MIT6.1810(which was called 6.S081 then) Lab1-4
关于用VScode调试XV6的方法我在上一篇博客有过介绍NJU操作系统课(蒋炎岩) 笔记-CSDN博客
这篇主要记录做XV6 Lab的过程。
关于Lec的学习我英语差而且机翻会有误差(会努力学英语的!),所以我使用肖宏辉大佬自己翻译的书面版本,非常感谢这位大佬!简介 - MIT6.S081
Lab: Xv6 and Unix utilities
sleep
任务要求实现 UNIX 程序
sleep,使其能够暂停执行一段用户指定数量的时钟滴答声(ticks)。滴答声是 xv6 内核定义的时间单位,即来自定时器芯片的两次中断之间的时间。
- 查看 user/ 目录中的其他程序(例如 user/echo.c、user/grep.c 和 user/rm.c),了解如何获取程序传递的命令行参数。
- 如果用户忘记传递参数,
sleep应该打印一个错误消息。- 命令行参数以字符串形式传递;可以使用
atoi将其转换为整数(参见 user/ulib.c)。- 使用系统调用
sleep。- 查看 xv6 内核代码中实现
sleep系统调用的部分(查找sys_sleep):kernel/sysproc.c。- 查看 user/user.h 获取从用户程序中调用的
sleep的 C 定义,以及 user/usys.S 中从用户代码跳转到内核进行sleep的汇编代码。- 在
main函数完成时调用exit(0)。- 将你的
sleep程序添加到 Makefile 的UPROGS中,这样运行make qemu时就会编译你的程序,然后可以从 xv6 shell 中运行它。
把题目建议看的代码理解一下,就可以做了,思路不是很难。
int main(int argc, char *argv[]){
if(argc!=2){
//提醒要传入参数
fprintf(2,"Usage: sleep \n");
exit(1);
}
int n = atoi(argv[1]);
if(sleep(n)!=0){
fprintf(2, "sleep: %s failed\n", argv[1]);
exit(1);
}
exit(0);
} pingpong
这是一个使用UNIX系统调用在两个进程之间通过一对管道进行“ping-pong”传递一个字节的程序。父进程应该向子进程发送一个字节;子进程应该打印"
: received ping",其中 是其进程ID,在管道上将字节写回父进程,并退出;父进程应该从子进程读取字节,打印" : received pong",然后退出。您的解决方案应位于文件user/pingpong.c中。
使用
pipe创建一个管道。使用
fork创建一个子进程。使用
read从管道读取字节,使用write向管道写入字节。使用
getpid查找调用进程的进程ID。
题目要求child向parent写一个字节,但是好像又没有用到,不是很明白,我把ping,pong都写入管道里,最开始实现的版本出现了并发bug,后来在parent向管道中读数据之前调用wait()等待child结束就能正常运行了。
int main(int argc, char *argv[]){
//读取(p[0])和写入(p[1])
int p[2];
pipe(p);
char buf[128];
if(fork()==0){
//child
read(p[0],buf,4);
write(p[1],"pong",4);
printf("%d: received %s\n", getpid(), buf);
close(p[0]);
close(p[1]);
exit(0);
}else{
//parent
write(p[1],"ping",4);
read(p[0],buf,4);
wait(0);
printf("%d: received %s\n", getpid(), buf);
close(p[0]);
close(p[1]);
exit(0);
}
}primes
要求通过使用管道实现一个并发的素数筛法。具体要求是创建一个管道流水线,第一个进程将数字 2 到 35 发送到管道中。对于每个质数,你需要安排创建一个进程,该进程从其左邻居的管道读取并通过右邻居的另一管道发送。由于 xv6 的文件描述符和进程数有限,第一个进程可以在数字 35 处停止。通过小心关闭不需要的文件描述符,确保主 primes 进程在整个流水线终止后退出。最终输出应该符合给定的格式。
- 谨慎关闭进程不需要的文件描述符,否则你的程序可能在第一个进程达到 35 之前耗尽 xv6 资源。
- 当第一个进程达到 35 时,它应该等待整个流水线终止,包括所有子进程、孙子进程等。因此,主 primes 进程应该在所有输出都已经打印出来,并且所有其他 primes 进程都已经退出之后才退出。
- 提示:当管道的写端关闭时,read 返回零。
- 直接向管道写入32位(4字节)整数比使用格式化的ASCII I/O 更简单。
- 你应该只在需要时创建流水线中的进程。
读完题目有点懵,我理解的就是fork一个子进程,然后在里面把所有数字写入一个管道,然后再fork一个子进程,把上个管道的数字筛选后写入下一个管道,最终在父进程把第二个管道,也就是筛选后的数字打印输出。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include
bool is_prime(int num);
int main(int argc, char *argv[]){
int int_nums[2];
pipe(int_nums);
//child用来把数字写入int_nums
if(fork()==0){
for(int i = 2;i < 36;i++){
write(int_nums[1],&i,sizeof(i));
}
exit(0);
}
wait(0);
close(int_nums[1]);
int out_nums[2];
pipe(out_nums);
//child用来从int_nums取数字筛选后写入out_nums
if(fork()==0){
int num;
while(read(int_nums[0],&num,sizeof(num))){
if(is_prime(num)){
write(out_nums[1],&num,sizeof(num));
}
}
exit(0);
}
wait(0);
close(int_nums[0]);
close(out_nums[1]);
int prime;
while(read(out_nums[0],&prime,sizeof(prime))){
printf("prime %d\n", prime);
}
exit(0);
}
bool is_prime(int num) {
for (int i = 2; i * i <= num; i++) {
if (num % i == 0) {
return false;
}
}
return true;
} find
编写一个简化版的UNIX
find程序,即查找目录树中具有特定名称的所有文件。你的解决方案应该放在user/find.c文件中。一些建议:
- 查看
user/ls.c以了解如何读取目录。- 使用递归使
find能够进入子目录。- 不要进入 "." 和 ".."。
- 更改文件系统在 qemu 运行之间是持久的,为了获得干净的文件系统,请运行
make clean,然后再运行make qemu。- 你需要使用 C 字符串。可以参考 K&R (the C book) 第5.5节。
- 注意,
==不像在 Python 中一样用于比较字符串。在 C 中,使用strcmp()来比较字符串。
先理解 ls.c 是如何读取目录的,查看一下代码 ,注释写得比较详细
void
ls(char *path)
{
char buf[512], *p;
int fd;
struct dirent de;//struct dirent 结构体,用于存储读取到的目录项
struct stat st;//struct stat 结构体,用于存储文件或目录的状态信息
if((fd = open(path, 0)) < 0){
fprintf(2, "ls: cannot open %s\n", path);
return;
}
// 获取文件或目录的状态信息
if(fstat(fd, &st) < 0){
fprintf(2, "ls: cannot stat %s\n", path);
close(fd);
return;
}
switch(st.type){
case T_DEVICE:
case T_FILE:
// 如果是设备或文件,直接打印信息
printf("%s %d %d %l\n", fmtname(path), st.type, st.ino, st.size);
break;
case T_DIR:
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("ls: path too long\n");
break;
}
strcpy(buf, path);
p = buf+strlen(buf);
*p++ = '/';
//读取目录项,存储到de中
while(read(fd, &de, sizeof(de)) == sizeof(de)){
//如果 inum 为 0,说明当前目录项是 . 或 ..,跳过当前迭代,继续下一次循环
if(de.inum == 0)
continue;
//DIRSIZ 是文件名的最大长度,p 指向 buf 中的当前位置dir/,把文件名复制上去
memmove(p, de.name, DIRSIZ);
//添加字符串结束符
p[DIRSIZ] = 0;
//获取当前目录项的状态信息
if(stat(buf, &st) < 0){
printf("ls: cannot stat %s\n", buf);
continue;
}
//打印目录项信息
printf("%s %d %d %d\n", fmtname(buf), st.type, st.ino, st.size);
}//重复该循环
break;
}
close(fd);
}写find.c也是照葫芦画瓢 ,不过注意 fmtname 函数不需要再填充0了,这样方便直接让 fmtname(path) 和 name 作比较,这题我干了几个小时,我最开始用switch 语句来判断,st.type为T_DIR时会对每个目录项调用find,为T_FILE时会让de.name和name进行strcmp判断,一样则打印,否则close+return,结果总是会报错一些文件调用open时出错,但是感觉逻辑又没有问题(感觉是XV6的文件系统出错),反复改了好多次,最终决定把strcmp判断放在最前面,然后接下来st.type不是 T_DIR 就return,这样才通过测试,有点麻了...
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
#include "kernel/fcntl.h"
char*
fmtname(char *path);
void find(char *path, char *name);
int
main(int argc, char *argv[])
{
if(argc < 3){
printf("Usage: find path filename\n");
exit(1);
}
find(argv[1], argv[2]);
exit(0);
}
char*
fmtname(char *path)
{
char *p;
for(p=path+strlen(path); p >= path && *p != '/'; p--)
;
p++;
return p;
}
void find(char *path, char *name) {
if(strcmp(fmtname(path), name)==0){
printf("%s\n", path);
}
char buf[512], *p;
int fd;
struct dirent de;//struct dirent 结构体,用于存储读取到的目录项
struct stat st;//struct stat 结构体,用于存储文件或目录的状态信息
if((fd = open(path, 0)) < 0){
fprintf(2, "find: cannot open %s\n", path);
return;
}
// 获取文件或目录的状态信息
if(fstat(fd, &st) < 0){
fprintf(2, "find: cannot stat %s\n", path);
close(fd);
return;
}
if (st.type != T_DIR) {
close(fd);
return;
}
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("find: path too long\n");
return;
}
strcpy(buf, path);
p = buf+strlen(buf);
*p++ = '/';
//读取目录项,存储到de中
while(read(fd, &de, sizeof(de)) == sizeof(de)){
//如果 inum 为 0,说明当前目录项是 . 或 ..,跳过当前迭代,继续下一次循环
if (!strcmp(de.name, ".") || !strcmp(de.name, "..") || de.inum == 0)
continue;
//DIRSIZ 是文件名的最大长度,p 指向 buf 中”dir/“的下一个字符,把文件名复制上去
memmove(p, de.name, DIRSIZ);
//添加字符串结束符
p[DIRSIZ] = 0;
//递归调用find查找子目录
find(buf,name);
}//重复该循环
close(fd);
}xargs
这个任务要求你编写一个简化版的UNIX xargs程序。xargs程序的参数描述了要运行的命令,它从标准输入读取行,并为每一行运行命令,将该行附加到命令的参数中。你的解决方案应该在文件
user/xargs.c中。这是一个用法示例:$ echo hello too | xargs echo bye bye hello too $在这个示例中,
xargs接收到echo hello too,然后将其附加到echo bye命令的参数列表中,从而形成echo bye hello too,并最终输出为 "bye hello too"。一些建议:
- 使用fork和exec在每一行输入上调用命令。在父进程中使用wait等待子进程完成命令。
- 要读取单独的输入行,请每次读取一个字符,直到出现换行符('\n')。
- kernel/param.h声明了MAXARG,如果需要声明argv数组,这可能会有用。
- 将程序添加到Makefile中的UPROGS。
- 对文件系统的更改会在多次运行qemu之间持续存在。要获得干净的文件系统,请运行
make clean,然后运行make qemu。注意标准输入可能会有很多行,每一行都要调用,我最开始就是因为没有理解好题意以为只有一行而写错了!!!
代码比较长,但是基本每一步思路我都写有注释,总体的思路是我先把xargs的参数存在commands,然后把标准输入的所有内容存进buf,然后从buf中把每一行的参数加到commands后面,执行一次,再读buf的下一行,以此循环,直到把buf读完(标准输入读完)。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/param.h" // MAXARG 命令行参数的最大数量
void strncpy(char *dest, char *src, int n);
int main(int argc, char *argv[]){
if(argc < 2){
printf("Usage: xargs [argv...]\n");
exit(1);
}
char buf[512], *p,ch; // p用来指示当前指针在buf中的位置
char commands[MAXARG][MAXARG]; //commands 是最终要传入exec命令的参数
// 首先把xargs自己的参数赋值给commands ,在之后的执行过程中会把从标准输入获得的参数也赋值给commands
int i;
for(i=0;i 0){
buf[j++]=ch;
}
p = buf;
// 定义word用来从buf中复制相应的字符串
char word[MAXARG];
// j 用来迭代 word
j = 0;
//从buf中读数据复制到 word
for(;*p!='\0';p++){
//当*p == '\n'时,说明此时已经读完了标准输入一行数据,那么就执行一次,然后再继续读下一行
while(*p != '\n'){
//如果为空格就说明此时word已经获得了一个参数,把word的内容复制到commands里
if(*p == ' '){
word[j++]='\0';
strncpy(commands[i++], word, sizeof(word));
//清空现在word,重新存储下一个参数
memset(word, 0, sizeof(word));
p++;
//清空word的下标
j=0;
}else{
word[j++]=*p;
p++;
}
}
//此时p遇到'\n'退出while循环,把最后一次读到的word复制到commands中
word[j++]='\0';
strncpy(commands[i++], word, sizeof(word));
memset(word, 0, sizeof(word));
//用args来存储commands的参数放进exec执行,因为commands是二维数组,需要转换一下
char *args[MAXARG];
for (j = 0; j < i; j++) {
args[j] = commands[j];
}
if (fork()==0) {
exec(args[0], args);
exit(0);
}
wait(0);
// j 用来记录
j=0;
// 把从标准输入得到的这一行赋值给commands的参数清空, 这样commands就只剩下xargs的参数,k是之前记录的xargs自己的参数的数量
for(;k 尾声
Lab1总算完成了,也花了挺多时间的,特别是find和xargs,调试了好久,我顺便记录一下感觉平常容易混淆但又比较重要的一个知识点:字符数组的首地址和字符指针的区别
字符数组的首地址和字符指针在很多情况下确实可以表现得很相似,因为数组名在大多数上下文中会隐式转换为指向数组首元素的指针。然而,它们有一些细微的区别:
-
修改行为:
- 字符数组的首地址是数组的起始地址,通常是一个固定的内存块。在一些情况下,这个地址可能是常量,不允许修改。
- 字符指针可以被赋予新的地址,因此可以指向不同的字符串或内存位置。
-
初始化:
- 字符数组的首地址是由数组名直接给出的。
- 字符指针可以通过赋值来初始化,可以指向任何有效的字符数组或字符串。
-
sizeof 运算符:
sizeof对字符数组返回整个数组的大小。sizeof对字符指针返回指针本身的大小。
char arr[] = "Hello";
char *ptr = arr; // 字符数组的首地址赋给字符指针
// 通过数组名访问
char firstChar1 = arr[0]; // 取第一个字符
char *ptrToFirstChar1 = &arr[0]; // 取第一个字符的地址
// 通过指针访问
char firstChar2 = *ptr; // 取第一个字符
char *ptrToFirstChar2 = ptr; // 取指针本身的地址
// 修改数组的首字符
arr[0] = 'X'; // 合法
// 修改指针指向的字符
*ptr = 'Y'; // 合法
// 修改数组的首地址!!!
arr = someOtherAddress; // 非法!!!,数组名是常量,不可修改
// 修改指针的值(指向新地址)
ptr = someOtherAddress; // 合法
总的来说,虽然在某些情况下它们的行为类似,但字符数组的首地址通常具有更多的限制,而字符指针更具灵活性。
Lab: system calls
Using gdb
1.在第一个终端xv6-lab-2022目录下输入 make qemu-gdb
2.在第二个终端xv6-lab-2022目录下输入 gdb-multiarch
3.在第二个终端xv6-lab-2022目录下输入 source .gdbinit
这样就进入调试了,然后按照文档输入命令

layout src 命令用于切换 GDB 界面的布局,切割成两个界面,多出的那个将显示源代码窗口
backtrace(缩写为 bt)命令用于显示当前调用栈的信息
之后就可以看到如下界面

现在可以回答这些问题了:
Looking at the backtrace output, which function called syscall?
由上图得出答案 -> usertrap()
What is the value of p->trapframe->a7 and what does that value represent? (Hint: look user/initcode.S, the first user program xv6 starts.)

所以a7存储的是系统调用号,值是SYS_exec(在syscall.h定义,值为 7)
What was the previous mode that the CPU was in?

打印sstatus特殊寄存器,观察下图,它的值由这些位组成

其中SPP位表示陷入 Supervisor 模式前的特权模式。当 SPP 为 0 时,表示陷入前是 User 模式;当 SPP 为 1 时,表示陷入前是 Supervisor 模式。那么根据打印结果得知此位是0,所以是 user mode。
Write down the assembly instruction the kernel is panicing at. Which register corresponds to the varialable num?

先在syscall.c替换该语句,然后终端 make qemu,让XV6 crush

然后在 kernel/kernel.asm 中查看sepc的地址,sepc为kernel 产生panic的地址

可以看出来是a3寄存器对应num
Why does the kernel crash? Hint: look at figure 3-3 in the text; is address 0 mapped in the kernel address space? Is that confirmed by the value in scause above? (See description of scause in RISC-V privileged instructions)

lw a3,0(zero)尝试将地址0的字赋值给a3,这显然是一个非法地址,因此发生错误.
What is the name of the binary that was running when the kernel paniced? What is its process id (pid)?

System call tracing
在这个任务中,你将添加一个系统调用追踪功能,以帮助你在后续的实验中进行调试。你将创建一个新的
trace系统调用来控制追踪。它应该接受一个整数参数 "mask",其中的位指定要追踪的系统调用。例如,要追踪 fork 系统调用,一个程序调用trace(1 << SYS_fork),其中SYS_fork是来自kernel/syscall.h的系统调用编号。你需要修改 xv6 内核,以便在每个系统调用即将返回时,如果系统调用的编号在掩码中被设置,就打印一行输出。该行应包含进程 ID、系统调用的名称和返回值;你不需要打印系统调用的参数。trace系统调用应该启用对调用它的进程以及随后由它 fork 的任何子进程的追踪,但不应影响其他进程。在上述的第一个例子中,trace 命令调用 grep 来追踪只有 read 系统调用。其中的 32 是通过左移操作得到的,即 1<
一些建议:
1. 在 Makefile 的 UPROGS 中添加 $U/_trace。
2. 运行 make qemu 时,你会看到编译器无法编译 user/trace.c,因为系统调用的用户空间存根还不存在:需要在 user/user.h 中为系统调用添加原型,在 user/usys.pl 中添加存根,在 kernel/syscall.h 中添加系统调用号。Makefile 会调用 user/usys.pl 脚本生成 user/usys.S,其中包含实际的系统调用存根,这些存根使用 RISC-V 架构的 ecall 指令进行内核转换。一旦解决了编译问题,运行 trace 32 grep hello README 会失败,因为你还没有在内核中实现该系统调用。用户空间存根(user-space stub)是一个在用户空间(用户程序中)和内核空间之间的接口层。也就是把系统调用号放进a7寄存器,然后执行ecall那部分代码。
3. 在 kernel/sysproc.c 中添加一个 sys_trace() 函数,通过将其参数保存在 proc 结构的新变量中来实现新的系统调用(参见 kernel/proc.h)。从用户空间检索系统调用参数的函数位于 kernel/syscall.c 中,你可以在 kernel/sysproc.c 中看到它们的使用示例。
4. 修改 fork() 函数(参见 kernel/proc.c),以将父进程的追踪掩码复制到子进程。
5. 修改 kernel/syscall.c 中的 syscall() 函数以打印追踪输出。你需要添加一个系统调用名称数组以进行索引。
6. 如果在直接在 qemu 中运行测试时通过,但使用 make grade 运行测试时出现超时,请尝试在 Athena 上测试你的实现。这个实验中的一些测试可能对本地机器的计算资源要求较高(尤其是如果你使用的是 WSL)。
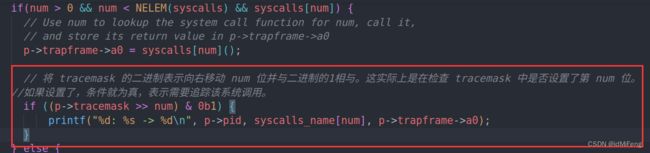
这里按照提示逐步去做就可以了,注意要自己在proc.h 的 struct proc 加上tracemask 字段。大体思路不难,RISCV是用寄存器传参的,所以你trace后的参数在a0寄存器里。下面给几个比较关键的步骤:
sysproc.c

syscall.c
Sysinfo
这项任务要求你添加一个名为 sysinfo 的系统调用,用于收集关于运行系统的信息。该系统调用接受一个参数,即指向 struct sysinfo 结构的指针(参见 kernel/sysinfo.h)。内核应该填充该结构的字段:freemem 字段应设置为空闲内存的字节数,而 nproc 字段应设置为状态不是 UNUSED 的进程数量。我们提供了一个名为 sysinfotest 的测试程序,如果运行该程序输出 "sysinfotest: OK",则表示你已通过此任务。
一些建议:
在 Makefile 的 UPROGS 中添加 $U/_sysinfotest。
运行 make qemu;user/sysinfotest.c 将无法编译通过。添加系统调用 sysinfo,按照前一项任务的步骤进行操作。在 user/user.h 中声明 sysinfo() 的原型之前,你需要预先声明 struct sysinfo 的存在:
struct sysinfo; int sysinfo(struct sysinfo *);修复编译问题后,运行 sysinfotest;此时它将失败,因为你还没有在内核中实现该系统调用。
sysinfo 需要将一个 struct sysinfo 结构复制回用户空间;参见 sys_fstat()(kernel/sysfile.c)和 filestat()(kernel/file.c)的例子,了解如何使用 copyout() 完成此操作。
为了收集空闲内存的数量,向 kernel/kalloc.c 添加一个函数。
为了收集进程数量,向 kernel/proc.c 添加一个函数。
先看copyout() ,它的作用就是从src复制len长度的内容到该用户进程的pagetable中dstva虚拟地址对应的物理地址处。
// Copy from kernel to user.
// Copy len bytes from src to virtual address dstva in a given page table.
// Return 0 on success, -1 on error.
int
copyout(pagetable_t pagetable, uint64 dstva, char *src, uint64 len)
{
uint64 n, va0, pa0;
while(len > 0){
va0 = PGROUNDDOWN(dstva); //使用 PGROUNDDOWN(dstva) 将目标虚拟地址 dstva 向下对齐到页面边界,得到 va0
pa0 = walkaddr(pagetable, va0);//使用 walkaddr(pagetable, va0) 查找 va0 对应的物理地址 pa0。
if(pa0 == 0)
return -1;
n = PGSIZE - (dstva - va0); //计算实际需要复制的字节数 n
if(n > len)
n = len;
memmove((void *)(pa0 + (dstva - va0)), src, n);//使用 memmove 将源数据 src 复制到用户空间的目标地址 pa0 + (dstva - va0)。
//更新 len、src 和 dstva,准备复制下一段数据
len -= n;
src += n;
dstva = va0 + PGSIZE;
}
return 0;
}然后需要添加sysinfo系统调用,添加的过程和trace差不多,主要是向kernel/kalloc.c 添加一个函数收集空闲内存的数量,向 kernel/proc.c 添加一个函数收集进程数量。
我们需要阅读proc.c和kalloc.c的源码,了解相关内容的定义。
最容易的是nproc(),遍历所有进程然后记录状态不是UNUSER的进程数量就行
//add nproc() for sysinfo
uint64 nproc(){
struct proc *p;
uint64 num;
for(p=proc;p < &proc[NPROC]; p++){
if (p->state != UNUSED)
num++;
}
return num;
}在 freemem ()函数中,需要遍历空闲页的数据结构,累计所有空闲页的大小,从而计算空闲内存的总量。
在kalloc.c 中的相关代码是这样的
struct run {
struct run *next;// 用于形成空闲页链表
};
struct {
struct spinlock lock;
struct run *freelist;//空闲内存块链表的头指针,指向第一个空闲块
} kmem; // 维护内核的空闲内存块链表于是写出freemem()就比较容易了
//add freemem for sysinfo
uint64 freemem(void){
struct run *p = kmem.freelist;
uint64 num = 0;
while (p)
{
p = p->next;
num++;
}
return num * PGSIZE;
}尾声
lab2感觉比lab1轻松多了,只要根据文档的提示,把该看的源码看懂,那么就有解题思路了。
Lab: page tables
xv6页表结构

一段6.S081的内容
学生提问:为什么通过3级page table会比一个超大的page table更好呢?
Frans教授:这是个好问题,这的原因是,3级page table中,大量的PTE都可以不存储。比如,对于最高级的page table里面,如果一个PTE为空,那么你就完全不用创建它对应的中间级和最底层page table,以及里面的PTE。所以,这就是像是在整个虚拟地址空间中的一大段地址完全不需要有映射一样。
学生:所以3级page table就像是按需分配这些映射块。
Frans教授:是的,就像前面(4.6)介绍的一样。最开始你只有3个page table,一个是最高级,一个是中间级,一个是最低级的。随着代码的运行,我们会创建更多的page table diretory。
做这里之前需要看一下相关文件的源码,kernel/memlayout.h ,kernel/vm.c ,kernel/kalloc.c
有Google和AI,理解源码不算特别难。
Speed up system calls
具体要求是在每个进程创建时,在虚拟地址
USYSCALL处映射一个只读页面,并在该页面的起始位置存储一个struct usyscall结构体,用于存储当前进程的 PID。一些建议:
- 您可以在
kernel/proc.c的proc_pagetable()中执行映射。- 选择允许用户空间仅读取页面的权限位。
- 您可能会发现
mappages()是有用工具。- 不要忘记在
allocproc()中分配和初始化页面。- 确保在
freeproc()中释放该页。
首先理解这个struct usyscall包含一个字段是当前进程的pid,每个进程都有这个struct,所以首先在proc.h的struct proc中添加
struct usyscall *usyscall;根据要求需要在 allocproc() 中分配和初始化页面,也就是定义usyscall所在的物理页,然后建立虚拟地址->USYSCALL 到 物理地址->usyscall所在的物理页 的映射。
这里可以仿造代码中关于trapframe的操作用kalloc()分配一页内存,地址指向usyspage,并把该进程的pid存到页表中。稍后就把用户内存中的USYSCALL映射到这里。
proc.c->allocproc
// Allocate a usyscall page.
if((p->usyscall = (struct usyscall *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
p->usyscall->pid = p->pid ; 之后在 kernel/proc.c 的 proc_pagetable() 中执行映射,通过调用mappages函数来实现映射,并且需要允许用户空间读,那标志位就是PTE_R和PTE_U,如果mappage失败的话,要撤销前面TRAMPOLINE和TRAPFRAME的映射。
if(mappages(pagetable, USYSCALL, PGSIZE,
(uint64)(p->usyscall), PTE_R | PTE_U) < 0){
uvmunmap(pagetable, TRAMPOLINE, 1, 0);
uvmunmap(pagetable, TRAPFRAME, 1, 0);
uvmfree(pagetable, 0);
return 0;
}仿照freeproc里对trapframe里的操作来释放usyscall
if(p->usyspage)
kfree((void*)p->usyscall);
p->usyspage = 0;在freeproc中首先会调用kfree函数释放指定的内核内存页,在这里也就是把p->usyscall全部memset为1,并放入run链表,然后会调用一个proc_freepagetable函数解除虚拟地址与物理地址之间的映射,需要补充在proc_freepagetable中取消USYSCALL到usyscall的映射。
uvmunmap(pagetable, USYSCALL, 1, 0);Print a page table
实现一个函数
vmprint(),用于打印 RISC-V 的页表内容。该函数应该接受一个pagetable_t参数,并以指定的格式打印该页表。在exec.c文件的main()函数中,插入if(p->pid==1) vmprint(p->pagetable)语句,以便在执行 init 进程时打印其页表。你将通过make grade中的 PTE 打印测试来获得此部分实验的全部学分。具体而言,打印的格式如下所示:
page table 0x0000000087f6b000 ..0: pte 0x0000000021fd9c01 pa 0x0000000087f67000 .. ..0: pte 0x0000000021fd9801 pa 0x0000000087f66000 .. .. ..0: pte 0x0000000021fda01b pa 0x0000000087f68000 .. .. ..1: pte 0x0000000021fd9417 pa 0x0000000087f65000 .. .. ..2: pte 0x0000000021fd9007 pa 0x0000000087f64000 .. .. ..3: pte 0x0000000021fd8c17 pa 0x0000000087f63000 ..255: pte 0x0000000021fda801 pa 0x0000000087f6a000 .. ..511: pte 0x0000000021fda401 pa 0x0000000087f69000 .. .. ..509: pte 0x0000000021fdcc13 pa 0x0000000087f73000 .. .. ..510: pte 0x0000000021fdd007 pa 0x0000000087f74000 .. .. ..511: pte 0x0000000020001c0b pa 0x0000000080007000上述示例中,第一行显示了传递给
vmprint的参数。接下来的每一行都代表一个 PTE(页表项),包括引用更深层树状结构中的页表页的 PTE。每个 PTE 行的缩进由 " .." 数量表示,表示其在树中的深度。每个 PTE 行显示其在页表页中的索引、PTE 位以及从 PTE 中提取的物理地址。不要打印无效的 PTE。在上述示例中,顶层页表页有 0 和 255 两个条目的映射。下一级中,条目 0 仅有索引 0 被映射,而该索引 0 对应的底层级别有 0、1 和 2 三个条目映射。一些提示:
- 你可以将
vmprint()放在kernel/vm.c中。- 使用
kernel/riscv.h文件末尾的宏。freewalk函数可能对你有一些启发。- 在
kernel/defs.h中定义vmprint的原型,以便你可以从exec.c中调用它。- 在
printf调用中使用%p,以打印出如示例中所示的完整的 64 位十六进制 PTE 和地址。
先看一下freewalk函数,这个函数的目的是递归地释放一个页表页及其所有子页表页
void
freewalk(pagetable_t pagetable)
{
// there are 2^9 = 512 PTEs in a page table.
for(int i = 0; i < 512; i++){
pte_t pte = pagetable[i];
if((pte & PTE_V) && (pte & (PTE_R|PTE_W|PTE_X)) == 0){
// this PTE points to a lower-level page table.
uint64 child = PTE2PA(pte);
freewalk((pagetable_t)child);
pagetable[i] = 0;
} else if(pte & PTE_V){
panic("freewalk: leaf");
}
}
kfree((void*)pagetable);
}- 函数使用
for循环遍历页表页中的所有 512 个 PTE。 - 对于每个 PTE,它检查是否是有效的(
PTE_V位被设置)且同时没有读写执行权限(PTE_R|PTE_W|PTE_X位均未设置)。如果是这样,说明该 PTE 指向一个更低级别的页表页。- 获取 PTE 中存储的指向子页表页的地址,然后递归调用
freewalk函数释放子页表页。 - 将当前 PTE 置零,表示该映射已被移除。
- 获取 PTE 中存储的指向子页表页的地址,然后递归调用
- 如果 PTE 是有效的且同时有读写执行权限,则抛出 panic(错误),因为该函数预期所有叶子映射必须已经被移除。
- 最后,使用
kfree函数释放当前页表页的内存。
那么vmprint的执行流程也是差不多的,也就是递归打印一下地址
写的时候发现必须要用到树的深度来决定打印多少个".. " ,但是按照题目的要求函数参数只有pagetable,所以只能定义一个辅助函数来记录递归的深度了。
void vmprint_help(pagetable_t pagetable,int depth){
for(int i = 0;i<512;i++){
pte_t pte = pagetable[i];
if(pte & PTE_V){
uint64 child = PTE2PA(pte);
if (depth == 0){
printf("..");
}
else if(depth == 1){
printf(".. ..");
}
else if(depth == 2){
printf(".. .. ..");
}
printf("%d: pte %p pa %p\n",i,pte,child);
depth++;
if(depth != 3){
vmprint_help((pagetable_t)child,depth);
}
//这里要减一,确保下次循环depth没有变
depth--;
}
}
}
void vmprint(pagetable_t pagetable){
printf("page table %p\n", pagetable);
vmprint_help(pagetable,0);
}
Detect which pages have been accessed
这个任务的目标是向 xv6 中添加一个名为
pgaccess()的系统调用,该调用能够检测和报告哪些页面已被访问。RISC-V 硬件页行走器在解析 TLB 缺失时标记了页面表项 (PTE) 中的访问位。pgaccess()系统调用接受三个参数:首先是要检查的第一个用户页面的起始虚拟地址,其次是要检查的页面数量,最后是一个用户地址,指向一个缓冲区,用于存储结果,其中使用一位表示一个页面,而第一个页面对应最低有效位。具体步骤如下:
实现
sys_pgaccess()函数: 位于kernel/sysproc.c文件中。在这个函数中,你需要使用argaddr()和argint()来解析系统调用的参数。然后,你可以调用walk()函数来找到正确的 PTE。这个函数应该检查给定范围内的每一页,看看它们的 PTE 中的PTE_A是否被设置。如果设置了,表示该页面已经被访问。记得在检查后清除PTE_A,以便下一次调用pgaccess()时仍然可以检测到是否有新的访问。定义
PTE_A: 在kernel/riscv.h文件中,你需要定义PTE_A,即访问位。你可以查阅 RISC-V 特权体系结构手册来确定其值。使用临时缓冲区: 由于用户空间的数据不能直接在内核中进行修改,最好在内核中使用临时缓冲区来存储结果,然后再通过
copyout()将其复制到用户空间。调试: 使用
vmprint()函数来帮助调试页表。这可以让你查看页面表的状态,确保访问位在访问后被正确清除。限制扫描的页面数量: 你可以设置对扫描的页面数量进行上限,以确保系统调用的效率。
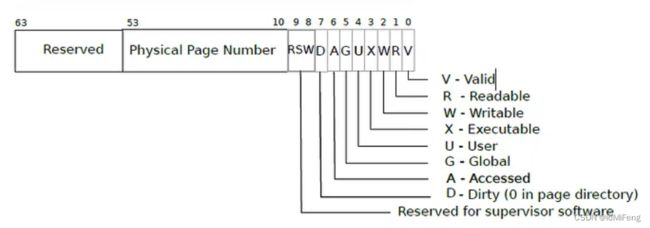
由上图可知PTE_A位于第六位,于是在kernel/riscv.h 定义如下
#define PTE_A (1L << 6)这题要检查传入的page是否被access过,就用把每页page的va传入walk得到的pte和PTE_A进行相与操作,1&1=1,如果相与的结果是1说明pte的accessed位是即它被访问过,就把对应这页的bitmask设置为1,然后把该pte的accesed位清空。用argaddr,argint来获取参数。
sys_pgaccess(void)
{
//这里一定要初始化不能只声明
unsigned int abits=0;
uint64 addr;
int num;
uint64 dest;
argaddr(0,&addr);
argint(1,&num);
argaddr(2,&dest);
for(int i = 0;ipagetable,va,0);
if(*pte&PTE_A)
{
abits=abits|(1<pagetable,dest,(char*)&abits, sizeof(abits)) < 0)
return -1;
return 0;
} Lab: traps
RISC-V assembly
仔细阅读 user/call.asm 文件,该文件包含了一个使用 RISC-V 汇编语言编写的程序的可读汇编版本。你需要回答一系列关于函数 g、f 和 main 的问题,并将答案保存在一个名为 answers-traps.txt 的文件中。
Which registers contain arguments to functions? For example, which register holds 13 in main's call to printf?
下图是RISC-V各寄存器的用途:

函数各参数显然是在a0-a7中传递的,汇编代码li a2,13 可以得出a2寄存器存放13。
Where is the call to function f in the assembly code for main? Where is the call to g? (Hint: the compiler may inline functions.)
在汇编代码中没有相关的代码片段,是编译器直接优化了,把f(8)+1的值直接计算出来传入printf中 。
At what address is the function printf located?
34: 612080e7 jalr 1554(ra) # 642 可以看出是0x642
What value is in the register ra just after the jalr to printf in main?
jalr 是 RISC-V 汇编指令中的一种,用于无条件跳转并链接(Jump and Link Register)。它的基本语法是
jalr rd, rs1, imm
rd是目标寄存器,用于保存返回地址。rs1是源寄存器,包含目标地址。imm是立即数,表示附加的偏移量。
jalr 指令的作用是将 PC + 4 存储到目标寄存器 rd 中,然后跳转到地址 (rs1 + imm)。jalr 1554(ra) 表示跳转到 ra + 1554 的地址,并将 PC + 4 存储到 ra 寄存器中,以便在函数返回时使用。把运行到jalr处的PC+4存入ra,也就是0x38。
Run the following code.
unsigned int i = 0x00646c72;
printf("H%x Wo%s", 57616, &i);
What is the output? Here's an ASCII table that maps bytes to characters.
The output depends on that fact that the RISC-V is little-endian. If the RISC-V were instead big-endian what would you set i to in order to yield the same output? Would you need to change 57616 to a different value?
Here's a description of little- and big-endian and a more whimsical description.
i是一个unsigned int类型的变量,初始化为十六进制值0x00646c72。printf函数的格式字符串包含两个占位符:%x用于以十六进制格式打印一个整数。%s用于打印字符串。
-
%x占位符将打印整数57616的十六进制表示(十进制值),即e110的十六进制形式。 -
%s占位符将把变量i地址处的内存解释为以空字符结尾的字符串。变量i的值是0x00646c72,在ASCII字符中对应着字符串 "rld"。
因此,输出将是 "He110 World"。
如果 RISC-V 是大端序,内存布局将不同。在这种情况下,为了产生相同的输出,需要将 i 设置为 0x726c6400(字节的顺序相反)。
In the following code, what is going to be printed after 'y='? (note: the answer is not a specific value.) Why does this happen?
printf("x=%d y=%d", 3);
y的值取决于printf第三个参数,a2寄存器的值。
Backtrace
实现一个名为
backtrace()的函数,该函数在kernel/printf.c中。你需要在sys_sleep中调用这个函数,并运行名为bttest的程序,该程序调用sys_sleep。backtrace()函数应该利用帧指针遍历调用堆栈,打印每个堆栈帧中保存的返回地址。完成后,运行
qemu并观察输出的返回地址列表,形式如下(实际数字可能不同):backtrace: 0x0000000080002cda 0x0000000080002bb6 0x0000000080002898然后,在终端窗口中运行
addr2line -e kernel/kernel(或riscv64-unknown-elf-addr2line -e kernel/kernel),将返回地址从你的回溯中复制并粘贴。你应该看到类似以下的输出:kernel/sysproc.c:74 kernel/syscall.c:224 kernel/trap.c:85完成这些步骤后,你应该能够在发生错误时看到内核的回溯。
- 在
kernel/defs.h中添加backtrace()的原型,这样就可以在sys_sleep中调用backtrace。- GCC编译器将当前执行函数的帧指针存储在
s0寄存器中。在kernel/riscv.h中添加以下函数:在static inline uint64 r_fp() { uint64 x; asm volatile("mv %0, s0" : "=r" (x) ); return x; }backtrace中调用这个函数以读取当前帧指针。r_fp()使用内联汇编来读取s0。- https://pdos.csail.mit.edu/6.1810/2022/lec/l-riscv.txt有一个关于堆栈帧布局的图片。注意,返回地址位于堆栈帧的帧指针的固定偏移量(-8),而保存的帧指针位于帧指针的固定偏移量(-16)。
backtrace()需要一种方式来识别是否已经看到了最后一个堆栈帧,并且应该停止。一个有用的事实是每个内核栈分配的内存都由一个单独的页面对齐的页面组成,因此给定栈的所有堆栈帧都位于同一页上。你可以使用PGROUNDDOWN(fp)(见kernel/riscv.h)来识别帧指针所引用的页面。- 一旦
backtrace正常工作,请在kernel/printf.c中的panic中调用它,这样当内核发生恐慌时,你将看到内核的回溯。
题目的意思就是打印每个栈帧的return address ,这个地址位于代码区,是函数调用时的下一条指令的地址,栈位于数据区, 再看提示中的"返回地址位于堆栈帧的帧指针的固定偏移量(-8),而保存的帧指针位于帧指针的固定偏移量(-16)",也就是说我们获得当前栈帧的起始地址(s0寄存器)后,-8就可以得到当前栈帧的return address,-16就可以得到当前栈帧中保存的上一个栈帧的起始地址。
要理解这一行为可以查看函数调用时的汇编代码
addi sp, sp, -16
sd s0, 8(sp)
addi s0, sp, 16
首先将栈指针寄存器(栈顶)sp下移16分配新的栈帧,然后把帧指针寄存器s0的值存到sp+8的位置,也就是把当前s0的值(当前栈帧的起始地址)存在新的栈帧中,然后把sp+16的值赋值给s0,此时s0存的是新栈帧的起始地址,所以我们知道寄存器s0存的是当前栈帧的起始地址,当前栈帧中会存有上一个栈帧的起始地址,可以通过偏移量得到。
那我们就不断循环遍历每个栈帧来得到它们的ra就可以了,由于每个内核栈都是由一个单独的页面对齐的页面组成,因此在遍历栈帧时,只要仍然位于相同的页面内,就可以继续循环遍历栈帧,直到离开这张页面。
通过r_fp获取当前栈帧起始地址,-8得到ra,-16得到上一栈帧起始地址,再-8得到ra...
void
backtrace(void)
{
printf("backtrace:\n");
uint64 fp = r_fp();
uint64 fp_page_start=PGROUNDDOWN(fp);
while (fp_page_start==PGROUNDDOWN(fp)) {
printf("%p\n", *(uint64*)(fp-8));
fp = *(uint64*)(fp-16);
}
}Alarm
在这个练习中,你需要为 xv6 操作系统添加一个新的功能,即定期提醒进程在使用 CPU 时间时进行某些操作。这对于计算密集型进程可能很有用,因为它们希望限制消耗的 CPU 时间,或者对于需要计算但也想执行一些定期操作的进程。更普遍地说,你将实现一种用户级中断/故障处理程序的原始形式;例如,你可以使用类似的机制来处理应用程序中的页面错误。你的解决方案在通过 alarmtest 和 'usertests -q' 时被视为正确。
具体要求如下:
添加一个新的系统调用
sigalarm(interval, handler)。如果一个应用程序调用sigalarm(n, fn),则在程序消耗的每 n 个 "ticks" 的 CPU 时间之后,内核应该调用应用程序函数 fn。当 fn 返回时,应用程序应该从离开的地方继续执行。tick 是 xv6 中的一个相当任意的时间单位,由硬件定时器生成中断的频率决定。如果应用程序调用sigalarm(0, 0),内核应该停止生成定期的警报调用。在 xv6 仓库中找到
user/alarmtest.c文件,并将其添加到 Makefile 中。这样做之前,它无法正确编译。alarmtest在test0中调用sigalarm(2, periodic),以请求内核每 2 个 tick 强制调用periodic()函数,然后在一段时间内旋转。你可以查看user/alarmtest.asm中的alarmtest的汇编代码,这可能对调试很有帮助。当alarmtest产生如下输出且usertests -q也正确运行时,你的解决方案被视为正确:$ alarmtest test0 start ........alarm! test0 passed test1 start ...alarm! ..alarm! ...alarm! ..alarm! ...alarm! ..alarm! ...alarm! ..alarm! ...alarm! ..alarm! test1 passed test2 start ................alarm! test2 passed test3 start test3 passed $ usertests -q ... ALL TESTS PASSED $当你完成时,你的解决方案可能只有几行代码,但要弄清楚可能有点棘手。我们将使用原始存储库中的 `alarmtest.c` 版本来测试你的代码。你可以修改 `alarmtest.c` 以帮助调试,但确保原始的 `alarmtest` 说所有测试都通过。
根据提示,首先在proc结构体中添加相应字段
int duration; // 距离上次报警经过的 ticks 数
int alarm; // 每隔多少 ticks 触发一次报警
uint64 handler; // 存储报警处理函数的地址
struct trapframe *alarm_trapframe; // 存储了报警时的寄存器状态在 proc.c 的 allocproc() 中初始化 proc 的字段
if((p->alarm_trapframe = (struct trapframe *)kalloc()) == 0){
freeproc(p);
release(&p->lock);
return 0;
}
p->duration=0;
p->alarm=0;
p->handler=0;并且在freeproc()中也要加上这些字段
if(p->alarm_trapframe)
kfree((void*)p->alarm_trapframe);
p->alarm_trapframe = 0;
p->alarm=0;
p->duration=0;
p->handler=0;之后实现sys_alarm函数,将相关信息填入proc中
uint64
sys_sigalarm(void)
{
int ticks;
uint64 handler;
argint(0, &ticks);
argaddr(1, &handler) ;
struct proc* p = myproc();
p->alarm = ticks;
p->handler = handler;
p->duration = 0;
p->alarm_trapframe = 0;
return 0;
}
根据提示可以知道当which_dev == 2时发生了时钟中断,用户程序运行了1个ticks,而sigalarm实现当用户程序运行了n个ticks后,触发一次回调函数。那么在usertrap中,当发生时钟中断时,将p->duration增加,如果p->duration == p->alarm,那么就要触发一次回调函数,而触发的方法就是将p->trapframe->epc设置为回调函数地址,当陷阱处理程序结束后就会跳转到回调函数。注意这里要根据p->alarm_trapframe 是否等于0来判断是否正在进行处理程序,因为如果处理程序尚未返回,内核不应再次调用它。
if(which_dev == 2){
if(p->alarm != 0){
if(++p->duration == p->alarm){
p->duration = 0;
if(p->alarm_trapframe ==0){
p->alarm_trapframe = kalloc();
memmove(p->alarm_trapframe, p->trapframe, sizeof(struct trapframe));
p->trapframe->epc = p->handler;
}
}
}
yield();
}最后就是sigreturn函数,这个函数要做的工作就是将之前保存的alarm_trapframe还原到trapframe中,并将alarm_trapframe释放掉。
uint64
sys_sigreturn(void)
{
struct proc* p = myproc();
if(p->alarm_trapframe != 0){
memmove(p->trapframe, p->alarm_trapframe, sizeof(struct trapframe));
kfree(p->alarm_trapframe);
p->alarm_trapframe = 0;
}
return 0;
}