【持续更新】Segment Anything Model (SAM)分割一切大模型相关论文和项目介绍
距离Meta AI 发布首个分割一切大模型SAM已经过去半年左右的时间了,该模型在分割任务上,尤其是零样本分割任务上取得了令人惊讶的优异表现,受到了整个CV界的广泛关注。基于SAM的各种改进版本、二创作品和工具不断涌现,本篇博客就记录自己在学习这些论文和项目过程中的一些理解和体会,并把相关的资源做一个简单的整理,方便大家去学习和尝试。
1. SAM
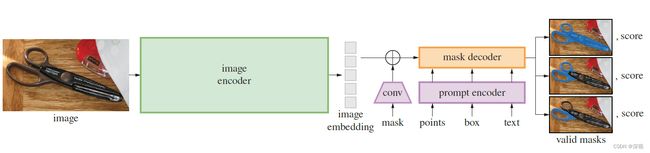
SAM的原始论文《Segment Anything》网上的分析和介绍已经非常多,我就不再重复了,这里只是简单的整理下相关的资源:
- 【论文链接】:https://arxiv.org/abs/2304.02643
- 【项目链接】:https://github.com/facebookresearch/segment-anything
- 【Demo链接】:https://segment-anything.com/demo
- 【论文解读】:https://www.yii666.com/blog/476264.html
2. PerSAM

《Personalize Segment Anything Model with One Shot》中提出一种基于SAM的个性化分割方法,使用者只需要提供一张待分割目标的参考图像和其对应的分割掩码,就可以在一张测试图像中准确分割出特定的目标物体。作者利用SAM的编码器分别对参考图像和测试图像提取特征图,参考图像的特征图经过掩码和池化操作后得到一个特征向量,计算特征向量与测试图像特征图每个像素之间的余弦相似度,将相似度最高的点和最低的点分别作为前景和背景提示点(Prompt),将其输入到SAM的Prompt编码器中引导实现特定目标的分割。此外,作者还提出了目标语义提示(Target-semantic Prompting),级联的后优化(Cascaded Post-refinement)等改进措施,并提出一个微调模型PerSAM-F,只需花费10秒时间,对两个权重参数进行微调训练,就能显著改善掩码尺度歧义的问题。
比如提示点在一个人所穿着衬衫的图案上,那分割对象到底是人,还是衬衫,还是图案?这就是掩码尺度歧义问题,这个问题在SAM中也做了专门的研究
总体而言,PerSAM解决了SAM无法对特定目标进行分割的问题,只需要One-shot,且无需训练就能实现特定目标的分割,在很多的应用中还是非常具有潜力的。但PerSAM只能对测试图像中一个目标进行分割,而不能对多个相同目标,甚至一类目标进行分割。
- 【论文链接】:https://arxiv.org/abs/2305.03048
- 【项目链接】:https://github.com/ZrrSkywalker/Personalize-SAM
- 【Demo链接】:https://huggingface.co/spaces/justin-zk/Personalize-SAM
- 【论文解读】:https://blog.csdn.net/a486259/article/details/131844692
3. Counting-SAM

《CAN SAM COUNT ANYTHING? AN EMPIRICAL STUDY ON SAM COUNTING》中提出一种基于SAM实现小样本目标计数的方法,使用者提供一张测试图片,并在图片中框选出1-3个待计数的目标物体,该方法可以给出图片中目标物体的总个数。实现过程也比较简单,作者使用SAM的编码器提取图片特征,并利用给定的目标框作为提示,实现目标物体的分割。将分割掩码与特征图相乘得到目标物体的特征,并取平均值得到特征向量。然后,对测试图片利用32*32的网格提示点,实现全分割,按照上面的过程计算处所有分割结果对应的特征向量,并计算每个特征向量与目标物体特征向量之间的余弦相似度,相似度大于阈值的分割结果即认为属于目标物体的类别,最后统计所有属于目标物体类别的分割结果的数量。
这个思路非常简单、直接,但实验结果来看效果并不是很好,在物体体积比较大,数量比较少的情况下,计数准确率还可以,但当目标小、数量多且存在重叠的复杂情况时,这种方法就难以满足要求了。本身SAM对于小目标的分割效果就不太完美,容易将多个同类小目标识别为一个大目标物体,另外仅利用特征的余弦相似度筛选目标物体,也过于简单,容易误判。
- 【论文链接】:https://arxiv.org/abs/2304.10817
- 【项目链接】:https://github.com/Vision-Intelligence-and-Robots-Group/count-anything?utm_source=catalyzex.com
- 【Demo链接】:https://huggingface.co/spaces/nebula/counting-anything
- 【论文解读】:https://zhuanlan.zhihu.com/p/623289122
4. SAM-Adapter

《SAM Fails to Segment Anything? – SAM-Adapter: Adapting SAM in Underperformed Scenes: Camouflage, Shadow, Medical Image Segmentation,and More》该文指出号称可以“分割一切”的SAM模型虽然在自然图像的通用分割任务中取得了优异的效果,但在许多特殊图像的特定分割任务上表现差强人意,如水下目标分割、阴影分割、伪装对象分割等。作者认为这是由于SAM主要在常见的自然图像中进行训练,其特征提取器不能很好的适应特殊图像。因此作者提出一种轻量化的适配器模块(Adaptor),对SAM的编码器得到的特征图进行适应性调整。编码器的输入为特定任务信息,该文采用了图块嵌入特征和高频成分特征,将两种特征相加后经过两个MLP层得到适配器模块的输出,并将该输出与对应SAM编码器的Transformer层输出相加,并传递至下一层。训练过程中SAM编码器的参数保持不变,解码器部分使用SAM的参数进行初始化,然后利用特定数据集进行微调。
该文提出的Adaptor模块包括所使用的两个特定任务信息——图块嵌入特征和高频成分特征,都是来源于另一篇论文《Explicit Visual Prompting for Low-Level Structure Segmentations》(EVP)。图块嵌入特征就是将图片划分成若干个图块,利用ViT将其映射为一个 C s e g C_{seg} Cseg维的特征;高频成分特征,则是将图片进行快速傅里叶变换,并保留其中的高频成分,再进行反变换得到高频成分对应的时域图,最后经过一个线性映射层得到一个特征向量。
实验表明,在多个任务中SAM-Adapter均取得了远超SAM的表现,甚至由于各自领域的其他优秀算法,作为SAM的一种改进思路还是有值得借鉴和学习的地方。然而,整篇论文的思路几乎完全照搬了EVP,只是将模型从SegFormer换成了SAM,其他并没有明显改变。但在实验章节的算法效果对比中却回避了EVP,尤其是有些结果还不如EVP,这就很让人质疑其原创性和先进性。
- 【论文链接】:https://arxiv.org/abs/2304.09148
- 【项目链接】:https://github.com/tianrun-chen/SAM-Adapter-PyTorch
- 【论文解读】:https://zhuanlan.zhihu.com/p/650109201?utm_id=0
5. EviPrompt
《EviPrompt: A Training-Free Evidential Prompt Generation Method for Segment Anything Model in Medical Images》该文提出一种无需训练的自动提示生成方法,结合SAM可用于医学领域图像的分割任务。SAM虽然分割能力十分强大,但需要人工给出提示却严重制约了他的应用,尤其是在医学领域,提示点的给出需要依赖医学专家的经验。而且由于SAM是在自然图像中训练得到的,与医学图像之间存在较大差异,无法利用医学图像自身的先验知识。为解决上述问题,作者提出了一种基于证据学习(Evidential Learning)的自动提示生成方法,并且引入了医学图像所具备的两个特点作为先验知识:1. 语义信息不随图像的光度变换或几何变换而变化;2.对于同种类型和类别的医学图像通常都非常相似。

首先,作者将目标图像 x t o x^o_t xto,分别进行光度变换和几何变换得到变换后的图像 x t p , x t g x^p_t,x^g_t xtp,xtg,并且与参考图像 x r x_r xr按照2*2的结构拼成一张大图。在大图上生成均匀的网格点作为提示点一起输入到SAM模型中,将Mask Decoder中分类头前的最后一层特征图提取出来划分为 F r , F t o , F t p , F t g F_r, F_t^o, F_t^p, F_t^g Fr,Fto,Ftp,Ftg分别对应输入的四个图像。根据参考图像对应的掩码图,对 F r F_r Fr中的特征点进行聚类,并得到各个类别的聚类中心作为锚点 { g k , n } n = 1 N k \{g_{k,n}\}_{n=1}^{N_k} {gk,n}n=1Nk。逐像素的计算目标特征图和各个锚点之间的相似度,并选取相似度最大的类别作为该像素的证据(evidence),如下式: e k [ i ] = max n σ ( F [ i ] T g k , n ) e_k[i]=\max_n\sigma(F[i]^Tg_{k,n}) ek[i]=nmaxσ(F[i]Tgk,n)其中 σ \sigma σ表示激活函数如SoftPlus来保证计算得到的证据是非负的。根据计算得到的证据,可以得到相应的观点(opinion) M = { b 1 , . . . , b K , u } M=\{b_1,...,b_K,u\} M={b1,...,bK,u},其计算过程如下 b k = e k S , u = K S b_k=\frac{e_k}{S},u=\frac{K}{S} bk=Sek,u=SK其中 K K K表示类别数量, S = ∑ k = 1 K ( e k + 1 ) S=\sum_{k=1}^K(e_k+1) S=∑k=1K(ek+1)表示狄利克雷强度。将目标图像和两个变换后的目标图像对应的三个观点 M o , M p , M g M^o,M^p,M^g Mo,Mp,Mg进行融合,融合方式如下假设有两个观点 M 1 = { b 1 1 , . . . b k 1 , u 1 } , M 2 = { b 1 2 , . . . b k 2 , u 2 } M^1=\{b_1^1,...b_k^1,u^1\},M^2=\{b_1^2,...b_k^2,u^2\} M1={b11,...bk1,u1},M2={b12,...bk2,u2},融合后的 M = M 1 ⊕ M 2 = { b 1 , . . . , b K , u } M=M^1\oplus M^2=\{b_1,...,b_K,u\} M=M1⊕M2={b1,...,bK,u},其中 b k = 1 1 − C ( b k 1 b k 2 + b k 1 u 2 + b k 2 u 1 ) , u = 1 1 − C u 1 u 2 b_k=\frac{1}{1-C}(b_k^1b_k^2 + b_k^1u^2 + b_k^2u^1), u=\frac{1}{1-C}u^1u^2 bk=1−C1(bk1bk2+bk1u2+bk2u1),u=1−C1u1u2 C = ∑ i ≠ j b i 1 b j 2 C=\sum_{i\neq j}b_i^1b_j^2 C=∑i=jbi1bj2表示两个观点之间的冲突。融合后的观点为 M = M o ⊕ M p ⊕ M g M=M^o\oplus M^p \oplus M^g M=Mo⊕Mp⊕Mg,其中每个点都代表该点属于某个类别的置信度,选取每个类别置信度最大的点作为该类别的提示点。
实验表明,该方法给出的提示结果在很多情况下并不能取得非常优秀的分割效果,甚至不如原始的SAM,但这篇文章还是给出了一个有价值的思路——利用证据学习的方式来寻找提示点,仅需一张带有分割掩码的参考图像,而无需训练。
- 【论文链接】:https://arxiv.org/pdf/2311.06400.pdf
6. T-Rex
《T-Rex: Counting by Visual Prompting》该文提出一种基于SAM实现目标物体计数的方法,与前文提到的Counting-SAM功能类似,但性能有显著提升。它的核心思想与SAM相似,通过与人类的交互实现计数。首先给定一个目标图像和参考图像(二者可以是同一幅图),利用图像编码器得到对应的视觉特征。然后,手动从给定的图像中,通过点选或者画框的方式标记出待计数的目标物体作为提示,经过提示编码器得到相应的视觉提示。将视觉特征和视觉提示同时输入到解码器中得到目标物体的检测框和对应的置信度得分。最后,利用置信度过滤掉得分较低的检测结果,统计检测框的数量得到计数结果。

该方法不仅支持正样本提示输入,还可以在初步分割计数的基础上,通过与人类交互,给出被误检对象作为负样本提示,进一步提升计数的准确性。作者还制作了一个大规模的计数数据集CA-44,用于评估计数算法的性能。
- 【论文链接】:https://arxiv.org/abs/2311.13596
- 【项目链接】:https://github.com/IDEA-Research/T-Rex
- 【Demo链接】:https://deepdataspace.com/playground/ivp
7. EfficientSAM
《EfficientSAM: Leveraged Masked Image Pretraining for Efficient Segment Anything》该文提出一种高效的SAM模型,利用掩码图像预训练方法对小模型编码器(ViT-Tiny或ViT-Small)进行训练。首先,输入图像经过分块和掩码后输入到一个轻量级的小型编码器中,得到未被掩码部分的特征(Unmasked Embeddings)作为锚点,与掩码部分的Tokens一起输入到一个交叉注意力解码器中,用于预测掩码部分对应的特征。将输出的掩码部分特征和输入的未被掩码部分的特征组合起来,并进行重新排序,就得到了完整图像所对应的重建特征。重建特征经过一个线性映射层调整通道数后,与原SAM中ViT-H编码器输出的特征进行比较,并利用L2损失函数计算重建损失,用于训练轻量级编码器,交叉注意力解码器和线性映射层。训练过程在ImageNet-1K数据集上进行。经过预训练后,轻量级小型编码器将取代SAM中的图像编码器部分,而其他部分不变,继续在SA-1B数据集上进行微调训练,得到最终的EfficientSAM模型。

该方法的模型参数和推理时间只有SAM的1/20,但分割效果仅有微弱的下降,在众多任务中均超过MobileSAM和FastSAM的表现。
- 【论文链接】:https://arxiv.org/pdf/2312.00863
- 【项目链接】:https://yformer.github.io/efficient-sam/
- 【Demo链接】:https://huggingface.co/spaces/yunyangx/EfficientSAM
- 【论文解读】:https://baijiahao.baidu.com/s?id=1784589123096664586&wfr=spider&for=pc
8. AI-SAM
《AI-SAM: Automatic and Interactive Segment Anything Model》 该文提出一种可自动生成提示并且可交互的分割方法。常见的自动分割方法,通常在一个特定的数据集上进行训练,训练好的模型无需任何提示即可对学习过的类别进行分割预测。而以SAM为代表的交互式分割方法,则无需在特定数据集上进行训练,但在预测时需要人工给定提示。模型在分割预测时是缺少语义信息的,即并不知道分割的对象是什么。为了结合这两种分割方法的优点,作者提出了一种AI-Prompter模型,通过在特定数据集上进行训练,可以根据输入图像,预测对应类别的提示点位置,并将其输入到SAM模型的提示编码器和掩码解码器中得到分割结果。使用者可以根据分割结果对预测的提示点进行删改,以保证提示点的正确性。.
AI-Prompter模型的输入是待处理图像的特征信息 X X X和待分割区域的类别信息 c c c,输出的是一组权重 W W W。其中每个权重值都对应图像中的一个点的位置编码 p p p,将所有点的位置编码进行加权求和就得到最终预测的提示点坐标 P g = W T P P^g=W^TP Pg=WTP,作者称之为“广义点”。训练时遵循两个启发式原则:1. 提示点应该在目标物体的内部, 2.提示点应该近似一个独热(one-hot)的点提示。

该方法虽然能够自动生成提示,但在训练过程中仍需要大量有标签数据,并且只能对学习过的特定类别目标进行预测,不具备开放类别的预测能力。而且其编码和分割效果完全取决于SAM自身的能力,因此其实际的应用价值还有待探索。
- 【论文链接】:https://arxiv.org/abs/2312.03119
- 【项目链接】:https://github.com/ymp5078/AI-SAM
- 【Demo链接】:https://github.com/ymp5078/AI-SAM/blob/main/automatic_interactive_demo.ipynb
9. HQ-SAM
《Segment Anything in High Quality》该文在SAM的基础上提出一种更加高质量的分割模型,提升了细节结构上的分割效果。为保留了SAM本身的零样本迁移能力,降低训练的复杂度,SAM原有的图像编码器、提示编码器和掩码解码器保留,并冻结了参数。改进的点主要有两个:1. 在原本Prompt Token和Output Token的基础上,增加了HQ-Output Token作为掩码解码器的输入,经过两层解码器的处理和自注意力层与image-to-token和token-to-image注意力层,得到更新后的HQ-Output Token;2.增加了全局和局部特征融合模块,将编码器第一个全局注意力块的输出和最后一层的全局特征,以及掩码解码器的掩码特征经过上采样统一尺寸和卷积处理后,逐元素累加起来得到HQ-Features。最终更新后的HQ-Output Token经过MLP处理和HQ-Features点乘得到分割预测结果。

相比于SAM,HQ-SAM只增加了约0.5%的参数量,并且可以在普通的3090设备上进行训练,而在多个数据集上的分割效果都有了一定程度的提升。
- 【论文链接】:https://arxiv.org/abs/2306.01567
- 【项目链接】:https://github.com/SysCV/SAM-HQ/
- 【Demo链接】:https://colab.research.google.com/drive/1QwAbn5hsdqKOD5niuBzuqQX4eLCbNKFL?usp=sharing
- 【论文解读】:https://blog.csdn.net/Transfattyacids/article/details/132253
9. FastSAM
《Fast Segment Anything》该文提出一种快速的SAM模型,可实现实时的图像分割。作者将SAM的处理过程解耦为两个部分:1.对所有物体进行分割(All- instance Segmentation);2. 根据提示选择被分割的目标对象(Prompt-guided Selection)。为了提升分割的速度,作者使用YOLOv8-seg作为分割模型,对图像中的所有物体进行分割。在YOLOv8-seg模型中特征提取网络采用CNN+FPN模型,取代了SAM中最为耗时的ViT模型。在解码阶段包含两个平行的分割分支和检测分支,其中检测分支输出类别和边界框,分割分支输出 K K K个原型和 K K K个掩码置信度。原型网络输入高分辨率特征图,保留空间细节,并包含语义信息。该特征图经过卷积层处理,上采样,然后通过另外两个卷积层输出掩码。将掩码与置信度相乘并求和得到实例分割结果。最后,根据输入的提示,从全部分割结果中选取对应的目标掩码作为输出。对于点提示,则选取提示点所在位置对应的分割结果,若对应多个分割结果,则根据给定的背景提示点进行筛选;对于框提示,则选取分割结果中与提示框交并比最大的目标掩码作为输出;对于文本提示输入,利用CLIP模型将其转化为图像特征,并计算与所有分割结果特征之间的相似性,选取最相似的分割掩码作为结果。

FastSAM仅需原SAM的2%数据量进行训练,处理速度可达到SAM的50倍,而取得了与SAM接近的分割效果。
- 【论文链接】:https://arxiv.org/abs/2306.12156
- 【项目链接】:https://github.com/casia-iva-lab/fastsam
- 【Demo链接】:https://huggingface.co/spaces/An-619/FastSAM
- 【论文解读】:https://zhuanlan.zhihu.com/p/640799074
10. MobileSAM
《Faster Segment Anything: Towards Lightweight SAM for Mobile Applications》该文提出一种基于知识蒸馏的SAM加速方法。作者发现在SAM中图像编码器具有632M参数量,占用了主要的计算量和处理时间,因此希望使用一个高效的轻量化模型来取代现有的图像编码器。相比而言提示编码器和掩码解码器只占用很小的计算量,因此作者选择保留原有的提示编码器和掩码解码器,以保证分割的质量。为实现知识蒸馏过程的有效训练,作者提出一种完全解耦的知识蒸馏方法。将图像编码器和后续的提示编码器与掩码解码器完全分离开,在知识蒸馏过程中仅对图像编码器进行训练。作者选用Tiny-ViT作为轻量化图像编码器模型,仅用0.1%的SA-1B数据集,在单张GPU上就完成了蒸馏学习。至于是否需要对提示编码器与掩码解码器进行微调训练,作者发现必要性并不大,知识蒸馏得到的编码器能够很好地与原解码器部分进行对齐。
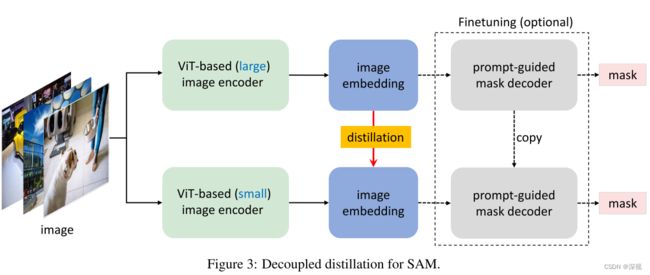
MobileSAM的参数量比SAM少60倍,比FastSAM少7倍,单张图片的处理速度比SAM快60倍,比FastSAM快5倍,但取得了优于FastSAM,接近SAM的分割效果。
- 【论文链接】:https://arxiv.org/pdf/2306.14289.pdf
- 【项目链接】:https://github.com/ChaoningZhang/MobileSAM
- 【Demo链接】:https://huggingface.co/spaces/dhkim2810/MobileSAM
- 【论文解读】:https://zhuanlan.zhihu.com/p/639924258
11. PA-SAM
《PA-SAM: Prompt Adapter SAM for High-Quality Image Segmentation》该文提出一种提示驱动的适配器(prompt-driven adapter)来改善SAM的分割效果。整体而言,作者做了两部分工作,首先是提出一种自适应的细节强化方法(Adaptive Detail Enhancement),其对稠密提示进行补充并对稀疏提示进行优化。作者指出在图像编码阶段经过一个16倍的下采样,已经丢失了许多的细节信息,因此必须对其进行补充。作者将原图和原图对应的梯度图作为输入,经过一个CNN网络进行编码作为引导信息,将其和原本的图像编码 x x x一起经过一致表示模块(consistent representation module,CRM)进行处理得到补充后的稠密提示 x p a = C R M ( W g [ I , ∇ I ] , x ) x_{pa}=CRM(W_g[I,\nabla I],x) xpa=CRM(Wg[I,∇I],x)。CRM可以通过交叉注意力机制或guided gate的形式实现。
在SAM中,稠密提示是指使用Mask作为提示,当输入的Mask为空时,则使用图像的Embedding作为默认的稠密提示。作者绘制的流程图中,没有看到稠密提示到Prompt Adapter的连线,不知道是遗漏了,还是因为线条过于复杂就省略了。
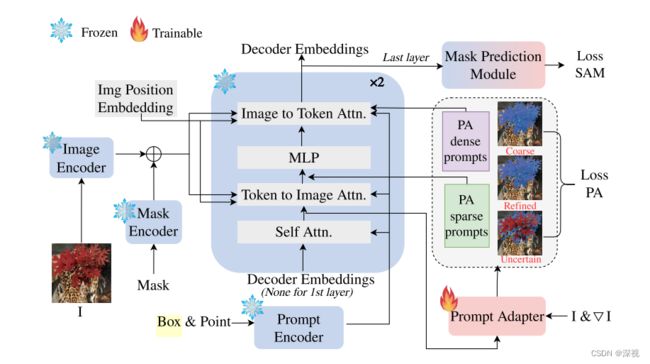
得到稠密提示 x p a x_{pa} xpa后,将其作为key和value,并使用原本输入的稀疏提示 t i n t_{in} tin作为query,经过一个token-to-image注意力层得到优化后的稀疏提示 t p a t_{pa} tpa。此外,作者还定义了一个不确定token和精细化token分别用于识别图像中难以分割的区域并对其进行分割。这两个token是将原本的mask token和对应的static token级联后经过一个MLP得到的。
这里的static token我不太清楚是指什么,我猜测是没有经过self Attention层的最初输入的mask token?

原本粗糙的分割掩码 M C M_C MC,不确定分割掩码 M U M_U MU和精细化分割掩码 M R M_R MR按照下式计算得到最终的分割掩码 M P A M_{PA} MPA M P A = M U ∘ M R + ( 1 − M U ) ∘ M C M_{PA} = M_U\circ M_R+(1-M_U)\circ M_C MPA=MU∘MR+(1−MU)∘MC
上述内容介绍了第一部分工作——自适应的细节强化,下面介绍第二部分工作难点挖掘(Hard Point Mining)。这部分的想法是在原有稀疏提示(点或框)的基础上,寻找对困难区域更有帮助的提示点,一起作为提示用于模型的分割预测。我们以正样本提示点为例,假设正样本点数量为 N N N,则新的提示点按照下述过程进行计算

首先根据 M C M_C MC, M R M_R MR, M U M_U MU计算出初始采样引导 ϕ 0 \phi^0 ϕ0,并按照上式依次计算 ϕ n , n ∈ N \phi^n,n\in N ϕn,n∈N, γ ∽ G u m b e l ( 0 , 1 ) \gamma \backsim Gumbel(0,1) γ∽Gumbel(0,1)。 g n g^n gn表示当前样本的Softmax输出
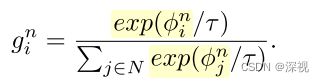
计算所有 g n g^n gn的总和 g ′ g' g′作为top-k Softmax概率,并按照下式选取新的提示点

s g sg sg表示stop gradient 操作。新的提示点记为 p s a m p l e p_{sample} psample,则完整的稀疏提示输入为 t p a = [ i o u p a , r p a , p p a , p s a m p l e , b p a ] t_{pa}=[iou_{pa},r_{pa},p_{pa},p_{sample},b_{pa}] tpa=[ioupa,rpa,ppa,psample,bpa],分别表示经过优化的iou token,mask token, 原始稀疏token, 新的提示token,和优化后的稀疏提示token。
PA-SAM取得了优于HQ-SAM的分割效果。
- 【论文链接】:https://arxiv.org/pdf/2401.13051.pdf
- 【项目链接】:https://github.com/xzz2/pa-sam