Java基本程序设计结构
1.一个简单的Java程序
public class Test {
public static void main(String[] args) {
System.out.println("==============args start============");
for (int i = 0; i < args.length; i++) {
System.out.println(args[i]);
}
System.out.println("==============args end============");
System.out.println("args: " + args);
}
}
在Java语言中,规定了入口函数是一个main()方法,该方法有一个String[]类型的参数,但是在很多时候,很多人都使用不上这个参数,也不关心为什么要写这个参数。
那么这个字符串数组类型的参数究竟是什么东西呢?
其实很简单,main()方法中的字符串数组类型的参数就是java命令的参数,使用java命令的方式运行main()方法,会将java命令的参数入参到Java main()方法的字符串数组参数中。
我们通过以下方式来验证:
- 先编写一个Hello.java文件,文件内容如下:
public class Test {
public static void main(String[] args) {
System.out.println("==============args start============");
for (int i = 0; i < args.length; i++) {
System.out.println(args[i]);
}
System.out.println("==============args end============");
System.out.println("args: " + args);
}
}
- 在
Test.java文件的路径下打开cmd命令提示符,运行javac -encoding utf-8 Test.java命令编译该文件,这将会在对应的文件路径下,得到一
个Test.class字节码文件。

当文件中出现中文的时候,比如输出的内容有汉字的时候需要使用utf-8编码,加上了编码格式,保证后续命令行编译输出没有乱码情况
- 使用
java Test命令运行Test.class文件,我们将会得到如下的运行结果:

- 我们这次在java命令后面添加一些参数,这些参数我们可以自己定义。
例如:java Test a b c d我们将会得到如下的运行结果:

正是因为Java main()方法的这个扩展性,使得每一个开发者,可以通过自己定义一些Java命令的参数,实现一些不同的功能。
2.注释
2.1 普通注释
这些注释用一个 “/*” 起头,随后是注释内容,并可跨越多行,最后用一个“/”结束
/* 这是
*一段注释,
* 它跨越了多个行
*/
进行编译时,/ 和 / 之间的所有东西都会被忽略,所以上述注释与下面这段注释并没
有什么不同
/* 这是一段注释,
它跨越了多个行 */
// 这是一条单行注释
2.2 嵌入文档
用于提取注释的工具叫作 javadoc。它采用了部分来自Java编译器的技术,查找我们置入程序
的特殊注释标记。它不仅提取由这些标记指示的信息,也将毗邻注释的类名或方法名提取出
来。这样一来,我们就可用最轻的工作量,生成十分专业的程序文档。
所有javadoc命令都只能出现于 /** 注释中。但和平常一样,注释结束于一个 */ 。主
要通过两种方式来使用javadoc:嵌入的HTML,或使用“文档标记”。其中,“文档标记”(Doc
tags)是一些以“@”开头的命令,置于注释行的起始处(但前导的*会被忽略)
/** 一个类注释 /
public class docTest {
/* 一个变量注释 /
public int i;
/* 一个方法注释 */
public void f() {}
}
嵌入HTML
/**
*
* System.out.println(new Date());
*
*/
/**
* 您甚至可以插入一个列表:
*\
*- 项目一
*- 项目二
*- 项目三
*
*/
引用其它类
@see 类名
@see 完整类名
@see 完整类名#方法名
类文档标记
@version 版本信息
@author 作者信息
变量文档标记
变量文档只能包括嵌入的HTML以及@see引用
方法文档标记
. @param 格式如下: @param 参数名 说明 其中,“参数名”是指参数列表内的标识符,
而“说明”代表一些可延续到后续行内的说明文字。一旦遇到一个新文档标记,就认为前一个说
明结束。可使用任意数量的说明,每个参数一个。
@return 说明
@exception 完整类名 说明【它们是一些特殊的对
象,若某个方法失败,就可将它们“扔出”对象】
注意javadoc只能为 public(公共)和 protected(受保护)成员处理注释文档。“private”(私
有)和“友好”成员的注释会被忽略,我们看不到任何输出(也可以用-private标记
包括private成员)。因为只有public和protected成员才可在文件之外使
用。
3. 编码样式
- 一个非正式的Java编程标准是大写一个类名的首字母。若类名由几个单词构成,那么把它们
紧靠到一起(也就是说,不要用下划线来分隔名字)。此外,每个嵌入单词的首字母都采用
大写形式 - 对于其他几乎所有内容:方法、字段(成员变量)以及对象句柄名称,可接受的样式与类样
式差不多,只是标识符的第一个字母采用小写。
举例:
class AllTheColorsOfTheRainbow {
int anIntegerRepresentingColors;
void changeTheHueOfTheColor(int newHue) {
// ...
}
// ...
}
4.基础数据类型【口诀:4类8种】
4.1 整型

在 C 和 C++ 中, int 和 long 等类型的大小与目标平台相关。在 8086 这样的16 位处理器上整型数值占 2 字节;不过, 在 32 位处理器上,整型数值则为 4 字节。 类似地, 在 32 位处理器上 long 值为 4 字节, 在 64 位处理器上则为 8 字节。由于存在这些差别, 这对编写跨平台程序带来了很大难度。 在 Java 中, 所有的数值类型所占据的字节数量与平台无关。
注意, Java 没有任何无符号(unsigned) 形式的 int、 long、short 或 byte 类型。
在通常情况下,int 类型最常用。但如果表示星球上的居住人数, 就需要使用 long 类型 了。byte 和 short
类型主要用于特定的应用场合,例如,底层的文件处理或者需要控制占用 存储空间量的大数组。
长整型数值有一个后缀 L 或 1 ( 如 4000000000L。) 十六进制数值有一个前缀 Ox 或 0X (如 OxCAFEL
八进制有一个前缀 0 , 例如, 010 对应八进制中的 8。很显然, 八进制表示法比较容易混淆, 所以建议最好不要使用八进制常数
从 Java 7 开始, 加上前缀 0b 或 0B 就可以写二进制数。例如,OblOO丨就是 9。 另外,同样是从 Java 7
开始,还可以为数字字面量加下划线,如用 1_000_000(或0b1111 0100 0010 0010 0000)表示一百万。这些下划线只是为了让人更易读。Java 编译器会去除这些下划线
4.2 浮点型

double 表示这种类型的数值精度是 float 类型的两倍(有人称之为双精度数值)。绝大部 分应用程序都采用 double类型。在很多情况下,float 类型的精度很难满足需求。实际上,只 有很少的情况适合使用 float 类型,例如,需要单精度数据的库,或者需要存储大量数据。 float 类型的数值有一个后缀 F 或 f (例如,3.14F。) 没有后缀 F 的浮点数值(如 3.14 ) 默认为 double 类型。当然,也可以在浮点数值后面添加后缀 D 或 d (例如,3.14D) 。
浮点数值不适用于无法接受舍入误差的金融计算中。 例如,命令 System.out.println( 2.0-1.1 ) 将打印出 0.8999999999999999, 而不是人们想象的 0.9。这种舍入误差的主要原因是浮点数值采用二进制系统表示, 而在二进制系统中无法精确地表示分数 1/10。这就好像十进制无法精确地表示分数 1/3—样。如果在数值计算中不允许有任何舍入误差,就应该使用 BigDecimal类
4.3 char 类型
char 类型原本要用单引号括起来于表示单个字符。不过,现在情况已经有所变化。 如今,有些 Unicode 字符可以用一个 char 值描述,另外一些 Unicode 字符则需要两个 char 值。char 类型的值可以表示为十六进制值,其范围从 \u0000 到 \Uffff。例如:W2122 表示注册符号 (® ), \u03C0 表示希腊字母 Π
Unicode 转义序列会在解析代码之前得到处理。 例如,"\u0022+\u0022”并不是一个由引号(U+0022)包围加号构成的字符串。 实际上, \u0022 会在解析之前转换为 ", 这会 得 到 也 就 是 一 个 空 串。更隐秘地,一定要当心注释中的 \u。 注释
// \u00A0 is a newline会产生一个语法错误, 因为读程序时\u00A0会替换为一个换行符类似地,下面这个注释// Look inside c:\users也会产生一个语法错误, 因为 \u> 后面并未跟着 4 个十六进制数

要想弄清 char 类型, 就必须了解 Unicode 编码机制。Unicode 打破了传统字符编码机制
的限制。
历史原因:在 Unicode 出现之前, 已经有许多种不同的标准:美国的 ASCII、 西欧语言中的ISO 8859-1 俄罗斯的 KOI-8、 中国的 GB 18030 和 BIG-5 等。这样就产生了下面两个问题:一个是对于任意给定的代码值,在不同的编码方案下有可能对应不同的字母;二是采用大字符集的语言其编码长度有可能同。例如,有些常用的字符采用单字节编码, 而另一些字符则需要两个或更多个字节。
改进:在设计 Java 时决定采用 16 位的 Unicode 字符集,这样会比使用 8 位字符集的程序设计语言有很大的改进。十分遗憾, 经过一段时间, 不可避免的事情发生了。Unicode 字符超过了 65 536 个,其主要原因是增加了大量的汉语、 日语和韩语中的表意文字。现在,16 位的 char 类型已经不能满足描述所有 Unicode 字符的需要了。
以下是维基百科内容:
16位的 cha r如何描述所有 Unicode 字符
从 Java SE 5.0 开始。码点( code point) 是指与一个编码表中的某个字符对应的代码值。在 Unicode标准中,码点采用十六进制书写,并加上前缀 U+, 例如 U+0041 就是拉丁字母 A 的码点。Unicode 的码点可以分成 17个代码级别( codeplane)。第一个代码级别称为基本的多语言级别( basicmultilingual plane ), 码点从U+0000 到U+FFFF, 其中包括经典的 Unicode 代码;其余的 16个级另丨〗码点从 U+10000 到 U+10FFFF ,其中包括一些辅助字符(supplementary character)。UTF-16 编码采用不同长度的编码表示所有 Unicode码点。在基本的多语言级别中,每个字符用 16 位表示,通常被称为代码单元( code unit); 而辅助字符采用一对连续的代码单元进行编码。这样构成的编码值落人基本的多语言级别中空闲的 2048 字节内,通常被称为替代区域(surrogate area) [ U+D800 ~ U+DBFF 用于第一个代码单兀,U+DC00 ~ U+DFFF用于第二个代码单元。这样设计十分巧妙,我们可以从中迅速地知道一个代码单元是一个字符的编码,还是一个辅助字符的第一或第二部分。例如,⑪是八元数(http://math.ucr.edu/home/baez/octonions) 的一个数学符号,码点为 U+1D546, 编码为两个代码单兀 U+D835 和U+DD46。(关于编码算法的具体描述见http://en.wikipedia.org/wiki/UTF-l6 )
强烈建议不要在程序中使用 char 类型,除非确实需要处理 UTF-16 代码单元。最好 将字符串作为抽象数据类型处理
4.4 boolean 类型
boolean (布尔)类型有两个值:false 和 true, 用来判定逻辑条件 整型值和布尔值之间
不能进行相互转换。
在 C++ 中, 数值甚至指针可以代替 boolean 值。值 0 相当于布尔值 false, 非 0 值相当于布尔值 true, 在
Java 中则不是这样,, 因此, Java 程序员不会遇到下述麻烦:
if (x = 0) // oops… meant x = 0
在 C++ 中这个测试可以编译运行, 其结果总是 false: 而在 Java 中, 这个测试将不 能通过编译, 其原因是整数表达式 x = 0 不能转换为布尔值。
5.变量
5.1 可以在一行中声明多个变量:
不能使用 Java 保留字作为变量名
int i , j; // both are integers
5.2 变量初始化
声明一个变量之后,必须用赋值语句对变量进行显式初始化, 千万不要使用未初始化的
变量。例如, Java 编译器认为下面的语句序列是错误的
int vacationDays;
System.out.println(vacationDays): // ERROR variable not initialized
C 和 C++ 区分变量的声明与定义。例如:
int i = 10; 是一个定义
而 extern int i; 是一个声明。
在 Java中, 不区分变量的声明与定义。
5.3 常量
在 Java 中, 利用关键字 final 指示常量。例如:
public class Test {
public static void main(String[] args) {
final double CM_PER_INCH = 2.54;
double paperWidth = 8.5;
double paperHeight = 11;
System.out.println("Paper size in centimeters: "
+ paperWidth * CM_PER_INCH + "by" + paperHeight * CM_PER_INCH);
}
}
//Paper size in centimeters: 21.59by27.94
在 Java 中,经常希望某个常量可以在一个类中的多个方法中使用,通常将这些常量称为
类常量。可以使用关键字 static fina丨设置一个类常量。 下面是使用类常量的示例:
public class Test {
public static final double CM_PER_INCH2 = 2.54;
public static void main(String[] args) {
double paperWidth = 8.5;
double paperHeight = 11;
System.out.println("Paper size in centimeters: "
+ paperWidth * CM_PER_INCH2 + "by" + paperHeight * CM_PER_INCH2);
}
}
//Paper size in centimeters: 21.59by27.94
需要注意, 类常量的定义位于 maiii 方法的外部。因此,在同一个类的其他方法中也可
以使用这个常量。而且,如果一个常量被声明为 public,那么其他类的方法也可以使用这个
常量。 在这个示例中,Constants2.CM_PER-INCH 就是这样一个常童。
6.运算符
6.1 可移植性和性能间的平衡
需要严格计算【了解】 很多 Intel 处理器计算 x * y,并且将结果存储在 80 位的寄存器中, 再除以 z 并将结果截断为 64 位„ 这样可以得到一个更加精确的计算结果,并且还能够避免产生指数溢出。但是, 这个结果可能与始终在 64 位机器上计算的结果不一样。 因此,Java 虚拟机的最初规范规定所有的中间计算都必须进行截断这种行为遭到了数值计算团体的反对。截断计算不仅可能导致溢出, 而且由于截断操作需要消耗时间, 所以在计算速度上实际上要比精确计算慢。 为此,Java程序设计语言承认了最优性能与理想结果之间存在的冲突,并给予了改进。在默认情况下, 虚拟机设计者允许对中间计算结果采用扩展的精度。但是,对于使用 strictfj) 关键字标记的方法必须使用严格的浮点计算来生成可再生的结果。例如,可以把 main 方法标记为:
publicstatic strictfp void main(String[] args)
于是,在 main 方法中的所有指令都将使用严格的浮点计算。如果将一个类标记为strictfp,这个类中的所有方法都要使用严格的浮点计算。实际的计算方式将取决于 Intel 处理器的行为。在默认情况下,中间结果允许使用扩展的指数,但不允许使用扩展的尾数(Intel 芯片在截断尾数时并不损失性能)。因此,这两种方式的区别仅仅在于采用默认的方式不会产生溢出,而采用严格的计算有可能产生溢出对大多数程序来说, 浮点溢出不属于大向题。
6.2常用数学函数
double y = Math.sqrt(3.14);//开平方,形参是double类型,返回值也是double类型
double y = Math.pow(x, a);//幂运算将,形参是double类型,返回值也是double类型
Math 类提供了一些常用的三角函数:
Math.sin
Math.cos
Math.tan
Math.atan
Math.atan2
有指数函数以及它的反函数—自然对数以及以 10 为底的对数:
Math.exp
Math.log
Math.loglO
最后,Java 还提供了两个用于表示 TC 和 e 常量的近似值:
Math.PI
Math.E
小技巧:不必在数学方法名和常量名前添加前缀“ Math”, 只要在源文件的顶部加上下面
这行代码就可以了。
import static java.lang.Math.*;
System.out.println("The square root of \u03C0 is " + sqrt(PI));
精度和性能:在 Math 类中, 为了达到最快的性能, 所有的方法都使用计算机浮点单元中的例
程… 如果得到一个完全可预测的结果比运行速度更重要的话, 那么就应该使用 StrictMath
类
6.3 数值类型之间的转换
某些整型数值转换为 float 类型时, 将会得到同样大小的结果,但却失去了一定
的精度
int n = 123456789;
float f = n; // f is 1.23456792E
System.out.println("n: " + n);
System.out.println("f: " + f);
System.out.printf("格式化输出f: %f\n", f);
//n: 123456789
//f: 1.23456792E8
//格式化输出f: 123456792.000000
//float ff = 3.14;//编译报错原因:因为小数会自动隐式提升到 double, 因此需要在小数后加上F或者f
float ff = 3.14f;
转换规则:当使用上面两个数值进行二元操作时(例如 n + f,n 是整数, f 是浮点数,) 先要将两个操作数转换为同一种类型,然后再进行计算。
- 如果两个操作数中有一个是 double 类型, 另一个操作数就会转换为 double 类型。
- 否则,如果其中一个操作数是 float 类型,另一个操作数将会转换为 float 类型。
- 否则, 如果其中一个操作数是 long 类型, 另一个操作数将会转换为 long 类型。
- 否则, 两个操作数都将被转换为 int 类型
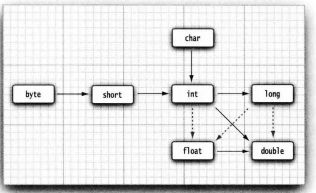
6.4 强制类型转换
byte b1 = 1;
byte b2 = 2;
byte b3 = (byte) (b1+b2);//编译报错原因:byte类型会隐式提升为 int,因此需要类型强转
int i1= (int) Math.round(3.14);//其原因是 round 方法返回的结果为 long 类型,由于存在信息丢失的可能性,所以只有使用显式的强制类型转换才能够将 long 类型转换成 int 类型。
如果试图将一个数值从一种类型强制转换为另一种类型, 而又超出了目标类型的表示范围,结果就会截断成一个完全不同的值。例如,(byte )> 300 的实际值为 44
System.out.println("byte取值范围: [" + Byte.MAX_VALUE + ", " + Byte.MIN_VALUE + "]");
System.out.println("(byte)128: " + (byte) 128);
System.out.println("(byte)(-129): " + (byte) (-129));
//byte取值范围: [127, -128]
//(byte)128: -128
//(byte)(-129): 127
System.out.println(Integer.MAX_VALUE);//System.out.println()默认内部数据类型是 int,超出范围即溢出
System.out.println(Integer.MAX_VALUE+1);
System.out.println(Integer.MIN_VALUE);
System.out.println(Integer.MIN_VALUE-1);
//2147483647
//-2147483648
//-2147483648
//2147483647

附加
不要在 boolean 类型与任何数值类型之间进行强制类型转换, 这样可以防止
发生错误。只有极少数的情况才需要将布尔类型转换为数值类型,这时可以使用条件表 达式 b ? 1:0
6.5 优先级

- % 表示取余, 不仅仅可以对 int 求模, 也能对 double 来求模
- &&,||会出现短路运算
- 左移 <<: 最左侧位不要了, 最右侧补 0【 左移 1 位, 相当于原数字 * 2. 左移 N 位, 相当于原数字 * 2 的N次方.】
- 右移 >>: 最右侧位不要了, 最左侧补符号位(正数补0, 负数补1)【右移 1 位, 相当于原数字 / 2. 右移 N 位, 相当于原数字 / 2 的N次方.】
- 无符号右移 >>>: 最右侧位不要了, 最左侧补 0.
- 没有无符号左移<<<
- 由于计算机计算移位效率高于计算乘除, 当某个代码正好乘除 2 的N次方的时候可以用移位运算代替.移动负数位或者移位位数过大都没有意义
System.out.println(10 < 20 && 20 < 30); 虽然关系运算符优先级高于逻辑运算符但此时明显是先计算的 10< 20 和 20 < 30, 再计算 &&. 否则 20 && 20 这样的操作是语法上有误的(&& 的操作数只能是 boolean).
6.6 结合赋值和运算符
可以在赋值中使用二元运算符,这是一种很方便的简写形式。例如:
X += 4;
等价于:
x = x + 4;
(一般地, 要把运算符放在 = 号左边,如 *=,%=,/=,-=,<<=,>>=,>>>=,&=, |=,,^=)
6.7 自增与自减运算
int n = 12;
n++;
将 n 的值改为 13。由于这些运算符会改变变量的值,所以它们的操作数不能是数值。例如,
4++ 就不是一个合法的语句。实际上, 这些运算符有两种形式;上面介绍的是运算符放在操作数后面的“ 后缀” 形式。还有一种“ 前缀” 形式:++n。后缀和前缀形式都会使变量值加 1 或减 1。但用在表达式中时,二者就有区别了。前缀形式会先完成加 1; 而后缀形式会使用变量原来的值。
int m = 7;
int n = 7;
int a = 2 * ++m; // now a is 16, m is 8
int b = 2 * n++; // now b is 14, n is 8
建议不要在表达式中使用 ++, 因为这样的代码很容易让人闲惑,而且会带来烦人的 bug。
6.8 枚举类型
public class Test {
enum Size {SMALL, MEDIUM, LARGE, EXTRA};
public static void main(String[] args) {
Size s = Size.MEDIUM;
System.out.println(s);
}
}
//MEDIUM
7.字符串
从概念上讲, Java 字符串就是 Unicode 字符序列。 例如, 串“ Java\u2122” 由 5 个Unicode 字符 J、a、 v、a 和™。Java 没有内置的字符串类型, 而是在标准 Java 类库中提供了一个预定义类,很自然地叫做 String。每个用双引号括起来的字符串都是 String类的一个实
例:
public class Test {
public static void main(String[] args) {
String str = "";
String str1 = null;
String str2 = "Hello World";
System.out.println(str);
System.out.println(str1);
System.out.println(str2);
}
}
//
//null
//Hello World
7.1 子串
public class Test {
public static void main(String[] args) {
String greeting = "Hello";
String s = greeting.substring(0, 3);
System.out.println(s);
}
}
//Hel
substring 方法的第二个参数是不想复制的第一个位置。这里要复制位置为 0、 1 和 2 (从 0 到 2, 包括 0 和 2 )
的字符。在 substring 中从 0 开始计数,直到 3 为止, 但不包含 3
7.2 拼接
public class Test {
public static void main(String[] args) {
String expletive = "Expletive";
String PC13 = "deleted";
String message = expletive + PC13;
System.out.println(message);
}
}
//Expletivedeleted
+ 号连接(拼接)两个字符串,“ Expletivedeleted” 赋给变量 message
当将一个字符串与一个非字符串的值进行拼接时,后者被转换成字符串
public class Test {
public static void main(String[] args) {
int age = 13;
String rating = "PC" + age;
System.out.println(rating);
}
}
//PC13
这种特性通常用在输出语句中。例如:System.out.println("The answer is " + answer);
如果需要把多个字符串放在一起, 用一个定界符分隔,可以使用静态 join 方法
public class Test {
public static void main(String[] args) {
String all = String.join(" / ", "S", "M", "L", "XL");
System.out.println(all);
}
}
//S / M / L / XL
7.3 不可变字符串
String 类没有提供用于修改字符串的方法。 如果希望将 src的内容修改为“ Hello Java!”,不能直接地将 greeting 的最后位置的字符修改为‘Java ’ 和 ‘!’ 这对于 C 语言来说,将会感到无从下手。如何修改这个字符串呢? 在 Java中实现这项操作非常容易。首先提取需要的字符, 然后再拼接上替换的字符串
public class Test {
public static void main(String[] args) {
String src = "Hello World";
src = src.substring(0, 5) + " Java!";
System.out.println(src);
}
}
//Hello Java!
理解 String 类不可变:
由于不能修改 Java 字符串中的字符, 所以在 Java 文档中将 String 类对象称为不可变字 符串, 如同数字 3 永远是数字 3—样,字符串“ Hello” 永远包含字符 H、 e、1、 1 和 o 的代 码单元序列, 而不能修改其中的任何一个字符。当然, 可以修改字符串变量 src, 让它 引用另外一个字符串, 这就如同可以将存放 3 的数值变量改成存放 4 一样
思考
这样做是否会降低运行效率呢? 看起来好像修改一个代码单元要比创建一个新字符串更 加简洁。答案是:也对,也不对。的确, 通过拼接“ Hello” 和“ Java! ” 来创建一个新字符串的 效率确实不高。但是,不可变字符串却有一个优点:编译器可以让字符串共享。为了弄清具体的工作方式,可以想象将各种字符串存放在公共的存储池中。字符串变量 指向存储池中相应的位置。如果复制一个字符串变量,原始字符串与复制的字符串共享相同 的字符。 总而言之,Java 的设计者认为共享带来的高效率远远胜过于提取、 拼接字符串所带来的 低效率
学 C 的同学第一次接触 Java 字符串的时候, 常常会感到迷惑, 因为他们总将字符串认为是字符型数组:
char greeting[ ] = "Hello";
//这种认识是错误的, Java 字符串大致类似于 char* 指针,
char* src= "Hello World";
//当采用另一个字符串替换 src 的时候, Java 代码大致进行下列操作:
char* temp = mal1oc(11);
strncpy(temp, src, 5);
strncpy(temp + 1, "Java!, 3);
src= temp;
以 Java 角度考虑这样做会不会产生内存遗漏呢? 毕竞, 原始字符串放置在堆中。十分幸运,强大的 JVM 将自动地进行垃圾回收。 如果一块内存不再使用了, 系统最终会将其回收。
有了前边的理论知识下面一幅图解释清楚不可变
字符串是一种不可变对象. 它的内容不可改变.String 类的内部实现也是基于 char[] 来实现的, 但是 String 类并没有提供 set 方法之类的来修改内部的字符数组.
public class Test {
public static void main(String[] args) {
String str = "hello" ;
str = str + " world" ;
str += "!!!" ;
System.out.println(str);
}
}
//hello world!!!
形如 += 这样的操作, 表面上好像是修改了字符串, 其实不是. 内存变化如下:

+= 之后 str 打印的结果却是变了, 但是不是 String 对象本身发生改变, 而是 str 引用到了其他的对象
回顾引用
引用相当于一个指针, 里面存的内容是一个地址. 我们要区分清楚当前修改到底是修改了地址对应 内存的内容发生改变了, 还是引用中存的地址改变了
那么如果实在需要修改字符串, 例如, 现有字符串 str = “Hello” , 想改成 str = “hello” , 该怎么办?
7.3.1 substring原地修改
a) 常见办法: 借助原字符串, 创建新的字符串
public class Test {
public static void main(String[] args) {
String str = "Hello";
str = "h" + str.substring(1);
System.out.println(str);
}
}
7.3.2 反射修改
b) 特殊办法(了解): 使用 “反射” 这样的操作可以破坏封装, 访问一个类内部的 private 成员.
IDEA 中 ctrl + 左键 跳转到 String 类的定义, 可以看到内部包含了一个 char[] , 保存了字符串的内容.

public class Test {
public static void main(String[] args) {
String str = "Hello";
// 获取 String 类中的 value 字段. 这个 value 和 String 源码中的 value 是匹配的
Field valueField = null;
try {
valueField = String.class.getDeclaredField("value");
} catch (NoSuchFieldException e) {
e.printStackTrace();
}
// 将这个字段的访问属性设为 true
valueField.setAccessible(true);
// 把 str 中的 value 属性获取到
char[] value = new char[0];
try {
value = (char[]) valueField.get(str);
} catch (IllegalAccessException e) {
e.printStackTrace();
}
// 修改 value 的值
value[0] = 'G';
System.out.println(str);
}
}
//Gello
为什么 String 要不可变?(不可变对象的好处是什么?) (了解)
- 方便实现字符串对象池. 如果 String 可变, 那么对象池就需要考虑何时深拷贝字符串的问题了.
- 不可变对象是线程安全的.
- 不可变对象更方便缓存 hash code, 作为 key 时可以更高效的保存到 HashMap 中.
注意事项: 如下代码不应该在你的开发中出, 会产生大量的临时对象, 效率比较低
public class Test {
public static void main(String[] args) {
String str = "hello";
for (int x = 0; x < 1000; x++) {
str += x;
}
System.out.println(str);
}
}
输出结果:

7.4 检测字符串是否相等
可以使用 equals 方法检测两个字符串是否相等。对于表达式:s.equals(t)
如果字符串 s 与字符串 t 相等, 则返回 true ; 否则, 返回 false。需要注意,s与 t 可以是字符串变量, 也可以是字符串字面量。 例如, 下列表达式是合法的:
public class Test {
public static void main(String[] args) {
System.out.println("Hello World".equals("Hello Java"));
}
}
//false
要想检测两个字符串是否相等,而不区分大小写, 可以使用 equalsIgnoreCase 方法。
public class Test {
public static void main(String[] args) {
System.out.println("HELLO".equalsIgnoreCase("hello"));
}
}
//true
一定不要使用==运算符检测两个字符串是否相等! 这个运算符只能够确定两个字串 是否放置在同一个位置上。当然, 如果字符串放置在同一个位置上,它们必然相等。但是, 完全有可能将内容相同的多个字符串的拷贝放置在不同的位置上。
public class Test {
public static void main(String[] args) {
String greeting = "Hello";
System.out.println(greeting == "Hello");// probably true
System.out.println(greeting.substring(0, 3).intern() == "Hel");// probably true
System.out.println(greeting.substring(0, 3) == "Hel");// probably false
}
}
//true
//true
//false
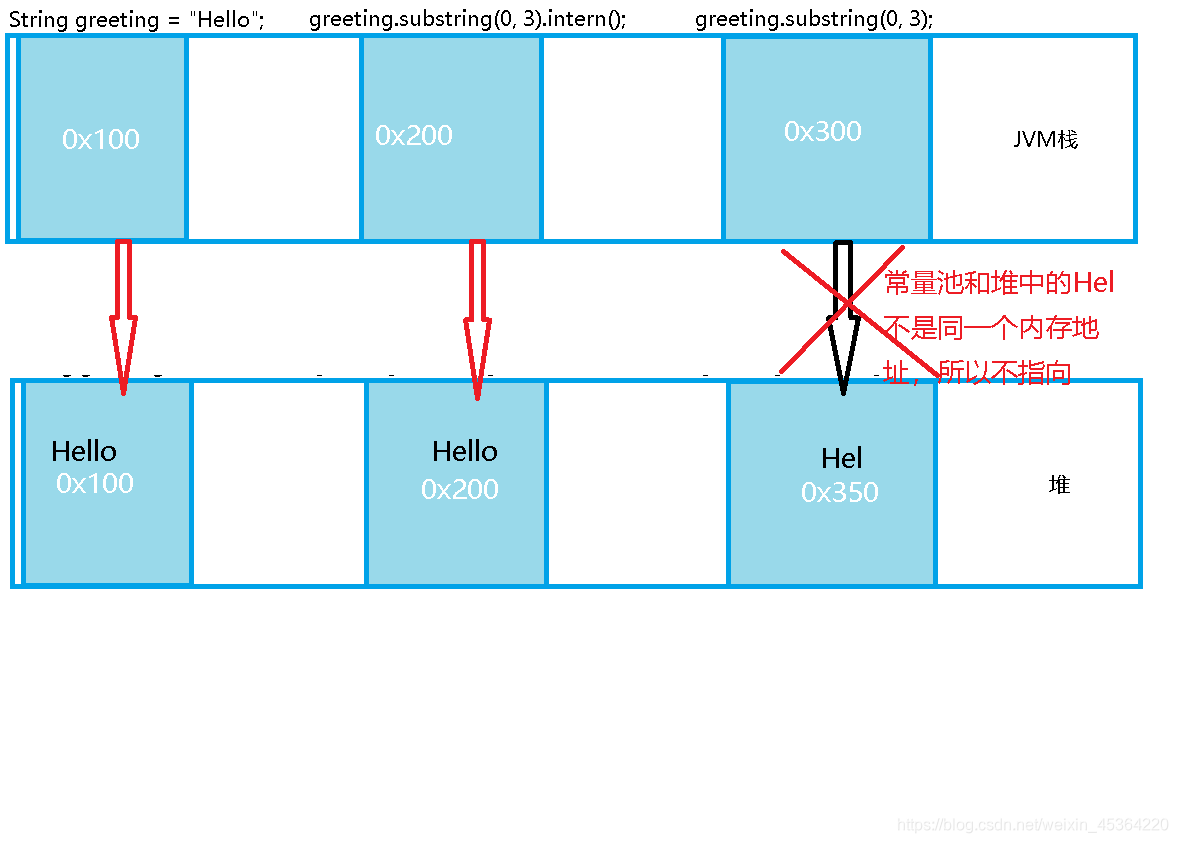
由于 String 是引用类型, 因此对于以下代码
String greeting = “Hello”;
greeting.substring(0, 3).intern();
greeting.substring(0, 3);
内存布局如图
如果没理解==比较的是两个元素的位置的话,再举个例子。
我们都知道 Java 字符串初始化的方式有如下几种:
// 方式一
String str = “Hello Bit”;
// 方式二
String str2 = new String(“Hello Bit”);
// 方式三
char[] array = {‘a’, ‘b’, ‘c’};
String str3 = new String(array);
在 官方文档 上我们可以看到
String 还支持很多其.他的构造方式, 我们用到的时候去查就可以了。
“hello” 这样的字符串也是字面值常量, 类型也是 String. String 也是引用类型. String str = “Hello”; 这样的代码内存布局如下:

回忆 "引用"
引用类似于 C 语言中的指针, 只是在栈上开辟了一小块内存空间保存一个地址. 但是引用和指针又 不太相同,指针能进行各种数字运算(指针+1)之类的, 但是引用不能, 这是一种 “没那么灵活” 的指针. 另外, 也可以把引用想象成一个标签, “贴” 到一个对象上. 一个对象可以贴一个标签, 也可以贴多个. 如果一个对象上面一个标签都没有, 那么这个对象就会被 JVM 当做垃圾对象回收掉.Java 中数组, String, 以及自定义的类都是引用类型
public class Test {
public static void main(String[] args) {
String str1 = "Hello";
String str2 = str1;
System.out.println(str1 == str2);
}
}
//true

那么有同学可能会说, 是不是修改 str1 , str2 也会随之变化呢?
public class Test {
public static void main(String[] args) {
String str1 = new String("Hello");
String str2 = new String("Hello");
System.out.println(str1 == str2);
str1 = "World";
System.out.println(str2);
}
}
//false
//Hello
我们发现, “修改” str1 之后, str2 也没发生变化, 还是 hello? 事实上, str1 = "world"这样的代码并不算 “修改” 字符串, 而是让 str1 这个引用指向了一个新的 String 对象.
通过 String str1 = new String(“Hello”); 这样的方式创建的 String 对象相当于再堆上另外开辟了空间来存储 “Hello” 的内容, 也就是内存中存在两份 “Hello”.
String 使用 == 比较并不是在比较字符串内容, 而是比较两个引用是否是指向同一个对象
关于对象的比较
面向对象编程语言中, 涉及到对象的比较, 有三种不同的方式, 比较身份, 比较值, 比较类型. 在大部分编程语言中 ==是用来比较比较值的. 但是 Java 中的 == 是用来比较身份的. 如何理解比较值和比较身份呢? 经过两张图,应该清楚所谓的身份了吧,也就是 JVM栈 存储的引用指向了 堆,因此 == 比较的也就是引用相不相同,也就是身份相同与否了。

equals方法比较字符堆上的串是否相等
public class Test {
public static void main(String[] args) {
String str1 = new String("Hello");
String str2 = new String("Hello");
System.out.println(str1 == str2);
System.out.println(str1.equals(str2));
}
}
//false
//true
好奇的小伙伴可能想知道为什么上文中System.out.println(greeting.substring(0, 3).intern() == "Hel");// probably true为何输出的是true,这就涉及到了 字符串常量池 这一概念
7.5 字符串常量池
在上面的例子中, String类的两种实例化操作, 直接赋值和 new 一个新的 String
7.5.1 直接赋值
String str1 = “hello” ;
String str2 = “hello” ;
String str3 = “hello”;
System.out.println(str1 == str2); // true
System.out.println(str1 == str3); // true
System.out.println(str2 == str3); // true
为什么现在并没有开辟新的堆内存空间呢?
前文提到了String类的设计使用了共享设计模式,因为设计者认为共享资源带来的效益高于性能

在JVM底层实际上会自动维护一个对象池(字符串常量池)
- 如果现在采用了直接赋值的模式进行String类的对象实例化操作,那么该实例化对象(字符串内
容)将自动保存到这个对象池之中. - 如果下次继续使用直接赋值的模式声明String类对象,此时对象池之中如若有指定内容,将直接进
行引用 - 如若没有,则开辟新的字符串对象而后将其保存在对象池之中以供下次使用
7.5.2 理解 “池” (pool)
“池” 是编程中的一种常见的, 重要的提升效率的方式, 我们会在未来的学习中遇到各种 “内存池”, “线程池”, “数据库连接池” …
然而池这样的概念不是计算机独有, 也是来自于生活中. 举个栗子:
现实生活中有一种女神, 称为 “绿茶”, 在和高富帅谈着对象的同时,还可能和别的屌丝搞暧昧. 这时 候这个屌丝被称为 “备胎”. 那么为啥要有备胎? 因为一旦和高富帅分手了, 就可以立刻找备胎接盘, 这样效率比较高. 如果这个女神, 同时在和很多个屌丝搞暧昧, 那么这些备胎就称为 备胎池.
7.5.3 采用构造方法
类对象使用构造方法实例化是标准做法。分析如下程序:
String str = new String("hello") ;

这样的做法有两个缺点:
- 如果使用String构造方法就会开辟两块堆内存空间,并且其中一块堆内存将成为垃圾空间(字符串常
量 “hello” 也是一个匿名对象, 用了一次之后就不再使用了, 就成为垃圾空间, 会被 JVM 自动回收掉). - 字符串共享问题. 同一个字符串可能会被存储多次, 比较浪费空间
我们可以使用 String 的 intern 方法来手动把 String 对象加入到字符串常量池中
public class Test {
public static void main(String[] args) {
// 该字符串常量并没有保存在对象池之中
String str1 = new String("hello") ;
String str2 = "hello" ;
System.out.println(str1 == str2);//false
String str11 = new String("hello").intern() ;
String str22 = "hello" ;
System.out.println(str11 == str22);//true
}
}
//false
//true

面试题:请解释String类中两种对象实例化的区别
- 直接赋值:只会开辟一块堆内存空间,并且该字符串对象可以自动保存在对象池中以供下次 使用。
- 构造方法:会开辟两块堆内存空间,不会自动保存在对象池中,可以使用intern()方法手工入 池。
综上, 我们一般采取直接赋值的方式创建 String 对象.
7.6 String 常用 API
| 函数原型 | 简介 |
|---|---|
| char charAt (int index) | 返回给定位置的代码单元。除非对底层的代码单元感兴趣, 否则不需要调用这个方法 |
| int compareTo(String other) | 按照字典顺序,如果字符串位于 other 之前, 返回一个负数;如果字符串位于 other 之后,返回一个正数;如果两个字符串相等,返回 0 |
| boolean equals(0bject other) | 如果字符串与 other 相等, 返回 true |
| boolean equalsIgnoreCase(String other ) | 如果字符串与 other 相等 ( 忽略大小写,) 返回 true |
| boolean startsWith(String prefix ) | 如果字符串以 prefix 开头, 则返回 true |
| boolean endsWith(String suffix ) | 如果字符串以 suffix结尾, 则返回 true |
| int indexOf(String str) | |
| int indexOf(String str, int fromlndex ) | |
| int indexOf(int cp) | |
| int indexOf(int cp, int fromlndex ) | 返回与字符串 str 或代码点 cp 匹配的第一个子串的开始位置。这个位置从索引 0 或fromlndex 开始计算。 如果在原始串中不存在 str,返回 -1 |
| int lastIndexOf(String str) | |
| int lastIndexOf(String str, int fromlndex ) | |
| int lastindexOf(int cp) | |
| int lastindexOf(int cp, int fromlndex ) | 返回与字符串 str 或代码点 cp 匹配的最后一个子串的开始位置。 这个位置从原始串尾端或 fromlndex 开始计算 |
| int length( ) | 返回字符串的长度 |
| String substring(int beginlndex ) | |
| String substring(int beginlndex, int endlndex ) | 返回一个新字符串。这个字符串包含原始字符串中从 beginlndex 到串尾或 endlndex-l的所有代码单元 |
| String toLowerCase( ) | 返回一个新字符串,这个字符串将原始字符串中的大写字母改为小写 |
| String toUpperCase( ) | 返回一个新字符串。 这个字符串将原始字符串中的所有小写字母改成了大写字母 |
| String trim( ) | 返回一个新字符串。这个字符串将删除了原始字符串头部和尾部的空格 |
| String join(CharSequence delimiter, CharSequence … elements ) | 返回一个新字符串, 用给定的定界符连接所有元素 |
7.7 构建字符串
使用场景分析:有些时候, 需要由较短的字符串构建字符串, 例如, 按键或来自文件中的单词。采用字符串连接的方式达到此目的效率比较低。每次连接字符串, 都会构建一个新的 String 对象,既耗时, 又浪费空间。使用 StringBuildei•类就可以避免这个问题的发生
如果需要用许多小段的字符串构建一个字符串, 那么应该按照下列步骤进行。 首先, 构建一个空的字符串构建器:
public class Test {
public static void main(String[] args) {
//效率低下:一般不这么构建字符串
String str = "hello";
for (int x = 0; x < 1000; x++) {
str += x;
}
System.out.println(str);
//快捷
StringBuilder builder = new StringBuilder("hello");
for (int i = 0; i < 1000; i++) {
builder.append(i);
}
String completedString = builder.toString();//在需要构建字符串时就凋用 toString 方法, 将可以得到一个 String 对象, 其中包含了构建器中的字符序列
System.out.println(completedString);
}
}
附加
在 JDK5.0 中引入 StringBuilder 类。 这个类的前身是 StringBuffer, 其效率稍有些 低, 但允许采用多线程的方式执行添加或删除字符的操作。如果所有字符串在一个单线 程中编辑 (通常都是这样,) , 则应该用StringBuilder 替代它。 这两个类的 AP丨是相同的
String Builder 常用 API
| 函数原型 | 简介 |
|---|---|
| StringBuilder() | 构造一个空的字符串构建器 |
| int length() | 返回构建器或缓冲器中的代码单元数量 |
| Stri ngBuilder append(String str) | 追加一个字符串并返回 this |
| StringBuilder append(char c) | 追加一个代码单元并返回 this |
| void setCharAt(int i ,char c) | 将第 i 个代码单元设置为 c |
| StringBuilder insert(int offset,String str) | 在 offset 位置插入一个字符串并返回 this |
| StringBuilder insert(int offset,char c) | 在 offset 位置插入一个代码单元并返回 this |
| StringBuilder delete(int startindex,int endlndex) | 删除偏移量从 startindex 到 -endlndex-1 的代码单元并返回 this |
| String toString() | 返回一个与构建器或缓冲器内容相同的字符串 |
8.输入输出
8.1 读取输入
打印输出到“ 标准输出流”(即控制台窗口)是一件非常容易的事情,只要调用System.out.println 即可。然而,读取“ 标准输人流” System.in 就没有那么简单了。要想通过控制台进行输人,首先需要构造一个 Scanner 对象,并与“ 标准输人流” System.in 关联
Scanner in = new Scanner(System.in);
8.2 Scanner 常用 API
| 函数原型 | 简介 |
|---|---|
| Scanner (InputStream in) | 用给定的输人流创建一个 Scanner 对象 |
| String nextLine( ) | 读取输入的下一行内容,如果前边有其其它输入,那么它会读取到回车换行符"\n",因此需要使用nextLine()的时候需要把它放在所有输入中第一个 |
| String next( ) | 读取输入的下一个单词(以空格作为分隔符。) |
| int nextlnt( ) | |
| double nextDouble( ) | 读取并转换下一个表示整数或浮点数的字符序列 |
| boolean hasNext( ) | 检测输人中是否还有其他单词 |
| boolean hasNextInt( ) | |
| boolean hasNextDouble( ) | 检测是否还有表示整数或浮点数的下一个字符序列 |
8.3 格式化输出
如下:
%8.2f:可以用 8 个字符的宽度和小数点后两个字符的精度打印 x。也就是说,打印输出一个空格和
7 个字符
%,.2f:另外,还可以给出控制格式化输出的各种标志。表 3-6 列出了所有的标志。例如,逗号
标志增加了分组的分隔符
public class Test {
public static void main(String[] args) {
double x = 10000.0 / 3.0;
System.out.println(x);
System.out.printf("%,.2f\n", x);
System.out.printf("%8.2f\n", x);
}
}
//3333.3333333333335
//3,333.33
// 3333.33
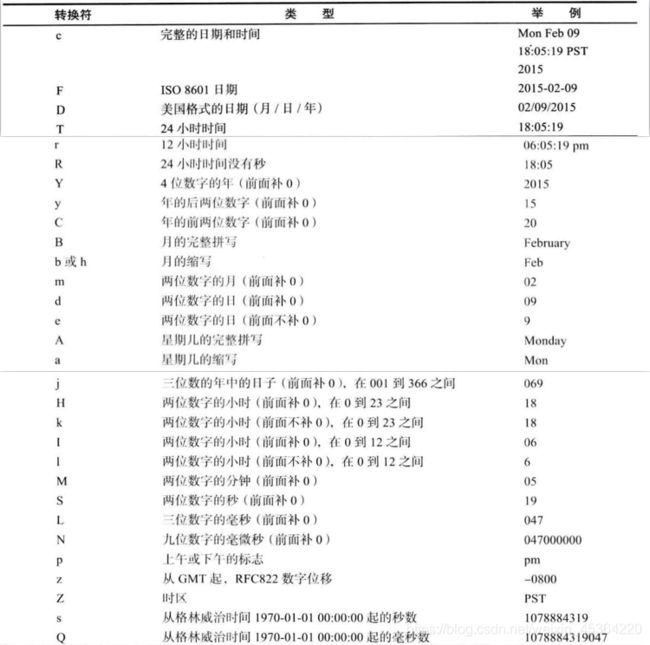
printf转换符

8.4 时间和日期
格式包括两个字母, 以 t 开始,以图中任意一个字母结束
经常用tc即可,其他可以忽略
public class Test {
public static void main(String[] args) {
System.out.printf("%tc", new Date());
System.out.println();
System.out.printf("%tT", new Date());
}
}
//星期六 八月 07 15:27:03 CST 2021
//15:27:03
8.5 文件输入与输出
public class Test {
public static void main(String[] args) {
try {
Scanner scanner = new Scanner(Paths.get("D:\\Program\\JetBrains\\IDEA\\Projects\\Java-Gao\\src\\读取三行情书.txt"), "UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
}
}
如果文件名中包含反斜杠符号,就要记住在每个反斜杠之前再加一个额外的反斜杠“:\D:\Program\JetBrains\IDEA\Projects\Java-Gao\src\读取三行情书.txt ”
在这里指定了 UTF-8 字符编码, 这对于互联网上的文件很常见(不过并不是普遍适用)。读取一个文本文件时,要知道它的字符编码—更多信息参见卷 n 第 2 章。如果 省略字符编码, 则会使用运行这个 Java程序的机器的“ 默认编码”。 这不是一个好主意, 如果在不同的机器上运行这个程序, 可能会有不同的表现
要想写入文件, 就需要构造一个 PrintWriter 对象。在构造器中,只需要提供文件名:
public class Test {
public static void main(String[] args) {
try {
PrintWriter out = new PrintWriter("D:\\Program\\JetBrains\\IDEA\\Projects\\Java-Gao\\src\\写入三行情书.txt", "UTF-8");
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 如果文件不存在,创建该文件。 可以像输出到 System.out—样使用 print、 println 以及 printf 命令
- 可以构造一个带有字符串参数的 Scanner, 但这个 Scanner 将字符串解释为数据,而不是文件名。
public class Test {
public static void main(String[] args) {
Scanner in = new Scanner("myfile.txt"); // ERROR?:这个 scanner 会将参数作为包含 10 个字符的数据:‘ m ’,‘y ’,‘ f’ 等。在这个示例中所显示的并不是所期望的效果
}
}
8.6 路径问题
当指定一个相对文件名时, 例如,“ myfile.txt”,“ mydirectory/myfile.txt” 或“ …/myfiletxt”,文件位于 Java 虚拟机启动路径的相对位置 , 如果在命令行方式下用下列命令启动程序:
java MyProg
启动路径就是命令解释器的当前路径。 然而,如果使用集成开发环境, 那么启动路径将由 IDE 控制。 可以使用下面的调用方式找到路径的位置:
public class Test {
public static void main(String[] args) {
String dir = System.getProperty("user.dir");
System.out.println(dir);
}
}
//D:\Program\JetBrains\IDEA\Projects\Java-Gao
如果觉得定位文件比较烦恼, 则可以考虑使用绝对路径, 例如:“ c:\mydirectory\myfile.txt ” 或者“ /home/me/mydirectory/myfile.txt”
当采用命令行方式启动一个程序时, 可以利用 Shell 的重定向语法将任意文件关联 到 System.in 和 System.out: java MyProg < rayfile.txt > output.txt 这样,就不必担心处理 IOException 异常了。
8.7 常用 API
| 函数原型 | 简介 |
|---|---|
| Scanner(File f) | 构造一个从给定文件读取数据的 Scanner |
| Scanner(String data) | 构造一个从给定字符串读取数据的 Scanner |
| PrintWriter(String fileName) | 构造一个将数据写入文件的 PrintWriter,文件名由参数指定 |
| static Path get(String pathname) | 根据给定的路径名构造一个 Path |
9.控制流程
9.1 if
-
if(布尔表达式){
//条件满足时执行代码 } -
if(布尔表达式){
//条件满足时执行代码
}else{
//条件不满足时执行代码
} -
if(布尔表达式){
//条件满足时执行代码
}else if(布尔表达式){
//条件满足时执行代码
}else{
//条件都不满足时执行代码
}
悬垂 else 问题:if / else 语句中可以不加 大括号 . 但是也可以写语句(只能写一条语句). 此时 else 是和最接近的 if 匹配.但是实际开发中我们 不建议 这么写. 最好加上大括号
public class Test {
public static void main(String[] args) {
int x = 10;
int y = 10;
if (x == 10)
if (y == 10)
System.out.println("aaa");
else
System.out.println("bbb");
}
}
//aaa
9.2 switch 语句
case 标签可以是:
- 类型为 char、byte、 short 或 int 的整形常量表达式。
- 枚举常量。
- 从 Java SE 7开始,case 标签还可以是字符串字面量。
public class Test {
public static void main(String[] args) {
switch (整数 | 枚举 | 字符 | 字符串) {
case 内容1: {
内容满足时执行语句;
break;
}
case 内容2: {
内容满足时执行语句;
break;
}
default: {
内容都不满足时执行语句;
break;
}
}
}
}
- 根据 switch 中值的不同, 会执行对应的 case 语句. 遇到 break 就会结束该 case 语句. 如果 switch> 中的值没有匹配的 case, 就会执行 default 中的语句. 我们建议一个 switch 语句最好都要带上 default
- break 不要遗漏, 否则会失去 “多分支选择” 的效果
- switch 中的值只能是 整数|枚举|字符|字符串
- switch 不能表达复杂的条件
例如: 如果 num 的值在 10 到 20 之间, 就打印 hehe 这样的代码使用 if 很容易表达, 但是使用 switch 就无法表示.
if (num > 10 && num < 20) {
System.out.println(“hehe”);
}
9.3 循环结构
9.3.1while 循环
9.3.2 for 循环
for(初始化; 判断; 更新)
如下代码可能永远不会结束。 由于舍入的误差, 最终可能得不到精确值。下面循环中, 因为 0.1 无法精确地用二进制表示,所以,x 将从 9.999 999 999 999 98 跳到10.099 999 999 999 98
public class Test {
public static void main(String[] args) {
for (double x = 0; x != 10; x += 0.1) {
System.out.print(x + " ");
}
}
}
//死循环
特别指出,如果在 for 语句内部定义一个变量, 这个变量就不能在循环体之外使用。因 此, 如果希望在 for循环体之外使用循环计数器的最终值,就要确保这个变量在循环语句的 前面且在外部声明!
public class Test {
public static void main(String[] args) {
for (int i = 0; i < 10; i++) {
;
}
System.out.println(i);
}
}
//java: 找不到符号
// 符号: 变量 i
// 位置: 类 Test
9.3.3 do while 循环(了解)
9.3.4 块作用域
块(即复合语句)是指由一对大括号括起来的若干条简单的 Java 语句。块确定了变量的作用域。一个块可以嵌套在另一个块中。下面就是在 main方法块中嵌套另一个语句块示例
public class Test {
public static void main(String[] args) {
int n;
{
int k;
}
}
}
但是,不能在嵌套的两个块中声明同名的变量。例如,下面的代码就有错误,而无法通过编译:
public class Test {
public static void main(String[] args) {
int n;
{
int k;
int n;//java: 已在方法 main(java.lang.String[])中定义了变量 n
}
}
}
9.3.5 中断流程
- break:用于 switch,for,while, do while流程
- continue:用于除 switch 之外的所有流程;while或者do while中continue语句将控制转移到最内层循环的首部;for中跳到循环的“ 更新” 部分
10.大数值
10.1 使用场景
如果基本的整数和浮点数精度不能够满足需求, 那么可以使用jaVa.math 包中的两个很有用的类:Biglnteger 和BigDecimaL 这两个类可以处理包含任意长度数字序列的数值。Biglnteger 类实现了任意精度的整数运算, BigDecimal实现了任意精度的浮点数运算
10.2 注意
遗憾的是,不能使用人们熟悉的算术运算符(如:+ 和 *) 处理大数值,应该使用给定的方法
下边是一个抽奖概率计算的程序,因为是需要数值精准所以使用了 大数值 来进行计算程序结果
public class Test {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
System.out.print("How many numbers do you need to draw? ");
int k = in.nextInt();
System.out.print("What is the highest number you can draw? ");
int n = in.nextInt();
BigInteger lotteryOdds = BigInteger.valueOf(1);
for (int i = 1; i <= k; i++) {
//otteryOdds = lotteryOdds *(n - i + 1) / i;
lotteryOdds = lotteryOdds.multiply(BigInteger.valueOf(n - i + 1)).divide(BigInteger.valueOf(i));
}
System.out.println("Your odds are 1 /" + lotteryOdds + ".Good luck !");
}
}
//How many numbers do you need to draw? 1
//What is the highest number you can draw? 2
//Your odds are 1 in 2.Good luck !
10.3 常用 API
| 函数原型 | 简介 |
|---|---|
| Biglnteger add(Biglnteger other) | |
| Biglnteger subtract(Biglnteger other) | |
| Biglnteger multipiy(Biginteger other) | |
| Biglnteger divide(Biglnteger other) | |
| Biglnteger mod(Biglnteger other) | 返冋这个大整数和另一个大整数 other的和、 差、 积、 商以及余数。 |
| int compareTo(Biglnteger other) | 如果这个大整数与另一个大整数 other 相等, 返回 0; 如果这个大整数小于另一个大整 |
| 数 other, 返回负数; 否则, 返回正数 | |
| static Biglnteger valueOf(1 ong x) | 返回值等于 x 的大整数。 |
| BigDecimal add(BigDecimal other) | |
| BigDecimal subtract(BigDecimal other) | |
| BigDecimal multipiy(BigDecimal other) | |
| BigDecimal divide(BigDecimal other RoundingMode mode) | 返回这个大实数与另一个大实数 other 的和、 差、 积、 商。要想计算商, 必须给出舍入方式 ( rounding mode。) RoundingMode.HALF UP 是在学校中学习的四舍五入方式( BP , 数值 0 到 4 舍去, 数值 5 到 9 进位)。它适用于常规的计算。有关其他的舍入方 |
| int compareTo(BigDecimal other) | 如果这个大实数与另一个大实数相等, 返回 0 ; 如果这个大实数小于另一个大实数,返回负数;否则,返回正数 |
| static BigDecimal valueOf(1 ong x) | |
| static BigDecimal valueOf(1 ong x ,int scale) | 返回值为 X 或 x / 10scale 的一个大实数 |
11.数组
11.1 一维数组创建&赋值
public class Test {
public static void main(String[] args) {
int len = 4;
int[] arr1 = new int[len];//数组长度不要求是常量: newint[n] 会创建一个长度为 n 的数组
int[] arr2 = new int[]{1, 2, 3, 4};
int[] arr3 = {1, 2, 3, 4};
for (int i = 0; i < arr1.length; i++) {
arr1[i] = i;
}
System.out.println(Arrays.toString(arr1));
}
}
//[0, 1, 2, 3]
- 数组长度为 0 与 null 不同
- 要想获得数组中的元素个数,可以使用 array.length
- 数组访问不可越界
- 一旦创建了数组, 就不能再改变它的大小(尽管可以改变每一个数组元素)0 如果经常需要在运行过程中扩展数组的大小, 就应该使用另一种数据结构—数组列表
11.2 一维数组打印输出
- 利用 Arrays 类的 toString 方法。 调用 Arrays.toString(a), 返回一个包含数组元素的字符串,这些元素被放置在括号内, 并用逗号分隔
- for循环遍历:可以输出全部也可以输出指定部分
- foreach遍历:不关心下标越界,输出所有元素
- 利用 Arrays 类的 toString 方法
11.3 数组拷贝
在 Java 中,允许将一个数组变量拷贝给另一个数组变量。这时, 两个变量将引用同一个数组
arr.clone():数组本身的一个拷贝可以复制给其它同类型的数组
int[] arr = {1, 2, 3, 4, 5, 6};
int[] newArr = arr.clone();
去和区分深浅拷贝:如果拷贝的是简单类型的数据则是深拷贝【内存中重新拷贝了一份数据】;如果是拷贝的引用类型就是浅拷贝【拷贝的引用,副本的修改也会改变元数据】
public class Test {
public static void main(String[] args) {
int[] smallPrimes = { 2, 3, 5, 7, 11, 13 };
int[] luckyNumbers = smallPrimes;
luckyNumbers[5] = 12; // now smallPrimes[5] is also 12
System.out.println(Arrays.toString(smallPrimes));
System.out.println(Arrays.toString(luckyNumbers));
}
}
//[2, 3, 5, 7, 11, 12]
//[2, 3, 5, 7, 11, 12]

如果希望将一个数组的所有值拷贝到一个新的数组中去,就要使用 Arrays 类的 copyOf方法
public class Test {
public static void main(String[] args) {
int[] smallPrimes = { 2, 3, 5, 7, 11, 13 };
int[] luckyNumbers = smallPrimes;
luckyNumbers[5] = 12; // now smallPrimes[5] is also 12
int[] copiedLuckyNumbers = Arrays.copyOf(luckyNumbers , luckyNumbers .length);
System.out.println(Arrays.toString(copiedLuckyNumbers));
}
}
//[2, 3, 5, 7, 11, 12]
第 2 个参数是新数组的长度。这个方法通常用来增加数组的大小
public class Test {
public static void main(String[] args) {
int[] smallPrimes = {2, 3, 5, 7, 11, 13};
int[] luckyNumbers = smallPrimes;
luckyNumbers[5] = 12; // now smallPrimes[5] is also 12
int[] copiedLuckyNumbers = Arrays.copyOf(luckyNumbers, luckyNumbers.length);
System.out.println(luckyNumbers.length);
luckyNumbers = Arrays.copyOf(luckyNumbers, 2 * luckyNumbers.length);
System.out.println(luckyNumbers.length);
}
}
//6
//12
如果数组元素是数值型,那么多余的元素将被赋值为 0 ; 如果数组元素是布尔型,则将赋值 为false。相反,如果长度小于原始数组的长度,则只拷贝最前面的数据元素
Java 数组与 C++ 数组在堆栈上有很大不同, 但基本上与分配在堆(heap) 上 的数组指针一样。也就是说
int[] a = new int[100];//Java
不同于
int a[100]; // C++
而等同于
int* a = new int[100];//C++
Java 中的 [ ] 运算符被预定义为检查数组边界,而且没有指针运算, 即不能通过 a 加 1 得到数组的下一个元素。
11.4 命令行参数
前面已经看到多个使用 Java 数组的示例。 每一个 Java 应用程序都有一个带 String arg[ ]参数的 main 方法。这个参数表明 main 方法将接收一个字符串数组, 也就是命令行参数
public class Test {
public static void main(String[] args) {
if (args.length == 0 || args[0].equals("-h"))
System.out.print("Hello, ");
else if (args[0].equals("-g"))
System.out.print("Goodbye, ");
// print the other command-line arguments
for (int i = 1; i < args.length; i++)
System.out.print(args[i]+" ");
System.out.println("!");
}
}
args[0] 是“ -h/-g”, 而不是“ Miss
java Test.java -g Miss Zhu is a charmous Girl
java Test.java -h Miss Zhu is a charmous Girl

11.5 数组排序
要想对数值型数组进行排序, 可以使用 Arrays 类中的 sort 方法
public class Test {
public static void main(String[] args) {
int[] arr = {1,3,5,7,9,2,4,6,8,10};
Arrays.sort(arr);
System.out.println(Arrays.toString(arr));
}
}
//[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
产生一个抽彩游戏中的随机数值组合
public class Test {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
//填充数据个数
System.out.print("How many numbers do you need to draw? ");
int k = in.nextInt();
//所能填充的最大数据
System.out.print("What is the highest number you can draw? ");
int n = in.nextInt();
int[] numbers = new int[n];
//填充数据
for (int i = 0; i < numbers.length; i++) {
numbers[i] = i + 1;
}
//k 个数据放入第二个数组
int[] result = new int[k];
for (int i = 0; i < result.length; i++) {
//随机生成 0~n-1
int r = (int) (Math.random() * n);
//选取任意位置的元素
result[i] = numbers[r];
//移动最后一个元素到随机位置
numbers[r] = numbers[n - 1];
--n;
}
Arrays.sort(result);
System.out.println("Bet the following combination. It'll make you rich!");
for (int r : result) {
System.out.println(r);
}
}
}
11.6 常用 API
| 函数原型 | 简介 |
|---|---|
| static String toString(type[]a) | 返回包含 a 中数据元素的字符串, 这些数据元素被放在括号内, 并用逗号分隔。参数: a 类型为 int、long、short、 char、 byte、boolean、float 或 double 的数组 |
| static type copyOf(type[]a, int length) | |
| static type copyOfRange(type[]a , int start, int end) | 返回与 a 类型相同的一个数组, 其长度为 length 或者 end-start, 数组元素为 a 的值。参数:a 类型为 int、 long、 short、 char、 byte、boolean、 float 或 double 的数组。start 起始下标(包含这个值)end 终止下标(不包含这个值)。这个值可能大于 a.length。 在这种情况下,结果为 0 或 false。length 拷贝的数据元素长度。如果 length 值大于 a.length, 结果为 0 或 false ;否则, 数组中只有前面 length 个数据元素的拷 W 值。參 static void sort(t y p e [ 2 a)采用优化的快速排序算法对数组进行排序。参数:a 类型为 int、long、short、char、byte、boolean、float 或 double 的数组 |
| static int binarySearch(type[] a , type v) | |
| static int binarySearch(type[]a, int start, int end, type v) | 采用二分搜索算法查找值 v。如果查找成功, 则返回相应的下标值; 否则, 返回一个负数值 。r -r-1 是为保持 a 有序 v 应插入的位置。参数:a 类型为 int、 long、 short、 char、 byte、 boolean 、 float 或 double 的有序数组。start 起始下标(包含这个值)。end 终止下标(不包含这个值。)v: 同 a 的数据元素类型相同的值。 |
| static void sort(type[] a) | 采用优化的快速排序算法对数组进行排序。参数:a 类型为 int、long、short、char、byte、boolean、float 或 double 的数组 |
| static void fill(type[]a , type v) | 将数组的所有数据元素值设置为 V。参数:a 类型为 int、 long、short、 char、byte、boolean、float 或 double 的数组。v 与 a 数据元素类型相同的一个值。 |
| static boolean equals(type[]a, type[] b) | 如果两个数组大小相同, 并且下标相同的元素都对应相等, 返回 true。参数:a、 b 类型为 int、long、short、char、byte、boolean、float 或 double 的两个数组。 |
11.7 多维数组
11.7.1 初始化和创建
public class Test {
public static void main(String[] args) {
double[][] balances;
balances = new double[4][4];
double[][] arr = new double[4][4];
//如果知道数组元素, 就可以不调用 new, 而直接使用简化的书写形式对多维数组进行初始化
int[][] magicSquare =
{
{16, 3, 2, 13},
{5, 10, 11, 8},
{9, 6, 7, 12},
{4, 15, 14, 1}
};
for (int[] row : magicSquare) {
for (int x : row) {
System.out.print(x + " ");
}
System.out.println();
}
System.out.println("======================");
System.out.println(Arrays.deepToString(magicSquare));
}
}
//16 3 2 13
//5 10 11 8
//9 6 7 12
//4 15 14 1
//======================
//[[16, 3, 2, 13], [5, 10, 11, 8], [9, 6, 7, 12], [4, 15, 14, 1]]
for each 循环语句不能自动处理二维数组的每一个元素。它是按照行, 也就是一维数组处理的要想访问二维教组 a 的所有元素,> 需要使用两个嵌套的循环
要想快速地打印一个二维数组的数据元素列表, 可以调用:System.out.println(Arrays.deepToString(magicSquare))
11.7 不规则数组
Java 实际上没有多维数组,只有一维数组。多维数组被解释为“ 数组的数组。”例如, 在前面的示例中, balances 数组实际上是一个包含 10 个元素的数组,而每个元素又是一个由 6 个浮点数组成的数组

与C++区分:
doublet][] balances = new double[10][6]; // Java
不同于
double balances [10] [6]; // C++
也不同于
double (balances)[6] = new double[10] [6]; // C++
而是分配了一个包含 10 个指针的数组:
double* balances = new double*[10]; // C++
然后, 指针数组的每一个元素被填充了一个包含 6 个数字的数组:
for (i = 0; i < 10; i++)
balances[i] = new double [6] ;
庆幸的是, 当创建 new double[10][6] 时, 这个循环将自动地执行,当需要不规则的数组时, 只能单独地创建行数组
构造一个“ 不规则” 数组, 即数组的每一行有不同的长度。下面是一个典型的示例。在这个示例中,创建一个数组, 第 i 行第 j 列将存放“ 从 i 个数值中抽取 j 个数值”产生的结果
public class Test {
public static void main(String[] args) {
final int MAX = 10;
int[][] odds = new int[MAX + 1][];
//创建不规则数组
for (int i = 0; i <= MAX; i++) {
odds[i] = new int[i + 1];
}
//填充数据
for (int i = 0; i < odds.length; i++) {
for (int j = 0; j < odds[i].length; j++) {
int lotteryOdds = 1;
for (int k = 1; k <= j; k++) {
lotteryOdds = lotteryOdds * (i - k + 1) / k;
}
odds[i][j] = lotteryOdds;
}
}
//打印
for (int[] row : odds) {
for (int odd : row) {
System.out.printf("%-4d", odd);
}
System.out.println();
}
}
}
//1
//1 1
//1 2 1
//1 3 3 1
//1 4 6 4 1
//1 5 10 10 5 1
//1 6 15 20 15 6 1
//1 7 21 35 35 21 7 1
//1 8 28 56 70 56 28 8 1
//1 9 36 84 126 126 84 36 9 1
//1 10 45 120 210 252 210 120 45 10 1