金钱逗号表示法
For past few months I have been very interested into self driving car technology. There are infinitely many possibilities upon how you can apply your machine learning knowledge to develop parts of the self driving car stack.
在过去的几个月中,我对自动驾驶汽车技术非常感兴趣。 如何运用您的机器学习知识来开发自动驾驶汽车堆栈的部件,有无限多种可能性。
In this post, I’d be taking you through the process of developing an end to end motion planner for autonomous robots. This project is hugely inspired by the approach that comma.ai uses in open pilot.
在本文中,我将带您完成为自动机器人开发端到端运动计划器的过程。 该项目的灵感来自comma.ai在开放试验中使用的方法。
自我驾驶的不同方法 (Different Approaches to Self Driving)
There are several approaches to make a self driving car software. The model can either be trained end-to-end or models can be trained using mid to mid approach. Below are some examples:
有几种方法可以制作自动驾驶汽车软件。 可以端到端地训练模型,也可以使用中到方法来训练模型。 以下是一些示例:
End to End Behavioral Cloning: In this approach, A CNN is trained end-to-end. Input is a sequence of images or a single image, and output is directly a steering angle. This approach got popular when Nvidia trained this type of neural network at scale. Respective blog can be found here. I have also worked on implementing many similar kinds of model. The link to the repo can be found here. It contains step by step procedure to train these kinds of model, some of them are: Nvidia’s model, Comma AI’s model, 3D CNNs, LSTMs. This approach is quite easy to implement since model learns almost everything internally and we won’t have to implement out conventional control stack, localizer, planner, etc. But the downside ? You lose full control over the model output, cannot interpret the results understood by humans (total black boxes), difficult to incorporate prior knowledge.
端到端行为克隆:在这种方法中,对CNN进行端到端训练。 输入是图像序列或单个图像,输出直接是转向角。 当Nvidia大规模训练这种类型的神经网络时,这种方法很受欢迎。 各自的博客可以在这里找到。 我还致力于实现许多类似的模型。 到仓库的链接可以在这里找到。 它包含逐步训练这些模型的过程,其中一些是:Nvidia模型,Comma AI模型,3D CNN,LSTM。 这种方法很容易实现,因为模型几乎是内部学习的,而我们不必实现传统的控制堆栈,本地化器,计划器等。但是缺点是? 您将无法完全控制模型输出,无法解释人类所理解的结果(总黑匣子),难以吸收先验知识。

Mid to Mid: In this approach, instead of directly outputting controls, the network is broken down into as many parts as you would like to. For example, training separate networks for object detection, motion prediction, path planning, etc. This approach is used by Lyft, Tesla, etc. Shown below, is how Lyft detects other vehicles, place them on a sementic map of surroundings, and predicts motion of all other things whose results are further passed to controllers which finally produces steering, throttle, etc outputs.
中到中:在这种方法中,不是直接输出控件,而是将网络分解为任意数量的部分。 例如,训练单独的网络以进行对象检测,运动预测,路径规划等。Lyft,Tesla等使用此方法。Lyft如何检测其他车辆,将其放置在特定的周围地图上并进行预测所有其他事物的运动,其结果进一步传递给控制器,这些控制器最终产生转向,油门等输出。

Disadvantages of this approach are, the errors keep accumulating through multiple steps, putting all the pieces of this together is exponentially harder. But on the flip side, advantages are, the process is fully interpretable by humans and can easily reason the decisions of the self driving car. Other than that, incorporating prior knowledge is now possible.
这种方法的缺点是,错误会通过多个步骤不断累积,将所有这些问题放在一起要困难得多。 但另一方面,好处是,该过程完全可以由人解释,并且可以轻松推断自动驾驶汽车的决策。 除此之外,现在可以合并现有知识。
Comma’s Approach: Comma skips object detection, depth estimation, etc to directly output trajectory to be followed by the vehicle. Read more about this in their blog post here. This path is then tracked by conventional control stack maintained by their team.
逗号方法:逗号跳过对象检测,深度估计等,以直接输出车辆要遵循的轨迹。 在此处的博客文章中阅读有关此内容的更多信息。 然后由他们的团队维护的常规控制堆栈跟踪此路径。
了解OpenPilot超级组合模型 (Understanding the OpenPilot Super Combo Model)
The supercombo model is elegantly crafted, yet lightweight which takes inputs as:
supercombo模型制作精巧,重量轻,输入如下:
- 2 Consecutive image frames in YUV format 2个YUV格式的连续图像帧
- State of the Recurrent Cells (being a recurrent neural network)循环细胞的状态(是循环神经网络)
- Desire (Discussed later) 欲望(稍后讨论)
And Predicts the following Outputs:
并预测以下输出:
- Path (Trajectory output to be followed) 路径(要遵循的轨迹输出)
- Left Lane 左车道
- Right Lane右车道
- Standard Deviations of Path and Lanes (Discussed Below)路径和车道的标准偏差(在下面讨论)
- Lead Car information 铅车信息
- Longitudinal Accelerations, Velocities and Displacements for n future steps纵向加速度,速度和位移,用于以后的n个步骤
- Pose (Discussed Below)姿势(在下面讨论)
- And some other stuff I am not sure about 还有一些我不确定的东西
The Path, Left Lane and Right Lane are the ‘Predicted Trajectory’ and the lane lines in Top Down / Bird’s Eye View coordinate system relative the the ego vehicle.
路径,左车道和右车道是“预测的轨迹”,并且自上而下/鸟瞰视图坐标系中的车道线相对于自我车辆。
See how the model predicts the curve on the road to the right. This ‘minimal model inferencer’ was opensourced by littlemountainman and can be found here.
查看模型如何预测右侧道路上的弯道。 这个“最小模型推论者”是littlemountainman开源的,可以在这里找到。
The one other thing to see here is that lane lines also fade when no lane lines are visible, or simply when the model is less confident about it’s prediction. This ‘confidence’ score is basically predicted by the model too and are simply the ‘standard deviations’. These standard deviations are predicted for each of the path, left lane and right lane and many other outputs including pose, lead outputs, etc.
在这里要看到的另一件事是,当看不到任何车道线时,或者仅仅是在模型对其预测缺乏信心时,车道线也会消失。 该“置信度”分数也基本上由模型预测,并且仅仅是“标准差”。 这些标准偏差是针对每个路径,左车道和右车道以及许多其他输出(包括姿势,领先输出等)进行预测的。

The standard deviations can be predicted using a Bayesian Neural Network that carries the unceartinity of the predictions down through the network as they are computed.
可以使用贝叶斯神经网络来预测标准偏差,该贝叶斯神经网络在计算预测时会通过网络向下传递预测的不确定性。
The pose output is the predicted translation and rotation between the two input images. This is probably used to perform visual odometery and to localize the car with respect to output trajectories.
姿势输出是两个输入图像之间的预测平移和旋转。 这可能用于执行视觉里程表并相对于输出轨迹定位汽车。
资料建立 (Data Creation)
Before even thinking of training the neural network, we need to collect and process the data into the right format for training. Comma.ai has released an opensource dataset containing much of this information like lanes, path and other stuff. But I wanted a bit more of the challenge and instead decided to use Udacity’s dataset that just contained:
在甚至考虑训练神经网络之前,我们需要收集数据并将其处理为正确的格式以进行训练。 Comma.ai发布了一个开源数据集,其中包含许多此类信息,例如车道,路径和其他内容。 但是我想要更多的挑战,而是决定使用刚包含的Udacity数据集:
- Steering angles 转向角
- Speed速度
- Gyroscope Readings陀螺仪读数
- GPS ReadingsGPS读数
- Image frames from center, left and right mounted camera.来自中央,左侧和右侧已安装摄像机的图像帧。
For training a custom model, I decided to just predict future path and speeds.
为了训练定制模型,我决定只预测未来的路径和速度。
欲望 (Desire)
Desire in basically a one-hot encoding of high level actions like ‘change lane left’, ‘change lane right’, ‘stay in lane’, ‘turn right’, ‘turn left’, etc.
基本上希望对高级别动作(例如“左转车道”,“右转车道”,“待在车道”,“向右转”,“向左转”等)进行一键编码。
The Udacity Dataset didn’t contain any “desire”. So I needed to manually label 10, 000 frames :(
Udacity数据集不包含任何“需求”。 所以我需要手动标记10,000帧:(
Labeling 10,000 frames by hand is not that easy. So instead of labeling each frame individually, I created a small tool for this purpose. The Autolabler.
手动标记10,000帧并非易事。 因此,我没有为此单独标记每个框架,而是为此目的创建了一个小工具。 自动标签器。
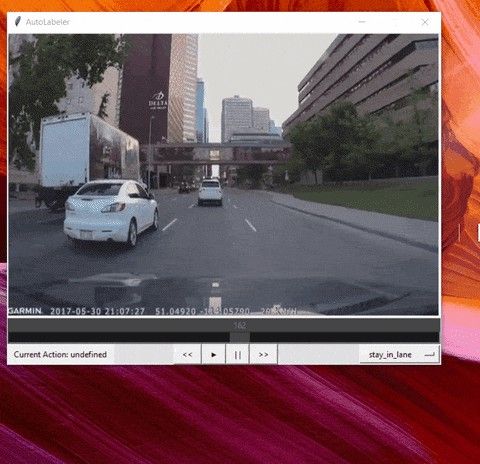
Using this, I labelled the whole dataset in under 30 minutes. It’s more like a small video player, you can pause, seek, fast forward, slow down the input frame stream as you like. It keeps tagging the selected label on the fly as the stream is being played. The full description for using it can be found in my repo.
使用此工具,我在30分钟内标记了整个数据集。 它更像是一个小型视频播放器,您可以根据需要暂停,搜索,快进,减慢输入帧流。 在播放流时,它会一直动态标记选定的标签。 使用它的完整描述可以在我的仓库中找到。
路径 (Path)
For trajectory ground truthing, I was constrained to use only the information that was present in the udacity dataset.
对于轨迹地面真实性,我被限制为仅使用udacity数据集中存在的信息。
First of all, I used a simple bicycle model to step it through time using velocity and steering angle inputs to the vehicle model.
首先,我使用一个简单的自行车模型通过使用输入到车辆模型的速度和转向角来逐步跟踪时间。
At low speeds, a simple bicycle model is used considering center of mass as the reference frame.
在低速时,使用简单的自行车模型,将质心作为参考框架。
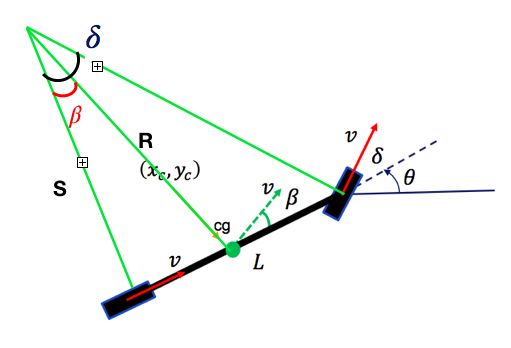
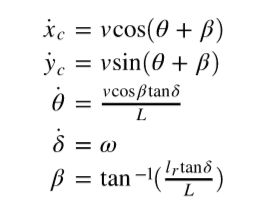
I could had used dynamic model for lateral control, but I didn’t really had data for vehicle parameters that was used to collect the dataset.
我本可以使用动态模型进行横向控制,但实际上并没有用于收集数据集的车辆参数数据。
Now definitely, the the above model is very simple and cannot really model the actual physics of the vehicle very well, so it definitely made sense to use additional data from gyro and GPS and fuse it together with kalman filters. Also, one other rule of developing an algorithm is, never ever throw any data away even if it is very noisy. Find ways to incorporate any information from other data sources. This would always only improve the algorithm.
现在绝对可以肯定,以上模型非常简单,无法真正很好地对车辆的实际物理模型进行建模,因此使用来自陀螺仪和GPS的其他数据并将其与卡尔曼滤波器融合在一起绝对是有道理的。 同样,开发算法的另一条规则是,即使数据非常嘈杂,也永远不要丢弃任何数据。 寻找合并其他数据源中任何信息的方法。 这总是只会改善算法。
Fortunately, the GPS model was known, so I was able to construct a kalman filter.
幸运的是,GPS模型是已知的,因此我能够构造一个卡尔曼滤波器。

See how the process model (Red) starts drifting away from original trajectory in after some time.
了解一段时间后流程模型(红色)如何开始偏离原始轨迹。
I used 3 methods of tracking and combined them together using kalman filter.
我使用了3种跟踪方法,并使用卡尔曼滤波器将它们组合在一起。
- Bicycle Model as the process mode 自行车模型作为处理模式
- GPS readingsGPS读数
- IMU Based Odometery基于IMU的里程表
- Visual Odometery视觉里程表
One difficulty I found was to make sure all the readings are converted to the same coordinate system with same reference (Car). For example, for GPS readings, latitude and longitude had to be converted to a XY grid system in meters.
我发现的一个困难是要确保所有读数都转换为具有相同参考(Car)的相同坐标系。 例如,对于GPS读数,纬度和经度必须转换为以米为单位的XY网格系统。
For small distances, I used below formula as approximaton to find distance between two latitude longitude pairs in meters. Latitude and longitude are basically measurements on a globe (angles) wrt Equator and prime meridian respectively.
对于小距离,我使用以下公式作为近似值,以米为单位查找两个纬度经度对之间的距离。 纬度和经度基本上是分别针对赤道和本初子午线的地球(角度)的度量。

def latlon_to_xy_grid(lat1, lon1, lat2, lon2):
dx = (lon1-lon2)*40075*math.cos((lat1+lat2)*math.pi/360)/360
dy = (lat1-lat2)*40075/360
return dx, dyNow, to collect extra data that included cases like avoiding obstacles, tight curves, and the problem of ‘car drifting away from the lane’, I made use of the CARLA simulator.
现在,为了收集包括避开障碍物,弯道过弯以及“汽车偏离车道”等问题在内的额外数据,我使用了CARLA仿真器。

Since I had the parameters of the camera used to collect the udacity dataset, I was able to design a similar camera model in CARLA. It was relatively easy to obtain ground truth data from CARLA.
由于我具有用于收集udacity数据集的摄像机的参数,因此我能够在CARLA中设计类似的摄像机模型。 从CARLA获得基本事实数据相对容易。
Also, for avoiding obstacles, I wrote a script that would create a scene, place a vehicle on edge of the lane, and use the CARLA autopilot to generate trajectory to avoid the obstacle. In few minutes after writing the script, I had thousands of scenes of this type of scenarios. This could actually make model worse for real life because this may not really be close to what humans would actually do in real life.
另外,为了避免障碍物,我编写了一个脚本来创建场景,将车辆放置在车道边缘,并使用CARLA自动驾驶仪生成避免障碍物的轨迹。 编写脚本后几分钟,我就看到了成千上万种此类场景。 实际上,这可能会使模型对现实生活变得更糟,因为这可能与人类在现实生活中实际所做的事情并不十分接近。
There were certain problems with how CARLA directly saved the data to disk. This caused a huge slowdown of the simulator that made it impossible to manually control the car and also caused slowdown in data collection process.
CARLA如何将数据直接保存到磁盘存在某些问题。 这导致模拟器大大降低,使其无法手动控制汽车,也导致数据收集过程降低。
Due to this, I had to write manual buffers that would keep on accumulating data until a certain size and dump them to disk at once. This hugely improved the efficiency of data collection process.
因此,我不得不编写手动缓冲区,该缓冲区将不断累积数据直到达到一定大小,然后立即将其转储到磁盘。 这极大地提高了数据收集过程的效率。

Now Finally the data collection process was complete. Let’s move to model training !
现在终于完成了数据收集过程。 让我们开始进行模型训练!
分析逗号模型 (Analyzing Comma’s Model)
For feature extraction from frames, comma uses a lot of skip connections and converts a 256 x 128 x 12 (two YUV format consecutive frames with 3 extra alpha channels. see here) and boils them down to 1024 dimensional encoding.
为了从帧中提取特征,逗号使用了大量的跳过连接并转换256 x 128 x 12(两个具有3个额外alpha通道的YUV格式连续帧。请参见此处),并将其简化为1024维编码。
This encoding learns all the information from the image once you train the path planner.
训练路径规划器后,此编码将从图像中学习所有信息。

“We can get insight into what is encoded in the 1024 output vector of the vision model by running it on an image and trying to reconstruct an image from it with a GAN. Above is the original image of a road, below is a reconstruction made by a GAN trained on a few million images and feature vectors. Notice how details relevant to planning such as locations of the lanes and lead car are preserved, while irrelevant details such as the colors of cars and background scenery are lost.” — Harald Schäfer
“我们可以通过在图像上运行视觉模型并尝试使用GAN从视觉图像中重构出图像来了解视觉模型的1024输出向量中编码的内容。 上图是道路的原始图像,下图是经过GAN训练的GAN重建而成,其经过了数百万个图像和特征向量的训练。 请注意,如何保留与规划相关的细节(例如车道和领头车的位置),而与细节无关的细节(如汽车的颜色和背景风景)将丢失。” —哈拉德·谢弗(HaraldSchäfer)
The model learns to encode all the relevant information required for planning into a compressed form. This vision encoding is later forked into several branches which are processed independently to output lanes, paths, etc.
该模型学习将计划所需的所有相关信息编码为压缩形式。 此视觉编码随后分叉到几个分支中,这些分支独立处理为输出通道,路径等。
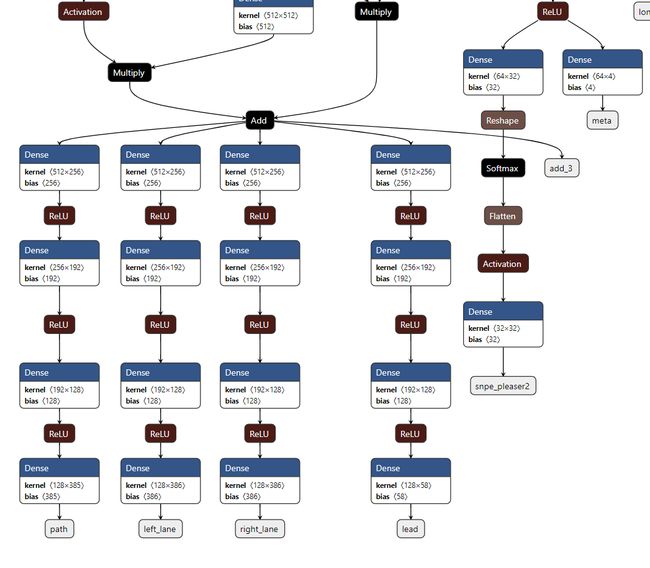
Comma also uses a GRU like layer that is used to encode the temporal information too. The network is stateful and the state output of the recurrent layer is re-fed during the next inference.
逗号还使用类似GRU的层,该层也用于编码时间信息。 网络是有状态的,并且在下一次推断期间会重新提供循环层的状态输出。
训练模型 (Training The Model)
for training the model, I will be taking desire and frames as input (RNN state is fed only during inference time) and outputs would be only the path and velocities for future 50 meters/steps and the standard deviations.
为了训练模型,我将期望和帧作为输入(仅在推理时间内提供RNN状态),而输出仅是未来50米/步的路径和速度以及标准偏差。
贝叶斯神经网络 (Bayesian Neural Networks)
Standard Deviations gives us an idea about how confident is the model about it’s prediction. This can be done using a special kind of network called Bayesian Neural Network.
标准差使我们对模型的预测有多自信。 这可以使用一种称为贝叶斯神经网络的特殊类型的网络来完成。
Instead of directly regressing the lanes, paths, velocities, we would be predicting a distribution.
我们将直接预测分布,而不是直接回归车道,路径,速度。
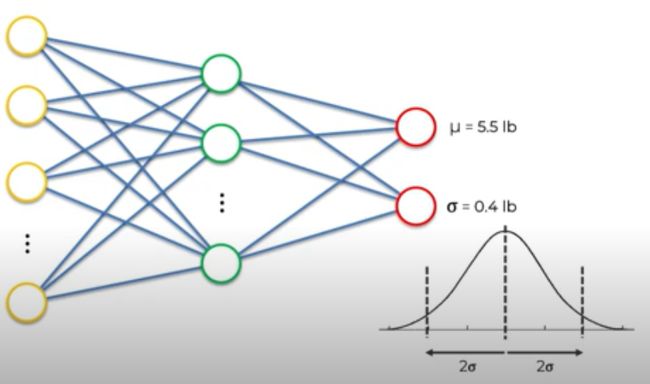
See this video by AI student for a beautiful explanation on this.
观看AI学生的这段视频,以获取有关此内容的详细说明。
We can use a mixture density networks for outputting multiple paths and their confidence scores, which converts this into a mixture density network.
我们可以使用混合密度网络来输出多个路径及其置信度得分,从而将其转换为混合密度网络。

I used a batch size of 16 with 16 time steps from the past with 2 gaussian mixtures for training the network.
我使用批次大小为16,具有过去16个时间步长的2种高斯混合气体来训练网络。
数据扩充 (Data Augmentation)
I used data augmentation for making model robust to noise. These included adding poisson noise to images, shuffling color channels of images, flipping images horizontally, increasing/decreasing contrast, temperature, etc of the images.
我使用数据增强使模型对噪声更强。 这些措施包括为图像增加泊松噪声,改组图像的色彩通道,水平翻转图像,增加/减小图像的对比度,温度等。

损失函数(Loss function)
Simple Point Output (No unceartanity prediction): In practical applications, we minimize the squared error term ( μ(x, Θ)− y )² of the output of the linear function μ given x, its parameters Θ, and the target value y for all pairs of (x, y) in some dataset . The learned function essentially “spits” out the conditional mean of the Gaussian distribution μ(x, Θ) given the data and parameters. It throws away the std. deviation and normalization constant, which do not depend on Θ.
单点输出(无不可预测性预测):在实际应用中,我们将给定x ,其参数Θ和目标值y的线性函数μ的输出的平方误差项(μ( x , Θ )− y )²最小化对于( x , y )在某些数据集中。 给定数据和参数,学习到的函数实质上“吐出”了高斯分布μ( x , Θ )的条件平均值。 它扔掉了性病。 偏差和归一化常数,它不依赖于Θ。
I tried multiple loss functions. In case of simple regression output (as discussed bove)(simple neural network, no standard deviation outputs), I used weighted sum of L2 loss between trajectories and L1 loss between the gradients of trajectories.
我尝试了多种损失函数。 在简单回归输出的情况下(如上所讨论)(简单神经网络,没有标准差输出),我使用了轨迹之间的L2损失和轨迹梯度之间的L1损失的加权和。
The intuition behind gradient loss is, we as humans estimate the ‘intensity’ of rotating the steering wheel according to the curves on the road. So it made sense to incorporate this into the loss function which turned to perform better than ‘simple L2 between trajectories alone’.
梯度损失背后的直觉是,我们作为人类,根据道路上的弯道来估计旋转方向盘的“强度”。 因此,将其纳入损失函数是有意义的,而损失函数的性能要优于“仅在轨迹之间的简单L2”。
MDN Network: The standard deviation in this case is now conditioned on the input, allowing us to account for variable standard deviation. Even when we are just using a single Gaussian distribution, this advantage applies.
MDN网络:现在,这种情况下的标准偏差取决于输入,因此我们可以考虑可变的标准偏差。 即使我们仅使用单个高斯分布,也具有这种优势。
For the MDN (predicting standard deviations too), the loss is computed as
对于MDN(也可以预测标准偏差),损耗计算为
cat = tfd.Categorical(logits=out_pi)
component_splits = [output_dim] * num_mixes
mus = tf.split(out_mu, num_or_size_splits=component_splits, axis=1) sigs = tf.split(out_sigma, num_or_size_splits=component_splits, axis=1)
coll = [tfd.MultivariateNormalDiag(loc=loc, scale_diag=scale) for loc, scale in zip(mus, sigs)]mixture = tfd.Mixture(cat=cat, components=coll)
loss = mixture.log_prob(y_true)
loss = tf.negative(loss)
loss = tf.reduce_mean(loss)I used implementation from this repo.
我使用了这个仓库中的实现。
测试中 (Testing)
See how the network outputs the means (actual path) and deviations.
查看网络如何输出均值(实际路径)和偏差。
Initially, the model is confident about the prediction and the deviation is low, but as the model predicts trajectory into the future, deviation increases, which make intuitive sense.
最初,模型对预测充满信心,偏差很小,但是随着模型预测未来的轨迹,偏差会增加,这很直观。


Even the openpilot model shows similar behavior.
甚至openpilot模型也显示出类似的行为。
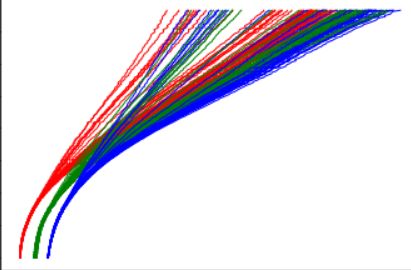
See how the model is fairly confident at smaller distances but predictions gets more noisier and unstable at larger distance.
了解该模型在较小距离下如何充满信心,但是在较大距离下预测会变得更加嘈杂和不稳定。
I’d be doing more rigorous testing and would be posting a video for model in action soon, on real life, as well as from synthetic data. Now we have the trajectories output, in next post we may discuss about how to actually convert trajectory to controls and control a simulated car. But this is going to be a lot of more work. But let’s try nonetheless :D
我将进行更严格的测试,并会在现实生活中以及从合成数据中发布用于模型的视频。 现在我们有了轨迹输出,在下一篇文章中,我们可能会讨论如何实际将轨迹转换为控件并控制模拟汽车。 但是,这将是一个很大的更多的工作。 但是尽管如此,让我们尝试:D
结论 (Conclusion)
Congratulations on making it to the end ! This was a long post.
恭喜您成功! 这是一个很长的帖子。
So, this was my journey to train an end to end path planner hugely inspired by the work of comma.ai. I’d like to that the comma.ai discord community for answering a lot of my doubts :D . I do not guarantee that all things in this post are correct. Please feel free to point any errors you may find and help in correcting them by commenting below.
因此,这是我受comma.ai的启发极大地培训端到端路径规划器的旅程。 我想要comma.ai不和谐社区回答我的很多疑问:D。 我不保证本文中的所有内容都是正确的。 请随时指出您可能发现的任何错误,并通过以下评论来帮助纠正错误。
I have explored a lot of things during this project. I didn’t really go into much details in this articles as well as I missed to write a lot of challenges faced by me during this project. Next time, I would try to write the article side by side so I don’t forget to add anything.
在这个项目中,我探索了很多东西。 在本文中我并没有真正详细介绍,也错过了写这个项目期间我面临的许多挑战。 下次,我将尝试并排写这篇文章,这样我就不会忘记添加任何内容。
Please feel free to ask any questions down below in comments :)
请随时在下面的评论中提问:)
码 (Code)
The whole project is some thousand lines of ‘not very well structured code’. I’d upload it after cleaning it up a bit. Keep an eye on my GitHub and LinkedIn for further updates :)
整个项目是几千行“结构不是很好的代码”。 我将其清理干净后再上传。 密切关注我的GitHub和LinkedIn,以获取更多更新:)
翻译自: https://medium.com/@mankaran32/end-to-end-motion-planning-with-deep-learning-comma-ais-approach-5886268515d3
金钱逗号表示法