat进行部署,且启动了大模型的API接口。安装driver后,启动api接口和启动模型的命令如下所示。ssh连接到申请的instance后,执行下面的命令,即可部署开源的vicuan-7b-v1.5模型,当然,你也可以部署其他开源模型,只需要修改--model-path的值即可。
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
#下载FastChat代码
pip3 install --upgrade pip # enable PEP 660 support
pip3 install -e ".[model_worker,webui]"
#安装依赖
python3 -m fastchat.serve.controller
#启动fastchat的controller
python3 -m fastchat.serve.model_worker --model-names "gpt-3.5-turbo,text-davinci-003,text-embedding-ada-002,vicuan-7b-v1.5" --model-path lmsys/vicuna-7b-v1.5
#启动模型,设置model-names等于是给启动的模型设置的别名
python3 -m fastchat.serve.openai_api_server --host localhost --port 8000
#启动API服务对于上面的命令,需要注意两点。
第一点:
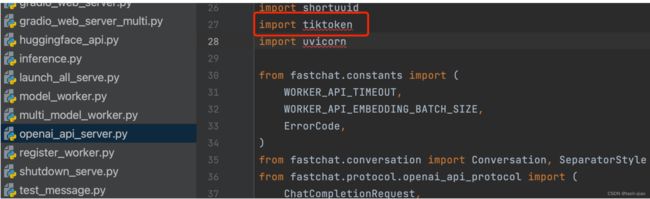
通过--model-names命令,等于是对启动的模型设置了别名,上面的命令中设置了多个别名,后面使用任意一个别名,本质上调用的还是vicuan-7b-v1.5模型。那么为什么要将vicuan-7b-v1.5模型设置成和OpenAI提供的模型相同的名称呢?因为FastChat在封装Embedding接口的时候,调用了OpenAI开源的ticktoken库,如果在写应用的时候,需要对内容进行向量化,即调用Embedding接口,模型名称如果不是OpenAI提供的模型名称,就会报错,具体错误如下所示:

查看FastChat的源代码,会发现在代码中调用了OpenAI的tiktoken库。所以,如果是调用Embedding接口,即将信息转换成向量的接口时,传入的模型名称必须是OpenAI提供的模型名词。如果是与机器对话的接口,例如chat/completions接口,此时,可以使用任何自定义的模型名称。
第二点:
在启动api服务时,模型的host是localhost,如果是在aws的instance上启动,host需要设置为0.0.0.0,这样才能从外网成功访问到启动的API服务。上面的命令中API启动在8000端口上,为了从外面的浏览器上成功访问到,需要在aws instance的security group中设置inbound规则,增加开放8000端口的规则。具体如下图所示:启动API时,监听的哪个端口,就开放哪个端口。如果为了更加安全,可以把Source设置为自己电脑所在的公网IP地址,这样更加安全可控。

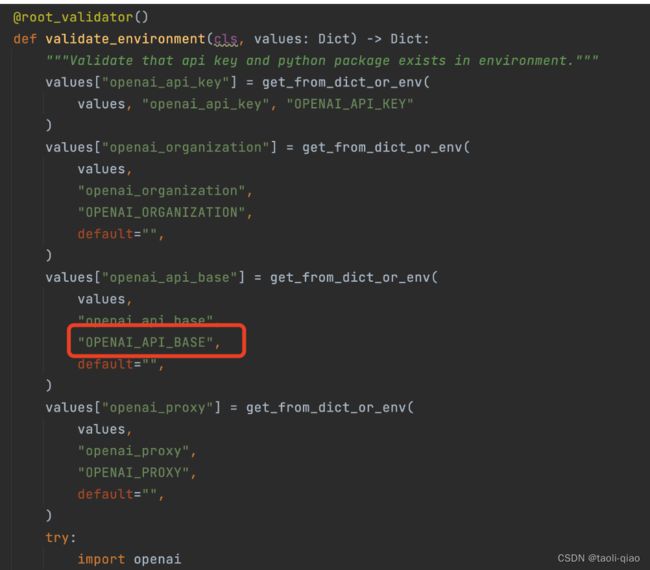
设置环境变量OPEN_API_BASE
上面的配置和部署成功后,还需要在外面电脑的环境变量中设置API接口地址,因为编写Chatbot时使用了Lanchain,我们需要修改默认的OpenAI api的base url。查看Langchain的源代码会看到有这些环境变量的检查,这里设置OPENAI_API_BASE的值为启动的本地模型的API的base url。即“http://public ip:8000/v1” 这个值,public ip是aws instance的public ip。
使用Lanchain编写Chatbot
下面是使用Lanchain编写Chatbot的代码,代码中可以通过参数动态传入模型名称,这样就可以灵活控制具体选用哪个模型了。
def chat_with_model(model_name, question, history):
llm = ChatOpenAI(model=model_name, temperature=0.5)
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# The `variable_name` here is what must align with memory
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}"),
]
)
# Notice that we `return_messages=True` to fit into the MessagesPlaceholder
# Notice that `"chat_history"` aligns with the MessagesPlaceholder name
memory = ConversationBufferMemory(
memory_key="chat_history", return_messages=True)
conversation = LLMChain(llm=llm, prompt=prompt,
verbose=True, memory=memory)
# Notice that we just pass in the `question` variables - `chat_history` gets populated by memory
bot_message = conversation({"question": question})['text']
history.append((question, bot_message))
return '', history前端是使用gradio框架编写,具体代码如下图所示:
with gr.Blocks() as simple_chat:
with gr.Row():
chat_model_radio = gr.Radio(
["gpt-3.5-turbo", "vicuna-7b-v1.5"], label="Chat Model")
chatbot = gr.Chatbot()
input_textbox = gr.Textbox()
clear_button = gr.ClearButton([chatbot, input_textbox])
input_textbox.submit(chat_with_model, inputs=[chat_model_radio,
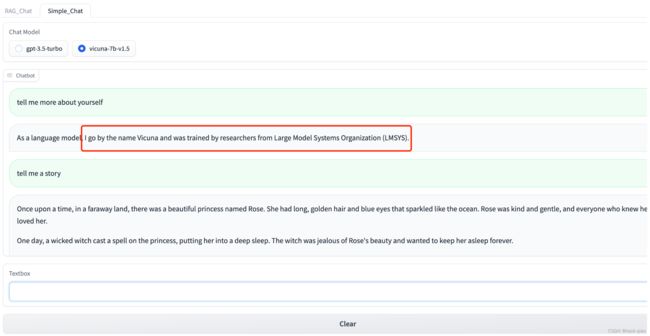
input_textbox, chatbot], outputs=[input_textbox, chatbot])启动应用,选择模型名称,就可以与本地部署的大模型开始对话了。可以看到,当问她是谁时,大模型返回了Vicuna模型,说明调用到的确实是本地部署的大模型。
基于本地模型做知识问答
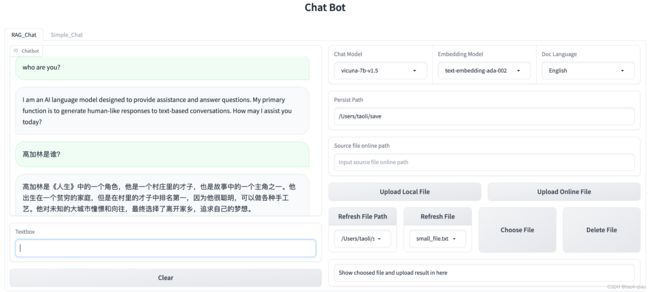
除了调用本地模型做chatbot外,还可以调用本地模型做基于知识的问答系统,做知识问答系统的时候需要将文档进行切割和向量化,此时输入的模型名称不能是vicuna-7b-v1.5,需要用其他模型别名,例如“text-embedding-ada-002”或者是“gpt-3.5-turbo”等。否则,向量化的时候会报错。如果对如何实现知识问答系统不清楚,可以查看我这篇博客。
利用Lanchain实现RAG
实现后的效果图如下所示:这里导入的知识库是路遥的小说<人生>这本书,向量化后,询问大模型高加林是谁,能比较准确的进行回答。这里Chat的模型选择的是vicuna-7b-v1.5,embedding的模型选择的是text-embedding-ada-002,实际模型本质都是vicuna-7b-v1.5,text-embedding-ada-002只是别名而已。因为已经在环境变量中修改了OPENAI_API_BASE的地址,所以,不可能会调用到真正的OPENAI的任何接口了。
在向量化文本过程中,因为是单个GPU的instance部署的大模型,可能会出现内存不够的错误,具体错误信息如下图所示:

FastChat对于这类错误,官网给出的解决办法是设置Batch-Size的大小为1 “export FASTCHAT_WORKER_API_EMBEDDING_BATCH_SIZE=1”,实际设置后,还是会报内存不够的问题,此时,可以将导入的文档内容减小一些,就不会出错了。这个本质是硬件不够的问题。大家知道如何避免即可。
以上就是对如何调用本地大模型实现ChatBot的介绍。