2024-02-07(Sqoop,Flume)
1.Sqoop的增量导入
实际工作中,数据的导入很多时候只需要导入增量的数据,并不需要将表中的数据每次都全部导入到hive或者hdfs中,因为这样会造成数据重复问题。
增量导入就是仅导入新添加到表中的行的技术。
sqoop支持两种模式的增量导入:
append模式:根据数值类型字段进行追加导入,大于指定的last-value值
Lastmodified模式:根据时间戳类型的字段进行追加,>=指定的last-value
注意,在Lastmodified模式下,还分为两种形式:append(附加),merge-key(合并)两种模式来添加。
merge-key做了两件事:如果数据有变化,会将变化的数据同步过来;如果有新增的数据,也会把新增的数据同步过来。还避免了append模式数据同步的问题,它的功能更加强大。
2.Sqoop导出
将数据从HDFS生态体系导出到RDBMS数据库前,目标表必须存在于目标数据库中。
导出有三种模式:
a.默认模式:Sqoop将文件中的数据使用insert语句插入到表中。
b.更新模式:Sqoop将生成updata替换数据库中现有记录的语句。
c.调用模式:Sqoop将为每条记录创建一个存储过程调用。
数据导出注意事项:导出的目标表需要自己手动提前创建,也就是sqoop并不会帮我们创建复制表的结构。
3.Sqoop中可以创建Job作业,执行Job,其目的不外乎还是用来导入导出数据。
4.Sqoop免密执行Job作业。
-------------------------------------------------------------Flume------------------------------------------------------------
5.Flume概述
Flume是一个分布式、高可用、高可靠的海量日志采集、聚合和传输的系统,支持在日志系统中定制各类数据发送方,用于收集数据,同时提供了对数据进行简单处理并写到各种数据接收方的能力。
Flume的设计原理是基于数据流的,能够将不同数据源的海量日志数据进行高效收集、聚合、移动,最后存储到一个中心化数据存储系统中。
Flume能够做到近似实时的推送,并且可以满足数据量是持续并且数量级很大的情况。比如它可以收集社交网站的日志,并将这些数量庞大的日志数据从网站服务器上汇集起来,存储到HDFS或者HBase分布式数据库中。
(注意:数据流中的流字,可以理解为不停的处理,就跟水流一样,不间断)
6.Flume的应用场景:
比如一个电商网站,想从网站的访问者中访问一些特定的节点区域来分析消费者的购物意图和行为。为了实现这一点,需要收集消费者访问的页面以及点击的产品等日志信息,然后移交到大数据Hadoop平台上去分析,可以利用Flume做到这一点。现在流行的内容推送,比如广告定点投递以及新闻私人定制也是基于这个道理。
7.Flume架构

几个概念:
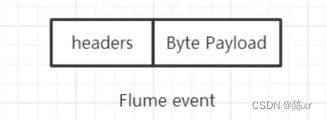
Event:Event/事件是Flume内部数据传输的最基本单元,将传输的数据进行封装。事件本身是由一个装有数据的字节数组和可选的headers头部信息构成的,如下图所示。Flume以事件的形式将数据从源头传输到最终的目的地。
Agent: Flume Agent是一个JVM进程,通过三个组件(Source,Channel,Sink)将事件流从一个外部数据源收集并发送给下一个目的地。
Source:从数据发生器接收数据,并将数据以Flume的Event格式传递给一个或者多个通道/channel。
Channel:通道是一种短暂的存储容器,位于Source和Sink之间,起到一个桥梁的作用。Channel把从 Source处拿到的Event格式的数据缓存起来,当Sink成功的将Event发送到下一跳的Channel或者最终的目的地之后,Events便从Channel中移除。
Channel是一个完整的事务,这一点保证了数据在收发的时候的一致性。
可以把Channel看作一个FIFO/先进先出队列,当数据的获取速率超过流出速率时,将Event保存到队列中,再从队中一个一个的出来。
Channel的形式也有很多种:Momery channel,File channel,Kafka channel等。
Sink:获取channel暂时保存的数据并进行处理。sinkc从channel中移除事件,并将其发送到下一个agent(简称下一跳)或者事件的最终目的地,比如HDFS中。
8.Flume整体过程简要描述:
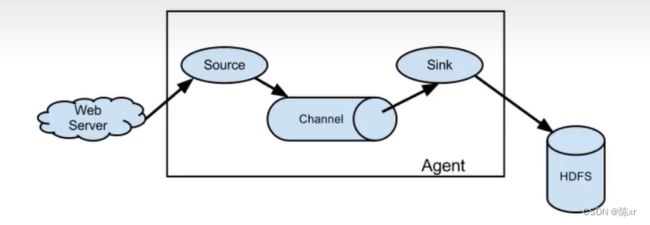
1)外部数据源(Web Server)将Flume可识别的Event发送到Source。
2)将Source收到Event事件后存储到一个或者多个Channel通道中。
3)Channel保留Event直到Sink将其处理完毕。
4)Sink从Channel中取出数据,并将其传输至外部存储(如HDFS)
9.Flume的可靠性:
事件在每个agent中的channel中短暂的存储,然后事件被发送到下一个agent或者最终的目的地。事件只有存储在下一个channel或者最终存储后才从当前的channel中删除。
Flume使用了事务的办法来保证Events的可靠性。(只有下一个“地点”明确的接收到了数据,才将上一个“地点”中的数据移除)