python蓝桥杯复习
列表
列表添加操作
list1 = ['1','3','3','8']
list1.append('9') #在列表末尾添加一个元素
list2 = ['10','11'] #在列表末尾一次性添加一个或多个元素
list1.extend(list2)
list1.insert(1,2) #在索引为1的位置添加元素2,在任意位置添加一个元素
print('切片前:',list1)
list3 = ['新','列','表']
list1[0:] = list3 #整体替换索引为一一直到最后的数据元素
print('切片后',list1)

列表删除操作
list1 = ['1','3','3','8','9','11','15']
list1.remove('3') #移除列表一个元素,如果有重复,只移除第一个
print(list1)
list1.pop(1) #移除列表指定索引的元素,如果没说索引,删除最后一个元素
list1.pop()
print(list1)
list1[2:] = [] #删除原列表内容
print(list1)

列表的修改
list1 = ['1','3','3','8','9','11','15']
print(list1)
list1[2:3] = ['四','五','六']
print(list1)

列表的排序
list1 = ['1','3','3','80','52','五','四']
list1.sort()
print(list1)
list1.sort(reverse = True) #默认参数reverse = False,改成 = True就是降序排列
print(list1)

字典
什么是字典


字典的创建

dict1 = {'张三' : 100,'李汜' : 98}
dict2 = dict(name = '王五',age = 20)
print(dict1)
print(dict2)

字典的获取
dict1 = {'张三' :100,'李汜':98,'王五':56}
print(dict1['张三'])
#print(dict1['六六']) #会报错KeyError
print(dict1.get('张三'))
print(dict1.get('六六')) #不会报错

字典的增删改
dict1 = {'张三' :100,'李汜':98,'王五':56}
print(dict1)
del dict1["张三"]
print(dict1)
dict1.clear() #清空
print(dict1)
dict1['赵六']=65
print(dict1)
dict1['赵六']=9999
print(dict1)

排序 学习
sorted函数:
a = sorted(iterable,key = None,reverse = False)
#iterable是一个可迭代的对象
#key
#reverse是排序规则
#a是返回值
#与sort函数比可以部分排序,但不能在原数据排序,会创建新的地址
sort函数
a = [5,56,32,441,28,356]
b = sorted(a)#创建新列表
print(a)
print(b)
a.sort(reverse = True) #列表不变
print(a)
a = "asdwx"
b = sorted(a)
print(b) #sorted可以对其他类型排序,sort只能对列表
结果如下:

sorted的使用
a = [('b','A',15),('c','B',12),('e','B',10)]
b = sorted(a,key = lambda s:s[0]) #按照第1个排序,默认升序
print(b)
b = sorted(a,key = lambda s:s[1])
print(b)
b = sorted(a,key = lambda s:s[2])
print(b)
结果如下:

部分排序:
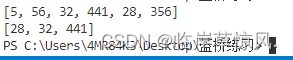
a = [5,56,32,441,28,356]
b = sorted(a[2:5])
print(a)
print(b)
例题:小蓝要把一个字符串中字母按照字母表顺序排序。请问对于WHERETHEREISAWILILTHEREISAWAY,排序后字符串为:
a = 'WHERETHEREISAWILILTHEREISAWAY'
b = sorted(a)
print(b)
![]()
例题:某次科研调查得到n个自然数。已知不同数不超过10000个,现在需要统计这些自然数出现个数,并按照从小到大排序。
输入描述:第一行是整数n,表示自然数个数,。第2~n行每行一个自然数。1≤n≤2*100000,每个数不超过1500000000
输出描述:输出m行(m为n个自然数不同数的个数,按照从小到大顺序输出。每行输出两个整数,分别是自然数和出现次数,中间用空格分开)
超时代码:
n = int(input())
nums = []
for i in range(n):
nums.append(input())
new_nums = sorted(set(nums))
print(new_nums)
for i in new_nums: #O(n)*O(n)
print(i,nums.count(i))
输入:

输出:
正确得分:
n = int(input())
dict1 = {}
for i in range(n):
x = int(input())
if x in dict1.keys():
dict1[x] += 1
else:
dict1[x] = 1
list1 = sorted(dict1.keys())
for i in list1:
print(i,dict1[i])
结果:

例题:某涉密单位下发了某种票据,并要在年终全部收回。每张票据有唯一的ID号。全年所有数据的ID号是连续的,造成了某个ID断号,另一个ID重号。你的任务是通过编程呢个,找出断号的ID和重号的ID。假设断号不能发生在最大和最小号上。
输入描述:要求首先输入一个整数N(N<100)表示后面数据行数。接着读入N行数据。每行数据长度不等,是用空格分开的若干个(不大于100个)正整数(不大于100000)。
输出描述:要求输出一行,含有两个整数m,n,用空格分开。其中m表示断号ID,n表示重号ID
#split()方法含义:
#是将指定字符串按某指定的分隔符进行拆分,拆分将会形成一个字符串的数组并返回。
#数组中的每元素都各自对应一个索引值,就好比在数据库的表中每行数据纪录都拥有自己的索引ID一样数组元素的索引值是从0开始计数的,也就是说第一个元素的索引值是0,往后依次加1
超时代码:(循环改成相邻两数相减)
n=int(input())
list1 = []
for i in range(n):
x = input().split()
for j in range(len(x)):
list1.append(int(x[j]))
print(list1)
list2 = sorted(list1)
for i in range(list1[0],list1[0]+len(list1)):
if i not in list1: m = i
if list1.count(i) == 2: n = i
print(m,n)
结果如下:

n=int(input())
list1 = []
for i in range(n):
x = map(int,input().split())
list1.extend(x)
list1.sort()
for i in range(list1[0],list1[0]+len(list1)-2):
if list1[i+1] - list1[i] == 2:
m = list1[i] + 1
elif list1[i+1] - list1[i] == 0:
n = list1[i]
print(m,n)
结构体排序
每个学生有三门课成绩:语文数学英语,先按总分从高到低排名,如果总分相同先按语文从高到低排序,如果还一样,那么规定学号小的同学排在前。排序是唯一的
任务:在根据输入的成绩计算总分,然后按排名输出前五名同学的学号和总分。
n = int(input())
list1 = []
for i in range(n):
num = i+1
x = list(map(int,input().split())) #map(int, )是将后边转换成int类型。
list1.append([num,sum(x)] + x)
index = reversed((1,2,0)) #按总分,语文,学号顺序排序
for i in index:
list1.sort(key = lambda x:x[i],reverse = True)
for i in range(5):
print(list1[i][0],list1[i][1])
结果如下:

排列和组合
irertools.permutations(iterable,r = None)函数
功能:连续返回由iterable序列中的元素生成的长度为r的排序
如果r未指定或为None,r默认设置为iterable的长度,即生成包含所有元素的全排列
排列:
from itertools import *
s = ['a','b','c']
for element in permutations(s,2):#elemen就是一个参数,可以换
a = element[0] +element[1] #或a = ''.jion(element)
print(a,end=' ')

手写排列:
例题1:从{1,2,3,4}中选3个排列,有24种:
s = [1,2,3,4]
for i in range(4):
for j in range(4):
if s[i]!=s[j]:
for m in range(4):
if s[m] != s[j] and s[i] !=s[m]:
print("%d%d%d"%(s[i],s[j],s[m]),end = ' ')
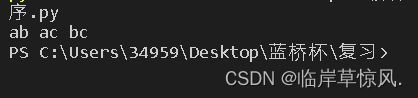
组合:
from itertools import *
s = ['a','b','c']
for element in combinations(s,2):
a = element[0] +element[1]#或a = ''.jion(element)
print(a,end=' ')
如果要去重,用集合,s用{}表示(此时输出是随机的,平常是按照位置输出):
from itertools import *
s = {'a','b','c','c'}
for element in combinations(s,2):
a = element[0] +element[1]#或a = ''.jion(element)
print(a,end=' ')

手写组合:
s = [1,2,3,4]
for i in range(4):
for j in range(i+1,4):
for m in range(j+1,4):
print("%d%d%d"%(s[i],s[j],s[m]),end = ' ')

二分法
时间复杂度:O(logn)
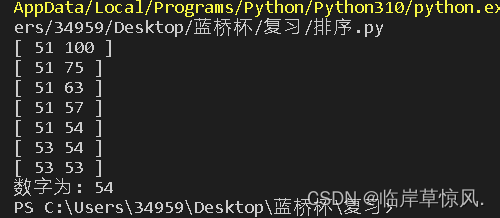
def bin_search(n,a,num):
l = 0
r = n
while(l < r):
mid = (l + r)//2
if(a[mid] >= num):r = mid
else:l = mid + 1
print('[',l,r,']')
return l
n = 100
a = [i for i in range(1,101)]
num = 54
pos = bin_search(n,a,num)
print("数字为:",a[pos])
前缀和,差分
sum = [0]*n意思是长度为n,全部为0