简单聊聊Swift闭包的用法
1.闭包
闭包是一个捕获了外部变量或者常量的函数,可以有名字的函数,可以是匿名的函数,也可以是不捕获外部变量的函数。所以可以说闭包是特殊的函数。
闭包是自包含的函数代码块,可以在代码中被传递和使用。Swift 中的闭包与 C 和 ObjC 中的代码块(blocks)比较相似。
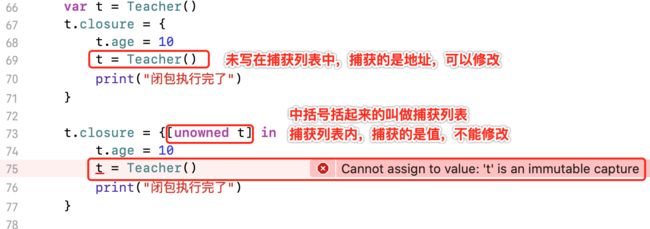
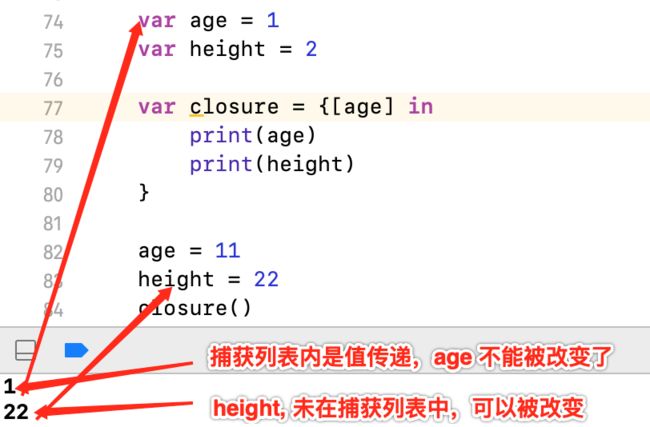
捕获的变量,可以写在捕获列表里. 如果使用捕获列表,即使省略了参数名字、参数类型、返回类型,也必须要用 in 的关键字
●捕获列表里面的是捕获的是值,不可变,
●未在捕获列表里,捕获到的是地址,可以修改
案例1: 闭包内部不能修改值传递的
案例2: 闭包外部修改值传递的数据,也是无效的
2. 闭包表达式
下面这种,是我们熟知的闭包表达式:一个匿名函数 + 捕获了外部的变量或者常量:
{ (age: Int) -> Int in
return age + 1
}
闭包表达式还可以按照下面的规则,变的更加简洁:
●如果参数及返回值类型可以根据上下文推断出来,则可以省略参数 / 返回值的类型
●如果只有一行,是单表达式,可以省略 return 关键字
●参数的名称可以根据参数的位置,简写成 $0、$1
●如果最后一个参数是闭包,可以使用尾随闭包表达式
●如果只有一个参数,且是闭包,可以省略小括号,直接写尾随闭包
var array = [1, 2, 3]
// 常规写法
array.sort(by: {(item1 : Int, item2: Int) -> Bool in return item1 < item2 })
// 省略参数类型
array.sort(by: {(item1, item2) -> Bool in return item1 < item2 })
// 省略返回值类型
array.sort(by: {(item1, item2) in return item1 < item2 })
// 省略 return 关键字
array.sort(by: {(item1, item2) in item1 < item2 })
// 省略小括号(尾随闭包)
array.sort{(item1, item2) in $0 < $1 }
// 省略参数,使用默认的$0 $1
array.sort{ $0 < $1 }
// 甚至整个闭包表达式,只剩下一个 < 符号
array.sort(by: <)
闭包可以当做类型使用,也就是可以用来定义变量、参数、返回值
// 定义变量
var closure : ((Int) -> Int)?
closure = { (age: Int) -> Int in
return age + 1
}
// 定义参数
func test(param: ((Int) -> Int)) {
print(param())
}
// 作为返回值
func getClosure() -> ((Int) -> Int) {
var closure : ((Int) -> Int) = { (age: Int) -> Int in
return age + 1
}
return closure
}
3.尾随闭包
当函数的最后一个参数是闭包时,可以使用尾随闭包来增强函数的可读性。在使用尾随闭包时,你不用写出它的参数标签:
func test(closure: () -> Void) {
...
}
// 不使用尾随闭包
test(closure: {
...
})
// 使用尾随闭包
test() {
...
}
4.逃逸闭包
逃逸闭包是指闭包作为参数传入函数中,然而它的生命周期比函数的声明周期还长,也就是闭包需要在函数释放后也可以调用,我们就称这个闭包为逃逸闭包。编译器默认闭包为非逃逸闭包,用@nonescaping修饰。逃逸闭包使用@escaping 修饰。
var completions: [() -> Void] = []
func testClosure(completion: () -> Void) {
completions.append(completion)
}
此时编译器会报错,提示你这是一个逃逸闭包,我们可以在参数名之前标注 @escaping,用来指明这个闭包是允许“逃逸”出这个函数的。
var completions: [() -> Void] = []
func testEscapingClosure(completion: @escaping () -> Void) {
completions.append(completion)
}
另外,将一个闭包标记为 @escaping 意味着你必须在闭包中显式地引用 self,而非逃逸闭包则不用。这提醒你可能会一不小心就捕获了self,注意循环引用。
有两种情况需要使用逃逸闭包:
●闭包被赋值给属性或者成员变量
●在延时后,使用闭包
4.1 闭包被赋值给属性或者成员变量
class LGTeacher{
var age = 18
var complitionHandler: ((Int)->Void)?
func makeIncrementer(amount: Int, handler: @escaping (Int) -> Void){
var runningTotal = 0
runningTotal += amount
self.complitionHandler = handler
}
func doSomething(){
self.makeIncrementer(amount: 10) {
//会引起循环引用
// self.age = 20
print($0)
}
}
deinit {
print("LGTeaher deinit")
}
}
func test() {
let t = LGTeacher()
t.doSomething()
t.complitionHandler?(50)
}
test()
4.2 延时执行逃逸闭包
func makeIncrementer(amount: Int, handler: @escaping (Int) -> Void){
var runningTotal = 0
runningTotal += amount
self.complitionHandler = handler
// 延时执行
DispatchQueue.global().asyncAfter(deadline: .now() + 1) {
self.complitionHandler?(50)
}
}
5. 自动闭包
解释1:
当闭包作为参数传入时,使用@autoclosure来修饰,就表示如果传入的是一个普通的值,就会被自动包装成一个闭包。这个闭包没有参数,返回值是String, 也就是我们传入的普通的字符串。
解释2:
自动闭包是一种自动创建的闭包,用于包装传递给函数作为参数的表达式。这种闭包不接受任何参数,让你能够省略闭包的花括号,用一个普通的表达式来代替显式的闭包。
并且自动闭包让你能够延迟求值,因为直到你调用这个闭包,代码段才会被执行。要标注一个闭包是自动闭包,需要使用@autoclosure。
例1:
func debugOutPrint(for condition: Bool , _ message: @autoclosure () -> String){
if condition {
print(message())
}
}
func doSomething() -> String{
//do something and get error message
return "NetWork Error Occured"
}
debugOutPrint(for: true, doSomething())
debugOutPrint(for: true, "Application Error Occured")
例2:
// 未使用自动闭包,需要显示用花括号说明这个参数是一个闭包
func test(closure: () -> Bool) {
}
test(closure: { 1 < 2 } )
// 使用自动闭包,只需要传递表达式
func test(closure: @autoclosure () -> String) {
}
test(customer: 1 < 2)
6.闭包捕获的变量的内存结构
我们通过下面这个例子,来探索闭包捕获的变量的内存结构:
func makeIncrementer() -> () -> Int {
var runningTotal = 12
func incrementer() -> Int {
runningTotal += 1
return runningTotal
}
return incrementer
}
用下面两种方式,执行函数,打印结果是什么?
// 方式一: 直接执行3次函数
print("方式1 - 第1次执行函数:\(makeIncrementer()())")
print("方式1 - 第2次执行函数:\(makeIncrementer()())")
print("方式1 - 第3次执行函数:\(makeIncrementer()())")
print("\n")
// 方法二: 先创建一个函数变量,并执行这个函数变量3次
var makeInc2 = makeIncrementer()
print("方式2 - 第1次执行函数:\(makeInc2())")
print("方式2 - 第2次执行函数:\(makeInc2())")
print("方式2 - 第3次执行函数:\(makeInc2())")
打印结果:
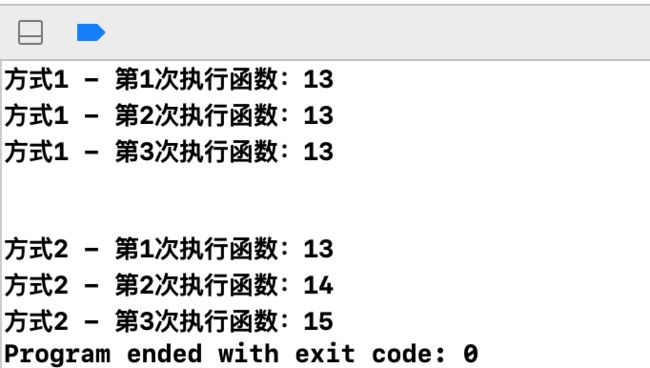
可以看到方式1中,每次执行方法,都是在初始值12的基础上 + 1. 打印的是13。
方式2中,每次执行方法,都是在上一次执行结果的基础上 + 1. 打印的是13、14、15。
第一种结果是在我们的预期之中的,因为我们按照平时的逻辑思考,会认为 runningTotal是方法内的局部变量,每一次执行都会重新初始化成12。所以无论执行多少次,应该都是13呀,为什么方法2中的执行方式却打印出了非预期的值呢?我们尝试通过SIL来探索被 block 捕获的变量的内存结构:

被捕获的变量,会在对上开辟内存空间,所以是引用类型。
●方法 2 中, 创建一个函数的变量,每次执行的都是这个函数变量。对于同一个函数变量,它的内部只有一个 runningTotal的地址,每次执行函数,都会去 runningTotal 的地址上去取值,所以每次拿的都上次 + 1 后的结果。
●方法 1 不能每次都 +1 , 是因为它的本质是创建了3个函数变量,也就对应的在堆上创建了 3个不同的 runningTotal 的内存空间,每个 runningTotal 的初始值都是12,所以执行函数,都是 12 + 1 = 13。
7.闭包的内存结构
还是上面那个例子,我们探究一个方式2中的,定义的函数变量 makeInc2 的数据类型
// 方法二: 先创建一个函数变量,并执行这个函数变量3次
var makeInc2 = makeIncrementer()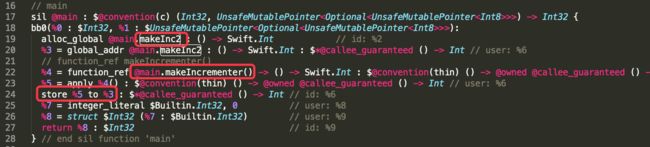
1创建一个makeInc2的变量%3
2执行makeIncrementer函数,并将返回值存储到%5中
3将%5的内容存储给%3
这。。。什么都看不出啊。。。我们再下沉一层中间代码,看看 IR 代码:
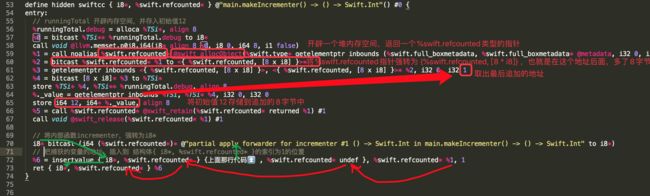
IR代码就非常详细的展示了整个函数内部的逻辑:
1不止为捕获变量runningTotal在堆内存中创建了内存空间,还在后面追加了一个8字节存放runningTotal的值
2makeIncrementer() 函数的返回值是这个结构体: { i8*, %swift.refcounted* }
a第一个成员变量是闭包incrementer() 的地址
b第二个成员变量是追加了8字节的捕获的外部变量runningTotal地址
我们自己构建一下数据结构:
// makeIncrementer()函数返回的数据结构
struct FuntionData{
var closuresPointer: UnsafeRawPointer
var captureValuePointer: UnsafePointer
}
// 闭包incrementer()的数据结构
struct Closures {
var refCounted: HeapObject
var value: T
}
// 捕获的外部变量runningTotal的数据结构
struct HeapObject{
var matedataPointer: UnsafeRawPointer
var refCount1: UInt32
var refCount2: UInt32
} 将makeInc变量,与我们构建的数据结构进行内存绑定:
//包装的结构体
struct VoidIntFun {
var f: () ->Int
}
// 要观察的函数变量
var makeInc = VoidIntFun(f: makeIncrementer())
// 将变量的地址,绑定到我们自己构建的数据结构
let ptr = UnsafeMutablePointer.allocate(capacity: 1)
ptr.initialize(to: makeInc)
let ctx = ptr.withMemoryRebound(to: FuntionData>.self, capacity: 1) {
$0.pointee
}
// 打印闭包incrementer()
print("闭包的地址:\(ctx.closuresPointer)" )
// 打印捕获的外部变量runningTotal
print("捕获的外部变量的HeapObject:\(ctx.captureValuePointer.pointee.heapObject)")
print("捕获的外部变量的value:\(ctx.captureValuePointer.pointee.value)") 打印结果:
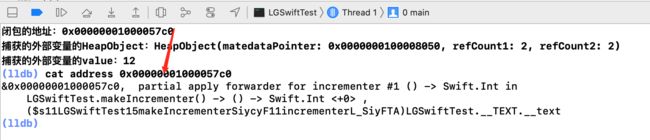
由此,我们可以知道:
●闭包其实是个引用类型,
●闭包的数据结构是闭包地址 + 捕获的外部变量(外部变量的HeapObject + 外部变量的值)。
●由于闭包是特殊的函数,所以函数也是引用类型