政安晨:政安晨:机器学习快速入门(三){pandas与scikit-learn} {模型验证及欠拟合与过拟合}
这一篇中,咱们使用Pandas与Scikit-liarn工具进行一下模型验证,之后再顺势了解一些过拟合与欠拟合,这是您逐渐深入机器学习的开始!

模型验证
评估您的模型性能,以便测试和比较其他选择。
在上一篇中,您已经建立了一个模型。但它有多好呢?
在本篇中,你将学会使用模型验证来衡量模型的质量。衡量模型质量是不断改进模型的关键。
什么是模型验证
还是得先讲一下概念:
模型验证(Model Validation)是机器学习中的一个重要步骤,用于评估和验证训练好的机器学习模型的性能和准确性。
在模型训练完成后,模型验证可以帮助我们确定模型是否具有良好的泛化能力,即应用于新数据时是否能够准确预测。模型验证通常在一个独立的测试数据集上进行,该数据集与训练数据集不重叠。 模型验证的目的是检查模型的预测结果与实际观测值之间的差异,并使用适当的指标来量化模型的性能。
常用的模型验证方法包括:准确率(accuracy)、精确率(precision)、召回率(recall)、F1 值等。这些指标可以帮助评估模型在不同任务和数据集上的表现,并帮助我们选择最合适的模型。 除了使用单一的测试数据集进行模型验证外,还可以使用交叉验证(cross-validation)等技术来更全面地评估模型的性能。交叉验证将数据集划分为多个子集,然后使用其中一部分数据进行验证,其他部分数据进行训练。通过重复这个过程,可以获得多个模型验证结果,并计算其平均值,从而更准确地评估模型的性能。 总之,模型验证是机器学习中必不可少的一环,它可以帮助我们评估和选择最好的模型,并为实际应用提供可靠的预测能力。
你将想评估你构建的几乎每个模型。在大多数(尽管不是所有)应用中,模型质量的相关衡量标准是预测准确度。换句话说,模型的预测结果是否接近实际发生的情况。
很多人在衡量预测准确度时犯了一个巨大的错误。他们使用训练数据进行预测,并将这些预测与训练数据中的目标值进行比较。你将会在接下来看到这种方法的问题以及如何解决它,但我们先来思考一下如何做这个。
你首先需要将模型质量总结为一种可理解的方式。如果你比较了对于1万个房屋的预测值和实际值,你可能会发现好坏参半的预测。浏览1万个预测和实际值的列表是没有意义的。我们需要将其总结为一个单一的度量标准。
有很多用于总结模型质量的度量标准,但我们会从一个叫做均方绝对误差(Mean Absolute Error,也称为MAE)的度量标准开始。让我们逐个解释这个度量标准,从最后一个词开始,误差。
接着上一篇看,每个房屋的预测误差是:
error=actual−predicted所以,如果一所房子的价格是15万元,而你预测它的价格是10万元,那么误差就是5万元。
"使用 MAE 指标时,我们取每个误差的绝对值。这将每个误差转换为正数。然后我们取这些绝对误差的平均值。这是我们衡量模型质量的标准。用简单的词来说,可以称之为:
平均而言,我们的预测误差大约为X。
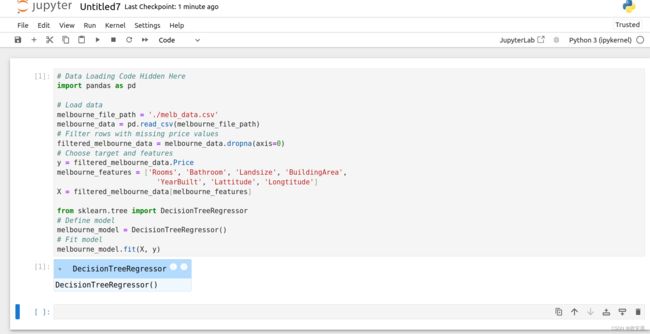
要计算MAE,我们首先需要一个模型。该模型在下面一个隐藏的单元格中构建,您可以通过点击代码按钮来查看。
# Data Loading Code Hidden Here
import pandas as pd
# Load data
melbourne_file_path = './melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# Filter rows with missing price values
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# Choose target and features
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.tree import DecisionTreeRegressor
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(X, y)对这段代码陌生没关系,先大概浏览一下我的上两篇文章:
政安晨:机器学习快速入门(一){基于Python与Pandas} https://blog.csdn.net/snowdenkeke/article/details/136046028政安晨:机器学习快速入门(二){基于Python与Pandas} {建立您的第一个机器学习模型}https://blog.csdn.net/snowdenkeke/article/details/136047590接下来,咱们执行上述代码:
https://blog.csdn.net/snowdenkeke/article/details/136046028政安晨:机器学习快速入门(二){基于Python与Pandas} {建立您的第一个机器学习模型}https://blog.csdn.net/snowdenkeke/article/details/136047590接下来,咱们执行上述代码:
一旦我们有了一个模型,下面就是我们如何计算平均绝对误差的方法:
from sklearn.metrics import mean_absolute_error
predicted_home_prices = melbourne_model.predict(X)
mean_absolute_error(y, predicted_home_prices)
关于“样本内”得分的问题
刚刚计算的度量可以称为“样本内”分数。我们在构建模型和评估模型时使用了同一个房屋样本。以下是为什么这样做不好。
想象一下,在庞大的房地产市场中,门的颜色与房价无关。
然而,在你用来构建模型的数据样本中,所有有绿色门的房屋都非常昂贵。模型的任务是寻找预测房价的模式,所以它会发现这个模式,并且总是预测有绿色门的房屋价格很高。
由于这个模式是从训练数据中得出的,模型在训练数据中看起来是准确的。
但是如果这个模式在模型看到新数据时不成立,那么在实际使用中,模型将非常不准确。
由于模型的实际价值来自于对新数据的预测,我们需要在没有用于构建模型的数据上评估模型的性能。最直接的方法是将一些数据从模型构建过程中排除,然后使用这些数据测试模型在之前未见过的数据上的准确性。这些数据被称为验证数据。
咱们编个码(Coding)
scikit-learn库有一个train_test_split函数,用于将数据分成两部分。我们将使用其中一部分数据作为训练数据来拟合模型,而将另一部分数据作为验证数据来计算平均绝对误差。
以下是代码:
from sklearn.model_selection import train_test_split
# split data into training and validation data, for both features and target
# The split is based on a random number generator. Supplying a numeric value to
# the random_state argument guarantees we get the same split every time we
# run this script.
train_X, val_X, train_y, val_y = train_test_split(X, y, random_state = 0)
# Define model
melbourne_model = DecisionTreeRegressor()
# Fit model
melbourne_model.fit(train_X, train_y)
# get predicted prices on validation data
val_predictions = melbourne_model.predict(val_X)
print(mean_absolute_error(val_y, val_predictions))
哇!看到了吧!
你在样本内的平均绝对误差约为500元。样本外的误差超过250,000元。
这是几乎完全正确的模型与对于大多数实际目的而言不可用的模型之间的区别。作为一个参考点,验证数据中的平均房屋价值为110万元。因此,新数据中的误差约为平均房屋价值的四分之一。
这样看来,这个模型的问题很多,但是有许多方法可以改进这个模型,例如尝试寻找更好的特征或不同的模型类型。
欠拟合与过拟合
优化你的模型以获得更好的性能。
在这一步骤结束时,您将理解欠拟合和过拟合的概念,并能够应用这些思想来使您的模型更准确。
尝试使用不同的模型进行实验
现在你已经有了一种可靠的测量模型准确性的方法,你可以尝试使用其他模型,并看看哪个模型能给出最好的预测结果。但是你有哪些模型选择呢?
你可以在scikit-learn的文档中看到,决策树模型有很多选项(比你很长一段时间内想要或需要的要多)。最重要的选项决定了树的深度。回想一下,在本课程的第一课中我们提到,树的深度是一个衡量在做出预测之前它进行了多少次拆分的标志。这是一棵相对较浅的树。

在实践中,一棵树在顶层(所有房屋)和叶子节点之间拥有10次分割并不罕见。随着树的深入,数据集被切分成含有较少房屋的叶子节点。如果一棵树只有1次分割,它将数据分成两组。如果每个组再次分割,我们将得到4组房屋。再次对每组进行分割,将创建8组。如果我们通过在每个层级添加更多的分割来使组数翻倍,到达第10层时,我们将有210组房屋。这意味着有1024个叶子节点。
当我们将房屋分配给很多叶子节点时,每个叶子节点中的房屋数量也较少。房屋数量较少的叶子节点会对这些房屋的实际价值做出非常接近的预测,但对于新数据的预测可能非常不可靠(因为每个预测仅基于少数房屋)。
这是一种称为过拟合的现象,即模型几乎完美地匹配训练数据,但在验证和其他新数据上表现不佳。另一方面,如果我们将决策树变得非常浅,它将无法将房屋划分为非常明显的群组。
在极端情况下,如果一棵树将房屋分为仅有2个或4个组,每个组仍然有各种各样的房屋。由此得出的预测可能对大多数房屋来说偏离较远,即使在训练数据中也如此(出于同样的原因,在验证中也会表现糟糕)。当模型未能捕捉到数据中的重要差异和模式,以至于即使在训练数据中表现不佳,这就被称为欠拟合。
由于我们关心新数据的准确性,我们根据验证数据来估计,我们希望找到欠拟合和过拟合之间的最佳点。从视觉上看,我们希望在下面图中的(红色)验证曲线的低点。

举个例子
有一些控制树深度的替代方法,其中许多方法允许树中的某些路径比其他路径更深。但是,max_leaf_nodes参数提供了一种非常合理的方法来控制过拟合和欠拟合。我们允许模型生成更多的叶节点,就会从上图中的欠拟合区域移动到过拟合区域。
我们可以使用效用函数来帮助比较不同max_leaf_nodes值的MAE分数。
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)数据已经使用你已经看过并写过的代码加载到train_X、val_X、train_y和val_y中。
接下来,咱们重新实现刚刚模型验证章节实现过的代码,只是稍稍改了点点,大家自己观察:
# Data Loading Code Runs At This Point
import pandas as pd
# Load data
melbourne_file_path = './melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# Filter rows with missing values
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# Choose target and features
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# split data into training and validation data, for both features and target
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)我们可以使用for循环来比较使用不同max_leaf_nodes值构建的模型的准确率。
# compare MAE with differing values of max_leaf_nodes
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))执行如下:
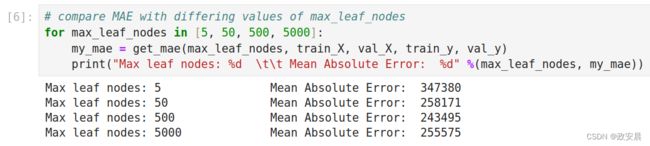
从列出的选项中,500是最佳叶子数量。
结论
这里的要点是,模型可能会遭受以下两种情况:
过拟合:捕捉到未来不会再次出现的虚假模式,导致预测结果不准确;
欠拟合:未能捕捉到相关模式,同样导致预测结果不准确。
我们使用验证数据来衡量候选模型的准确性,而这些验证数据不用于模型训练。这样可以让我们尝试多个候选模型,并选择出最好的一个。
告一段落
现在您已经理解了模型验证,以及欠拟合与过拟合,跟着做一下。
瞧瞧,机器学习中这么复杂的概念您都学会了。