数据处理方法—— 7 种数据降维操作 !!
文章目录
数据降维
1. 主成分分析(PCA)
2. 线性判别分析(LDA)
3. t-分布随机邻域嵌入(t-SNE)
4. 局部线性嵌入(LLE)
5. 多维缩放(MDS)
6. 奇异值分解(SVD)
7. 自动编码器(Autoencoders)
总结
数据降维
数据降维是一种将高维数据转换为低纬数据的技术,同时尽量保留原始数据的重要信息。这对于处理大规模数据集非常有用,因为它有助于减少计算资源的需要,并提高算法的效率。以下是一些常用的数据降维方法,以及它们的原理和应用。
1. 主成分分析(PCA)
原理:PCA通过正交变换将原始数据转换到一组线性不相关的成份上,通常称为主成分。它识别数据中的模式,以找出数据的最大方差方向,并将数据投影到这些方向上。
应用:PCA通常用于减少数据集的维度,同时尽可能保留数据中的变异性。它也常用于可视化高维数据。
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# 加载数据集
data = load_iris()
X = data.data
# 应用PCA
pca = PCA(n_components=2) # 降到2维
X_pca = pca.fit_transform(X)
# 可视化结果
plt.scatter(X_pca[:, 0], X_pca[:, 1])
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title('PCA of Iris Dataset')
plt.show()
2. 线性判别分析(LDA)
原理:LDA是一种监督学习算法,旨在找到能够最大化类间差异和最小化类内差异的特征子空间。LDA特别关注数据的类别标签,使得数据投影后,同类数据点尽可能接近,不同类数据点尽可能远离。
应用:LDA常用于增强分类模型的性能。通过最大化类间差异和最小化类内差异,LDA能够提高分类算法的准确度。它还常用于模式识别任务,如人脸识别,其中可以利用LDA来提取面部特征。(LDA用于展示不同类别的数据在降维后的分布情况)。
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
# LDA也是一种监督学习算法,需要类别标签
y = data.target
# 应用LDA
lda = LDA(n_components=2) # 降到2维
X_lda = lda.fit_transform(X, y)
# 可视化结果
plt.scatter(X_lda[:, 0], X_lda[:, 1], c=y)
plt.xlabel('LD1')
plt.ylabel('LD2')
plt.title('LDA of Iris Dataset')
plt.show()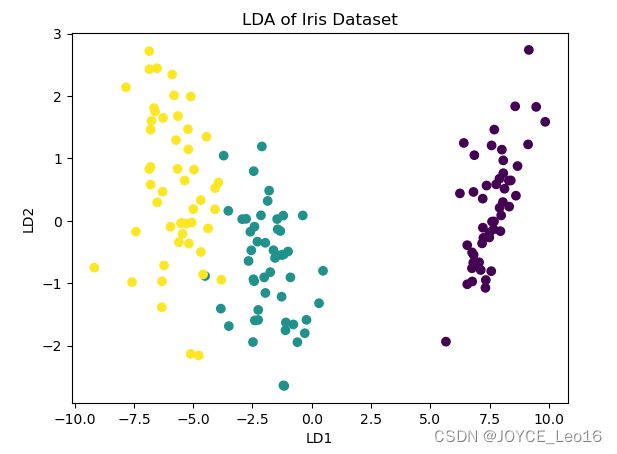
3. t-分布随机邻域嵌入(t-SNE)
原理:t-SNE是一种非线性降维技术,特别适合于将高维数据嵌入到二维或三维空间中进行可视化。它通过概率分布转换到相似性来保留局部结构,使得相似的对象在低维空间中更接近。
应用:t-SNE常用于高维数据的可视化。由于它在降维过程中保持了数据点间的局部关系,因此它特别适合于探索性数据分析,以识别高维数据集中的模式和群体。在生物信息学和社交网络分析中尤为常见。
from sklearn.manifold import TSNE
# 应用t-SNE
tsne = TSNE(n_components=2, random_state=0)
X_tsne = tsne.fit_transform(X)
# 可视化结果
plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y)
plt.xlabel('t-SNE feature 1')
plt.ylabel('t-SNE feature 2')
plt.title('t-SNE of Iris Dataset')
plt.show()
4. 局部线性嵌入(LLE)
原理:LLE是一种非线性降维技术。它的核心思想是保持数据点的局部特性。LLE首先在每个点的邻域中找到最佳的线性表示,然后在低维空间中重建这些线性关系。这种方法尤其适用于那些局部区域结构重要的数据。
应用:LLE通常用于数据可视化和探索数据分析,尤其是当数据具有非线性结构时。它在图像处理、语音识别和生物信息学中被广泛应用,用于发现数据中的内在结构和模式。
from sklearn.manifold import LocallyLinearEmbedding
# 应用LLE降维
lle = LocallyLinearEmbedding(n_components=2)
X_lle = lle.fit_transform(X)
# 可视化结果
plt.scatter(X_lle[:, 0], X_lle[:, 1], c=digits.target, cmap='Spectral', alpha=0.5)
plt.colorbar()
plt.title("LLE on the Digits Dataset")
plt.show()
5. 多维缩放(MDS)
原理:MDS是一种用于降维的技术,旨在数据点在低维空间中的相对位置尽可能地反映它们在原始高维空间中的距离。MDS通过优化过程寻找一个低维表示,使得这个表示中的点间距离尽可能地接近原始数据中的距离。
应用:MDS常用于数据可视化,尤其是当我们关心数据点之间的距离或相似性时。它在心理学、市场研究和社会学中特别有用,用于分析和可视化距离或相似性数据,如在语义分析或用户偏好研究中。
from sklearn.manifold import MDS
from sklearn.datasets import load_digits
import matplotlib.pyplot as plt
# 加载数据集
digits = load_digits()
X = digits.data
# 应用MDS降维
mds = MDS(n_components=2)
X_mds = mds.fit_transform(X)
# 可视化结果
plt.scatter(X_mds[:, 0], X_mds[:, 1], c=digits.target, cmap='Spectral', alpha=0.5)
plt.colorbar()
plt.title("MDS on the Digits Dataset")
plt.show()
6. 奇异值分解(SVD)
原理:SVD是一种将矩阵分解为三个矩阵的乘积的方法。它将原始数据矩阵分解为特征值和特征向量,能够揭示数据的本质结构。
应用:SVD在推荐系统中非常有用,尤其是处理大型稀疏矩阵时。通过提取矩阵中最重要的特征,SVD有助于预测用户对项目的评分或偏好。此外,它也用于数字信号处理和图像压缩领域。
import numpy as np
from scipy.linalg import svd
import matplotlib.pyplot as plt
# 假设 A 是一个矩阵
U, s, VT = svd(A)
# 选择前k个奇异值来近似原始矩阵
k = 2
A_approx = np.dot(U[:, :k], np.dot(np.diag(s[:k]), VT[:k, :]))
# 可以将 A_approx 可视化或用于进一步分析7. 自动编码器(Autoencoders)
原理:Autoencoders是一种基于神经网络的非线性降维技术。它通过训练网络学习一个低维表示(编码),然后重构输出,以尽可能接近输入数据。
应用:Autoencoders广泛应用于无监督学习的特征提取和数据压缩。在深度学习领域,它们用于学习数据的有效表示,有助于改善图像重构和去噪任务。也可以生成新的数据实例,如在生成对抗网络(GAN)中的应用。
from keras.layers import Input, Dense
from keras.models import Model
# 设定输入维度
input_dim = 784 # 例如,对于 28x28 的图像,这将是 784
encoding_dim = 32 # 编码空间的维度
# 定义编码器层
input_layer = Input(shape=(input_dim,))
encoded = Dense(encoding_dim, activation='relu')(input_layer)
# 定义解码器层
decoded = Dense(input_dim, activation='sigmoid')(encoded)
# 构建自动编码器模型
autoencoder = Model(input_layer, decoded)
# 构建编码器模型
encoder = Model(input_layer, encoded)
# 构建解码器模型
encoded_input = Input(shape=(encoding_dim,))
decoder_layer = autoencoder.layers[-1] # 最后一层作为解码器
decoder = Model(encoded_input, decoder_layer(encoded_input))
# 编译自动编码器
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
# 训练自动编码器
# 假设 x_train 是输入数据
# autoencoder.fit(x_train, x_train, epochs=50, batch_size=256, shuffle=True)
# 用编码器和解码器生成编码和解码后的数据
# encoded_imgs = encoder.predict(x_test)
# decoded_imgs = decoder.predict(encoded_imgs)总结
数据降维技术广泛被划分为两类:线性降维方法与非线性降维方法。线性方法,例如主成分分析(PCA)和线性判别分析(LDA),通常适用于数据具有线性分布的场景。相对地,非线性方法如t-分布随机邻域嵌入(t-SNE)、多维缩放(MDS)和局部线性嵌入(LLE),则更适合处理具有复杂分布特征的数据集。
选择合适的降维技术取决于数据的固有属性及分析目标的具体需求。在适当的情境中应用恰当的降维策略,能够显著提升数据处理流程的效率以及算法的整体性能表现。