MFQE 2.0: A New Approach for Multi-FrameQuality Enhancement on Compressed Video
在过去几年中,深度学习在提高压缩图像/视频质量方面取得了巨大成功。现有的方法主要着眼于提高单个帧的质量,而没有考虑连续帧之间的相似性。由于本文所研究的压缩视频帧之间存在较大的波动,因此,对于相邻的高质量帧,可以利用帧相似性来提高低质量帧的质量。此任务是多帧质量增强(MFQE)。因此,本文提出了一种用于压缩视频的MFQE方法,作为这方面的首次尝试。在我们的方法中,我们首先开发了一种基于双向长短时记忆(BiLSTM)的检测器来定位压缩视频中的峰值质量帧(PQF)。然后,设计了一种新的多帧卷积神经网络(MF-CNN),以非PQF及其最近的两个PQF为输入,提高压缩视频的质量。在MF-CNN中,非PQF和PQFs之间的运动由运动补偿子网进行补偿。随后,质量增强子网融合非PQF和补偿PQF,然后减少非PQF的压缩伪影。此外,PQF质量也以同样的方式得到提高。最后,实验验证了MFQE方法在提高压缩视频质量方面的有效性和泛化能力
1 INTRODUCTION
在过去的几十年里,互联网上视频的普及率有了很大的提高。根据Cisco数据流量预测[1],2016年视频产生了60%的互联网流量,预计到2020年这一数字将达到78%。在带宽有限的互联网上传输视频时,必须应用视频压缩以显著节省编码比特率。然而,压缩后的视频不可避免地会出现压缩伪影,这严重降低了体验质量(QoE)[2]、[3]、[4]、[5]、[6]。此外,这些伪影可能会降低分类和识别任务的准确性。文献[7]、[8]、[9]、[10]验证了压缩质量增强可以提高分类和识别的性能。因此,迫切需要对压缩视频的质量增强进行研究
最近,为提高压缩图像和视频的视觉质量进行了大量的工作【11】、【12】、【13】、【14】、【15】、【16】、【17】、【18】、【19】、【20】、【21】、【22】、【23】、【24】、【25】。例如,Dong等人[17]设计了一个四层卷积神经网络(CNN)[26],命名为ARCNN,这大大提高了JPEG图像的质量。然后,提出了应用残差学习策略的去噪CNN(DnCNN)[20],用于图像去噪、图像超分辨率和JPEG质量增强。后来,Yang等人[24]、[25]设计了一种解码器端可伸缩CNN(DS-CNN),用于视频质量增强。DS-CNN结构由两个子网组成,旨在分别减少编码内和编码间失真。然而,在处理单个帧时,所有现有的质量增强方法都没有利用相邻帧提供的信息,因此其性能受到严重限制。如图1所示,压缩视频的质量在帧之间急剧波动。因此,可以使用高质量帧(即,峰值质量帧,称为PQFs1)来增强其相邻的低质量帧(非pqf)的质量。这可以看作是多帧质量增强(MFQE),类似于多帧超分辨率[27]、[28]、[29]

本文提出了一种用于压缩视频的MFQE方法。具体而言,我们研究了几乎所有压缩标准压缩的视频序列在连续帧中存在较大的质量波动。因此,可以借助其相邻PQF来提高非PQF的质量。为此,我们首先训练一种双向长短时记忆(BiLSTM)模型作为检测PQF的无参考方法。
然后,提出了一种新的多帧CNN(MF-CNN)结构,该结构以当前非PQF及其相邻PQF为输入,用于非PQF质量增强。我们的MF-CNN包括两个组件,即运动补偿子网(MC子网)和质量增强子网(QE子网)。MC子网用于补偿当前非PQF与其相邻PQF之间的运动。QE子网采用时空体系结构,旨在提取和合并当前非QF和补偿PQF的特征。最后,QE子网利用相邻PQF提供的高质量信息,可以提高当前非PQF的质量。例如,如图1所示,在我们的MFQE方法中,当前非PQF(第95帧)及其最近的两个PQF(第92帧和第96帧)都被馈入MF-CNN。因此,非PQF(第95帧)中的低质量内容(篮球)可以在相邻PQF(第92帧和第96帧)中基本相同但质量更好的内容的基础上进行增强。此外,图1显示,我们的MFQE方法也缓解了质量波动,这是由于非PQF的质量得到了显著改善。请注意,我们的MFQE方法还用于通过使用相邻PQF来提高当前处理的PQF的质量,从而减少PQF的压缩伪影。
这项工作是我们会议论文[30](本文中称为MFQE 1.0)的扩展版本,并进行了额外的工作和实质性的改进,因此称为MFQE 2.0(为了简单起见,本文中称为MFQE)。扩展如下所示。(1) 我们在[30]中将数据库从70个未压缩视频扩展到160个。在此基础上,对压缩视频进行了更深入的分析。(2) 我们开发了一种新的PQF检测器,该检测器基于BiLSTM而不是文献[30]中的支持向量机(SVM)。我们的新检测器能够提取PQF的空间和时间信息,从而将PQF检测的F1分数从91.1%提高到98.2%。(3) 通过引入多尺度策略、批量规范化[31]和密集连接[32],我们推进了QE子网,而不是在[30]中CNN的设计,此外,我们还开发了一种轻量级的结构去加速视频增强的速度,实验表明,在[33]选择的18个序列上,平均峰值信噪比(PSNR)的改善从0.455 dB大幅增加到0.562 dB(即改善23.5%),而参数数量从1787547大幅减少到255422(即节省85.7%),导致质量提高速度至少提高了2倍。(4) 通过更广泛的实验验证了MFQE方法的性能和泛化能力。MFQE方法的代码可从https://github.com/RyanXingQL/MFQEv2.0.git获得。
2 RELATED WORKS
2.1 Related Works on Quality Enhancement
最近,大量的工作【11】、【12】、【13】、【14】、【15】、【16】、【17】、【18】、【19】、【20】、【21】、【22】、【23】都集中于提高压缩图像的视觉质量。具体而言,Foi等人【12】应用逐点形状自适应DCT(SA-DCT)来减少JPEG压缩造成的阻塞和振铃效应。后来,Jancsary等人[14]提出通过采用回归树字段(RTF)来减少JPEG图像的块效应。此外,使用稀疏编码来去除JPEG伪影,例如[15]和[16]。最近,深度学习也被成功地应用于提高压缩图像的视觉质量。特别是,Dong等人[17]提出了一种四层AR-CNN来减少图像的JPEG伪影。随后,D3[19]和深度双域卷积网络(DDCN)[18]被提出作为高级深度网络,用于JPEG图像的质量增强,利用JPEG压缩的先验知识。后来,DnCNN在[20]中被提出用于图像恢复的多项任务,包括质量增强。Li等人[21]提出了一种20层CNN,用于增强图像质量。最近,内存网络(MemNet)[23]被提议用于图像恢复任务,包括质量增强。在MemNet中,引入了内存块来生成跨CNN层的长期内存,从而成功地补偿了压缩过程中失真的中高频信号。它实现了最先进的压缩图像质量增强性能。
对于压缩视频的质量增强,还提出了一些其他的工作【24】、【34】、【35】。例如,提出了可变滤波器尺寸残差学习CNN(VRCNN)[34]来代替HEVC内编码的环路内滤波器。然而,参考文献[34]中的CNN被设计为视频编码器的一个组件,因此对于已经压缩的视频来说并不实用。最近,在[35]中提出了一种基于深度CNN的自动解码器(DCAD),它包含10个CNN层,以减少压缩视频的失真。此外,Yang等人[24]提出了DS-CNN视频质量增强方法。在[24]中,DS-CNN-I和DSCNN-B作为DS-CNN的两个子网络,分别用于减少帧内和帧间编码的伪影。所有上述方法都可以看作是单帧质量增强方法,因为它们没有利用具有高相似度的相邻帧的任何优势。因此,它们在视频质量增强方面的性能受到严重限制。
2.2 Related Works on Multi-Frame Super-Resolution
据我们所知,压缩视频不存在MFQE工作。最近的区域是多帧视频超分辨率。早年,Brandi等人[36]和Song等人[37]提出通过利用高分辨率关键帧来扩大视频分辨率。近年来,许多多帧超分辨率方法都采用了深度神经网络。例如,Huang等人【38】开发了一种双向递归卷积网络(BRCN),与传统的单帧方法相比,该网络提高了超分辨率性能。Kappeler等人提出了一种视频超分辨率网络(VSRnet)[27],其中相邻帧根据估计的运动进行扭曲,然后将当前帧和扭曲的相邻帧都馈送到超分辨率CNN中,以扩大当前帧的分辨率。后来,Li等人[28]提出用具有剩余学习策略的更深层网络取代VSRnet。所有这些多帧方法都超出了单帧方法(如SR-CNN[39])对超分辨率的限制,后者仅利用一帧内的空间信息。
最近,基于CNN的FlowNet【40】、【41】已在【42】中应用,以估计超分辨率帧间的运动,从而联合训练FlowNet和超分辨率网络。然后,Caballero等人【29】设计了一个空间变压器运动补偿网络,用于检测扭曲相邻帧的光流。然后将当前帧和扭曲的相邻帧馈入高效亚像素卷积网络(ESPCN)[43]进行超分辨率。最近,文献[44]中提出了用于视频超分辨率的亚像素运动补偿(SPMC)层。此外,[44]利用卷积长短时记忆(ConvLSTM)实现了视频超分辨率的最新性能。
上述多帧超分辨率方法的动机是,在视频的连续帧中很可能存在对同一对象或场景的不同观察。结果,相邻帧可能包含在对当前帧进行下采样时丢失的内容。类似地,对于压缩视频,低质量帧可以通过利用其具有较高质量的相邻帧来增强,因为在压缩帧之间存在严重的质量波动。因此,压缩视频的质量,可以通过利用多帧信息有效地改进。据我们所知,本文提出的MFQE方法是这方面的首次尝试。
3 ANALYSIS OF COMPRESSED VIDEO
在本节中,我们首先建立一个原始和压缩视频序列的大型数据库(第3.1节),用于在MFQE方法中训练深层神经网络。我们进一步分析我们的数据库,以调查帧级质量波动(第3.2节)和连续压缩帧之间的相似性(第3.3节)。分析结果可以看作是我们工作的动力。
3.1 Database
首先,我们建立了一个包含160个未压缩视频序列的数据库。这些序列选自Xiph.org【45】的数据集。、VQEG【46】和视频编码联合协作团队(JCT-VC)】【47】。我们数据库中包含的视频序列的分辨率范围很大:SIF(352?240)、CIF(352?288)、NTSC(720?486)、4CIF(704?576)、240p(416?240)、360p(640?360)、480p(832?480)、720p(1280?720)、1080p(1920?1080)和WQXGA(2560?1600)。此外,图2显示了我们数据库中序列的一些典型示例,展示了视频内容的多样性。然后,所有视频序列在不同的量化参数(QPs^2)下被MPEG-1【48】、MPEG-2【49】、MPEG-4【50】、H.264 /AVC【51】和HEVC【52】压缩,以在我们的数据库中生成相应的视频流.
3.2 Frame-Level Quality Fluctuation
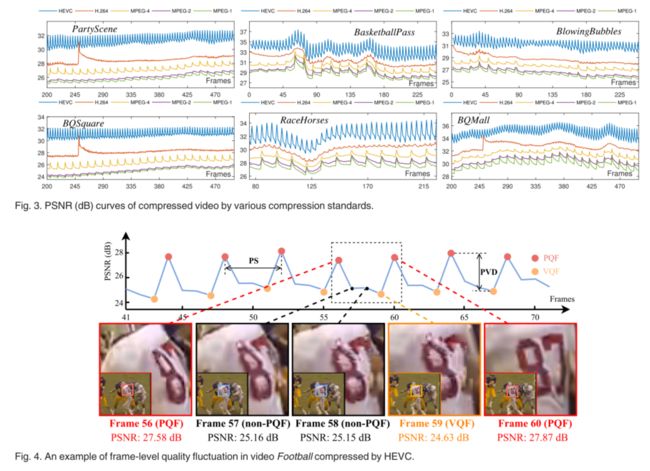
图3显示了按不同压缩标准压缩的6个视频序列的PSNR曲线。可以看出,峰值信噪比随压缩帧的变化而显著波动。这表明,对于MPEG-1、MPEG-2、MPEG-4、H.264 \/AVC和HEVC,压缩视频序列中存在相当大的质量波动。此外,图4可视化了一个视频序列中的一些帧的主观结果,该视频序列由最新HEVC标准压缩。我们可以看到,视觉质量在压缩帧之间变化,这也意味着帧级质量波动。
此外,我们还测量了每个压缩视频序列的帧级PSNR和结构相似性的标准偏差(SD)来衡量整个帧的质量波动。此外,还测量了每个压缩序列的峰值信噪比(PSNR)和SSIM曲线的峰谷差(PVD),该值计算峰值与其最近的谷值之间的平均差。请注意,PVD反映了短时间内框架之间的质量差异。表1中报告了SD和PVD的结果,它们是我们数据库中所有160个视频序列的平均值。表1显示,对于所有五种压缩标准,PSNR的平均SD值均高于0.87 dB。这意味着压缩后的视频序列随着帧的变化存在较大的波动。此外,从表1可以看出,对于MPEG-1、MPEG-2、MPEG-4和HEVC,除H.264(0.4732 dB)外,PSNR的平均PVD结果均在1 dB以上。因此,PQF和Valley quality Frames(VQF)之间的视觉质量存在显著差异,因此,考虑到相邻PQF,可以显著改善VQF的视觉质量。请注意,SSIM的类似结果如表1所示。综上所述,我们可以得出这样的结论:在PSNR和SSIM方面,各种视频压缩标准都存在显著的帧级质量波动。
3.3 Similarity between Neighboring Frames
根据直觉,短时间内的帧具有很高的相似性。因此,我们评估了数据库中所有160个序列的每个压缩帧与其前/后10个帧之间的相关系数(CC)值。CC值的平均值和SD如图5所示,它们是从HEVC压缩的所有序列中获得的。我们可以看到,当两帧的周期在10以内时,平均CC值大于0.75,CC的SD值小于0.20。其他四种视频压缩标准也有类似的结果。这验证了相邻视频帧的高相关性。
此外,有必要调查这两个相邻PQF之间的非PQF数量,用峰值间隔(PS)表示,因为每个非PQF的质量增强是基于两个相邻PQF。表1还报告了PS的结果,这是我们数据库中所有160个视频序列的平均值。我们可以从表3中看到,PS值远远小于10帧,尤其是对于最新的H.264(PS=2.0529)和HEVC(PS=2.6641)标准。如此短的距离,加上图5中的相似性结果,表明两个相邻PQF之间的高度相似性。因此,PQF可能包含一些有用的内容,这些内容在其相邻的非QF中被扭曲。基于此,我们建议采用MFQE方法通过最近PQF的优势信息提高非PQF的质量。
4 THE PROPOSED MFQE APPROACH
4.1 Framework
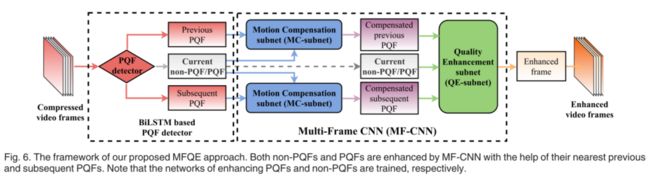
MFQE方法的框架如图6所示。如图所示,我们的MFQE方法首先检测用于提高非PQF质量的PQF。在实际应用中,原始序列在视频质量增强中不可用,因此无法通过与原始序列的比较来区分PQFs和非PQFs。因此,我们为MFQE方法开发了一个无参考PQF检测器,详见第4.2节。然后,我们提出了一种新的MF-CNN架构来提高非PQF的质量,该架构利用了最近的PQF,即之前和后续PQF。如图6所示,MF-CNN体系结构由MC子网和QE子网组成。MC子网(在第4.3节中介绍)用于补偿相邻帧之间的时间运动。具体而言,MC子网首先预测当前非PQF与其最近PQF之间的时间运动。然后,根据估计的运动,使用空间变换器对最近的两个PQF进行扭曲。因此,可以补偿非PQF和PQF之间的时间运动。最后,提出了具有时空体系结构的QE子网(在第4.4节中介绍)来提高质量。在QE子网中,当前非PQF和补偿PQF都是输入,然后通过相邻的补偿PQF来提高非PQF的质量。注意,在拟议的MF-CNN中,MC子网和QE子网以端到端的方式联合训练。同样,MF-CNN在其最近的PQF的帮助下也增强了每个PQF。
4.2 BiLSTM-Based PQF Detector
在我们的MFQE方法中,无参考PQF检测器基于BiLSTM网络。回想一下,PQF是质量高于其相邻帧的帧。因此,前向和后向上的当前帧和相邻帧的特征一起用于检测PQF。如第3.2节所示,PQF经常出现在压缩视频中,导致质量波动。因此,我们将BiLSTM网络【53】用作PQF检测器,其中可以提取和建模PQF和非PQF之间的长期和短期相关性。

特征提取。在训练之前,我们为每个fn提取38个特征。具体而言,在每个帧处提取2个压缩域特征,即分配的比特数和量化参数,用于检测PQF,因为它们与视觉质量密切相关,并且可以直接从比特流中获得。此外,我们遵循无参考质量评估方法[2],在像素域提取36个特征。最后,提取的特征以38维向量的形式作为BiLSTM的输入。
架构:BiLSTM的架构如图7所示。如图所示,LSTM是双向的,以便从正向和反向提取依赖项并对其建模。首先,将输入的38维特征向量馈入2个LSTM单元,对应于正向或反向。每个LSTM单元在一个时间步由128个单元组成(对应于一个视频帧)。

然后,将双向LSTM单元的输出进行融合并发送到完全连接的层,用 sigmoid 激活。因此,全连接层输出pn,作为PQF帧的概率。最后,可根据pn生成PQF标签ln。


上述两图表达的含义:POF帧不可能连续出现,非POF不可能连续出现超过D帧,借此优化POF帧识别率。
4.3 MC-Subnet
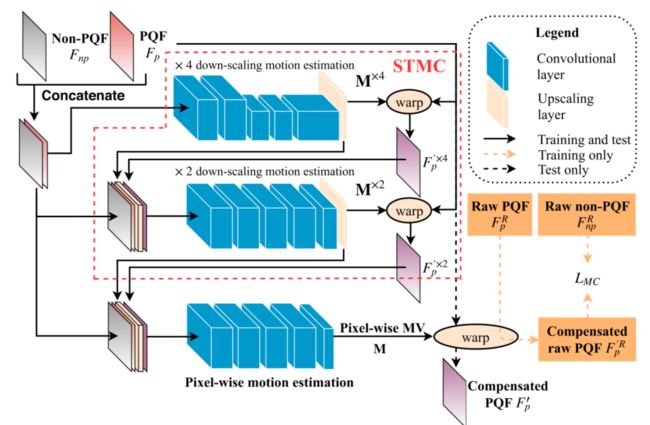 结构:STMC的体系结构如图8所示。此外,表2中描述了逐像素运动估计的卷积层。与[29]相同,我们的MC子网采用卷积层来估计,X4和X2个缩小比例的运动矢量(MV)映射,用M^(x4)和M^(x2)、降尺度运动估计是处理大尺度运动的有效方法。然而,由于向下缩放,MV估计的精度降低。因此,除了STMC之外,我们还进一步开发了一些额外的卷积层,用于MC子网中的像素级运动估计,该子网不包含任何缩小过程。然后,STMC的输出包括X2缩小MV map M^(x2)和相应的补偿。它们与原始PQF和非PQF串联,作为像素级运动估计卷积层的输入。因此,可以生成像素级MV map,其由M表示。注意,MV map M包含两个通道,即水平MV map Mx和垂直MV map My。这里,x和y是每个像素的水平和垂直索引。给定Mx和My,PQF会扭曲以补偿时间运动。假设压缩的PQF和非PQF分别为Fp和Fnp。补偿后的PQF 可表示为(
结构:STMC的体系结构如图8所示。此外,表2中描述了逐像素运动估计的卷积层。与[29]相同,我们的MC子网采用卷积层来估计,X4和X2个缩小比例的运动矢量(MV)映射,用M^(x4)和M^(x2)、降尺度运动估计是处理大尺度运动的有效方法。然而,由于向下缩放,MV估计的精度降低。因此,除了STMC之外,我们还进一步开发了一些额外的卷积层,用于MC子网中的像素级运动估计,该子网不包含任何缩小过程。然后,STMC的输出包括X2缩小MV map M^(x2)和相应的补偿。它们与原始PQF和非PQF串联,作为像素级运动估计卷积层的输入。因此,可以生成像素级MV map,其由M表示。注意,MV map M包含两个通道,即水平MV map Mx和垂直MV map My。这里,x和y是每个像素的水平和垂直索引。给定Mx和My,PQF会扭曲以补偿时间运动。假设压缩的PQF和非PQF分别为Fp和Fnp。补偿后的PQF 可表示为(![]() 表示双线性插值):
表示双线性插值):
![]()
培训策略。由于很难获得MV的地面真值,因此无法直接训练用于运动估计的卷积层参数。相反,我们可以通过最小化补偿后的相邻帧和当前帧之间的均方误差来训练参数。请注意,对于视频超分辨率任务中的运动补偿,在[29]中采用了类似的训练策略。然而,在我们的MC子网中,输入Fp和Fnp都是具有质量失真的压缩帧。因此,当最小化F'p和Fnp之间的MSE时,the MC-subnet学习扭曲的MV,因此,MCsubnet在原始帧的监督下进行训练。也就是说,我们使用从运动估计的卷积层输出的MV贴图扭曲PQF的原始帧(由F R p表示),并最小化补偿的原始PQF(由F 0R p表示)和原始非PQF(由F R np表示)之间的MSE。从数学上讲,MCsubnet的损失函数可以通过
![]()
请注意,在测试和实际使用中补偿运动时,不需要原始帧![]() 和
和![]() 。
。
4.4 QE-Subnet
 给定补偿的PQF,可以通过QE子网提高非PQF的质量。具体而言,非PQF Fnp与补偿后的先前和后续PQF(F 0 p1和F 0 p2)一起馈入QE子网。这样,这三个帧的空间和时间特征都被提取和融合,使得相邻PQF中的有利信息可以用于提高非PQF的质量。它不同于传统的基于CNN的单帧质量增强方法,后者只能处理单帧内的空间信息。
给定补偿的PQF,可以通过QE子网提高非PQF的质量。具体而言,非PQF Fnp与补偿后的先前和后续PQF(F 0 p1和F 0 p2)一起馈入QE子网。这样,这三个帧的空间和时间特征都被提取和融合,使得相邻PQF中的有利信息可以用于提高非PQF的质量。它不同于传统的基于CNN的单帧质量增强方法,后者只能处理单帧内的空间信息。
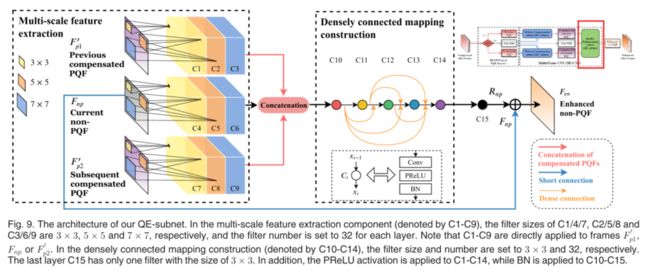
结构:QE子网的架构如图9所示。QE子网由两个关键的轻量级组件组成:多尺度特征提取。QEsubnet的输入为非PQF Fnp及其相邻的补偿PQF F 0 p1和F 0 p2。然后,用C1-9表示的多尺度卷积滤波器提取Fnp、F 0 p1和F 0 p2的空间特征。具体而言,C1,4,7的滤波器尺寸为33,而C2,5,8和C3,6,9的过滤器尺寸为5X5和7X7。C1-9的过滤器编号均为32。经过特征提取,得到了288幅不同尺度下过滤的特征图。随后,将来自Fnp、F 0 p1和F 0 p2的所有特征映射串联起来,然后流入密集连接组件。
Densely connected mapping construction:在从Fnp、f0p1和f0p2中获取特征映射后,采用一种紧密连接的结构来构建从特征映射到增强残差的非线性映射。请注意,增强残差是指原始帧和增强帧之间的差异。具体而言,在密集连接架构的非线性映射中有5个卷积层。每个都有32个卷积滤波器,大小为3X3、此外,采用密集连接[32]鼓励特征重用,加强特征传播,缓解消失梯度问题。此外,在PReLU激活后,将批量归一化(BN)[31]应用于所有5层,以减少内部协变量偏移,从而加快训练过程。我们将复合非线性映射表示为Hl(.),包括卷积(Conv)、PReLU和BN。我们进一步将第lth层的输出表示为xl,这样,每一层可以表示为:
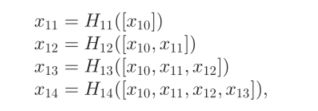
5 EXPERIMENTS
5.1 Settings
在本节中,给出了实验结果,以验证我们的MFQE 2.0方法的有效性。请注意,我们的MFQE 2.0方法在本文中被称为MFQE,而我们的会议文件[30]中的MFQE方法被命名为MFQE 1.0以进行比较。在我们的数据库中,除了视频编码联合协作团队(JCT-VC)[33]的18个标准测试序列外,其他142个序列随机分为非重叠训练集(106个序列)和验证集(36个序列)。我们在低延迟配置下使用HM16.5压缩所有160个序列,将量化参数(QPs)分别设置为22、27、32、37和42。
对于基于BiLSTM的PQF检测器,在后处理4中将(3)的超参数D设置为3,因为对于HEVC压缩序列,PS的平均值为2.66帧。此外,LSTM长度设置为8。在训练MF-CNN之前,原始和压缩序列被分割成64X64个补丁作为训练样本。批次大小设置为128。我们采用Adam算法[54],初始学习率为10?4以最小化损失函数(9)。值得一提的是,如果初始学习速率过大,例如1e-3、对于QE子网,我们首先在(9)中设置a=1和b=0:01,使MC子网收敛。收敛后,我们设置a=0:01和b=1,以便QE子网能够更快地收敛。
5.2 Performance of the PQF Detector

PQF检测的性能至关重要,因为它是我们MFQE方法的第一个过程。因此,我们评估了基于BiLSTM的方法在PQF检测中的性能。为了评估,我们测量了在五个QP(=22、27、32、37和42)下压缩的所有18个测试序列的PQF检测精度、召回率和F1分数。平均结果如表3所示。在该表中,我们还列出了通过MFQE 1.0基于SVM的方法进行PQF检测的结果,如【30】中所述。请注意,【30】中仅报告了两个QP(=37和42)的结果。
从表3可以看出,MFQE 2.0中提出的基于BiLSTMbased的PQF检测器在精确度、召回率和F1得分方面表现良好。例如,在QP=37时,基于BiLSTM的PQF检测器的平均精度、召回率和F1分数分别为100.0%、96.5%和98.2%,大大高于MFQE 1.0中基于SVM的方法。更重要的是,我们的方法的PQF检测对所有5个QP都很稳健,因为F1得分的平均值都在90%以上。此外,表4显示了我们基于BiLSTM的PQF检测器在QP=37时压缩的18个测试序列中的每一个上的性能。如下表所示,几乎所有序列的PQF检测器都实现了高性能,因为只有序列BQSquare的召回率低于90%。总之,我们基于BiLSTM的PQF检测器的有效性得到了验证,为我们的MFQE方法奠定了坚实的基础。
5.3 Performance of Our MFQE Approach
在本节中,我们根据DPSNR评估MFQE方法的质量增强性能,该方法测量增强序列和原始压缩序列之间的PSNR差距。此外,还对结构相似性(SSIM)指数进行了评估。然后,将我们的MFQE方法的性能与AR-CNN【17】、DnCNN【20】、Li等人【21】、DCAD【35】和DS-CNN【25】的性能进行了比较。其中,AR-CNN、DnCNN和Li等人是最新的压缩图像质量增强方法,而DCAD和DS-CNN是最先进的视频质量增强方法。为了进行公平比较,所有比较的方法都在我们的培训集中进行了重新培训,与我们的MFQE方法相同.
Quality Enhancement on Non-PQFs:
我们的MFQE方法主要是利用相邻的多帧信息来提高非PQF的质量。因此,我们首先评估非PQF的质量增强。图10显示了在4个不同QPs下压缩的所有18个测试序列的PQFs和非PQFs上平均的 PSNR和SSIM结果。如图所示,我们的MFQE方法在非PQF增强方面明显优于其他方法。PQF质量的平均改善为0.614 dB在PSNR上和0.012在SSIM中,而次优方法的PSNR为0.317 dB,SSIM为0.007。我们可以从图10中进一步看出,与PQF相比,非PQF的MFQE方法的PSNR改善幅度要大得多。相比之下,对于比较的方法,非PQFs的PSNR改善类似于甚至小于PQFs的。总之,上述结果验证了我们的MFQE方法在提高非PQF质量方面的卓越有效性。
PSNR和SSIM结果。如图所示,我们的MFQE方法在非PQF增强方面明显优于其他方法。PQF质量的平均改善为0.614 dB在PSNR上和0.012在SSIM中,而次优方法的PSNR为0.317 dB,SSIM为0.007。我们可以从图10中进一步看出,与PQF相比,非PQF的MFQE方法的PSNR改善幅度要大得多。相比之下,对于比较的方法,非PQFs的PSNR改善类似于甚至小于PQFs的。总之,上述结果验证了我们的MFQE方法在提高非PQF质量方面的卓越有效性。
整体质量提升。表5给出了在每个测试序列的所有帧上平均的PSNR和SSIM结果。如表所示,我们的MFQE方法始终优于所有比较方法。具体而言,在QP=37时,我们的MFQE方法的最高DPSNR达到0.920 dB,即,对于序列PeopleOnStreet。我们的MFQE方法的平均DPSNR为0.562 dB,比MFQE 1.0(0.455 dB)高23.5%,比Li等人(0.299 dB)高88.0%,比DCAD(0.322 dB)高74.5%,比DS-CNN(0.300 dB)高87.3%。与AR-CNN和DnCNN相比,可以观察到更高的DPSNR改善。在其他QP(=22、27、32和42)下,我们的MFQE方法始终优于其他最先进的视频质量增强方法。表5中的SSIM也有类似的改进。这证明了我们的MFQE方法在增强视频质量方面的稳健性。这主要归功于非PQFs(大多数压缩视频帧)的质量得到了显著改善。

Rate-Distortion Performance:通过与其他方法的比较,我们进一步评估了MFQE方法的率失真性能。首先,图11显示了我们和其他最先进方法在四个选定序列上的率失真曲线。请注意,此图中绘制了DCAD和DS-CNN方法的结果,因为它们的性能优于其他比较方法。从图11可以看出,我们的MFQE方法在率失真性能方面优于其他方法。然后,我们通过评估BD比特率(BD-BR)降低来量化率失真性能,该降低是根据五个QP(=22、27、32、37和42)的PSNR结果计算的。结果如表6所示。可以看出,我们MFQE方法的BD-BR平均减少14.06%,而次佳方法DCAD的BD-BR平均减少8.89%。一般来说,MFQE方法的质量增强相当于提高率失真性能。
Quality Fluctuation:除了压缩伪影之外,压缩视频中的质量波动也可能导致导致QoE退化【55】、【56】、【57】。幸运的是,我们的MFQE方法有助于缓解质量波动,因为它对非QF有显著的质量改进,如图10所示。我们根据第3节介绍的PSNR曲线的SD和PVD结果来评估视频质量的波动,图12显示了从质量增强方法和HEVC基线中获得的所有18个测试序列的平均SD和PVD值。如图所示,我们的MFQE方法成功地降低了SD和PVD,而其他五种比较方法在HEVC基线上扩大了SD和PVD值。原因是,我们的MFQE方法对非PQF的PSNR改善要比PQF大得多,从而缩小了PQF和非PQF之间的质量差距。此外,图13显示了我们的MFQE方法和HEVC基线的两个选定测试序列的峰值信噪比曲线。可以看出,我们MFQE方法的峰值信噪比波动明显小于HEVC基线。总之,我们的方法还能够减少视频压缩的质量波动。
Subjective Quality Performance:图14显示了QP=37时四人、QP=37时篮球传球和QP=42时赛马序列的主观质量表现。可以观察到,我们的MFQE方法比其他五种比较方法更有效地减少压缩伪影。具体来说,严重扭曲的内容,例如四人脸、篮球传中的球和赛马中的马蹄,可以通过我们的多帧策略MFQE方法很好地恢复。相比之下,这种压缩失真很难通过比较的方法恢复,因为它们只使用单个低质量帧。因此,我们的MFQE方法在主观质量增强方面也表现良好。
Test Speed:我们使用配备Intel i7 CPU的计算机评估质量增强的测试速度-8700 3.20GHz和GeForce GTX 1080 Ti的GPU。具体来说,当测试不同分辨率的视频序列时,我们测量平均每秒帧数(fps)。注意,在【33】中,测试集以不同的分辨率分为5类。表7中报告了不同分辨率下序列的平均结果。如下表所示,当增强非PQFs时,MFQE 2.0可以实现至少2倍于MFQE 1.0的加速度。对于PQFs,MFQE 2.0也比MFQE 1.0快得多。原因是MFQE 2.0中MF-CNN体系结构的参数明显少于MFQE 1.0中的参数。总之,MFQE 2.0在视频质量增强方面非常有效,其效率主要取决于其轻量级结构。

此外,我们还计算了MFQE方法的运算次数。对于MFQE 1.0,需要99561个加法和215150624个乘法来增强64X64个补丁,而MFQE 2.0的补丁是150276和5942640。大幅减少操作的原因是我们将MF-CNN映射结构中的过滤器数量从64个减少到32个,并通过将输出特征映射的数量从128个减少到32个来减轻特征提取的负担。同时,我们深化了映射结构,引入了密集策略、批量归一化和剩余学习。这样,MF-CNN的非线性得到很大改善,同时有效地节省了参数数量。总之,MFQE 2.0在视频质量增强方面非常有效,其效率主要归功于其轻量级结构。
5.4 Ablation Study
PQF Detector:在本节中,我们验证了利用PQF提高非QFS质量的必要性和有效性。为此,我们对MFQE方法的MF-CNN模型进行了重新训练,以借助相邻帧而不是PQF来增强非PQF。MF-CNN网络和实验设置均与第4.3节和第5.1节中的设置一致。重新训练的模型由MFQE_NF表示(即,具有相邻帧的MFQE,实验结果如图15所示,它是通过在QP=37时压缩的所有18个测试序列的平均值获得的。我们可以看到,我们的方法在不考虑PQFs的情况下,PSNR增益只能达到0.274 dB。相比之下,如上所述,我们使用PQFs的方法可以在DPSNR中实现0.562 dB的增强。此外,如第5.3节所验证,与单帧方法相比,我们的MFQE方法在非PQF上获得了相当高的增强。总之,上述消融研究证明了在视频质量增强任务中使用PQFs的必要性和有效性。
此外,我们还使用ground truth PQFs对MF-CNN模型进行了测试。具体来说,根据峰值信噪比曲线和PQF的定义,获得地面真值PQF标签。实验结果(由MFQE_GT表示,即带有地面真值PQFs的MFQE)如图15所示。我们可以看到,平均DPSNR为0.563 dB。这表示PQF估计性能的上限。
此外,我们还测试了PQF检测器后处理的影响,即移除相邻PQF并在两个PQF之间长距离插入PQF。具体而言,我们测试了未经后处理的PQF检测器的F1分数,并进一步评估了其在 PSNR方面的质量增强性能(用MFQE_NP表示,即无后处理的MFQE)。与未进行后处理的检测器相比,经过后处理的F1平均得分从98.15%略微增加到98.21%。此外,去除后处理后,平均 PSNR降低了0.001 dB。虽然后处理对 PSNR的改善很小,但在某些极端情况下,后处理仍然是必要的,因为后处理可以防止MFQE方法进行不准确的运动补偿和较差的质量增强。以序列Kristenadsara为例。将第273和277帧的非PQF标签更正为PQFs。因此,在使用后处理标签之后,帧270到280的平均 PSNR可以从0.659 dB增加到0.724 dB。
最后,我们进行了一个实验来验证在训练和评估中用BiLSTM代替SVM后的质量改进,这是MFQE 2.0相对于MFQE 1.0的进步。具体来说,我们首先在检测阶段用SVM替换MFQE 2.0的BiLSTM检测器。然后,我们对由基于SVM的检测器和MF-CNN组成的模型(用MFQE_SVM表示)进行了重新训练和测试。平均 PSNR从0.562 dB降至0.528 dB(即6.0%的降级)。这验证了改进的PQF检测器的贡献。
多尺度、密集连接策略。我们进一步验证了多尺度特征提取策略和密集连接结构在提高视频质量方面的有效性。首先,我们在MFQE方法的QE子网中消除所有密集连接。此外,我们将C11的滤波器数量从32个增加到50个,以便保持可训练参数的数量,以实现公平比较。相应的重训练模型由MFQE_ND表示(即,无密集连接的MFQE)。其次,我们消除了QE子网中的多尺度结构。基于上述密集烧蚀网络,我们将特征提取组件的所有内核大小固定为5X5、MFQE方法和实验设置的其他部分均与第4节和第5.1节相同。因此,重新训练的模型表示为MFQE_GC(即,带有通用CNN的MFQE)。图15显示了烧蚀结果,其也是在QP=37的所有18个测试序列上的平均值。如下表所示,禁用密集连接时,峰值信噪比(PSNR)改善从0.562 dB降至0.299 dB(即46.8%降级),然后进一步烧蚀多尺度结构时,PSNR改善降至0.278 dB(即50.5%降级)。这表明了我们的多尺度战略和密集连接结构的有效性。
扩大了数据库。本文的贡献之一是将我们的数据库从70个未压缩视频序列扩展到160个。在这里,我们验证了扩大后的数据库相对于之前的数据库的有效性【30】。具体而言,我们测试了在[30]中通过数据库培训的MFQE方法的性能。然后,在QP=37的所有18个测试序列上评估性能。图15中,重新训练的模型及其相应的测试结果由MFQE_PD(即,带有先前数据库的MFQE)表示。我们可以看到,与MFQE-A7相比,MFQE 2.0在质量增强方面取得了实质性的改进。特别是,MFQE 2.0的性能平均将DPSNR从0.533 dB提高到0.562 dB。因此,我们扩大的数据库可以有效地提高视频质量增强性能。
5.5 Generalization Ability of Our MFQE Approach
Transfer to H.264:我们验证了MFQE方法对其他标准压缩的视频序列的泛化能力。为此,我们在QP=37时用H.264压缩的18个测试序列测试我们的MFQE方法。请注意,测试模型与第5.3节中的测试模型相同,该测试模型在QP=37时通过HEVC压缩的训练集进行训练。因此,平均PSNR改善为0.422 dB。此外,我们还测试了在H.264数据集上重新训练的MFQE模型的性能。平均PSNR改善为0.464 dB。总之,在HEVC数据集上训练的MFQE模型执行在H.264视频中效果良好,在H.264上重新训练的MFQE模型可以稍微提高质量增强的性能。这意味着我们的MFQE方法在不同压缩标准中具有很高的泛化能力。
Performance on other Sequences:值得一提的是,文献[30]中的测试集与本文中的测试集不同。在我们之前的工作【30】中,从之前的数据库中随机选择了10个测试序列,包括70个视频。本文中,我们的18个测试序列是由视频编码联合协作团队(JCT-VC)[33]选择的,这是视频压缩的标准测试集。为了进行公平比较,我们测试了MFQE 2.0的性能,以及与之前测试集相比的所有比较方法。实验结果如表8所示。注意,10个测试序列中的4个测试序列与上述实验的18个测试序列重叠。从表8可以看出,我们的方法在PSNR方面有0.680 dB的改善,并且再次优于其他方法。在该表中,比较方法的结果也优于文献[30]及其论文中报告的结果。这是因为对扩大的数据库进行了再培训。总之,我们的MFQE方法在不同的测试序列上具有很高的泛化能力。
6 CONCLUSION
在本文中,我们提出了一种基于CNN的MFQE方法,通过减少压缩伪影来提高压缩视频的质量。与传统的单帧质量增强方法不同,我们的MFQE方法通过利用具有更高质量的最近PQF来提高一帧的质量。为此,我们开发了一种基于BiLSTM的PQF检测器,用于对压缩视频中的PQF和非PQF进行分类。然后,我们提出了一种新的CNN框架,称为MF-CNN,以提高非PQF的质量。具体而言,我们的MF-CNN框架由两个子网组成,即MC子网和QE子网。首先,MC子网补偿PQF和非PQF之间的运动。随后,QE子网通过馈送当前非PQF和最近的补偿PQF来提高每个非PQF的质量。此外,PQF质量也以同样的方式得到提高。最后,大量的实验结果表明,我们的MFQE方法显著提高了压缩视频的质量,优于其他最先进的方法。因此,与其他方法相比,整体质量可以显著提高,质量更高,质量波动更小。未来工作可能存在两个研究方向。(1) 本文的工作仅将峰值信噪比(PSNR)和SSIM作为需要增强的客观指标。未来的潜在工作可能会在我们的方法中进一步采用感知质量指标,以提高视频质量增强中的体验质量(QoE)。(2) 我们的工作主要集中在解码器端的质量增强。为了进一步改进质量增强的性能,可以利用来自编码器的信息,例如编码单元的划分。这是一项有希望的未来工作。