一文综述常用图像评估方法
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
介绍
作为视觉生物,人类对视觉信号损耗(例如块状,模糊,嘈杂和传输损耗)敏感。因此,我将研究重点放在发现图像质量如何影响Web应用程序中的用户行为上。最近,一些研究测试了低质量图像在网站上的影响。康奈尔大学![]() 证明了低质量的图像会对用户体验,网站转换率,人们在网站上停留多长时间以及信任/信誉产生负面影响。他们使用由LetGo.com提供的公开数据集训练的深度神经网络模型。目的是衡量图像质量对销售和感知到的信任度的影响,但是他们无法衡量图像质量对可信赖性的影响。
证明了低质量的图像会对用户体验,网站转换率,人们在网站上停留多长时间以及信任/信誉产生负面影响。他们使用由LetGo.com提供的公开数据集训练的深度神经网络模型。目的是衡量图像质量对销售和感知到的信任度的影响,但是他们无法衡量图像质量对可信赖性的影响。
图像失真
最常见的图像失真是白噪声(WN),高斯模糊(GB),JPEG压缩和JP2K压缩。例如,晚上在用手机拍摄照片时,可能会引起白噪声失真;如果在拍摄前未正确聚焦,则可能导致高斯模糊。
 (a)参考图像,(b)JP2K压缩,(c)高斯模糊
(a)参考图像,(b)JP2K压缩,(c)高斯模糊

(a)参考图像,(b)JPEG压缩,(c)白噪声
文献回顾
图像质量评估(IQA)方法主要分为两类:(1)参考(reference)和(2)无参考(reference-less or blind)。参考的算法需要原始(参考认为是高质量的)和失真的图像计算质量分数。基于参考的算法已广泛用于衡量在应用诸如图像压缩,图像传输或图像拼接之类的处理后图像的质量。例如,在图像压缩方面需要权衡取舍;压缩率越高,可感知的图像质量越低。作为另一个示例,拥有一种自动测量图像质量的方法可以帮助公司定义最佳压缩参数,以在不影响用户体验的情况下最大化加载速度。另一方面,无参考侧重于无法访问原始图像的过程。
最初,无参考的IQA算法特定于失真。因此,为了计算图像质量分数,需要在计算之前确定失真类型。因此,需要两个模型,(1)一个预测失真类型的模型,以及(2)给定失真类型的一个预测质量分数的模型。这些方法的整体性能要低得多,并且研究工作继续朝着通用方法发展。
几位研究人员发现,自然图像统计(NSS)以及诸如小波和离散余弦变换(DCT)域之类的变换是评估图像失真程度的有力鉴别器。这些方法一直占据主导地位,直到被基于特征学习的新算法所取代。如果有足够的数据,这些算法将超越基于手工(hand-crafted)特征的算法的性能。主要缺点是参数数量激增,增加了缺乏泛化能力的风险。
问题描述
图像质量评估(IQA)与其他图像应用不同。与分类,目标检测或分割相反,IQA数据集的收集是复杂且费时的。因此,大型数据集的创建是昂贵的,因为它需要负责确保方法正确执行的专家的监督。另一个限制是,由于不得修改参考图像的像素结构,因此无法使用数据增强。
方法
大多数最新算法都专注于特征学习。如前所述,这些方法的主要局限性在于广泛数据集泛化的必要性。但是,最新的方法侧重于混合方法,该方法第一步是自动学习hi质量相关(quality-aware)特征 ,其次将这些特征与质量分数相关联。
本节的目的是介绍三种与以前的方法相比具有出色性能的完全不同的方法。第一种方法基于经过训练以学习objective error map的深度神经网络。第二种方法引入了多个伪参考图像(MPRI)的概念,并通过高阶统计量汇总来提取特征;第三种方法则利用了无监督的kMeans聚类来创建图像质量特征码本(characteristics codebook)。
Deep CNN-Based Blind Image Quality Predictor (DIQA)
如前所述,图像质量评估的重大挑战之一是标记图像的成本。但是,Jongyoo Kim等人在[1]中通过将训练分为两个步骤,找到了一种利用大量数据的方法(参见下图):
1.训练可学习objective error map的卷积神经网络(CNN)。
2.使用subjective scores微调CNN。
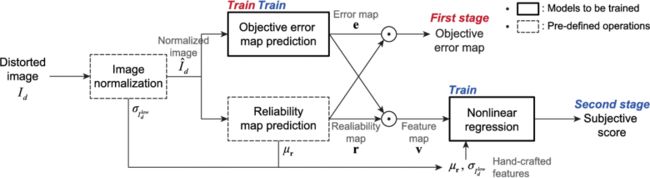
第一步,由于使用了CNN,可以学习原始图像和失真图像之间的error map,因此无需使用人类意见评分。我们可以使用伪参考图像(PRI)及其失真的概念扩展第一阶段数据集的大小(请参阅下面的BMPRI算法)。
在第二步中,在Conv8 之后添加两个全连接的层,并使用subjective scores进行微调以学习人类的观点。
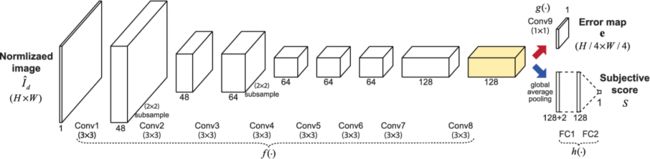
学习 Objective Error Map
第一阶段是回归分析,目的是学习objective error map。它由上图中的红色箭头描述。损失函数定义为预测的和真实的error maps的均方误差。此外,通过可靠的map预测来加权这样的error maps之间的差异。
第一阶段的损失函数,其中函数g和f在上图中定义。
通过可靠的map预测r具有通过测量失真图像的纹理强度来避免在同质区域中预测失败的作用。

真实误差只是参考图像和失真图像之间的差的p次方。作者建议p = 0.2,以使误差分布范围从0到1。
学习 Subjective Opinion
在训练了第一个模型以预测objective error maps之后,使用第一个网络并添加两个全连接层来创建一个新的网络。为了利用不同大小的图像,对Conv8应用全局平均池化(GAP),并将其变成全连接层。为了补偿丢失的信息,将两个手工特征μ和σ连接到FC1(请参见上图)。该阶段的损失函数定义为:

阶段二的损失函数,μ和σ是手工特征,S是subjective score
其中v是应用于Conv8的全局平均池化操作。
Blind Image Quality Estimation via Distortion Aggravation (BMPRI)
通过失真加重(distortion aggravation )进行无参考图像质量估计的主要思想是消除参考图像的概念,而使用失真图像。因此,作者介绍了多个伪参考图像(MPRI)的思想。MPRI由失真图像生成。因此,伪参考图像(PRI)的质量通常比它的失真图像差。
该方法的思想是通过进一步‘降解’失真图像生成一系列的PRI,然后利用local binary patterns(LBP)测量它们之间的相似性来评估其质量。
失真加重
作者说,选择失真类型至关重要,因为不同的失真会引入不同的伪影,并且需要有一致的PRI。例如,为了估计模糊的伪影,我们可以对失真的图像进行模糊处理。选定的失真为JPEG,JP2K,高斯模糊(GB)和白噪声(WN),以测量阻塞,振铃,模糊和噪声伪影。
块效应,其中Q控制压缩质量
振铃效应,其中R控制压缩比
模糊效应,其中g是高斯核,*是卷积运算符
噪声效应,其中N(0,v)为正态分布的随机值,均值为0,方差为v。
其中i∈{1,2,3,4,5}表示第i级的失真加重,k和r,b,n表示阻塞,振铃,模糊和噪声效应。
LBP特征提取
为每个MPRI和失真的图像提取LBP特征。最初,这些特征用于对不同类型的纹理进行分类。
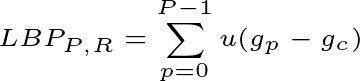
其中,g_p和g_c为像素点,P、R为LBP结构的邻居数和半径。
其中,
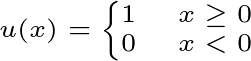
为简单起见,作者建议P = 4和R =1。
失真图像与MPRI之间的相似度
为了计算失真加重的图像和失真图像之间的相似度,我们将Lo定义为失真图像(Ld)和MPRI (Lm)特征图之间的重叠
失真图像和MPRI特征图之间的重叠
其中,
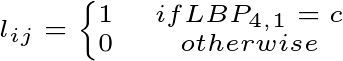
LBP特征图,其中将c设置为给定失真类型的不同值。例如,将c设置为0或1以估计噪声效应
然后质量被定义为:
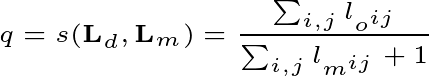
给定的加重m的分数,其中q越表示质量较差
质量预测
在为所有先前定义的加重计算q分数后,我们需要将所有得到的得分连接到一个特征向量q中,该特征向量q包含失真图像的阻塞,振铃,模糊和噪声效果的描述符。
最后,训练一个回归器,将训练集中图像的质量标签(MOS)映射到特征向量q上。
Blind Image Quality Assessment Based on High Order Statistics Aggregation (HOSA)
HOSA方法是一种混合算法,它利用了无监督学习阶段的功能,该阶段可以检测一组失真图像中的相似块。此步骤称为码本构造(codebook construction)。然后,第二步使用训练数据集来查找每个新块与码本中五个最接近的码字(codewords)之间的相似性以训练回归器。
HOSA算法分为两个不同的步骤:
1.码本构造(Codebook construction):将一组图像分成N个块,用于创建码本。该码本是一组K个质量相关的码字。
2.高阶统计量汇总(High order statistics aggregation):给定一个新的训练数据集,对于每个新块,将使用它们的高阶统计量来关联5个最近的簇。

局部特征提取
该方法的总体思路是为每个图像找到一组N个归一化的B x B图像块I(i,j)(局部特征提取阶段),每个块都被归一化然后用于创建特征向量。此过程将应用于初始集的所有图片。作者选择了CSIQ数据库。
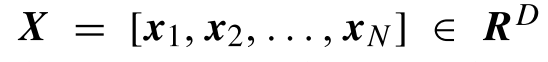
码本构造
HOSA不是唯一基于码本的方法。它是一个多个作者遵循的框架,用于自动检测对评估图像质量有用的图像特征。码本框架依赖于将图像划分为信息区域的想法。一个信息丰富的区域称为可视码字,一组可视码字构成可视码本。基于码本框架的方法之间的区别在于创建此类码本的算法。在这种方法中,码字的数量为100。
为了创建码本,给定集合X包含初始数据集的局部特征,可以通过使用KMeans最小化累积近似误差来找到K个中心。

累积近似误差
对于每个簇,均值,协方差和协偏度被计算。
高阶统计量汇总
对于训练集中的每个单个局部特征x,通过欧几里得距离选择r个最近的码字rNN(x)。作者建议r = 5。计算簇平均值和r个最近码字之间的残差。

簇的局部特征的软加权平均值与簇k的平均值之间的残差,其中d表示向量的第d维

局部特征x和代码字k之间的高斯核相似度权重
实际上,对于两个不同的特征集,簇k的平均值与指定的r个局部特征的平均值之间的软加权差可能会生成相同的m。因此,计算第二和第三阶统计量以进一步区分不同的质量等级图像。


局部特征和码字之间的软加权二阶和三阶统计量
最后,对于训练集中的每个局部特征x,将为码本中的每个簇计算一阶,二阶和三阶统计量,并将其连接起来以创建单个质量相关的特征向量。
使用质量相关特征向量作为描述符训练回归器以来学习subjective scores。
性能比较
SRCC( Spearman rank-order correlation coefficient)用于比较不同的方法。根据结果,这三种方法的效果相似。他们通常使用质量相关学习特征来计算分数。与依靠手工特征的方法BRISQUE相比,SRCC有了显着提升。

总结
简要介绍了三种最新的图像质量评估方法。所有这些都是基于特征学习来检测图像上的失真。根据作者提供的SRCC分数,这些方法始终优于以前的依靠手工特征来计算图像质量的方法。
好消息!
小白学视觉知识星球
开始面向外开放啦

下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~