深度解析ScheduledThreadPoolExecutor源码之DelayedWorkQueue
文章目录
- 引言
- 一、什么是二叉堆?
-
- 1.1什么是最大堆、最小堆?
- 1.2堆的基本操作
-
- 1.2.1插入节点元素
- 1.2.2删除节点元素
- 1.2.3构建二叉堆
- 1.3堆特性总结
- 二、DelayedWorkQueue源码解析
-
- 2.1 DelayedWorkQueue参数解析
- 2.2 DelayedWorkQueue方法解析
- 总结
引言
该系列文章将完整解析JDK8中ScheduledThreadPoolExecutor的实现原理,解析ScheduledThreadPoolExecutor如何实现任务的延迟执行、周期性执行等原理。在阅读此文章之前,需要您对线程池ThreadPoolExecutor的使用有一定的了解,并对Future和阻塞队列BlockingQueue的实现原理也要有一定的掌握,因为本章将涉及这些知识点,但不会对这些知识点做过多的讲解,如果您对JDK中的Future原理还不太了解,您可以先预览文章Java中的Future源码讲解做初步的了解。如果您对阻塞队列BlockingQueue的原理不太了解,您可以先预览文章深度了解LinkedBlockingQueue底层实现原理做初步了解。
本章节将对ScheduledThreadPoolExecutor源码中的延迟队列DelayedWorkQueue做全面源码分析,涉及到的知识点有阻塞队列BlockingQueue、二叉堆算法(上浮、下沉)。对于ScheduledThreadPoolExecutor中的另一个类ScheduledFutureTask,我打算放到第二章节去讲解。
一、什么是二叉堆?
我记得二叉堆第一次出现是在大学时期一本叫《数据结构与算法》的书上,初步的定义是:
二叉堆是一种特殊类型的堆,它是一种完全二叉树,同时也满足堆的基本特性:所有节点的左子树和右子树也都是二叉堆。
二叉堆分为两种类型:最大堆和最小堆。
1.1什么是最大堆、最小堆?
最大堆:任何一个父节点的值都大于或等于它左右孩子节点的值。也就是说最大堆中根的值最大。如下图所示,每个父节点的值都大于等于左右子节点,这种也就称为最大堆。但请注意,左右子节点的值并不是有顺序的,也就是说右节点的值不一定大于左节点。但可以保证的是,父节点的值一定大于等于左右两个子节点。

最小堆:任何一个父节点的值,都要小于或等一它左右孩子节点的值。也就是说最小堆中根的值最小。如下图所示,每个父节点的值都小于等于左右子节点,这种也就称为最小堆。

1.2堆的基本操作
二叉堆有几种常见的操作:插入节点元素、删除节点元素、构建二叉堆。这几种操作都基于堆的自我调整,所谓堆的自我调整,就是把一个不符合堆性质的完全二叉树,调整为一个堆。本文以最小堆为例子,因为DelayedWorkQueue中就是采用最小堆的算法方式对任务进行插入、排序、删除等操作。
1.2.1插入节点元素
对于新节点元素的插入,插入的位置是完全二叉树的最后一个位置。然后再与其父节点进行比较,如果插入节点值小于父节点,则进行位置互换,然后继续重复以上操作,和父节点进行比较,直至插入元素的值大于或者等于父节点时,结束该操作,这种操作也叫做上浮,插入元素从底部开始逐一与父节点进行比较。比如当前最小堆将插入一个节点值为1,此时节点1应该与其父节点5进行比较,如果父节点的值大于1,则进行位置替换。
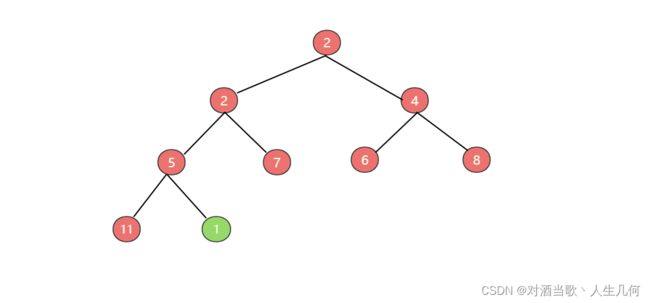
由于父节点值为5,则将节点1与节点5的位置进行互换,互换后图如下:
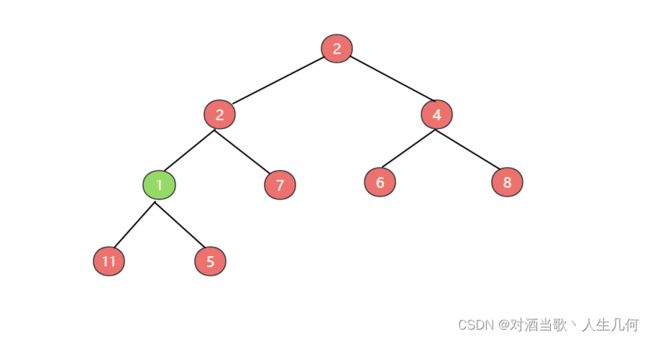
互换后,发现此时不满足最小堆的特性,此时插入操作还未结束,虽然节点1和节点5进行了互换,但是此时节点1的父节点值为2,父节点值大于子节点,则还需进行位置互换,互换结果图如下:

互换后发现还是不满足最小堆的特性,因此还需要进行一次位置互换,互换后才满足最小堆特性,根的值最小,此时上浮才算完成。
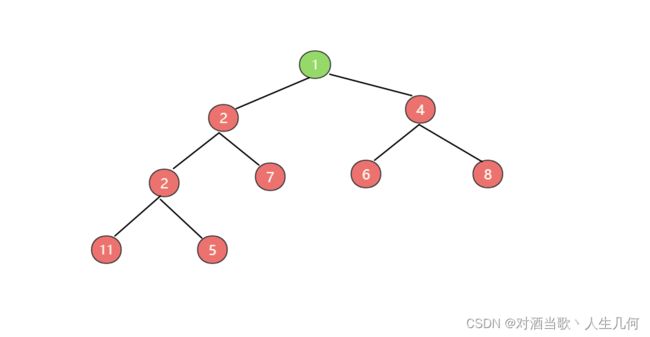
1.2.2删除节点元素
二叉堆删除节点的过程和插入节点的过程正好相反,删除是从堆的顶部移除节点元素,然后将二叉堆最后一个位置的元素放到堆顶部,然后从顶部向下比较,这个操作叫做下沉。意思是父节点与左右节点中较小的那个子节点进行比较,请注意是和左右子节点中较小的那个节点进行比较,如果父节点的值大于较小那个子节点,那么进行位置互换。为什么要和较小那个子节点进行比较,这样可以保证在下沉时,堆顶部节点的值是最小的。我们以刚刚插入完成那个最小堆为例,先移除堆顶部节点
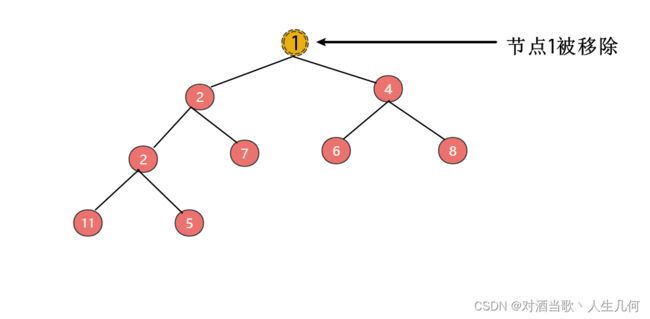
移除后,将最尾部的元素放到堆顶部:
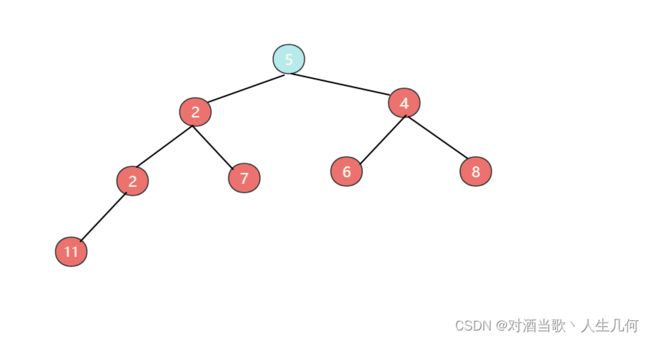
此时并不满足最小堆,现在需要进行下沉操作,将节点5与左右子节点中较小的节点进行比较,如果较小的节点值小于父节点,则进行位置互换,由于节点5的左右子节点分别为2和4,则节点2小于节点5,所以两则进行位置互换。
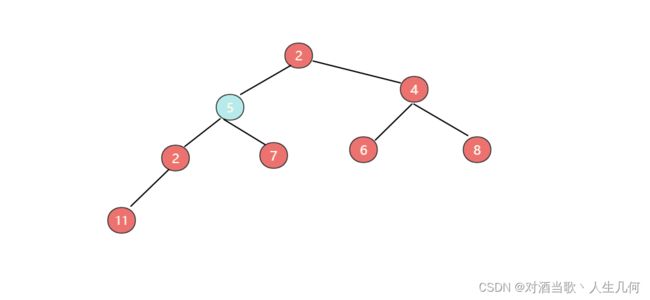
互换后再次进行以上操作,则节点5又将于节点2进行位置互换,形成最终的最小堆:
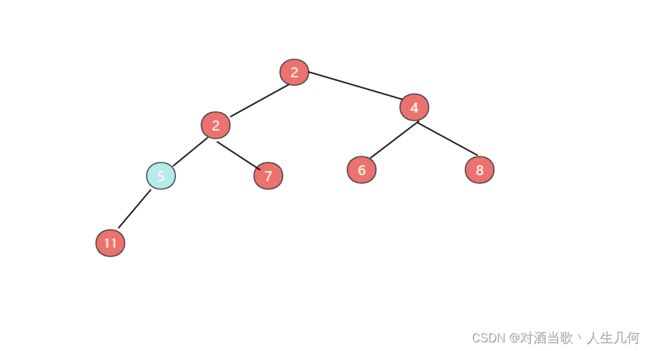
1.2.3构建二叉堆
构建二叉堆,也就是把一个无序的完全二叉树调整为二叉堆,本质就是让所有非叶子节点依次下沉。我们以以下列子进行构建最小堆:
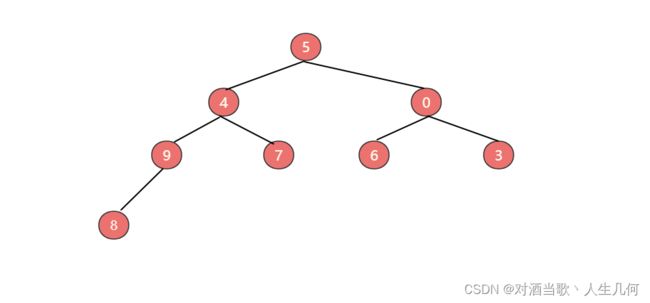
首先从最后一个非叶子节点开始下沉,也就是节点9开始下沉,与节点8比较后,发现节点8小于节点9,进行位置互换:
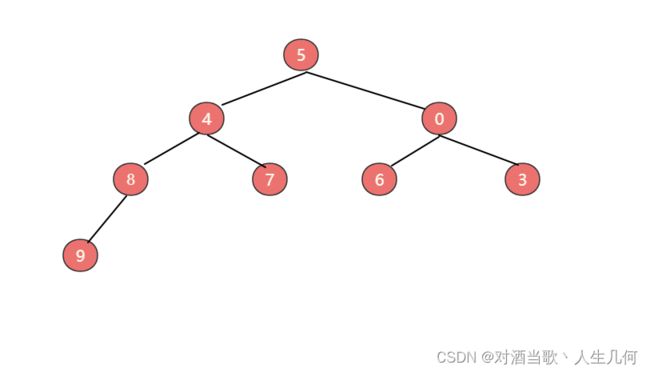
现在轮到节点0与左右子节点6和3中较小的节点3比较,发现节点0小于节点3,则不进行位置互换,然后轮到节点4与左右子节点8和7中较小的节点7比较,也不用互换位置。最后轮到节点5与左右子节点比较,进行下沉操作:

节点5继续下沉:

此时构建最小堆就完成了。
1.3堆特性总结
堆的插入操作是单一节点的“上浮” ,堆的删除操作是单一节点的“下沉” ,这两个操作的平均交换次数都是堆高度的一半,所以时间复杂度是 O(logn)。构建堆的时间复杂度却并不是O(n)。二叉堆虽然是一个完全二叉树,但是它的存储方式并不是并不是链式存储,而是顺序存储。换句话说,二叉堆的所有节点都存储在数组中。
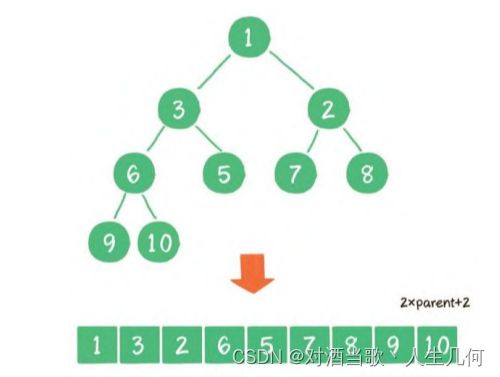
在数组中,在没有左、右指针的情况下,如何定位一个父节点的左孩子和右孩子呢? 像上图那样,可以依靠数组下标来计算。 假设父节点的下标是parent,那么它的左孩子下标就是2*parent+1,右孩子坐标为2*parent+2。读者可能有疑问为什么我要花费这么多时间来讲堆的特性和操作。因为在DelayedWorkQueue中就是使用最小堆的算法来对任务进行排序,而排序要用到上浮和下沉操作。如果您不掌握这些内容,对于后面讲解DelayedWorkQueue的源码会有很大的阻碍。因此我才会在此处重点讲解堆的概念,也希望读者能充分理解上浮和下沉操作后,再继续往下阅读。如果我讲解的不够细致或者有误,您可以参考文章[数据结构】二叉堆进一步了解堆的特性。
二、DelayedWorkQueue源码解析
如果您已经对堆的特性和实现原理有一定的掌握,可以继续阅读下文,否则我建议您先要对堆要有一定的掌握。DelayedWorkQueue是ScheduledThreadPoolExecutor中的一个内部类,DelayedWorkQueue实现BlockingQueue接口并继承了AbstractQueue抽象类,因此DelayedWorkQueue是具有阻塞特性的。JAVA中自带有DelayQueue,其实现是内部维护着一个PriorityQueue来对元素进行排序。DelayedWorkQueue是由ScheduledThreadPoolExecutor制定化的队列,其实现原理与DelayQueue相似。
2.1 DelayedWorkQueue参数解析
DelayedWorkQueue默认初始组数大小为16,数组元素类型为RunnableScheduledFuture,ReentrantLock 默认采用公平锁,用于任务插入堆、从堆中删除控制并发,size用于记录当前任务总数。leader顾名思义领袖,当存在多个线程尝试获取任务时,将第一个线程标志为领袖,意味着当有任务可以获取时,它应该第一个获取到任务。以上就是DelayedWorkQueue中的所有参数。
private static final int INITIAL_CAPACITY = 16;
//默认队列长度
private RunnableScheduledFuture<?>[] queue = new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
//处理并发问题
private final ReentrantLock lock = new ReentrantLock();
//记录队列中元素个数
private int size = 0;
//记录当前等待获取队列头元素的线程
private Thread leader = null;
/**
* Condition signalled when a newer task becomes available at the
* head of the queue or a new thread may need to become leader.
*/
//当队列头的任务延时时间到了,或者新线程可能需要成为leader,用来唤醒等待线程
private final Condition available = lock.newCondition();
2.2 DelayedWorkQueue方法解析
现在我们将从DelayedWorkQueue源码从上往下依次解析每个方法的作用和实现原理,您可以打开自己的IDEA这样更便于您理解和学习。通过以下结构图可以看到DelayedWorkQueue的内部方法并不多,很大以部分都来自继承的AbstractQueue。在接口BlockingQueue的基础上增加了几个重要的方法(setIndex、siftUp、siftDown、grow)。那么我们就从这几个方法开始逐一解析。

setIndex是用于给ScheduledFutureTask类型的任务设置索引位置,这个位置就是该元素在数组中的位置,在第一小节的总结中我们已经知道,二叉堆的元素是顺序存储在数组中的,每个元素都有一个数组下标序号。ScheduledFutureTask是ScheduledThreadPoolExecutor中的另一个核心类,对于该类的解析将放在下一章节。在此处您可以暂时不用关心其实现。
/**
* Sets f's heapIndex if it is a ScheduledFutureTask.
* 如果元素是ScheduledFutureTask,则记录当前元素所在堆的索引序号
* 每个ScheduledFutureTask都维护着一个最小二叉堆的顺序
* ScheduledFutureTask 是ScheduleThreadPoolExecutor里维护的类
*/
private void setIndex(RunnableScheduledFuture<?> f, int idx) {
if (f instanceof ScheduledFutureTask)
((ScheduledFutureTask) f).heapIndex = idx;
}
siftUp是二叉堆中上浮操作的代码实现,该方法可以实现对插入元素的上浮操作。参数k是当前待插入元素在数组中的初始位置(size+1),key则是当前待插入的元素。可能以下代码与您JDK的有一些不一致,是只是变量名称有改变,为了更好的阅读源码,我改了源码中一些变量名称
/**
* Sifts element added at bottom up to its heap-ordered spot.
* Call only when holding lock.元素从底部向上添加到其堆序点。只在持有锁时调用。上浮
* 上浮的原则是找到当前子节点的父节点,如果父节点大于子节点,则子节点上浮到父节点的位置,父节点下沉到子节点位置
* 然后继续比较,直到父节点小于等于子节点
*/
private void siftUp(int k, RunnableScheduledFuture<?> key) {
while (k > 0) {
int parentIndex = (k - 1) >>> 1;//获取父节点在堆中的索引位置
RunnableScheduledFuture<?> parentNode = queue[parentIndex]; //获取父节点元素
if (key.compareTo(parentNode) >= 0) //当前节点与父节点进行比较,比较的实现参考ScheduledFutureTask中的里compare方法
break;
queue[k] = parentNode;//如果比较得出父节点大于子节点,则进行上浮,将父节点放入子节点的位置
setIndex(parentNode, k);//更新父节点在堆中的序号
k = parentIndex;//更新当前位置
}
queue[k] = key;//比较完成后,更新插入元素位置
setIndex(key, k);//设置插入元素的位置
}
siftDown是二叉堆中下沉操作的代码实现,该方法可以实现堆删除元素后进行下沉调整。参数k是当前待下沉元素在数组中的位置,key则是当前待下沉的元素。以下已为每行代码增加注释,部分源码可能存在变量命名差异
/**
* Sifts element added at top down to its heap-ordered spot.
* Call only when holding lock.
* 下沉一般是在堆顶元素被移除时,需要将堆尾元素移至堆顶,然后向下堆化
* 正常的下沉由以下几点:
* 1.从堆顶开始,父节点与左右子节点进行比较(左右孩子节点的值大小不固定,并非右孩子节点的值一定大于左孩子节点)
* 2.父节点小于等于两个孩子节点时,则结束循环,不需交换位置
* 3.如果父节点大于其中一个子子节点,则将与较小的一个子节点进行位置交换
* 4.继续重复以上1~3步骤,直到以前任意条件不满足则结束
*/
private void siftDown(int k, RunnableScheduledFuture<?> key) {
int lastParentIndex = size >>> 1; //最后一个元素的父亲索引位置,就是最后一层非叶子节点层(因为要与有子节点的节点进行比较)
while (k < lastParentIndex) {
int leftChildIndex = (k << 1) + 1;//获取左子节点孩子索引位置
RunnableScheduledFuture<?> leftChild = queue[leftChildIndex];//获取左子节点孩子元素
int rightChildIndex = leftChildIndex + 1; //获取右子节点孩子位置
//rightChildIndex < size用于判断当前右孩子节点存在。
//leftChild.compareTo(queue[rightChildIndex]) > 0 用于判断当前左节点是否大小与右节点
if (rightChildIndex < size && leftChild.compareTo(queue[rightChildIndex]) > 0) {
leftChild = queue[leftChildIndex = rightChildIndex]; //如果当前左节点大于右节点,则拿右孩子节点与插入节点进行比较
}
if (key.compareTo(leftChild) <= 0) {//如果当前节点小于等于左右孩子节点中较小的一个节点,则不在进行下沉,结束循环
break;
}
queue[k] = leftChild;//如果当前节点大于左右孩子节点中较小的节点,则进行位置交换
setIndex(leftChild, k);
k = leftChildIndex;
}
queue[k] = key;//设置当前节点在数组中的位置
setIndex(key, k);
}
grow调整堆容量,每次扩容数组50%,所谓扩容就是新建一个数组,将旧数组的元素复制到新数组中。
/**
* Resizes the heap array. Call only when holding lock. 调整堆数组的大小。只在持有锁时调用。
* 扩容队列
*/
private void grow() {
int oldCapacity = queue.length;
int newCapacity = oldCapacity + (oldCapacity >> 1); // grow 50%
if (newCapacity < 0) // overflow
newCapacity = Integer.MAX_VALUE;
queue = Arrays.copyOf(queue, newCapacity);
}
indexOf用于查询给定元素在堆中的位置,如果是元素是ScheduledFutureTask类型,则在元素插入堆时,会将元素在堆中的位置赋值给heapIndex。因此如果是ScheduledFutureTask类型,可以尝试通过ScheduledFutureTask.heapIndex获取位置。否则只能通过循环遍历数组进行比较。
/**
* Finds index of given object, or -1 if absent.
* 获取给定对象所在二叉堆中的位置
*/
private int indexOf(Object x) {
if (x != null) {
if (x instanceof ScheduledFutureTask) {
int i = ((ScheduledFutureTask) x).heapIndex;
// Sanity check; x could conceivably be a
// ScheduledFutureTask from some other pool.
if (i >= 0 && i < size && queue[i] == x)
return i;
} else {
for (int i = 0; i < size; i++)
if (x.equals(queue[i]))
return i;
}
}
return -1;
}
contains判断堆中是否含有给定的元素对象。如果存在则返回true,否则返回false。
/**
* 判断所给对象是否在堆中
*
* @param x
* @return
*/
public boolean contains(Object x) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return indexOf(x) != -1;
} finally {
lock.unlock();
}
}
remove从堆中移除指定元素,在整个移除操作中,使用ReentrantLock锁定,避免多线程影响。通过indexOf查询所给元素是否存在堆中,如果不存在则返回false,存在则将移除对象在堆中的位置设置为-1,然后拿到堆尾元素,进行下沉操作。
/**
* 将所给的对象从堆中移除
*
* @param x
* @return
*/
public boolean remove(Object x) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = indexOf(x);
if (i < 0) {//如果所给对象未在堆中查到,则返回false
return false;
}
setIndex(queue[i], -1);//设置对象在队列中的序号为-1,表示移出队列
int s = --size;//数量减1
RunnableScheduledFuture<?> replacement = queue[s]; //获取队列尾的元素
queue[s] = null;
if (s != i) {//如果移出的对象不是处于队列尾部,则需要对队列进行重新排序
siftDown(i, replacement);//从当前位置重新进行下沉排序
if (queue[i] == replacement)
siftUp(i, replacement);
}
return true;
} finally {
lock.unlock();
}
}
peek就是正常的检索操作,检索堆中第一个元素,但是不将该元素从堆中删除。
/**
* 检索堆头元素
*
* @return
*/
public RunnableScheduledFuture<?> peek() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return queue[0];
} finally {
lock.unlock();
}
}
offer是堆插入元素的核心方法,put方法也是插入元素,其底层也是调用offer方法。offer方法相对简单,将给定元素转为RunnableScheduledFuture类型,ReentrantLock 加锁保证多线程安全问题,对数组容量进行判断是否需要扩容,如果当前为空数组,则插入元素无需进行上浮操作,直接放入数组并设置元素位置。否则调用siftUp进行元素上浮。代码已附带注释
/**
* ScheduledThreadPoolExecutor提交任务时调用的是DelayedWorkQueue.add,
* 而add、put等一些对外提供的添加元素的方法都调用了offer
* 元素入列
*
* @param x
* @return
*/
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>) x;
final ReentrantLock lock = this.lock;
lock.lock();
try {
int oldSize = size;
if (oldSize >= queue.length) { //如果当前数组已满,则进行扩容
grow();
}
size = oldSize + 1;
if (oldSize == 0) {//如果当前size为0,则表示为空队列,则不需要进行上浮排序
queue[0] = e;
setIndex(e, 0);
} else {
siftUp(oldSize, e);//如果当前队列不为空,则进行上浮排序
}
if (queue[0] == e) { //如果当前队列元素为刚刚插入的元素,则表示队列在未插入之前处于空队列,在空队列时可能存在获取出列操作的睡眠线程,则要尝试唤醒睡眠线程
leader = null;
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
/**
* 元素入列
*
* @param e
*/
public void put(Runnable e) {
offer(e);
}
finishPoll操作是堆删除元素操作的代码实现,将堆尾部元素放入堆顶往下进行下沉操纵,将旧的堆顶元素位置设置为-1并返回堆顶元素。
/**
* Performs common bookkeeping for poll and take: Replaces
* first element with last and sifts it down. Call only when
* holding lock.
*
* @param f the task to remove and return
* 完成出列操作
* 将给定元素移除队列,并对元素重新进行堆下沉操作
*/
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
int s = --size;//总数量减1
RunnableScheduledFuture<?> x = queue[s];
queue[s] = null;//队列尾元素置空便于GC
if (s != 0) //如果数组不为空,则尾部元素进行堆下沉
siftDown(0, x);
setIndex(f, -1);//设置元素在堆中的序号为-1,表示该元素脱离队列
return f;
}
take具有阻塞特性的弹出操作,获取堆顶元素并将该元素移除。代码已附带注释,结合代码理解更佳
/**
* 移除并获取队列头元素
*
* @return
* @throws InterruptedException
*/
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (; ; ) {
RunnableScheduledFuture<?> first = queue[0];//获取堆顶元素
if (first == null) {//如果当前堆顶元素为空,则进入休眠,等待有新的元素插入,将其唤醒
available.await();
} else {
long delay = first.getDelay(NANOSECONDS);//获取当前任务剩余延迟执行时间,实现在ScheduledFutureTask的getDelay方法中
if (delay <= 0) {//如果当前任务延迟执行时间为小于0,表示当前任务可以被执行,则进行删除操作
return finishPoll(first);
}
first = null; // don't retain ref while waiting
if (leader != null) { //如果当前任务延迟执行时间大于0,表示当前任务还未到调度时间,并且leader!=null,表示在该线程之前,已经存在其他线程等待获取待执行的任务,该线程进入睡眠
available.await();
} else {
Thread thisThread = Thread.currentThread();
leader = thisThread;//当前线程设置为领袖
try {
available.awaitNanos(delay);//设置指定的睡眠时间后,唤醒
} finally {
if (leader == thisThread) {
leader = null; //将当前leader置空,以便于后续第1190行操作,唤醒其他睡眠的线程,也给其他线程争夺提供机会
}
}
}
}
}
} finally {
if (leader == null && queue[0] != null) { //当前线程获取元素成功后,尝试唤醒其他睡眠线程
available.signal();
}
lock.unlock();
}
}
总结
ScheduledThreadPoolExecutor指定化了DelayedWorkQueue用于存储任务。采用最小堆的算法对待执行任务进行排序,以此来保证每次取出的总是离执行时间最近的任务。最核心的代码则是方法siftUp和siftDown,当您对二叉堆的上浮和下沉有一定的概念和理解时,DelayedWorkQueue的源码看起来就不足为惧了。下个章节我们将继续探讨ScheduledThreadPoolExecutor中的另一个核心类ScheduledFutureTask,这需要您对FutureTask有一定的了解。