【代码分享】基于VMD(变分模态分解)-RIME(霜冰算法优化)-LSTM的时间序列预测模型
程序名称:基于VMD(变分模态分解)-RIME(霜冰算法优化)-LSTM的时间序列预测模型
实现平台:matlab
代码简介:提出了变分模态分解(VMD)和霜冰算法优化法(RIME)与长短期记忆神经网络 (LSTM)相耦合,建立了时间序列预测模型(VMD-RIME-LSTM)。
变分模态分解(Variational Mode Decomposition,简称VMD)是一种信号分解方法,可以将复杂的信号分解为多个局部成分,每个局部成分对应于一个特定频率范围内的振动模态。
- VMD具有良好的多尺度分解能力。它可以在不同频率范围内精确地捕捉到信号的振动模态,适用于处理非平稳和非线性信号。
- VMD能够提供高时间和频率分辨率。通过分解信号为一系列窄带信号模态,可以准确地描述信号的瞬时频率和时频特征。
- VMD对噪声具有较强的鲁棒性。由于引入正则化项和模态频率约束项,VMD能够抑制噪声的干扰,提高信号分解的精度。
- VMD是一种自适应的信号分解方法,可以根据信号的特性进行优化。通过调节正则化参数和约束条件,可以灵活地适应不同信号的分解需求。
霜冰优化算法(RIME)是一项2023年发表于SCI、中科院二区Top期刊《Neurocomputing》上的新型优化算法。目前尚未发现任何关于RIME优化算法应用的相关文献。
该优化算法将霜冰形成过程成功模拟,并将其应用于算法搜索领域。具体而言,该算法提出了一种全新的搜索策略——软霜搜索策略,灵感来源于对软霜颗粒在运动中的特性模拟。同时,文中还模拟了硬霜颗粒之间的交叉行为,并提出了硬霜穿刺机制,以更好地利用这一算法。穿刺机制通过模拟硬霜颗粒相互交叉的方式引入了一种新的优化手段。最后,该算法进一步改进了元启发式算法的选择机制,引入了正向贪婪选择机制,并结合软霜搜索策略、硬霜穿刺机制和正向贪婪选择机制构建出了RIME算法。
首先利用 VMD 对历史数据进行分解,然 后依据RIME 对 LSTM 的参数进行寻优,并将分解出的时间序列数据分量输入到 LSTM 神经网络,最后将每个分量 的预测值相加,得到时间序列预测值。结果表明,与 LSTM、VMD-LSTM 模型相比,VMD-RIME-LSTM 模型的预测精度更高。附带参考文献。本代码具有一定创新性,且模块化编写,可自由根据需要更改完善模型,如将VMD替换为EMD CEEMD CEEMDAN EEMD等分解算法,RIME可以改为任意其他优化算法,对LSTM进一步改善,替换为GRU,BILSTM等。代码注释详细,无敌精品!!!本案例使用数据集是北半球光伏功率,共四个输入特征(太阳辐射度 气温 气压 大气湿度),一个输出预测(光伏功率),预测对象可以替换为是电力负荷、风速、光伏等等时间序列数据集;
参考文献:《Hang Su, Dong Zhao, Ali Asghar Heidari, Lei Liu, Xiaoqin Zhang, Majdi Mafarja, Huiling Chen,RIME: A physics-based optimization,Neurocomputing,ELSEVIER- 2023》《基于VMD-LSTM-ELMAN模型的国际原油价格人工智能预测研究》《基于IAOA-VMD-LSTM的超短期风电功率预测》《基于VMD-LSTM-Attention模型的短期负荷预测研究》《融合VMD和LSTM模型的新能源汽车销量预测方法》《基于VMD-LSTM的舟山港低硫保税船用燃油价格预测》《基于VMD-LSTM-Informer的光伏功率预测模型研究》
代码获取方式:【代码分享】基于VMD(变分模态分解)-RIME(霜冰算法优化)-LSTM的时间序列预测模型
部分代码展示
%% VMD-RIME-LSTM预测
tic
disp('…………………………………………………………………………………………………………………………')
disp('VMD-RIME-LSTM预测')
disp('…………………………………………………………………………………………………………………………')
% SSA参数设置
pop=3; % 种群数量
Max_iter=5; % 最大迭代次数
dim=3; % 优化LSTM的3个参数
lb = [50,50,0.001];%下边界
ub = [300,300,0.01];%上边界
numFeatures=f_;
numResponses=outdim;
fobj = @(x) fun(x,numFeatures,numResponses,X) ;
[Best_pos1,Best_score1,curve1,BestNet1]=RIME(pop,Max_iter,lb,ub,dim,fobj);
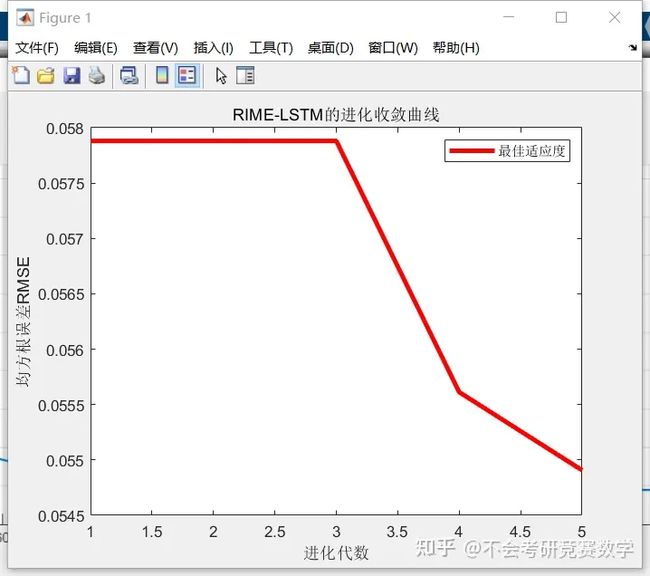
% 绘制进化曲线
figure
plot(curve1,'r-','linewidth',3)
xlabel('进化代数')
ylabel('均方根误差RMSE')
legend('最佳适应度')
title('RIME-LSTM的进化收敛曲线')
disp('')
disp(['最优隐藏单元数目为 ',num2str(round(Best_pos1(1)))]);
disp(['最优最大训练周期为 ',num2str(round(Best_pos1(2)))]);
disp(['最优初始学习率为 ',num2str((Best_pos1(3)))]);
%% 对每个分量建模
for d=1:c
disp(['第',num2str(d),'个分量建模'])
X_imf=[X(:,1:end-1) imf(d,:)'];
% 重构数据集
for i = 1: num_samples - kim - zim + 1
res(i, :) = [reshape(X_imf(i: i + kim - 1,:), 1, kim*or_dim), X_imf(i + kim + zim - 1,:)];
end
% 训练集和测试集划分
outdim = 1; % 最后一列为输出
num_size = 0.5; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度运行结果展示