Elasticsearch(四)
是这样的前面的几篇笔记,感觉对我没有形成知识体系,感觉乱糟糟的,只是大概的了解了一些基础知识,仅此而已,而且对于这技术栈的学习也是为了在后面的java开发使用,但是这里的API学的感觉有点乱!然后在准备二刷!
1、倒排索引
倒排索引中有两个非常重要的概念:
-
文档(
Document):用来搜索的数据,其中的每一条数据就是一个文档。例如一个网页、一个商品信息 -
词条(
Term):对文档数据或用户搜索数据,利用某种算法分词,得到的具备含义的词语就是词条。例如:我是中国人,就可以分为:我、是、中国人、中国、国人这样的几个词条
创建倒排索引是对正向索引的一种特殊处理,流程如下:
-
将每一个文档的数据利用算法分词,得到一个个词条
-
创建表,每行数据包括词条、词条所在文档id、位置等信息
-
因为词条唯一性,可以给词条创建索引,例如hash表结构索引
| id | title | price |
|---|---|---|
| 1 | 小米手机 | 3499 |
| 2 | 华为手机 | 4999 |
| 3 | 华为小米充电器 | 49 |
| 4 | 小米手环 | 299 |
上表是我们正向的索引,由id去查找相关的词条,但是事实上我们一般会依靠一些关键字"手机"去检索数据,然后会数据库会逐行扫描数据,这样做的确可以解决问题,但是如果数据量大的时候啧啧啧!
| 词条(term) | 文档id |
|---|---|
| 小米 | 1,3,4 |
| 手机 | 1,2 |
| 华为 | 2,3 |
| 充电器 | 3 |
| 手环 | 4 |
倒排索引的搜索流程如下(以搜索"华为手机"为例):
1)用户输入条件"华为手机"进行搜索。
2)对用户输入内容分词,得到词条:华为、手机。
3)拿着词条在倒排索引中查找,可以得到包含词条的文档id:1、2、3。
4)拿着文档id到正向索引中查找具体文档。
1.1、总结
正向索引:是最传统的,根据id索引的方式。但根据词条查询时,必须先逐条获取每个文档,然后判断文档中是否包含所需要的词条,是根据文档找词条的过程。
倒排索引:则相反,是先找到用户要搜索的词条,根据词条得到保护词条的文档的id,然后根据id获取文档。是根据词条找文档的过程。
正向索引:
-
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
-
-
缺点:
-
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
-
倒排索引:
-
优点:
-
根据词条搜索、模糊搜索时,速度非常快
-
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
-
2、前置概念
2.1、文档和字段
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中:
{
"id": 1,
"title": "小米手机",
"price": 3499
},
{
"id": 2,
"title": "华为手机",
"price": 4999
},
{
"id": 3,
"title": "华为小米充电器",
"price": 49
},
{
"id": 4,
"title": "小米手环",
"price": 299
}而Json文档中往往包含很多的字段(Field),类似于数据库中的列。
2.2、索引和映射
索引(Index),就是相同类型的文档的集合。
例如:
-
所有用户文档,就可以组织在一起,称为用户的索引;
-
所有商品的文档,可以组织在一起,称为商品的索引;
-
所有订单的文档,可以组织在一起,称为订单的索引;
用户索引:
{
"id": 101,
"name": "张三",
"age": 21
}
{
"id": 102,
"name": "李四",
"age": 24
}
{
"id": 103,
"name": "麻子",
"age": 18
}商品索引:
{
"id": 1,
"title": "小米手机",
"price": 3499
}
{
"id": 2,
"title": "华为手机",
"price": 4999
}
{
"id": 3,
"title": "三星手机",
"price": 3999
}订单索引:
{
"id": 10,
"userId": 101,
"goodsId": 1,
"totalFee": 294
}
{
"id": 11,
"userId": 102,
"goodsId": 2,
"totalFee": 328
}映射(mapping):索引中文档的字段约束信息,类似表的结构约束
因此,我们可以把索引当做是数据库中的表。数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
2.3、Mysql和ElasticSearch作比较
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
3、索引
3.1、mapping属性
mapping是对索引库中文档的约束,常见的mapping属性包括:
-
type:字段数据类型,常见的简单类型有:
-
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
-
数值:long、integer、short、byte、double、float、
-
布尔:boolean
-
日期:date
-
对象:object
-
-
index:是否创建索引,默认为true
-
analyzer:使用哪种分词器
-
properties:该字段的子字段
3.2、索引操作
创建索引:
PUT user
{
"mappings": {
"properties": {
"info": {
"type": "text",//字符串的话就是对于分词可以使用text分词查询,keyword需要全部匹配
"analyzer": "ik_max_word"//分词器
},
"name":{
"properties": {//子属性
"firstName":{
"type":"keyword"
},
"lastName":{
"type":"keyword"
}
}
},
"email":{
"type": "keyword",
"index": false
},
"age":{
"type": "integer",//其他数据类型
"index": false//默认是true,可以被查询,false是不可以作为索引查询,不写就是true
}
}
}
}
查询:
GET /user
修改索引:
倒排索引结构虽然不复杂,但是一旦数据结构改变(比如改变了分词器),就需要重新创建倒排索引,这简直是灾难。因此索引库一旦创建,无法修改mapping。虽然无法修改mapping中已有的字段,但是却允许添加新的字段到mapping中,因为不会对倒排索引产生影响。
PUT /user/_mapping
{
"properties":{
"sex":{
"type":"keyword"
}
}
}删除:
DELETE /user查询所有:
GET /_cat/indices?v4、文档操作
4.1、添加文档
#指定id
POST /user/_doc/1
{
"info":"我是一个小学生",
"email":"[email protected]",
"name":{
"firstName":"三",
"lastName":"张"
}
}
#系统生成的id
POST /user/_doc
{
"info":"不是隐形的安安",
"email":"[email protected]",
"name":{
"firstName":"狗",
"lastName":"张"
}
}4.2、查询文档
#查询
GET /user/_doc/a1i8fo0BN8Iyr0gVeyne4.3、删除文档
#删除
DELETE /user/_doc/a1i8fo0BN8Iyr0gVeyne4.4、修改文档
#修改 方式1 全量修改,会删除旧的文档然后插入新的文档(存在旧文档)
PUT /user/_doc/1
{
"info":"我是一个大学生",
"email":"[email protected]",
"name":{
"firstName":"三三",
"lastName":"张"
}
}
#修改 不存在直接创建
PUT /user/_doc/2
{
"info":"你看看是什么要你管的",
"email":"[email protected]",
"name":{
"firstName":"四四",
"lastName":"李"
}
}
#局部修改
POST /user/_update/2
{
"doc":{
"name":{
"lastName":"赵"
}
}
}5、查询文档
5.1、DSL查询分类
Elasticsearch提供了基于JSON的DSL(Domain Specific Language)来定义查询。常见的查询类型包括:
-
查询所有:查询出所有数据,一般测试用。例如:match_all
-
全文检索(full text)查询:利用分词器对用户输入内容分词,然后去倒排索引库中匹配。例如:
-
match_query
-
multi_match_query
-
-
精确查询:根据精确词条值查找数据,一般是查找keyword、数值、日期、boolean等类型字段。例如:
-
ids
-
range
-
term
-
-
地理(geo)查询:根据经纬度查询。例如:
-
geo_distance
-
geo_bounding_box
-
-
复合(compound)查询:复合查询可以将上述各种查询条件组合起来,合并查询条件。例如:
-
bool
-
function_score
-
5.2、具体操作
5.2.1、查询所有
-
查询类型为match_all
-
没有查询条件
#查询所有
GET /hotel/_search
{
"query": {
"match_all": {
}
}
}5.2.2、全文检索
全文检索查询的基本流程如下:
-
对用户搜索的内容做分词,得到词条
-
根据词条去倒排索引库中匹配,得到文档id
-
根据文档id找到文档,返回给用户
比较常用的场景包括:
-
商城的输入框搜索
-
百度输入框搜索
因为是拿着词条去匹配,因此参与搜索的字段也必须是可分词的text类型的字段。常见的全文检索查询包括:
-
match查询:单字段查询
-
multi_match查询:多字段查询,任意一个字段符合条件就算符合查询条件
#全文检索-match查询
GET /hotel/_search
{
"query": {
"match": {
"name": "七天连锁"
}
}
}
#全文检索-mulit_match
GET /hotel/_search
{
"query": {
"multi_match": {
"query": "外滩如家",
"fields": ["brand","name","business"]
}
}
}因为我们将brand、name、business值都利用copy_to复制到了all字段中。因此你根据三个字段搜索,和根据all字段搜索效果当然一样了。但是,搜索字段越多,对查询性能影响越大,因此建议采用copy_to,然后单字段查询的方式。
5.2.3、精准查询
精确查询一般是查找keyword、数值、日期、boolean等类型字段。所以不会对搜索条件分词。常见的有:
-
term:根据词条精确值查询
-
range:根据值的范围查询
5.2.3.1、term查询
因为精确查询的字段搜是不分词的字段,因此查询的条件也必须是不分词的词条。查询时,用户输入的内容跟自动值完全匹配时才认为符合条件。如果用户输入的内容过多,反而搜索不到数据。
#term查询 豫园地区
GET /hotel/_search
{
"query": {
"term": {
"business": {
"value": "豫园地区"
}
}
}
}只能查询允许可以作为索引的字段!而且字段要百分百匹配!
5.2.3.2、range查询
范围查询,一般应用在对数值类型做范围过滤的时候。比如做价格范围过滤。
#range查询 价格
GET hotel/_search
{
"query": {
"range": {
"price": {
"gte": 500,
"lte": 1000
}
}
}
}5.2.4、地理坐标查询
所谓的地理坐标查询,其实就是根据经纬度查询,官方文档:Geo queries | Elasticsearch Guide [8.12] | Elastic
常见的使用场景包括:
-
携程:搜索我附近的酒店
-
滴滴:搜索我附近的出租车
-
微信:搜索我附近的人
5.2.4.1、矩形范围查询
矩形范围查询,也就是geo_bounding_box查询,查询坐标落在某个矩形范围的所有文档:
查询时,需要指定矩形的左上、右下两个点的坐标,然后画出一个矩形,落在该矩形内的都是符合条件的点。
// geo_bounding_box查询
GET /indexName/_search
{
"query": {
"geo_bounding_box": {
"FIELD": {
"top_left": { // 左上点
"lat": 31.1,
"lon": 121.5
},
"bottom_right": { // 右下点
"lat": 30.9,
"lon": 121.7
}
}
}
}
}5.2.4.2、附近查询
附近查询,也叫做距离查询(geo_distance):查询到指定中心点小于某个距离值的所有文档。换句话来说,在地图上找一个点作为圆心,以指定距离为半径,画一个圆,落在圆内的坐标都算符合条件:

#geo_distance 查询
GET /hotel/_search
{
"query": {
"geo_distance": {
"distance": "15km",
"location": "31.21,121.5"
}
}
}5.2.5、复杂查询
复合(compound)查询:复合查询可以将其它简单查询组合起来,实现更复杂的搜索逻辑。常见的有两种:
-
fuction score:算分函数查询,可以控制文档相关性算分,控制文档排名
-
bool query:布尔查询,利用逻辑关系组合多个其它的查询,实现复杂搜索
5.2.5.1、相关性算分
当我们利用match查询时,文档结果会根据与搜索词条的关联度打分(_score),返回结果时按照分值降序排列。
在elasticsearch中,早期使用的打分算法是TF-IDF算法,公式如下:

在后来的5.1版本升级中,elasticsearch将算法改进为BM25算法,公式如下:

5.2.5.2、算分函数查询
使用这个查询的话,可以人工干预查询的结果,也就是改变查询结果的排名顺序!
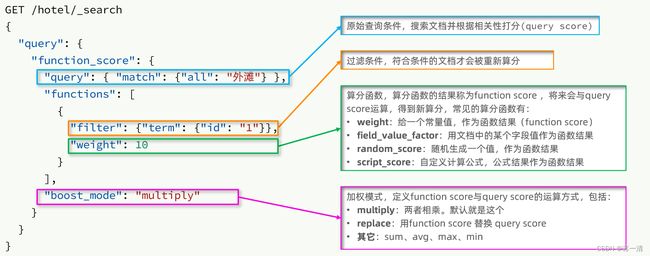
function score 查询中包含四部分内容:
-
原始查询条件:query部分,基于这个条件搜索文档,并且基于BM25算法给文档打分,原始算分(query score)
-
过滤条件:filter部分,符合该条件的文档才会重新算分
-
算分函数:符合filter条件的文档要根据这个函数做运算,得到的函数算分(function score),有四种函数
-
weight:函数结果是常量
-
field_value_factor:以文档中的某个字段值作为函数结果
-
random_score:以随机数作为函数结果
-
script_score:自定义算分函数算法
-
-
运算模式:算分函数的结果、原始查询的相关性算分,两者之间的运算方式,包括:
-
multiply:相乘
-
replace:用function score替换query score
-
其它,例如:sum、avg、max、min
-
function score的运行流程如下:
-
1)根据原始条件查询搜索文档,并且计算相关性算分,称为原始算分(query score)
-
2)根据过滤条件,过滤文档
-
3)符合过滤条件的文档,基于算分函数运算,得到函数算分(function score)
-
4)将原始算分(query score)和函数算分(function score)基于运算模式做运算,得到最终结果,作为相关性算分。
#加分函数查询
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match": {
"all": "外滩"
}
},
"functions": [
{
"filter": {
"term": {
"brand": "如家"
}
},
"weight":2
}
],
"boost_mode": "multiply"
}
}
}5.2.5.3、布尔查询
布尔查询是一个或多个查询子句的组合,每一个子句就是一个子查询。子查询的组合方式有:
-
must:必须匹配每个子查询,类似“与”
-
should:选择性匹配子查询,类似“或”
-
must_not:必须不匹配,不参与算分,类似“非”
-
filter:必须匹配,不参与算分
每一个不同的字段,其查询的条件、方式都不一样,必须是多个不同的查询,而要组合这些查询,就必须用bool查询了。需要注意的是,搜索时,参与打分的字段越多,查询的性能也越差。因此这种多条件查询时,建议这样做:
-
搜索框的关键字搜索,是全文检索查询,使用must查询,参与算分
-
其它过滤条件,采用filter查询。不参与算分
GET /hotel/_search
{
"query": {
"bool": {
"must": [
{"term": {"city": "上海" }}
],
"should": [
{"term": {"brand": "皇冠假日" }},
{"term": {"brand": "华美达" }}
],
"must_not": [
{ "range": { "price": { "lte": 500 } }}
],
"filter": [
{ "range": {"score": { "gte": 45 } }}
]
}
}
}5.2.6、搜索结果处理
5.2.6.1、排序
elasticsearch默认是根据相关度算分(_score)来排序,但是也支持自定义方式对搜索结果排序。可以排序字段类型有:keyword类型、数值类型、地理坐标类型、日期类型等。
普通字段排序:
keyword、数值、日期类型排序的语法基本一致。
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"FIELD": "desc" // 排序字段、排序方式ASC、DESC
}
]
}
#排序
GET /hotel/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"score": {
"order": "desc"
},
"price": {
"order": "desc"
}
}
]
}排序条件是一个数组,也就是可以写多个排序条件。按照声明的顺序,当第一个条件相等时,再按照第二个条件排序,以此类推
地理坐标排序
GET /indexName/_search
{
"query": {
"match_all": {}
},
"sort": [
{
"_geo_distance" : {
"FIELD" : "纬度,经度", // 文档中geo_point类型的字段名、目标坐标点
"order" : "asc", // 排序方式
"unit" : "km" // 排序的距离单位
}
}
]
}
#地理位置
GET /hotel/_search
{
"query": {
"match_all": {
}
},
"sort": [
{
"_geo_distance": {
"location": {
"lat": 31.034661,
"lon": 121.612282
},
"order": "asc",
"unit": "km"
}
}
]
}这个查询的含义是:
-
指定一个坐标,作为目标点
-
计算每一个文档中,指定字段(必须是geo_point类型)的坐标 到目标点的距离是多少
-
根据距离排序
5.2.6.2、分页
elasticsearch 默认情况下只返回top10的数据。而如果要查询更多数据就需要修改分页参数了。elasticsearch中通过修改from、size参数来控制要返回的分页结果:
-
from:从第几个文档开始
-
size:总共查询几个文档
类似于mysql中的limit ?, ?
基本分页
GET /hotel/_search
{
"query": {
"match_all": {}
},
"from": 0, // 分页开始的位置,默认为0
"size": 10, // 期望获取的文档总数
"sort": [
{"price": "asc"}
]
}深度分页
当我们查询的数据是10000以后的时候,这种方式的查询的方式会使在集群的环境下的服务器的资源消耗过大,检索数据是从所有的的分片中筛选出来后,然后排序后截取响应的数据,所以超出10000条后是被禁止的。

针对深度分页,ES提供了两种解决方案,官方文档:
-
search after:分页时需要排序,原理是从上一次的排序值开始,查询下一页数据。官方推荐使用的方式。
-
scroll:原理将排序后的文档id形成快照,保存在内存。官方已经不推荐使用。
总结
分页查询的常见实现方案以及优缺点:
-
from + size:-
优点:支持随机翻页
-
缺点:深度分页问题,默认查询上限(from + size)是10000
-
场景:百度、京东、谷歌、淘宝这样的随机翻页搜索
-
-
after search:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:只能向后逐页查询,不支持随机翻页
-
场景:没有随机翻页需求的搜索,例如手机向下滚动翻页
-
-
scroll:-
优点:没有查询上限(单次查询的size不超过10000)
-
缺点:会有额外内存消耗,并且搜索结果是非实时的
-
场景:海量数据的获取和迁移。从ES7.1开始不推荐,建议用 after search方案。
-
5.2.6.3、高亮显示
GET /hotel/_search
{
"query": {
"match": {
"FIELD": "TEXT" // 查询条件,高亮一定要使用全文检索查询
}
},
"highlight": {
"fields": { // 指定要高亮的字段
"FIELD": {
"pre_tags": "", // 用来标记高亮字段的前置标签
"post_tags": "" // 用来标记高亮字段的后置标签
}
}
}
}注意:
-
高亮是对关键字高亮,因此搜索条件必须带有关键字,而不能是范围这样的查询。
-
默认情况下,高亮的字段,必须与搜索指定的字段一致,否则无法高亮
-
如果要对非搜索字段高亮,则需要添加一个属性:required_field_match=false