前后端大文件分片上传、断点续传和秒传
文件上传在项目开发中再常见不过了,大多项目都会涉及到图片、音频、视频、文件的上传,通常简单的一个Form表单就可以上传小文件了,但是遇到大文件时比如1GB以上,或者用户网络比较慢时,简单的文件上传就不能适用了,用户辛苦传了好几十分钟,到最后发现上传失败,这样的系统用户体验是非常差的。
或者用户上传到一半时,把应用退出了,下次进来再次上传,如果让他从头开始传也是不合理的。本文主要通过一个Demo从前端、后端用实战代码演示小文件上传、大文件分片上传、断点续传、秒传的开发原理。
1.小文件上传
小文件小传非常的简单,本项目后端我们使用SrpingBoot 3.1.2 + JDK17,前端我们使用原生的JavaScript+spark-md5.min.js实现。
后端代码:POM.xml使用springboot3.1.2JAVA版本使用JDK17
org.springframework.boot
spring-boot-starter-parent
3.1.2
com.example
uploadDemo
0.0.1-SNAPSHOT
uploadDemo
uploadDemo
17
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-maven-plugin
JAVA接文件接口:
@RestController
public class UploadController {
public static final String UPLOAD_PATH = "D:\\upload\\";
@RequestMapping("/upload")
public ResponseEntity> upload(@RequestParam MultipartFile file) throws IOException {
File dstFile = new File(UPLOAD_PATH, String.format("%s.%s", UUID.randomUUID(), StringUtils.getFilename(file.getOriginalFilename())));
file.transferTo(dstFile);
return ResponseEntity.ok(Map.of("path", dstFile.getAbsolutePath()));
}
} 前端代码:
upload
upload
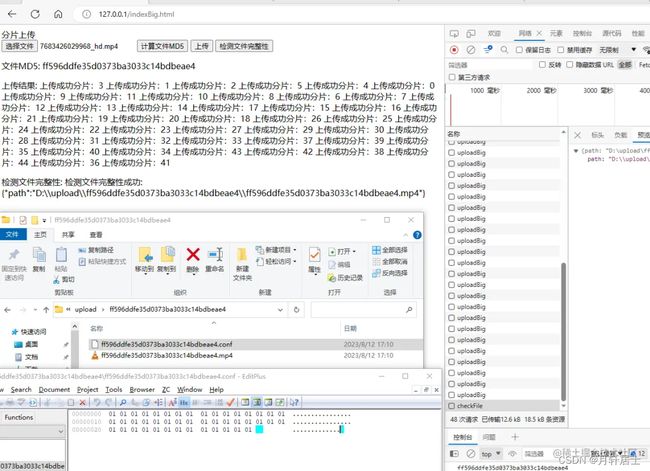
上传结果
在上传过程会报文件大小限制错误,主要有三个参数需要设置,在springboot的application.properties 或者application.yml中添加max-file-size和max-request-size配置项,默认大小分别是1M和10M,肯定不能满足我们上传需求的。
spring.servlet.multipart.max-file-size=1024MB
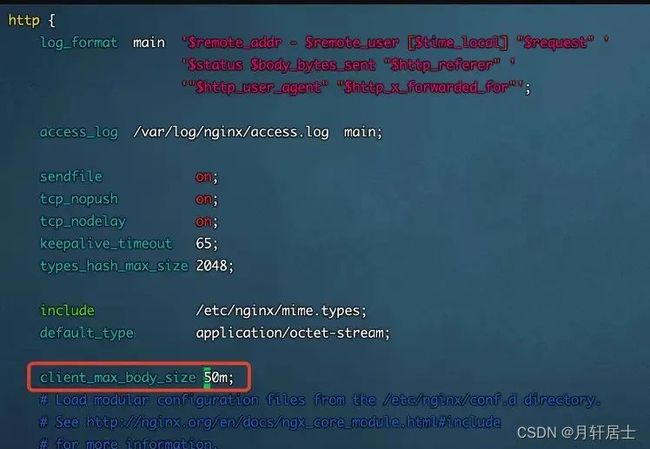
spring.servlet.multipart.max-request-size=1024MB如果使用nginx报 413状态码413 Request Entity Too Large,Nginx默认最大上传1MB文件,需要在nginx.conf配置文件中的 http{ }添加配置项:client_max_body_size 1024m。
2.大文件分片上传
前端上传流程
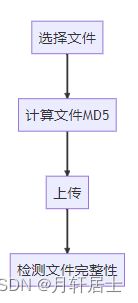
大文件分片上传前端主要有三步:

前端上传代码计算文件MD5值用了spark-md5这个库,使用也是比较简单的。这里为什么要计算MD5简单说一下,因为文件在传输写入过程中可能会出现错误,导致最终合成的文件可能和原文件不一样,所以要对比一下前端计算的MD5和后端计算的MD5是不是一样,保证上传数据的一致性。
分片上传
分片上传
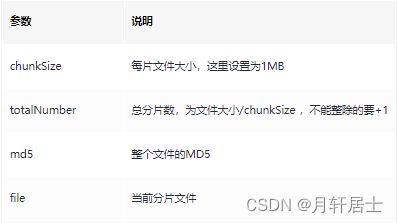
文件MD5:
上传结果:
检测文件完整性:
前端注意事项
前端调用uploadBig接口有四个参数:
计算大文件的MD5可能会比较慢,这个可以从流程上进行优化,比如上传使用异步去计算文件MD5、不计算整个文件MD5而是计算每一片的MD5保证每一片数据的一致性。
后端代码处理
后端就两个接口/uploadBig用于每一片文件的上传和/checkFile检测文件的MD5。
这里需要注意的:
-
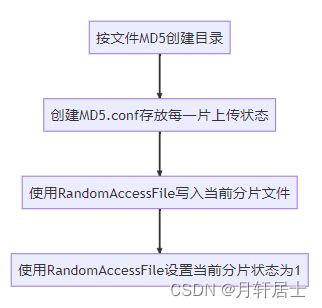
MD5.conf每一次检测文件不存在里创建个空文件,使用
byte[] bytes = new byte[totalNumber];将每一位状态设置为0,从0位天始,第N位表示第N个分片的上传状态,0-未上传 1-已上传,当每将上传成功后使用randomAccessConfFile.seek(chunkNumber)将对就设置为1。 -
randomAccessFile.seek(chunkNumber * chunkSize);可以将光标移到文件指定位置开始写数据,每一个文件每将上传分片编号chunkNumber都是不一样的,所以各自写自己文件块,多线程写同一个文件不会出现线程安全问题。 -
大文件写入时用
RandomAccessFile可能比较慢,可以使用MappedByteBuffer内存映射来加速大文件写入,不过使用MappedByteBuffer如果要删除文件可能会存在删除不掉,因为删除了磁盘上的文件,内存的文件还是存在的。
MappedByteBuffer写文件的用法:
FileChannel fileChannel = randomAccessFile.getChannel();
MappedByteBuffer mappedByteBuffer = fileChannel.map(FileChannel.MapMode.READ_WRITE, chunkNumber * chunkSize, fileData.length);
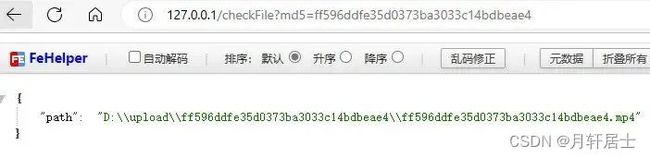
mappedByteBuffer.put(fileData);checkFile接口流程:

大文件上传完整Java代码
@RestController
public class UploadController {
public static final String UPLOAD_PATH = "D:\\upload\\";
/**
* @param chunkSize 每个分片大小
* @param chunkNumber 当前分片
* @param md5 文件总MD5
* @param file 当前分片文件数据
* @return
* @throws IOException
*/
@RequestMapping("/uploadBig")
public ResponseEntity> uploadBig(@RequestParam Long chunkSize, @RequestParam Integer totalNumber, @RequestParam Long chunkNumber, @RequestParam String md5, @RequestParam MultipartFile file) throws IOException {
//文件存放位置
String dstFile = String.format("%s\\%s\\%s.%s", UPLOAD_PATH, md5, md5, StringUtils.getFilenameExtension(file.getOriginalFilename()));
//上传分片信息存放位置
String confFile = String.format("%s\\%s\\%s.conf", UPLOAD_PATH, md5, md5);
//第一次创建分片记录文件
//创建目录
File dir = new File(dstFile).getParentFile();
if (!dir.exists()) {
dir.mkdir();
//所有分片状态设置为0
byte[] bytes = new byte[totalNumber];
Files.write(Path.of(confFile), bytes);
}
//随机分片写入文件
try (RandomAccessFile randomAccessFile = new RandomAccessFile(dstFile, "rw");
RandomAccessFile randomAccessConfFile = new RandomAccessFile(confFile, "rw");
InputStream inputStream = file.getInputStream()) {
//定位到该分片的偏移量
randomAccessFile.seek(chunkNumber * chunkSize);
//写入该分片数据
randomAccessFile.write(inputStream.readAllBytes());
//定位到当前分片状态位置
randomAccessConfFile.seek(chunkNumber);
//设置当前分片上传状态为1
randomAccessConfFile.write(1);
}
return ResponseEntity.ok(Map.of("path", dstFile));
}
/**
* 获取文件分片状态,检测文件MD5合法性
*
* @param md5
* @return
* @throws Exception
*/
@RequestMapping("/checkFile")
public ResponseEntity> uploadBig(@RequestParam String md5) throws Exception {
String uploadPath = String.format("%s\\%s\\%s.conf", UPLOAD_PATH, md5, md5);
Path path = Path.of(uploadPath);
//MD5目录不存在文件从未上传过
if (!Files.exists(path.getParent())) {
return ResponseEntity.ok(Map.of("msg", "文件未上传"));
}
//判断文件是否上传成功
StringBuilder stringBuilder = new StringBuilder();
byte[] bytes = Files.readAllBytes(path);
for (byte b : bytes) {
stringBuilder.append(String.valueOf(b));
}
//所有分片上传完成计算文件MD5
if (!stringBuilder.toString().contains("0")) {
File file = new File(String.format("%s\\%s\\", UPLOAD_PATH, md5));
File[] files = file.listFiles();
String filePath = "";
for (File f : files) {
//计算文件MD5是否相等
if (!f.getName().contains("conf")) {
filePath = f.getAbsolutePath();
try (InputStream inputStream = new FileInputStream(f)) {
String md5pwd = DigestUtils.md5DigestAsHex(inputStream);
if (!md5pwd.equalsIgnoreCase(md5)) {
return ResponseEntity.ok(Map.of("msg", "文件上传失败"));
}
}
}
}
return ResponseEntity.ok(Map.of("path", filePath));
} else {
//文件未上传完成,反回每个分片状态,前端将未上传的分片继续上传
return ResponseEntity.ok(Map.of("chucks", stringBuilder.toString()));
}
}
} 配合前端上传演示分片上传,依次按如下流程点击按钮:
3.断点续传
有了上面的设计做断点续传就比较简单的,后端代码不需要改变,只要修改前端上传流程就好了:
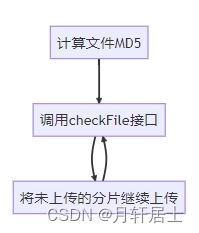

用/checkFile接口,文件里如果有未完成上传的分片,接口返回chunks字段对就的位置值为0,前端将未上传的分片继续上传,完成后再调用/checkFile就完成了断点续传
4.秒传
秒传也是比较简单的,只要修改前端代码流程就好了,比如张三上传了一个文件,然后李四又上传了同样内容的文件,同一文件的MD5值可以认为是一样的(虽然会存在不同文件的MD5一样,不过概率很小,可以认为MD5一样文件就是一样),10万不同文件MD5相同概率为110000000000000000000000000000\frac{1}{10000000000000000000000000000}100000000000000000000000000001,福利彩票的中头奖的概率一般为11000000\frac{1}{1000000}10000001,具体计算方法可以参考走近消息摘要--Md5产生重复的概率,所以MD5冲突的概率可以忽略不计。
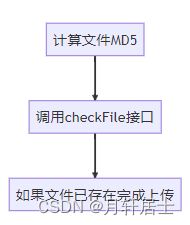
当李四调用/checkFile接口后,后端直接返回了李四上传的文件路径,李四就完成了秒传。大部分云盘秒传的思路应该也是这样,只不过计算文件HASH算法更为复杂,返回给用户文件路径也更为安全,要防止被别人算出文件路径了。
秒传前端代码流程:
本文从前端和后端两个方面介绍了大文件的分片上传、断点继续、秒传设计思路和实现代码,所有代码都是亲测可以直接使用。