【Python从零基础到入门】第一章 基础语法
第一章 基础语法
文章目录
- 第一章 基础语法
-
- 1.字面量
- 2.注释
- 3.变量
- 4.数据类型
- 5.数据类型转换
- 6.标识符
- 7.运算符
- 8.字符串拓展
-
- 1.字符串的三种定义方式
- 2.字符串拼接(不用)
- 3.字符串格式化(了解)
- 4.格式化的精度控制
- 5.字符串格式化2(常用)
- 6.对表达式格式化
- 小练习
- 9.数据输入
- 10.python中定义字符串前面加b、u、r的含义
1.字面量
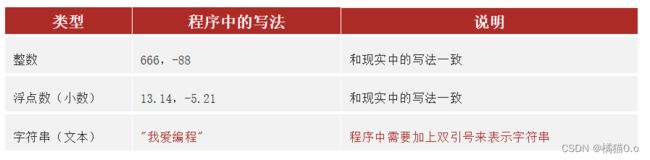
字面量:在代码中,被写下来的的固定的值,称之为字面量
| 类型 | 描述 | 说明 |
|---|---|---|
| 数字(Number) | 支持整数(int)浮点数(float)复数(complex)布尔(bool) | 整数(int),如:10、-10 |
| 浮点数(float),如:13.14、-13.14 | ||
| 复数(complex),如:4+3j,以j结尾表示复数 | ||
| 布尔(bool)表达现实生活中的逻辑,即真和假,True表示真,False表示假。True本质上是一个数字记作1,False记作0 | ||
| 字符串(String) | 描述文本的一种数据类型 | 字符串(string)由任意数量的字符组成 |
| 列表(List) | 有序的可变序列 | Python中使用最频繁的数据类型,可有序记录一堆数据 |
| 元组(Tuple) | 有序的不可变序列 | 可有序记录一堆不可变的Python数据集合 |
| 集合(Set) | 无序不重复集合 | 可无序记录一堆不重复的Python数据集合 |
| 字典(Dictionary) | 无序Key-Value集合 | 可无序记录一堆Key-Value型的Python数据集合 |
字符串(string),又称文本,是由任意数量的字符如中文、英文、各类符号、数字等组成。所以叫做字符的串
- print(10),输出整数10
- print(13.14),输出浮点数13.14
- print(“我爱编程”),输出字符串:我爱编程
2.注释
注释:在程序代码中对程序代码进行解释说明的文字。
作用:注释不是程序,不能被执行,只是对程序代码进行解释说明,让别人可以看懂程序代码的作用,能够大大增强程序的可读性。
-
单行注释:以 #开头,#右边 的所有文字当作说明,而不是真正要执行的程序,起辅助说明作用
#我是单行注释 print("Hello World") 运行结果: Hello World -
多行注释: 以 一对三个双引号 引起来 ( “”“ 注释内容 ”“” )来解释说明一段代码的作用使用方法
""" 我是多行注释 我可以写多行 """ print("hello,world") 运行结果: hello,world
3.变量
变量:在程序运行时,能储存计算结果或能表示值的抽象概念。
简单的说,变量就是在程序运行时,记录数据用的

- 变量,从名字中可以看出,表示“量”是可变的。所以,变量的特征就是,变量存储的数据,是可以发生改变的。
- 变量的目的是存储运行过程的数据。存储的目的是为了:重复使用
#将数字10存到data变量里
data = 10
4.数据类型
数据是有类型的。目前在入门阶段,我们主要接触如下三类数据类型:
| 类型 | 描述 | 说明 |
|---|---|---|
| string | 字符串类型 | 用引号引起来的数据都是字符串 |
| int | 整型(有符号) | 数字类型,存放整数 如 -1,10, 0 等 |
| float | 浮点型(有符号) | 数字类型,存放小数 如 -3.14, 6.66 |
那么,问题来了,如何验证数据的类型呢?
我们可以通过type()语句来得到数据的类型:
语法:type(被查看类型的数据)
示例代码:
#1.用print语句,直接输出类型信息
print(type("这是字符串"))
print(type(666))
print(type(3.14))
#运行结果
<class 'str'>
<class 'int'>
<class 'float'>

5.数据类型转换
数据类型之间,在特定的场景下,是可以相互转换的,如字符串转数字、数字转字符串等
跟C语言里面的强制转换很像
数据类型转换,将会是我们以后经常使用的功能。
如:
- 从文件中读取的数字,默认是字符串,我们需要转换成数字类型
- 后续学习的input()语句,默认结果是字符串,若需要数字也需要转换
- 将数字转换成字符串用以写出到外部系统等等
常见的转换语句
| 语句(函数) | 说明 |
|---|---|
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
同前面学习的type()语句一样,这三个语句,都是带有结果的(返回值)
我们可以用print直接输出
或用变量存储结果值
-
任何类型,都可以通过str(),转换成字符串
-
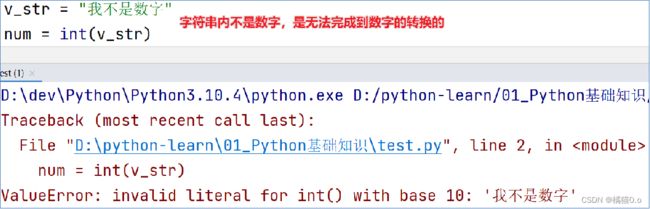
字符串内必须真的是数字,才可以将字符串转换为数字
-
浮点数转整数会丢失精度,也就是小数部分
6.标识符
在Python程序中,我们可以给很多东西起名字,比如:
- 变量的名字
- 方法的名字
- 类的名字,等等
这些名字,我们把它统一的称之为标识符,用来做内容的标识。
所以,标识符:是用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名。
标识符命名规则中,只允许出现:
- 英文
- 中文(不推荐使用中文)
- 数字(数字不可以开头)
- 下划线(_)
-
区分大小写
-
不可使用关键字

变量的命名规范
- 见名知意
- 下划线命名法
- 英文字母全小写
7.运算符
a = 10,b = 20
| 运算符 | 描述 | 实例 |
|---|---|---|
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | b / a 输出结果 2 |
| // | 取整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取余 | 返回除法的余数 b % a 输出结果 0 |
| ** | 指数 | a**b 为10的20次方, 输出结果 100000000000000000000 |
赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 赋值运算符 | 把 = 号右边的结果 赋给 左边的变量,如 num = 1 + 2 * 3,结果num的值为7 |
复合赋值运算符
| 运算符 | 描述 | 实例 |
|---|---|---|
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c ** = a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
8.字符串拓展
1.字符串的三种定义方式
- 单引号方式 name = ‘张三’
- 双引号方式 name = “张三”
- 三引号方式 name = ”’ 张三 “‘
字符串的引号嵌套
- 单引号定义法,可以内含双引号
- 双引号定义法,可以内含单引号
- 可以使用转移字符(\)来将引号解除效用,变成普通字符串
print(“ I\ ‘m ”)
2.字符串拼接(不用)
- 变量过多,拼接起来实在是太麻烦了
- 字符串无法和数字或其它类型完成拼接。
![]()
字符串无法和非字符串变量进行拼接。因为类型不一致,无法接上
3.字符串格式化(了解)
name = "小明"
message = "大家好,我叫%s"%name
print(message)
#运行结果:
大家好,我叫小明
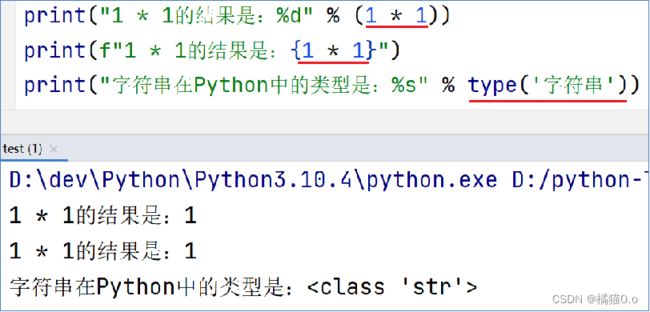
其中的,%s
-
% 表示:我要占位
-
s 表示:将变量变成字符串放入占位的地方
所以,综合起来的意思就是:我先占个位置,等一会有个变量过来,我把它变成字符串放到占位的位置
Python中,其实支持非常多的数据类型占位
最常用的是如下三类:
| 格式符号 | 转化 |
|---|---|
| %s | 将内容转换成字符串,放入占位位置 |
| %d | 将内容转换成整数,放入占位位置 |
| %f | 将内容转换成浮点型,放入占位位置 |
多个变量占位,变量要用括号括起来,并按照占位的顺序填入
str ="字符串abc"
int = 10
float = 3.14
print("这是字符串%s,这是整型数%d,这是浮点数%f"%(str,int,float))
#运行结果:
这是字符串字符串abc,这是整型数10,这是浮点数3.140000
4.格式化的精度控制
我们可以使用辅助符号"m.n"来控制数据的宽度和精度
-
m,控制宽度,要求是数字(很少使用)(设置的宽度小于数字自身,不生效)
-
.n,控制小数点精度(要求是数字,会进行小数的四舍五入)
示例: -
%5d:表示将整数的宽度控制在5位,(如数字11,被设置为5d,就会变成:空格 空格 空格 11,用三个空格补足宽度)
-
%5.2f:表示将宽度控制为5,将小数点精度设置为2, 小数点和小数部分也算入宽度计算。
(如,对11.345设置了%7.2f 后,结果是: 空格 空格 11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35%.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35)
-
%.2f:表示不限制宽度,只设置小数点精度为2,(如11.345设置%.2f后,结果是11.35)

5.字符串格式化2(常用)
语法:f”{变量} {变量}”的方式进行快速格式化
这种写法不做精度控制,也不理会类型。适用于快速格式化字符串(可以说是原样输出了)

6.对表达式格式化
表达式:一条具有明确执行结果的代码语句
如:
1 + 1、5 * 2,就是表达式,因为有具体的结果,结果是一个数字
又或者,常见的变量定义:
name = “张三” age = 11 + 11
等号右侧的都是表达式呢,因为它们有具体的结果,结果赋值给了等号左侧的变量。
在无需使用变量进行数据存储的时候,可以直接格式化表达式,简化代码哦
至此,已经学会了两种字符串格式化的方法
-
f"{表达式}"
-
“%s%d%f” % (表达式、表达式、表达式)
小练习
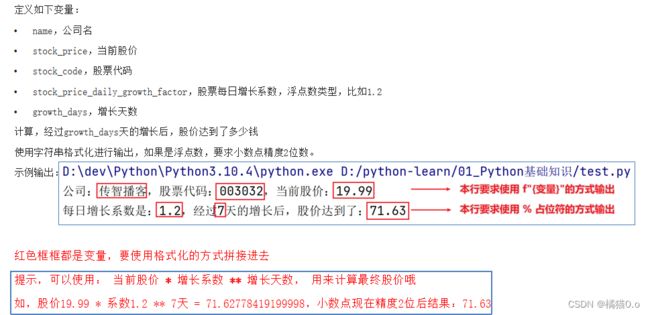
name,公司名
stock_price,当前股价
stock_code,股票代码
stock_price_daily_growth_factor,股票每日增长系数,浮点数类型,比如1.2
growth_days,增长天数
name = "橘猫"
stock_price = 19.99
stock_code = 003032
stock_price_daily_growth_factor = 1.2
growth_days = 7
price = stock_price*stock_price_daily_growth_factor**growth_days
print(f"公司{name},股票代码{stock_code},当前股价{stock_price}")
print("每日增长系数%d,经过%d天的增长后,股价达到了:%d"%(stock_price_daily_growth_factor,growth_days,price))
9.数据输入
关键词:input()函数
- input()语句的功能是,获取键盘输入的数据
- 可以使用:input(提示信息),用以在使用者输入内容之前显示提示信息。
- 要注意,无论键盘输入什么类型的数据,获取到的数据永远都是字符串类型
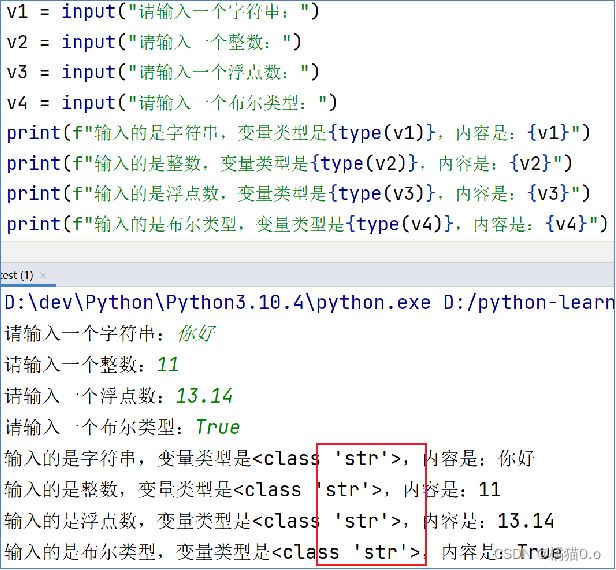
input不管你输入的什么数据类型,它输出的统一都是字符串,所以如果我们需要别的类型时,需要进行强转
10.python中定义字符串前面加b、u、r的含义
1.1 基本格式
str = b"xxxx"
str = u"xxxx"
str = r"xxxx"
str = f"xxxx"
1.2 描述及对比
(1)字符串前面加b表示后面字符串是bytes类型,以便服务器或浏览器识别bytes数据类型;
(2)字符串前面加u表示以Unicode格式进行编码,往往用来解决中文乱码问题,一般英文字符串基本都可以正常解析,而中文字符串必须表明用什么编码,否则就会乱码。
(3)字符串前面加r表示以raw string格式进行定义,可以防止字符串规避反斜杠\的转义。
例如:
str1 = "\thello"
str2 = r"\thello"
print("str1 =",str1)
print("str2 =",str2)
输出
str1 = hello
str2 = \thello
(4)字符串前面加f表示能支持大括号里面的表达式。
例如:
python = "蟒蛇"
print("我要好好学{python}!")
print(f"我要好好学{python} !")
输出
我要好好学{python} !
我要好好学蟒蛇 !
(5)在python3中,bytes和str的相互转换
str.encode('utf-8')
bytes.decode('utf-8')
例如:
print("你好".encode(encoding="utf-8"))
输出b’\xe4\xbd\xa0\xe5\xa5\xbd’
print(b'\xe4\xbd\xa0\xe5\xa5\xbd'.decode())
输出你好
往往用于图片、音视频等文件的读写时,可用bytes数据。