一篇文章理解 “进程间通信“
本文主要是关于,命名管道,匿名管道,system V 共享内存的理解!
进程间通信的目的
- 数据传输:进程间可能需要相互发送数据
- 资源共享:多个进程间需要共享资源
- 事件通知:一个进程需要向另一个或一组进程发送消息,通知它(它们)发生了某种事件(如进程终止时要通知父进程)
- 进程控制:有些场景下需要一个进程去控制另外一个进程
进程间通信的分类
管道
-
匿名管道pipe
-
命名管道
System V IPC
- system V 消息队列
- system V 共享内存
- system V 信号量
POSIX IPC
- 消息队列
- 共享内存
- 信号量
- 互斥量
- 条件变量
- 互斥锁
管道
概念:把一个进程连接到另一个进程的一个数据流叫管道。
管道的读写规则
-
当没有数据可读时:
- 如果使用了非阻塞模式(O_NONBLOCK enable),read 调用会立即返回-1,并将 errno 设置为 EAGAIN。这表示当前没有数据可读,但是程序不会被阻塞,可以继续执行其他任务。
- 如果未使用非阻塞模式(O_NONBLOCK disable),read 调用会阻塞,即进程暂停执行,直到管道中有数据可读为止。
-
当管道满的时候:
- 如果使用了非阻塞模式(O_NONBLOCK enable),write 调用会立即返回-1,并将 errno 设置为 EAGAIN。这表示管道已满,无法继续写入数据,但是程序不会被阻塞,可以继续执行其他任务。
- 如果未使用非阻塞模式(O_NONBLOCK disable),write 调用会阻塞,直到有其他进程读走数据,腾出空间,才能继续写入数据。
- 如果所有管道写端对应的文件描述符被关闭,则read返回0
- 如果所有管道读端对应的文件描述符被关闭,则write操作会产生信号SIGPIPE,进而可能导致write进程退出
- 当要写入的数据量不大于PIPE_BUF时,linux将保证写入的原子性。
- 当要写入的数据量大于PIPE_BUF时,linux将不再保证写入的原子性。
管道的特点
-
单向性:管道是单向的,数据只能从一个进程流向另一个进程,不能反向流动。因此,在通信双方之间需要建立两个管道,一个用于从进程A向进程B传输数据,另一个用于从进程B向进程A传输数据。
-
半双工性:管道是半双工的,即同一时刻只能有一个进程进行读操作,另一个进程进行写操作。要实现全双工通信,需要使用两个管道,分别用于两个方向的通信。
-
进程间通信:管道通常用于实现相关进程之间的通信,例如父子进程之间的通信。一个进程可以将数据写入管道,另一个进程可以从同一个管道读取数据。
-
基于文件描述符的访问:管道在操作上类似于文件,可以使用文件描述符来操作它们。一个进程创建管道后,会获得两个文件描述符,一个用于读取数据,另一个用于写入数据。这两个文件描述符可以被不同的进程使用。
-
阻塞式操作:当管道已满时,写入进程会被阻塞,直到有足够的空间可以写入数据。同样,当管道为空时,读取进程会被阻塞,直到有数据可供读取。可以使用非阻塞模式来改变此行为。
-
容量限制:管道的容量是有限的,通常在4KB至64KB之间。当管道达到容量限制时,进程尝试写入数据将会被阻塞。
-
临时性:管道通常是临时的,即在进程结束后会自动销毁。但也可以使用命名管道(Named Pipe)来创建具有持久性的管道,以便不相关的进程之间进行通信。
匿名管道
#include
int pipe(int pipefd[2]); 利用pip系统调用创建一个匿名管道
参数:
pipefd:文件描述符组,其中pipefd[0] 表示读取端,pipefd[1] 表示写端
返回值:成功返回0,失败则错误码被返回
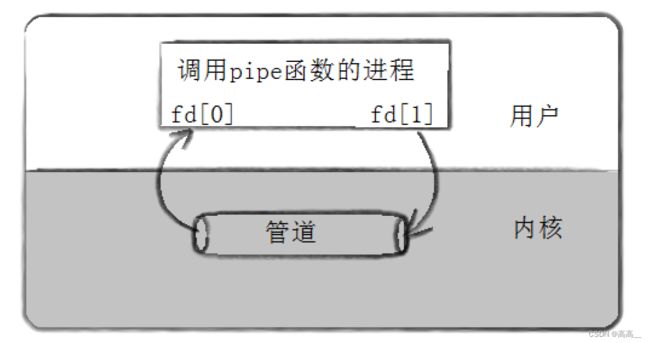
以下代码 实现从键盘读取数据,写入管道 ,然后读取管道数据,写到屏幕
#include
#include
#include
#include
int main(void)
{
int fds[2];
char buf[100];
int len;
if (pipe(fds) == -1)
perror("make pipe"), exit(1);
// 从键盘读取数据读到buf中
while (fgets(buf, 100, stdin))
{
len = strlen(buf);
// 将buf中的数据写入管道中
if (write(fds[1], buf, len) != len)
{
perror("write to pipe");
break;
}
//重置buf
memset(buf, 0x00, sizeof(buf));
// 从管道中读取数据
if ((len = read(fds[0], buf, 100)) == -1)
{
perror("read from pipe");
break;
}
// 将从管道中读取的数据写到显示器上
if (write(1, buf, len) != len)
{
perror("write to stdout");
break;
}
}
} 使用fork来模拟共享管道原理
使用fork创建子进程后,子进程会继承父进程的部分数据结构,其中就包含父进程的file*数组。

代码实现
#include
#include
#include
#include
#include
int main(int argc, char *argv[])
{
int pipefd[2];
if (pipe(pipefd) == -1)
perror("pipe error");
pid_t pid;
pid = fork();
if (pid == -1)
perror("fork error");
if (pid == 0)
{
close(pipefd[0]);
write(pipefd[1], "hello", 5);
close(pipefd[1]);
exit(1);
}
close(pipefd[1]);
char buf[10] = {0};
read(pipefd[0], buf, 10);
printf("buf=%s\n", buf);
return 0;
} 命名管道
管道应用的一个限制就是只能在具有共同祖先(具有亲缘关系)的进程间通信。
如果我们想在不相关的进程之间交换数据,可以使用FIFO文件来做这项工作,它经常被称为命名管道。
命名管道是一种特殊类型的文件
//创建命名管道头文件及函数
#include
#include
int mkfifo(const char *pathname, mode_t mode);
//命名管道的创建
int main(int argc, char *argv[])
{
mkfifo("p2", 0644);
return 0;
} 命名管道和匿名管道的区别
- 匿名管道由pipe函数创建并打开。
- 命名管道由mkfifo函数创建,打开用open
- FIFO(命名管道)与pipe(匿名管道)之间唯一的区别在它们创建与打开的方式不同,一但这些工作完成之后,它们具有相同的语义。
system V 共享内存

System V 共享内存允许多个进程共享同一块内存的主要原因是它们将同一块内存区域映射到它们各自的地址空间中。这意味着所有进程都可以访问并操作相同的内存区域,因此能够看到相同的数据。
具体来说,System V 共享内存允许多个进程通过将共享内存段映射到它们的地址空间中来共享同一块内存。这样,每个进程都可以像访问自己的内存一样访问共享内存段中的数据。进程可以使用 shmat() 系统调用将共享内存段映射到自己的地址空间中,并使用返回的指针来访问共享内存中的数据
共享内存作为最快的IPC形式,一旦这样的内存映射到共享它的进程的地址空间,进程不再通过执行进入内核的系统调用来传递彼此的数据。
共享内存有以下特点和使用方式
-
共享内存段:进程可以通过创建共享内存段,在其地址空间中映射一块共享的内存区域。多个进程可以将同一个共享内存段映射到它们各自的地址空间中,从而实现共享数据的访问。
-
高速数据交换:与其他形式的进程间通信相比,共享内存提供了一种高速的数据交换方式,因为它直接操作内存,不涉及复制数据或者内核的中介。
-
互斥访问:由于多个进程可以访问同一个共享内存段,因此需要使用互斥机制(例如信号量或者互斥锁)来确保对共享数据的互斥访问,以避免数据的不一致性和竞争条件。
-
生命周期管理:共享内存段的创建和销毁由系统调用来完成。进程可以使用
shmget函数来创建共享内存段,使用shmat函数将共享内存段映射到自己的地址空间中,以及使用shmctl函数来控制共享内存段的属性和状态。 -
键值:共享内存段通过一个唯一的键值来标识和访问。进程通过指定相同的键值来访问同一个共享内存段。
shmget函数
功能:用来创建共享内存
原型
int shmget(key_t key, size_t size, int shmflg);
参数
key: 这个共享内存段名字
size: 共享内存大小
shmflg: 由九个权限标志构成,它们的用法和创建文件时使用的mode模式标志是一样的
返回值:成功返回一个非负整数,即该共享内存段的标识码;失败返回-1
shmat函数
功能:将共享内存段连接到进程地址空间
原型
void *shmat(int shmid, const void *shmaddr, int shmflg);
参数
shmid: 共享内存标识
shmaddr:指定连接的地址
shmflg:它的两个可能取值是SHM_RND和SHM_RDONLY
返回值:成功返回一个指针,指向共享内存第一个节;失败返回-1
shmdt函数
功能:将共享内存段与当前进程脱离
原型
int shmdt(const void *shmaddr);
参数
shmaddr: 由shmat所返回的指针
返回值:成功返回0;失败返回-1
注意:将共享内存段与当前进程脱离不等于删除共享内存段
shmctl函数
功能:用于控制共享内存
原型
int shmctl(int shmid, int cmd, struct shmid_ds *buf);
参数
shmid:由shmget返回的共享内存标识码
cmd:将要采取的动作(有三个可取值)
buf:指向一个保存着共享内存的模式状态和访问权限的数据结构
返回值:成功返回0;失败返回-1