SQL条件判断语句嵌套window子句的应用【易错点】--HiveSql面试题25
目录
0 需求分析
1 数据准备
3 数据分析
4 小结
0 需求分析
需求:表如下
| user_id | good_name | goods_type | rk |
| 1 | hadoop | 10 | 1 |
| 1 | hive | 12 | 2 |
| 1 | sqoop | 26 | 3 |
| 1 | hbase | 10 | 4 |
| 1 | spark | 13 | 5 |
| 1 | flink | 26 | 6 |
| 1 | kafka | 14 | 7 |
| 1 | oozie | 10 | 8 |
以上数据中,goods_type列,假设26代表是广告,现在有个需求,想获取每个用户每次搜索下非广告类型的商品位置自然排序,如果下效果:
| user_id | good_name | goods_type | rk | naturl_rk |
| 1 | hadoop | 10 | 1 | 1 |
| 1 | hive | 12 | 2 | 2 |
| 1 | sqoop | 26 | 3 | null |
| 1 | hbase | 10 | 4 | 3 |
| 1 | spark | 13 | 5 | 4 |
| 1 | flink | 26 | 6 | null |
| 1 | kafka | 14 | 7 | 5 |
| 1 | oozie | 10 | 8 | 6 |
1 数据准备
(1)建表
create table window_goods_test (
user_id int, --用户id
goods_name string, --商品名称
goods_type int, --标识每个商品的类型,比如广告,非广告
rk int --这次搜索下商品的位置,比如第一个广告商品就是1,后面的依次2,3,4...
)ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
(2)数据
vim window_goods_test
1 hadoop 10 1
1 hive 12 2
1 sqoop 26 3
1 hbase 10 4
1 spark 13 5
1 flink 26 6
1 kafka 14 7
1 oozie 10 8
(3)加载数据
load data local inpath "/home/centos/dan_test/window_goods_test.txt" into table window_goods_test;(4)查询数据
21/06/25 11:35:33 INFO DAGScheduler: Job 2 finished: processCmd at CliDriver.java:376, took 0.209632 s
1 hadoop 10 1
1 hive 12 2
1 sqoop 26 3
1 hbase 10 4
1 spark 13 5
1 flink 26 6
1 kafka 14 7
1 oozie 10 8
Time taken: 0.818 seconds, Fetched 8 row(s)
21/06/25 11:35:33 INFO CliDriver: Time taken: 0.818 seconds, Fetched 8 row(s)3 数据分析
分析
从结果表来看只需要增加一列为排序列,只不过是将goods_type列去除掉重新排序,因此我们很容易想到用窗口函数解决排序问题.row_number()便可顺利解决。于是很容易写出如下SQL:
select
user_id,
goods_name,
goods_type,
rk,
case when goods_type!=26 then row_number() over(partition by user_id order by rk) else null end as naturl_rank
from window_goods_test执行结果如下:
1 hadoop 10 1 1
1 hive 12 2 2
1 sqoop 26 3 NULL
1 hbase 10 4 4
1 spark 13 5 5
1 flink 26 6 NULL
1 kafka 14 7 7
1 oozie 10 8 8
Time taken: 2.858 seconds, Fetched 8 row(s)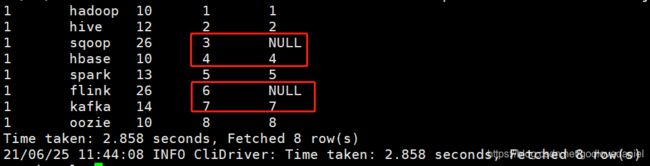 从结果可以看出并非自然排序,不是我们最终想要的目标结果,从实现上看逻辑也清除没什么问题,问题出哪了呢?其原因在于对窗口函数的执行原理及顺序不了解。下面我们进一步通过执行计划来看此SQL的执行过程。SQL如下:
从结果可以看出并非自然排序,不是我们最终想要的目标结果,从实现上看逻辑也清除没什么问题,问题出哪了呢?其原因在于对窗口函数的执行原理及顺序不了解。下面我们进一步通过执行计划来看此SQL的执行过程。SQL如下:
explain select
user_id,
goods_name,
goods_type,
rk,
case when goods_type!=26 then row_number() over(partition by user_id order by rk) else null end as naturl_rank
from window_goods_test具体执行计划如下:
== Physical Plan ==
*Project [user_id#67, goods_name#68, goods_type#69, rk#70, CASE WHEN NOT (goods_type#69 = 26) THEN _we0#72 ELSE null END AS naturl_rank#64]
+- Window [row_number() windowspecdefinition(user_id#67, rk#70 ASC NULLS FIRST, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS _we0#72], [user_id#67], [rk#70 ASC NULLS FIRST]
+- *Sort [user_id#67 ASC NULLS FIRST, rk#70 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(user_id#67, 200)
+- HiveTableScan [user_id#67, goods_name#68, goods_type#69, rk#70], MetastoreRelation default, window_goods_test
Time taken: 0.238 seconds, Fetched 1 row(s)
21/06/25 13:06:24 INFO CliDriver: Time taken: 0.238 seconds, Fetched 1 row(s)

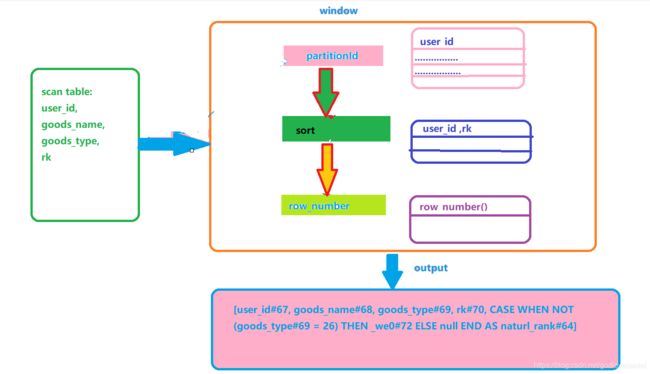
具体执行步骤如下:
(1)扫描表
(2)按照use_id分组
(3)按照user_id和rk进行升序排序
(4)执行row_number()函数进行分析
(5) 使用case when进行判断
由执行计划可以看出case when是在窗口函数之后执行的,与我们同常理解先进行条件判断,满足条件后再执行窗口函数的认知是有差异的。
也就是说case when中使用窗口函数时候,先执行窗口函数再执行条件判断。
上述代码中数据运转流程图如下:
实际上上述SQL被拆分成三部分执行:
第一步:扫描表,获取select的结果集
select
user_id,
goods_name,
goods_type,
rk
from window_goods_test21/06/25 13:49:49 INFO DAGScheduler: Job 9 finished: processCmd at CliDriver.java:376, took 0.039341 s
1 hadoop 10 1
1 hive 12 2
1 sqoop 26 3
1 hbase 10 4
1 spark 13 5
1 flink 26 6
1 kafka 14 7
1 oozie 10 8
Time taken: 0.153 seconds, Fetched 8 row(s)
21/06/25 13:49:49 INFO CliDriver: Time taken: 0.153 seconds, Fetched 8 row(s)
第二步:执行窗口函数
select
user_id,
goods_name,
goods_type,
rk,
row_number() over(partition by user_id order by rk) as naturl_rank
from window_goods_test21/06/25 13:47:33 INFO DAGScheduler: Job 8 finished: processCmd at CliDriver.java:376, took 0.754508 s
1 hadoop 10 1 1
1 hive 12 2 2
1 sqoop 26 3 3
1 hbase 10 4 4
1 spark 13 5 5
1 flink 26 6 6
1 kafka 14 7 7
1 oozie 10 8 8
Time taken: 1.016 seconds, Fetched 8 row(s)
21/06/25 13:47:33 INFO CliDriver: Time taken: 1.016 seconds, Fetched 8 row(s)
第三步:在第二步的结果集中执行case when
select
user_id,
goods_name,
goods_type,
rk,
case when goods_type!=26 then row_number() over(partition by user_id order by rk) else null end as naturl_rank
from window_goods_test其变换结果集如下:
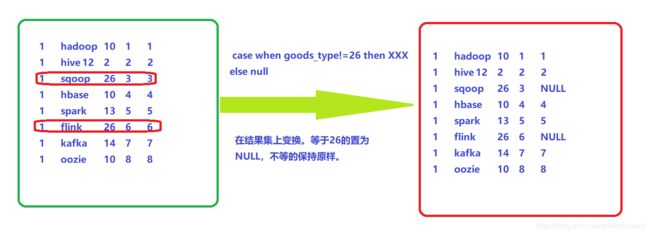
由以上分析我们我们可以看出要想得到正确的SQL需要在窗口函数执行前就需要将数据先过滤掉而不是窗口函数执行后。因此可以想到在where语句里面先过滤,但是根据结果商品类型为26的排序需要置为NULL,因此我门采用union,具体SQL如下:
select user_id
,goods_name
,goods_type
,rk
,row_number() over(partition by user_id order by rk) as naturl_rank
from window_goods_test
where goods_type!=26
union all
select user_id
,goods_name
,goods_type
,rk
,null as naturl_rank
from window_goods_test
where goods_type=261 hadoop 10 1 1
1 hive 12 2 2
1 hbase 10 4 3
1 spark 13 5 4
1 kafka 14 7 5
1 oozie 10 8 6
1 sqoop 26 3 NULL
1 flink 26 6 NULL
Time taken: 1.482 seconds, Fetched 8 row(s)
21/06/25 14:08:14 INFO CliDriver: Time taken: 1.482 seconds, Fetched 8 row(s)但此处的缺点是需要扫描表 window_goods_test两次,显然对于此题不是最好的解法.
下面我们给出其他解法。为了能够先过滤掉商品类型为26的商品,我们可以先在partition by分组中先进行if 语句过滤,如果goods_type!=26则取对应的id进行分组排序,如果goods_type=26则置为随机数再按照随机数分组排序,最后外层再通过goods_type!=26将其过滤掉。此处partition by分组中if 语句中的else后不置为NULL而是随机数,是因为如果置为NULL,goods_type=26的数较多的情况下会被分到一组造成数据倾斜,因此采用了rand()函数。具体SQL如下:
select user_id
,goods_name
,goods_type
,rk
,if(goods_type!=26,row_number() over(partition by if(goods_type!=26,user_id,rand()) order by rk),null) naturl_rank
from window_goods_test
order by rk
------------------------------
此处为了得到最终的结果对rk进行了order by排序,order by执行是在窗口函数之后。
获取的中间结果如下:
select user_id
,goods_name
,goods_type
,rk
,row_number() over(partition by if(goods_type!=26,user_id,rand()) order by rk) naturl_rank
from window_goods_test
order by rk
---------------------------------
1 hadoop 10 1 1
1 hive 12 2 2
1 sqoop 26 3 1
1 hbase 10 4 3
1 spark 13 5 4
1 flink 26 6 1
1 kafka 14 7 5
1 oozie 10 8 6
Time taken: 1.069 seconds, Fetched 8 row(s)
== Physical Plan ==
*Sort [rk#217 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(rk#217 ASC NULLS FIRST, 200)
+- *Project [user_id#214, goods_name#215, goods_type#216, rk#217, naturl_rank#211]
+- Window [row_number() windowspecdefinition(_w0#219, rk#217 ASC NULLS FIRST, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS naturl_rank#211], [_w0#219], [rk#217 ASC NULLS FIRST]
+- *Sort [_w0#219 ASC NULLS FIRST, rk#217 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(_w0#219, 200)
+- *Project [user_id#214, goods_name#215, goods_type#216, rk#217, if (NOT (goods_type#216 = 26)) cast(user_id#214 as double) else rand(-4528861892788372701) AS _w0#219]
+- HiveTableScan [user_id#214, goods_name#215, goods_type#216, rk#217], MetastoreRelation default, window_goods_test
Time taken: 0.187 seconds, Fetched 1 row(s)
21/06/25 14:37:27 INFO CliDriver: Time taken: 0.187 seconds, Fetched 1 row(s)
最终执行结果如下:
1 hadoop 10 1 1
1 hive 12 2 2
1 sqoop 26 3 NULL
1 hbase 10 4 3
1 spark 13 5 4
1 flink 26 6 NULL
1 kafka 14 7 5
1 oozie 10 8 6
Time taken: 1.255 seconds, Fetched 8 row(s)
21/06/25 14:14:21 INFO CliDriver: Time taken: 1.255 seconds, Fetched 8 row(s)
explain select user_id
,goods_name
,goods_type
,rk
,if(goods_type!=26,row_number() over(partition by if(goods_type!=26,user_id,rand()) order by rk),null) naturl_rank
from window_goods_test
order by rk
== Physical Plan ==
*Sort [rk#227 ASC NULLS FIRST], true, 0
+- Exchange rangepartitioning(rk#227 ASC NULLS FIRST, 200)
+- *Project [user_id#224, goods_name#225, goods_type#226, rk#227, if (NOT (goods_type#226 = 26)) _we0#230 else null AS naturl_rank#221]
+- Window [row_number() windowspecdefinition(_w0#229, rk#227 ASC NULLS FIRST, ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW) AS _we0#230], [_w0#229], [rk#227 ASC NULLS FIRST]
+- *Sort [_w0#229 ASC NULLS FIRST, rk#227 ASC NULLS FIRST], false, 0
+- Exchange hashpartitioning(_w0#229, 200)
+- *Project [user_id#224, goods_name#225, goods_type#226, rk#227, if (NOT (goods_type#226 = 26)) cast(user_id#224 as double) else rand(1495282467312192326) AS _w0#229]
+- HiveTableScan [user_id#224, goods_name#225, goods_type#226, rk#227], MetastoreRelation default, window_goods_test
Time taken: 0.186 seconds, Fetched 1 row(s)
21/06/25 14:39:55 INFO CliDriver: Time taken: 0.186 seconds, Fetched 1 row(s)
4 小结
此题给我们的启示:
- (1)case when(或if)语句中嵌套窗口函数时,条件判断语句的执行顺序在窗口函数之后
- (2)窗口函数partition by子句中可以嵌套条件判断语句
欢迎关注石榴姐公众号"我的SQL呀",关注我不迷路
