02数据采集与操作
目录
•常用格式的本地数据读写
•Python的数据库基本操作
•数据库多表连接
•爬虫简介
•BeautifulSoup解析网页
•爬虫框架Scrapy基础
•Logistic 回归
•实战案例:获取国内城市空气质量指数数据
•常用格式的本地数据读写
txt
•由字符串行组成,每行由EOL (End Of Line) 字符隔开,‘\n’
•打开文件 注意编码
•file_obj= open(filename, access_mode)
•access_mode: ‘r’,‘w’
•读操作
•file_obj.read() 读取整个文件内容
•file_obj.readline() 逐行读取
•file_obj.readlines() 返回列表,列表中的每个元素是行内容
•写操作
•file_obj.write() 将内容写入文件
•file_obj.writelines() 将字符串列表内容逐行写入文件
构造字符串列表两种方式:
#构造字符串列表
lines=[]
for n in range(100):
line='这是第 %i行\n' %n
lines.append(line)
lines=['这是第 %i行\n' %n for n in range(100)]
打开文件两种方式:
text_filename='./Data_Set_File/python_baidu.txt'
#打开文件
file_obj=open(text_filename,'r',encoding='utf-8')
lines=file_obj.readlines()
for i,line in enumerate(lines):
print('{}---{}'.format(i,line))
#关闭文件
file_obj.close()
enumerate
text_filename='./Data_Set_File/test_write.txt'
#with 语句,包括了异常处理,自动调用文件关闭操作,推荐使用
with open(text_filename,'r',encoding='utf-8') as f_obj:
print(f_obj.readline())
csv
以纯文本形式存储的表格数据(以逗号作为分隔符),通常第一行为列名
•读操作
•df_obj= pd.read_csv(),返回DataFrame类型的数据
•写操作
•df_obj.to_csv()
Pandas
•基于NumPy构建
•索引在左,数值在右。索引是pandas自动创建的。
•数据结构
•Series,类似于一维数组的对象。
•DataFram,表格型数据结构,每列可以是不同的数据类型,可表示二维或更高维的数据
JSON (JavaScript Object Notation)
•轻量级的数据交换格式
•语法规则
•数据是键值对
•由逗号分隔
•{}保存对象,如{key1:val1, key2,:val2}
•[]保存数组,如[val1, val2, …, valn]
•读操作
•json.load(file_obj)
•返回值是dict类型
•类型转换json-> csv
•编码操作
•json.dumps()
•编码注意•ensure_ascii=False
#[{'书名': '道德经', '作者': '老子'}, {'书名': '道德经2', '作者': '老子'}]
#上述数据的载入与数据操作分类
import json
filename='./Data_Set_File/json_output.json'
with open (filename,'r',encoding='utf-8') as f_obj:
json_data=json.load(f_obj) #返回值是list类型
print(type(json_data))
print(json_data)
lists1=[]
lists2=[]
for json in json_data:
for i,x in enumerate(json.values()):
if i%2==0:
lists1.append(x)
else:
lists2.append(x)
print(lists1)
print(lists2)
JSON文件在线视图查看器
XLS/XLSX (Excel文件)
•常用的电子表格数据
•文件操作
•利用pandas处理,快捷方便
•读操作•df_obj= pd.read_excel(),返回DataFrame类型的数据
•写操作
•df_obj.to_excel()
•具体操作参考pandas如何处理CSV文件
(excel先转为csv)
•Python的数据库基本操作
SQLite
一种集成在程序中的嵌入式的轻量级数据库
•关系型数据库管理系统
•嵌入式数据库,适用于嵌入式设备
•SQLite不是C/S的数据库引擎
•集成在用户程序中
•实现了大多数SQL标准
SQLite
•连接数据库
•conn = sqlite3.connect(db_name
•如果db_name存在,读取数据库
•如果db_name不存在,新建数据库
•获取游标
•conn.cursor()
•一段私有的SQL工作区,用于暂时存放受SQL语句影响的数据
CRUD操作
•cursor.execute(sql_str)
•cursor.executemany(sql_str) 批量操作
•fetchone()
•fetchall()
•conn.commit(),提交操作
•关闭连接 conn.close()
SQL基础
SQL 是用于访问和处理数据库的标准的计算机语言。
这类数据库包括:MySQL、SQL Server、Access、Oracle、Sybase、DB2 等等。
SQL 能做什么?
SQL 面向数据库执行查询
SQL 可从数据库取回数据
SQL 可在数据库中插入新的记录
SQL 可更新数据库中的数据
SQL 可从数据库删除记录
SQL 可创建新数据库
SQL 可在数据库中创建新表
SQL 可在数据库中创建存储过程
SQL 可在数据库中创建视图
SQL 可以设置表、存储过程和视图的权限
SQLite基本操作
•连接数据库
import sqlite3
db_path='./Data_Set_File/test.sqlite'
conn=sqlite3.connect(db_path)
cur=conn.cursor() #获取游标,一段私有的SQL工作区,用于暂时存放受SQL语句影响的数据
conn.text_factory=str #处理中文
cur.execute('SELECT SQLITE_VERSION()')
print('SQLite版本:',str(cur.fetchone()[0]))
•逐条插入数据
# 判断表是否存在
cur.execute("DROP TABLE IF EXISTS book")
# 新建表
cur.execute("CREATE TABLE book(id INT, name TEXT, price DOUBLE)")
# 逐行插入数据
cur.execute("INSERT INTO book VALUES(1,'肖秀荣考研书系列:肖秀荣(2017)考研政治命题人终极预测4套卷',14.40)")
cur.execute("INSERT INTO book VALUES(2,'法医秦明作品集:幸存者+清道夫+尸语者+无声的证词+第十一根手指(套装共5册) (两种封面随机发货)',100.00)")
cur.execute("INSERT INTO book VALUES(3,'活着本来单纯:丰子恺散文漫画精品集(收藏本)',30.90)")
cur.execute("INSERT INTO book VALUES(4,'自在独行:贾平凹的独行世界',26.80)")
cur.execute("INSERT INTO book VALUES(5,'当你的才华还撑不起你的梦想时',23.00)")
cur.execute("INSERT INTO book VALUES(6,'巨人的陨落(套装共3册)',84.90)")
cur.execute("INSERT INTO book VALUES(7,'孤独深处(收录雨果奖获奖作品《北京折叠》)',21.90)")
cur.execute("INSERT INTO book VALUES(8,'世界知名企业员工指定培训教材:所谓情商高,就是会说话',22.00)")
•建表批量插入数据
#建company表,并插入数据
cur.execute("DROP TABLE IF EXISTS company ")
cur.execute("CREATE TABLE company(\
id INT PRIMARY KEY NOT NULL,\
name CHAR(50) NOT NULL,\
age INT NOT NULL,\
address CHAR(50) NOT NULL,\
salary DOUBLE NOT NULL)")
companies=(
(1,'li ming',32,'china',15000.0),
(2,'zhangsan',25,'japan',16000.0),
(3,'lisi',27,'california',17000.0),
(4,'mazi',24,'texas',18000.0),
(5,'little mazi',22,'norway',19000.0),
(6,'middle mazi',23,'country1',20000.0),
(7,'big mazi',26,'country2',21000.0)
)
cur.executemany("INSERT INTO company VALUES(?,?,?,?,?)",companies)
SQL语句:
1>DROP TABLE IF EXISTS book
2>CREATE TABLE book(id INT, name TEXT)
3>INSERT INTO book VALUES()
4>SELECT emp_id,name,dept FROM company CROSS JOIN department
5>SELECT emp_id,name,dept FROM company LEFT OUTER JOIN department ON company.id=department.emp_id
其他常用数据库的连接
Mysql
MongoDB分布式数据库
PostgreSQL(Django推荐与PostgreSQL配合使用)
Oracle适用于各类大、中、小、微机环境。它是一种高效率、可靠性好的适应高吞吐量的数据库解决方案
•数据库多表连接
多表连接
•查询记录时将多个表中的记录连接(join)并返回结果
•join方式
•交叉连接(cross join)
•内连接(inner join)
•外连接(outer join)
•cross join
•生成两张表的笛卡尔积
•返回的记录数为两张表的记录数的乘积
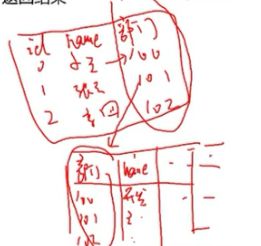
查询小王所处部门名称或其他信息(多表链接:两张表通过一列联系起来)
•inner join
•生成两张表的交集
•返回的记录数为两张表的交集的记录数
•outer join
•left join (A,B),返回表A的所有记录,另外表B中匹配的记录有值,没有匹配的记录返回null
•right join (A,B),返回表B的所有记录,另外表A中匹配的记录有值,没有匹配的记录返回null
•[注]目前在sqlite3中不支持,可考虑交换A、B表操作
CROSS JOIN交叉连接
cur.execute("SELECT emp_id,name,dept FROM company CROSS JOIN department")
rows=cur.fetchall()
for row in rows:
print(row)
INNER JOIN内连接
cur.execute("SELECT emp_id,name,dept FROM company INNER JOIN department\
ON company.id=department.emp_id;") #做了个交集
rows=cur.fetchall()
for row in rows:
print(row)
OUTER 外连接
#左链接left join (A,B)
#返回表A的所有记录,另外表B中匹配的记录有值,没有匹配的记录返回null
##右链接,sqlite3中不支持,可考虑交换A、B表操作
cur.execute("SELECT emp_id,name,dept FROM company LEFT OUTER JOIN department\
ON company.id=department.emp_id;")
rows=cur.fetchall()
for row in rows:
print(row)
•爬虫简介
爬虫
•自动抓取互联网信息的程序
•利用互联网数据进行分析、开发产品
爬虫基本架构
•URL 管理模块
•对计划爬取的或已经爬取的URL进行管理
•网页下载模块
•将URL管理模块中指定的URL进行访问下载
•网页解析模块
•解析网页下载模块中的URL,处理或保存数据
•如果解析到要继续爬取的URL,返回URL管理模块继续循环
URL管理模块
•防止重复爬取或循环指向
•实现方式
•Python的set数据结构,原因?
•数据库中的数据表,how?
•缓存数据库Redis,适用于大型互联网公司
URL下载模块
•将URL对应的网页下载到本地或读入内存(字符串)
•实现方式
•urllib,Python官方基础模块
•requests或其他第三方的模块
1>通过URL直接下载
#python3.x
import urllib.request
test_url="http://www.google.com"
test_url2="http://www.baidu.com"
#通过url下载
respose=urllib.request.urlopen(test_url2)
print(respose.getcode()) #200表示访问成功
print(respose.read())
2>通过Request访问下载
# 通过Request访问
request = urllib.request.Request(test_url2)
#request.add_header("user-agent", "Mozilla/5.0")
response = urllib.request.urlopen(request)
print(response.getcode()) # 200 表示访问成功
print(response.read())
3>通过Cookie访问下载
# 通过cookie访问
import http.cookiejar
cookie_jar = http.cookiejar.CookieJar()
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cookie_jar))
urllib.request.install_opener(opener)
response = urllib.request.urlopen(test_url2)
print(response.getcode()) # 200 表示访问成功
print(response.read())
print(cookie_jar)
网页解析模块
从网页中提取数据有很多方法,概况起来大概有这么三种方式,首先是正则,然后是流行的Beautiful Soup模块,最后是强大的Lxml模块。
1、正则表达式:最原始的方法,通过编写一些正则表达式,然后从HTML/XML中提取数据。
2、Beautiful Soup模块:Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据的 Python 库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup 会帮你节省数小时甚至数天的工作时间。
3、Lxml模块:lxml是基于libxm12这一XML解析库的Python封装,该模块使用C语言编写,解析速读比Beautiful Soup模块快,不过安装更为复杂。
•从已下载的网页中爬取数据
•实现方式
•正则表达式,字符串的模糊匹配
•html.parser
•BeautifulSoup,结构化的网页解析
•lxml
结构化解析
•DOM (Document Object Model),树形结构
•BeautifulSoup解析网页
BeautifulSoup
•用于解析HTML或XML
•pip install beautifulsoup4
•import bs4
•步骤
- 创建BeautifulSoup对象
- 查询节点
find,找到第一个满足条件的节点
find_all, 找到所有满足条件的节点
创建对象
• 创建BeautifulSoup对象
• bs= BeautifulSoup(
url,
html.parser, 指定解析器
from_enoding 指定编码格式(确保和网页编码格式一致)
)
from bs4 import BeautifulSoup
import urllib.request
html=urllib.request.urlopen("http://www.baidu.com") #打开网址
bs_obj=BeautifulSoup(html,'html.parser',from_encoding='utf-8') #创建BeautifulSoup对象,返回DOM树形结构
print(bs_obj.title) #对象的一个属性
print(bs_obj)
查找节点
<a href=‘a.html’ class=‘a_link’> next page</a>
•可按节点类型、属性或内容访问
•按类型查找节点
•bs.find_all(‘a’)
# 提取所有链接
print('1.提取所有链接:\n')
link_list=bs_obj.find_all('a')
for link in link_list:
print(link) #Elsie
print(link.name, link['href'], link.get_text()) # #link['href']按照访问键值对的方式,把key放进去
#a http://example.com/elsie Elsie
•按属性查找节点
•bs.find_all(‘a’, href=‘a.html’)
•bs.find_all(‘a’, href=‘a.html’, string=‘next page’)
•bs.find_all(‘a’, class_=‘a_link’)
•注意:是class_
# 提取一条链接
#属性:id,class_,href,string
print('2.提取一条链接:\n')
link1=bs_obj.find('a',id="link1")
print(link1.name,link1['href'],link1.get_text())
link2=bs_obj.find('a',string="Tillie")
print(link2.name,link2['href'],link2.get_text())
print('3.再提取一条链接:\n')
links=bs_obj.find_all('a',class_="sister") #注意:是class_
for link in links:
print(link.name,link['href'],link.get_text()) #get_text()获取节点文字
获取节点信息
•node是已查找到的节点
•node.name 获取节点标签名称
•node[’href’] 获取节点href属性
•node.get_text() 获取节点文字
异常处理
•网络资源或URL是经常变动的
•需要处理异常
# 创建一个完整的函数处理title
def get_html_title(url):
"""
获取url地址的title
"""
try:
html = urllib.request.urlopen(url)
except Exception as e:
return None
try:
bs_obj = BeautifulSoup(html.read(), 'html.parser')
title = bs_obj.title
except Exception as e:
return None
return title
title = get_html_title("http://www.jd.com")
if title is not None:
print(title)
else:
print("Title获取失败!")
BeautifulSoup进阶
•使用CSS选择器方式、正则表达式查找节点
•保存解析的内容
•DOM树形结构
children 只返回“孩子”节点
desecdants返回所有“子孙”节点
next_siblings返回下一个“同辈”节点
previous_siblings返回上一个“同辈”节点
parent 返回“父亲”节点
CSS方式查找节点
import urllib.request
from bs4 import BeautifulSoup
#html = urllib.request.urlopen("https://hao.360.com/?wd_xp1")
html = '''
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie
Lacie
and
Tillie
and they lived at the bottom of a well.
hhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhhh
zhangsan
lisi
and
mazi
zzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzzz
'''
bs_obj = BeautifulSoup(html, 'html.parser')
bs_obj.prettify() ##prettify实现格式化的输出
nav = bs_obj.find("p", {"class" : "story"}) #CSS键值对方式进行条件筛选
print(nav)
print(nav.get_text())
nav_list = bs_obj.find_all("p", {"class" : "story"})
for nav in nav_list:
print("zz",nav)
print(nav.get_text())
#保存解析的内容
nav_name_list=[nav.get_text() for nav in nav_list]
print(nav_name_list)
# 保存到文件中
with open('./Data_Set_File/output.txt', 'w', encoding='utf-8') as f:
for i,nav_name in enumerate( nav_name_list):
f.write('{}--{}\n\n\n\n\n\n\n\n\n\n'.format(i,nav_name))
树形结构
# contents:获取直接子节点,返回list类型
print(bs_obj.p.contents)
# children,返回的是可以迭代的,直接打印输出None
for i in bs_obj.p.children:
print("xx",i)
#children孩子节点
for i,child in enumerate(bs_obj.find("p", {"class" : "story"}).children):
print(i,child)
#descendants子孙节点
for i,child in enumerate(bs_obj.find("p", {"class" : "story"}).descendants):
print(i,child)
#next_siblings同辈节点
for i,sibling in enumerate(bs_obj.find("p", {"class" : "story"}).next_siblings):
print(i,sibling)
#parent父亲节点,previous_siblings同辈节点
#print(bs_obj.find("p", {"class" : "story"}).parent)
for i,sibling in enumerate(bs_obj.find("p", {"class" : "story"}).parent.previous_siblings):
print(i,sibling)
#print(bs_obj.find("p", {"class" : "story"}).parent.get_text())
正则表达式
•简单的字符串匹配可以使用字符串方法完成
•复杂、模糊的字符串匹配使用正则表达式,如:电子邮箱格式匹配
•通过使用单个字符串描述匹配一系列符合某个语法规则的字符串
•字符串操作的逻辑公式
•常用于处理文本数据
•匹配过程:依次拿出表达式和文本中的字符作比较,如果每个字符都能匹配,则匹配成功;否则失败
•import re
•pattern = re.compile(‘str’) 返回pattern对象
•推荐使用r’str’ 无需考虑转义字符
•pattern.match()
•基本语法
正则表达式语法
file_obj=open("./poem.txt")
lines=file_obj.readlines()
text=""
for i,line in enumerate(lines):
#print('{}---{}'.format(i,line))
text=text+line
file_obj.close()
#print(text)
import re
result=re.findall(" to ",text)
print(len(result))
#查找以a开头三个字母的 单词
result2=re.findall("a..",text) #一个点表示任意一个字符
print(len(result2))
#过滤空格
result3=re.findall("a[a-z][a-z]",text)
print(len(result3))
#print(result3)
#前后空格
result4=re.findall(" a[a-z][a-z] ",text)
print(len(result4))
#print(result4)
#去掉单词前后的空格
result5=re.findall(" (a[a-z][a-z]) ",text)
print(result5)
#去掉重复的单词
result6=set(result5)
print(result6) #{'ash', 'air', 'are', 'all', 'and'}
#加上以A开头的三个字母的单词
result7=re.findall(" *([Aa][a-z][a-z]) ",text) #空格+*表示可以没空格,可以是一个空格,两个空格或多个空格
print(set(result7))
#{'ash', 'any', 'all', 'ars', 'ake', 'ace', 'And', 'ath', 'arp', 'are', 'air', 'ast', 'age', 'ain', 'ade', 'ard', 'ame', 'ant', 'afe', 'ave', 'All', 'ads', 'ags', 'and'}
#不行
result7=re.findall(" (a[a-z][a-z]) |(A[a-z][a-z]) ",text)
print(set(result7))
final_result=set()
for pair in set(result7):
if pair[0] is "":
final_result.add(pair[1])
if pair[1] is "":
final_result.add(pair[0])
#final_result.remove("")
print(final_result)
# \d表示任意一个数字 ,+表示至少有一个
file_obj=open("./poem.txt")
lines=file_obj.readlines()
text=""
for i,line in enumerate(lines):
#print('{}---{}'.format(i,line))
text=text+line
file_obj.close()
#print(text)
result=re.findall("\d+",text)
print(result)
result2=re.findall("\d{2}",text) #刚好匹配两个数字
print(result2)
result2=re.findall("\d{2,3}",text) #匹配两个或三个数字
print(result2)
result=re.findall("\w{2,3}",text) #\w表示字母,[A-Za-z]
print(result)
使用正则表达式查找节点
import urllib.request
from bs4 import BeautifulSoup
import re
html = urllib.request.urlopen("http://www.pythonscraping.com/pages/page3.html")
bs_obj = BeautifulSoup(html, 'html.parser', from_encoding='uf-8')
#print(bs_obj)
images = bs_obj.find_all("img", {"src":re.compile(r"\.\./img/gifts/img.*\.jpg")})
#images = bs_obj.findAll("img", src=re.compile(r"\.\./img/gifts/img.*\.jpg"))
#images = bs_obj.findAll("img", {"src":re.compile(r"\.\./img/gifts/img.*\.jpg")})
for image in images:
print(image["src"])
import urllib.request
from bs4 import BeautifulSoup
import re
html = urllib.request.urlopen("http://baike.baidu.com/item/Python/407313?fr=aladdin")
bs_obj = BeautifulSoup(html, 'html.parser', from_encoding='uf-8')
for link in bs_obj.find("div", {"class":"main-content"}).findAll("a", href=re.compile("^(/view/)((?!:).)*$")):
if 'href' in link.attrs:
print('{}: {}'.format(link.attrs['href'], link.get_text()))
\.\./img/gifts/img.*\.jpg
^(/view/)((?!:).)*$
•爬虫框架Scrapy基础
Scrapy简介
•开源的爬虫框架
•快速强大,只需编写少量代码即可完成爬取任务
•易扩展,添加新的功能模块
Scrapy抓取过程
•使用start_urls作为初始url生成Request,默认将parse作为他的回调函数
•在parse函数中解析目标url
Scrapy高级特性
•内置数据抽取器css/xpath/re
•交互式控制台用于调试
•结果输出的格式支持,JSON, CSV, XML等
•自动处理编码
•支持自定义扩展
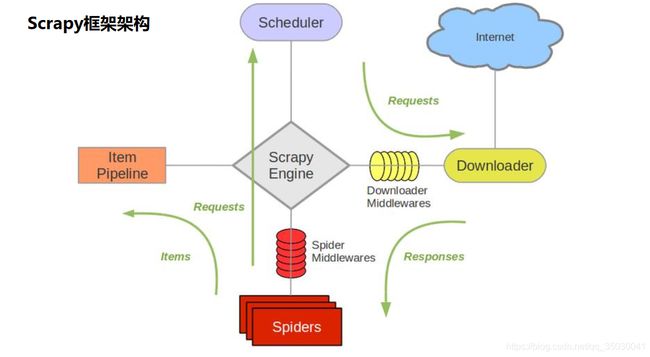
Scrapy使用步骤
•安装:pip install scrapy(可能需要额外安装visual c++build tools)
•1. 创建工程
•2. 定义Item,构造爬取的对象(可选)
•3. 编写Spider,爬虫主体
•4. 编写配置和Pipeline,用于处理爬取的结果(可选)
•5. 执行爬虫
Scrapy使用步骤
- 创建工程
•scrapy startproject air_quality
•目录结构 - 编写Spider
. •scrapy genspider aqi_history_spider https://www.aqistudy.cn/historydata/index.php - 运行Spider
•scrapy crawl aqi_history_spider
Scrapy使用步骤
4. 定义Item
•scrapy.Field()
5. 编写Spider
•调用自定义的Item
6. pipelines
•默认return item
7. 运行Spider
•scrapy crawl aqi_history_spider
Scrapy常用命令
•help: 查看帮助,
scrapy–help
•version: 查看版本信息,
•scrapy version, 查看scrapy版本
•scrapy version –v,查看相关模块的版本
•新建工程,
scrapy startproject porj_name
•生成spider模板,
scrapy genspider spider_name url
•list,列出所有的spider,
scrapy list
•view, 返回网页源代码并在浏览器中打开,
scrapy view url
•有时页面渲染的结果和查看结果是不同的
•parse, 调用工程spider中的parse解析url,
scrapy parse url
•shell, 进入交互式调试模式,
scrapy shell url
•bench, 可以用来检测scrapy是否安装成功
•…
新建框架工程和运行都在命令行
如何新建scrapy工程:
1.找到想要建立的目标工程路径cmd
2.创建工程
scrapy startproject air_quality
3.进入.cfg目录
cd air_quality
4.生成spider模板
scrapy genspider aqi_history_spider https://www.aqistudy.cn/historydata/index.php
5.运行
scrapy crawl aqi_history_spider
•实战案例:获取国内城市空气质量指数数据
爬取中国各城市历史空气质量记录
项目任务
1.掌握Scrapy框架的基本操作
2.能够爬取简单的页面数据
3.掌握深度数据的爬取及广度数据的爬取
调试:
根目录下scrapy shell https://www.aqistudy.cn/historydata/index.php
查看 response
查看 response.xpath(’//div[@class=“all”]//div[@class=“bottom”]//a//@href’)
附录链接:
Python的文件读写
Pandas的IO工具
SQLite中的多表连接
sqlite3模块
Python的中文编码
BeautifulSoup
正则表达式
Scrapy
Xpath教程
Scrapy命令行
验证码识别
Scrapy中的IP代理