代码随想录算法训练营第三天|203.移除链表元素,707.设计链表,206.反转链表
第三天和第四天都是补卡的,这几天忙着复习周o(╥﹏╥)o,下面开始吧!
203.移除链表元素
题目链接:203.移除链表元素
一开始读错题目,以为是自带一个虚拟头结点的链表(平时学校学的就是“带头结点的链表”表示是有“虚拟头结点”的链表),然后平时学数据结构,用的是浙大版的数据结构,默认语言是c,还没熟悉Java定义链表,一开始还有些陌生,这里复制一下leetcode里默认创建结点的方式吧(说实话,还没用Java实现过基本数据结构呢)。
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
下面开始解题吧:
1.不添加虚拟节点and pre Node方式(还没看题解想到的,借随想录里名字用一用了)
不添加虚拟节点并且还只用一个p指针,那关键地方就在于:
(1). 对第一个节点进行“优化”,使得头结点一定不是需要删除的结点
(2). 构造一个p作为“探索”指针,只要p的下一个结点是需要删除的,那么就一直更新p的下一个结点,只有当p的下一个结点不是需要删除的之后,才移动p
上代码!
class Solution {
public ListNode removeElements(ListNode head, int val) {
// 1.不添加虚拟节点and pre Node方式
while(head != null && head.val == val){// “优化头结点”的操作
head = head.next;
}
if(head == null){
return null;
}
// 上面是排除头结点是空,或者头结点就是需要删除的结点的情况,这样才能保证下面的p结点合理并且好操作
ListNode p = head; // p作为head的前驱
while(p != null && p.next != null){
if(p.next.val == val){
p.next = p.next.next;
continue; // 这里continue的意思是,后面可能还有连续的等于val的结点,所以,不移动p,接着让p停留在原来的位置,持续更新p的next,直到p.next.val != val 为止
}
p = p.next;
}
return head;
}
}2.添加虚拟节点的方式
很简单啦,平时学的也是这种方式,这个方式就可以不用做上一个方法“优化头结点”的操作,所有结点一视同仁,操作起来舒舒服服~自由自在(*^▽^*)
class Solution {
public ListNode removeElements(ListNode head, int val) {
// 2.添加虚拟节点的方式
ListNode newHead = new ListNode();
newHead.next = head;
ListNode p = newHead; // p作为一个探索指针
while(p.next != null){
if(p.next.val == val){ // 不断探寻p的下一个结点是否是需要删除的
p.next = p.next.next; // 是,则更新p的下一个结点
continue; // 重新循环,重新判断 “p的下一个结点是否是需要删除的”
}
p = p.next;
}
return newHead.next; // 由于是构造的虚拟节点,它下一个结点的位置才是原来head的位置
}
}707.设计链表
题目链接:707.设计链表
之前都是用c实现的数据结构,第一次用Java实现链表,很是不熟练。其实也有类似的地方,把Java里的“类”想象成C语言里的结构体会好理解一点。
遇到的问题:
1.不清楚怎么在Java中创建链表(带虚拟头节点的链表)
2.混淆了C语言的函数与Java类中的方法
3.不会结合下标index来移动p指针(平时就是单纯移动p指针,很少做过要移动到某个下标的情况)
4.对“无效下标”含义理解不准确
1.如何在Java中创建链表(带虚拟头节点的链表)
只知道C语言里是先创建一个结构体,然后把结构体想象成类里面的构造函数了,一开始在构造函数里定义节点,真是够蠢的┓(;´_`)┏
这样理解:把链表的每一个结点定义成一个类,那么,显然,数据域的值是一个属性,还有指针域的指向也是一个属性,那么就应该先定义下面这个ListNode类,来表示链表节点。
/**
* 首先定义一个节点类,封装节点各属性(类似于C语言先写一个节点结构体)
* @author remember_me.
*/
class ListNode{
int val;
ListNode next;
// 无参/含参构造:
public ListNode() {}
public ListNode(int val) {
this.val = val;
}
}还有大小(size)、虚拟头节点(head)这两个属性,则放在MyLinkedList这个类里,因为在这个类里会频繁使用。于是,题目中第一个方法的代码就应该这样写:
int size; // 链表长度
ListNode head; // 定义一个虚拟头节点指针
public MyLinkedList() {
size = 0;
head = new ListNode(0); // 只有new了一个ListNode,
// 才为head开辟了空间,head才成为了虚拟头节点
}然后,一旦外界new了这个类(MyLinkedList myLinkedList = new MyLinkedList();)之后,在这个类里面就可以用head这个节点了,可以想象成是下面这个样子:

2.C语言中的函数与Java中类的方法的区别
C语言中,在函数之外的变量,大多数时候,都是靠参数来转递的,如:
int myLinkedListGet(MyLinkedList* obj, int index) {
MyLinkedList *cur = obj->next;
...
}(要访问obj的next,是通过传入的obj参数来访问的)而Java中,在同一个类里,是可以直接使用方法外的变量的:
public int get(int index) {
if(index < 0 || index >= size) { return -1; }
ListNode p = head;
...
}(head是同一个类中的属性,可以直接使用,并且head在这个类中一直存在)反正一开始自己写的时候,还带着C语言的思想,忘了Java是“面相对象的编程语言”,所以对这题实现链表的各个方法特别懵,一直把外界创建的这个myLinkedList在类中用this代替,总之就是云里雾里。
3.*!* 我愿称之为本题精髓 *!*(结合下标index来移动p指针)
本题大量要完成“插入到链表中下标为 index 的节点之前”的操作,对于平时没怎么做过跟下标的我来说,着实有点懵逼,怎么把下标跟p结点所在位置结合起来?如何理解“找到插入点的前驱”?其实本题关键有两种情况:
1.p在index前(用于插入、删除)
2.p在index这个位置处(用于返回index处的val)
(1)p在index前(用于插入、删除)
我自己画了两种图,应该比较好理解(p指针是卡哥代码里的pred)

(2)p在index这个位置处(用于返回index处的val)
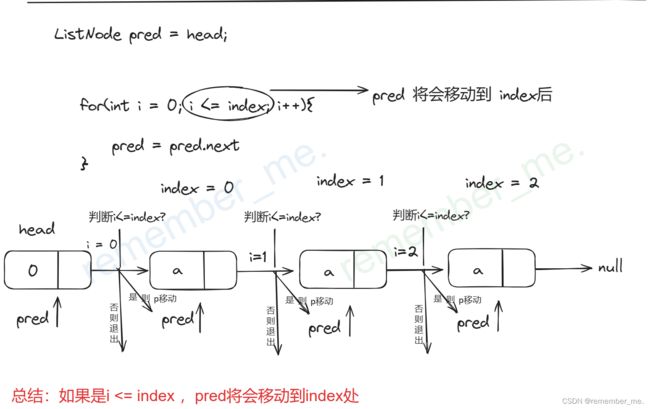
4.对“无效下标”含义理解不准确
在题目中,int get(int index)、void addAtIndex(int index, int val)、void deleteAtIndex(int index)都存在对下标的合理性的判断问题,一开始也是懵里懵懂,啥时候无效啥时候有效,排除了无效之后又在后面的代码里加逻辑判断,逻辑向当地混乱⊙(・◇・)?
其实,每一个方法的“无效下标”的判断,在一开始就可以解决,并且解决了之后,在下面的代码里就不用担心下标异常的问题了,比如,在get方法中,index<0,显然是一个无效值,然后大于链表长度的边界值又是什么呢?是index>size的时候?还是index>=size的时候?这个就得根据这道题的特点来确定了,根据题目实例中的:
...
myLinkedList.addAtIndex(1, 2); // 链表变为 1->2->3
myLinkedList.get(1); // 返回 2
...
可以看出,链表下标是从0开始的,这就类似数组了:size代表链表大小,那么size-1才是链表最后一个元素的索引,所以,当index>=size时,就已经是“无效下标”了。
同样道理,删除的时候,显然index不能小于0或者大于等于size。
而addAtIndex方法中,题目中给了提示:
“如果
index等于链表的长度,那么该节点会被追加到链表的末尾。如果index比长度更大,该节点将 不会插入 到链表中。”
一个显然的“无效下标”是index超出了链表长度,即:index>size。这个时候,addAtIndex什么也不干,直接return。还有,“如果 index 等于链表的长度,那么该节点会被追加到链表的末尾。”以及代码随想录里额外加的“如果index小于0,则在头部插入节点。”又该怎么操作?
这就得想到addAtIndex的定义“ 将一个值为 val 的节点插入到链表中下标为 index 的节点之前”。如果是index小于0,即插入在头节点处,那就是下标为0(第一个节点)之前的意思咯,所以,当index小于0的时候,直接令index=0就好了。那“如果 index 等于链表的长度,那么该节点会被追加到链表的末尾”也是一样的道理,当输入的index=size,即需要在index=size的前一个结点插入,其实是不需要做单独处理的,因为每次插入的方法,我们都是通过找到index前一个结点,然后再插入的,代码如下:
public void addAtIndex(int index, int val) {
// (核心方法 )用虚拟头节点,其实就很好理解了
if(index > size) {// 首先排除无效下标情况
return;
}
if(index < 0) {// 如果index小于0,下标更新成插入在第一个的情况
index = 0;
}
ListNode p = head;
// 因为有虚拟头节点,所以所有链表节点都一视同仁的处理即可
for(int i = 0; i < index; i++) {// for循环结束之后,p将会移动到index下标之前,即所谓的找到index的前驱
p = p.next;
}
ListNode newNode = new ListNode(val);
newNode.next = p.next;
p.next = newNode; // 这两个的顺序很重要!!画个图就能理解了,
// 应该先让newNode连接到p所指下一个,不然p所指下一个节点会丢失
size++; // 别忘了链表大小加1!!!!!
}以上便是这道题困扰我的四个问题(还有一个小细节,就是插入和删除的最后别忘了size++/size--),解决了这些,链表其实还是很简单的٩(๑>◡<๑)۶
最终代码(每个方法都加了注释,便于理解):
class MyLinkedList {
/**
* 首先定义一个节点类,封装节点各属性(类似于C语言先写一个节点结构体)
* @author remember_me.
*/
class ListNode{
int val;
ListNode next;
// 无参/含参构造:
public ListNode() {}
public ListNode(int val) {
this.val = val;
}
}
// 利用虚拟头结点法
// 下面这两个,相当于我们自己构建的这个MyLinkedList类的属性,表示有大小,有虚拟头节点
int size; // 链表长度
ListNode head; // 定义一个虚拟头节点指针
public MyLinkedList() {
size = 0;
head = new ListNode(0); // 只有new了一个ListNode,才为head开辟了空间,head才成为了虚拟头节点
}
public int get(int index) {
if(index < 0 || index >= size) {// 显然,下标无效就是index 小于0 或者 大于等于(因为链表下标从0开始)链表长度
return -1;
}
ListNode p = head;
for(int i = 0; i <= index; i++) {// i <= index p将会移动到index这个下标的节点位置
p = p.next;
}
// 退出循环,p已经指向了index位置处,所以直接返回p的值即可
return p.val;
}
public void addAtHead(int val) {
// 同一个类里,可以互相调用方法,显然,插在头处,就是插在下标为0的前面
this.addAtIndex(0, val);
}
public void addAtTail(int val) {
// 同addAtHead方法一样,根据addAtIndex的定义,是插入在size前面
// 拿size=3举例,插入在index=3之前,不就是插在index=2之后吗,
// 而index=2,就是size=3的情况下,链表的最后一个下标啊
this.addAtIndex(size, val);
}
public void addAtIndex(int index, int val) {
// (核心方法 )用虚拟头节点,其实就很好理解了
if(index > size) {// 首先排除无效下标情况
return;
}
if(index < 0) {// 如果index小于0,下标更新成插入在第一个的情况
index = 0;
}
ListNode p = head;
// 因为有虚拟头节点,所以所有链表节点都一视同仁的处理即可
for(int i = 0; i < index; i++) {// for循环结束之后,p将会移动到index下标之前,即所谓的找到index的前驱
p = p.next;
}
ListNode newNode = new ListNode(val);
newNode.next = p.next;
p.next = newNode; // 这两个的顺序很重要!!画个图就能理解了,
// 应该先让newNode连接到p所指下一个,不然p所指下一个节点会丢失
size++; // 别忘了链表大小加1!!!!!
}
public void deleteAtIndex(int index) {
if(index < 0 || index >= size) {// 首先排除无效下标情况
return;
}
ListNode p = head;
// 因为有虚拟头节点,所以所有链表节点都一视同仁的处理即可
for(int i = 0; i < index; i++) {// for循环结束之后,p将会移动到index下标之前,即所谓的找到index的前驱
p = p.next;
}
p.next = p.next.next;
size--; // 别忘了大小减1!!!!!!
}
}
/**
* Your MyLinkedList object will be instantiated and called as such:
* MyLinkedList obj = new MyLinkedList();
* int param_1 = obj.get(index);
* obj.addAtHead(val);
* obj.addAtTail(val);
* obj.addAtIndex(index,val);
* obj.deleteAtIndex(index);
*/206.反转链表
题目链接:206.反转链表
重点在写上一题了,反转指针我用了三种方法,哈哈哈,第一种直接用头插法创建一个新的链表(有点投机取巧了)后面两个是看了随想录之后写的,emmm,第二种从后往前的递归属实是看不懂了,算了算了,以后再尝试看吧,思路放在代码注释里了( 后面有点懒写了 _(:3」∠❀)_
1.头插法创建一个新的链表
class Solution {
public ListNode reverseList(ListNode head) {
// 1.类似于“头插法”,根据旧的链表,利用头插法重新创建一个链表
if(head == null){
return null;
}
ListNode newHead = new ListNode(0); // 二话不说,先创建一个虚拟头节点
ListNode p = head;
ListNode q;
while(p != null){
q = new ListNode(p.val);
q.next = newHead.next;
newHead.next = q;
p = p.next;
}
return newHead.next;
}
}2.双指针法
class Solution {
public ListNode reverseList(ListNode head) {
// 2.双指针法
ListNode right = head; // 右边的指针,初始化指向head
ListNode left = null; // 左边的指针,初始化为空
ListNode temp = null;
while(right != null){ // 当右边的指针指向空(也就是走到头的时候,说明反转就应该结束了)
temp = right.next; // 翻转前,先保存right的后一个节点,以保证下次移动时能够找得到
right.next = left;
// 翻转一次完毕,right和left整体移动
left = right; // 应该先让左边的先移动,右边的再移动,不然left将移动出错
right = temp;
}
return left;
}
}3.递归法(从前往后)
class Solution {
// 3.递归法(从前往后,结合双指针的思想)
public ListNode reverse(ListNode left,ListNode right){
if(right == null) { // 对应双指针法中,循环结束返回left
return left;
}
ListNode temp = right.next;
right.next = left;
// 对应双指针法中,翻转一次链表
return reverse(right,temp); // 对应双指针法中,整体移动left和right
}
public ListNode reverseList(ListNode head) {
return reverse(null,head);
}
}