python判断空字节_Python的第三天:字符串和字节数据类型,搬,砖,之,旅,3rdday,Bytes,专题...

Python搬砖之旅(3rd day):字符串、Bytes数据类型专题
第1章 字符串的创建
在我们日常生活中,处理最多的数据其实不是数值,而是"字符串"。
在Python程序中,我们使用一对单引号或一对双引号包裹住一串字符,来创建字符串,或者使用三对单引号或三对双引号来创建多行字符串。
字符串的数据类型是"str",字符串可以被print()函数直接打印出来。
str1 = 'I Love Python'
print(type(str1))
str2 = "I Love China"
print(type(str2))
str3 = """
我爱我的祖国,
一刻也不能分割!
"""
print(type(str3))
print(str3)
程序运行结果如下:
我爱我的祖国,
一刻也不能分割!
可以看出,以上三种方法都可以创建一个字符串对象。
我们也可以使用"" 或 ''来创建一个空字符串。
>>> s = ''
>>> print(s)
''
可以看出,打印结果为空字符串。
第2章 字符的访问
字符串被创建的时候,每个字符是"
单独存储
"的,分配在了连续的内存空间里,而整数的所有内容,都放在一个内存空间内。
字符串其本身是一个字符的"序列",也就是说,字符被分配到了连续的内存空间里,我们可以通过index(索引)来访问字符串中的字符。
注意:
index(索引)是从 0 开始的
。

从上面这幅图,我们就可以清晰地了解到整数型数据类型与字符串型数据类型的区别:
整数型的数值对象是整体保存在一个32位的内存块中(有些编程语言使用int64或者int8等其他的数据类型,那么内存块的大小可能并不是固定的);而字符串中的每个"字符"是被"单独"保存,每一块内存都单独保存一个字符,并且字符串的地址空间是"
连续
"的,这样我们就能按顺序访问特定的字符。
现在,创建一个字符串"I Love China"我们分别来使用索引访问其中的 “I” 、“L”、 “a"这三个字符。
我们先观察一下这个字符串的位置顺序。

细心的同学们已经发现了这个字符串的奥秘了吧:
1,空格占用一个字符串的位置;
2,索引的方向有两个,一个是从左向右(从头向尾),一个是从右向左(从尾向头)
3,从左向右的索引起始位置是"0”,而从右向左的起始位置是"-1"。
接下来,我们使用index索引来访问字符
>>> s = "I Love China"
>>> s[0] # 访问首字符
'I'
>>> s[2] # 访问"L"字符
'L'
>>> s[-1] # 访问最后一个字符
'a'
思考:
在上面的案例中,我们能通过索引取到字符串之外的字符吗?比如s[12]或者s[-13]吗?
我们来看看会发生什么。
>>> s[12]
Traceback (most recent call last):
File "", line 1, in
s[12]
IndexError: string index out of range
>>> s[-13]
Traceback (most recent call last):
File "", line 1, in
s[-13]
IndexError: string index out of range
上述的两种方式都报了一个"string index out of range"的错误,翻译过来就是说索引超出范围。
所以说,
索引的范围不能超过字符串本身的长度
。
有了索引,我们就能实现字符串的遍历,字符串的遍历有三种方法:
方法一:使用while循环遍历
s = "I Love China."
i = 0 # 设定索引的起始位置
while i < len(s): # 索引的范围不能超过字符串的长度
print(s[i],end = '') # 依次打印字符串中索引对应的字符
i += 1 # 每次循环后索引向后增加一位
方法二:使用for循环迭代遍历
s = "I Love China."
for i in s: # 使用迭代后,i依次取到s中的每个字符
print(i, end = '')
方法三:使用for循环迭代 + 索引的方式 (推荐)
s = "I Love China."
for i in range(len(s)): # 使用迭代后,i依次+1,范围不超过字符串长度
print(s[i], end = '')
小练习:
在 Robert McCloskey 的一本名叫《Make Way for Ducklings》的书中,小鸭子的名字依次为:Jack, Kack, Lack, Mack, Nack, Ouack, Pack, 和Quack。想一个办法,能够依次输出小鸭子们的名字。
参考答案:
#下面这个循环会依次输出他们的名字:
# 这串字符包含了首字符
prefixes = 'JKLMNOPQ'
# 这是字符串的后缀
suffix = 'ack'
for letter in prefixes:
if letter != "O" and letter != "Q":
print(letter + suffix)
else:
print(letter + "u" + suffix)
第3章 字符串的切片
如果我们遇到需要使用字符串中某一段字符的情况,应该怎么处理呢?
这时候我们就需要使用字符串的切片功能了。
字符串切片的语法格式为str[start : end : (step)]
这里,start指字符串的起始位置;end指字符串的结束位置,step为步长,默认为1.
需要注意的是,
使用切片功能获取字符串片段,是一个左闭右开的区间,即切片的取值范围在
[start, end) 的区间
,切片的字符串最多只能取到end-1的位置。
我们来看下面这段代码:
>>> s = "I Love China"
>>> s[:1] # 取"I"这个单词
'I'
>>> s[2:6] # 取"Love"这个单词
'Love'
>>> s[-5:] # 取"China"这个单词
'China'
我们来观察上面的代码:
1,当起始位置为0的时候,start可以省略,但是":“需要保留,所以s[:1]等价于s[0:1];
2,当结束位置为字符串长度+1时,end可以省略,但是”:"需要保留,所以s[-5:]等价于s[-5:12];
3,使用切片时,是取不到end位置的字符的。如果需要取end位置的字符,需要让end加1。
比如,字符"e"对应的索引位置是5,但是我们使用s[2:5]就只能取到’Lov’这个片段,想要完整地获得’Love’这个字符串,需要让end+1,即取s[2:6]。
关于步长:
步长是指在字符串中取字符时,每次前进的单位,默认为1,即按顺序取值。
当步长为1时,步长可以省略,第二个":"也可以省略。
如果步长为2的话,需每隔一个字符取值,以此类推;
步长有正向和逆向,正向从左向右取值,逆向从右向左取值。
观察下列代码:
>>> s = "0123456789"
>>> s[::] # 全选,步长为1,其实就是其本身
'0123456789'
>>> s[::2] # 全选,步长为2的情况
'02468'
>>> s[1::2] # 设定起始位置,步长为2的情况
'13579'
>>> s[::-1] # 全选,步长为-1,其实就是字符串的逆序排列
'9876543210'
>>> s[-1::-1] # s[-1::-1] 与 s[::-1] 是等价的
'9876543210'
>>> s[::-2] # 全选,步长为-2的情况
'97531'
>>> s[-1::-2] # s[-1::-2] 与 s[::-2] 其实是等价的
'97531'
>>> s[-2::-2] # 设定起始位置,步长为-2的情况
'86420'
>>> s[3:8:2] # 切片方向与步长方向一致,返回结果
'357'
>>> s[3:8:-2] # 切片方向与步长方向不一致,返回空字符串
''
>>> s[8:3:-2] # 切片方向与步长方向一致,返回结果
'864'
>>> s[8:3:2] # 切片方向与步长方向不一致,返回空字符串
''
规律分析:
步长的方向应该与切片的方向一致
当切片的start位置 < end 位置时,切片的方向时从左向右,与之对应的,step的数值应>0;
当切片的start位置 > end 位置时,切片的方向时从右向左,与之对应的,step的数值应<0;
如果切片方向与步长方向一致,返回切片结果;
如果切片方向与步长方向不一致,返回空字符串。
小结:
字符串的索引默认从0开始;
字符串切片的范围是左闭右开区间;
当取单个字符的时候,索引超出字符串的长度会报错,而切片时则不会报错;
切片时,步长不能为0,也不允许为浮点数;
切片时,步长的方向应该与切片的方向一致。
第4章 字符串的修改
提出一个问题:
有一个字符串"I Love China",我们需要将其中的"Love"改成"love",我们可以使用索引或切片的方式吗?
答案是不能。
>>> s = "I Love China"
>>> s[2] = 'l' # 字符串不能使用索引修改字符,这是错误的写法
Traceback (most recent call last):
File "", line 1, in
s[2] = 'l'
TypeError: 'str' object does not support item assignment
>>> s[2:6] = 'love' # 字符串不能使用切片修改字符,这是错误的写法
Traceback (most recent call last):
File "", line 1, in
s[2:6] = 'love'
TypeError: 'str' object does not support item assignment
我们发现系统报了一个错误:str类型不支持元素赋值,这说明了什么问题?
这说明,字符串是一种"
不可变
"的序列数据类型,也就是说,我们
不能通过索引或切片直接修改字符串本身,要修改字符串,就必须重新对其进行赋值
!
>>> s = "I Love China"
>>> s = "I love China" # 修改字符串需重新对字符串整体赋值
>>> s
'I love China'
思考:
如果要将字符串"I Love China." 改为 “I Love Python.”,除了整体改字符串的方法,还有其他什么方法?
答案:使用字符串切片。
>>> s = "I Love China."
>>> s = s[:7] + "Python" + s[-1]
>>> s
'I Love Python.'
第5章 字符串的类型转换
字符串可以很方便地和整数型和浮点型的数值进行相互的转换,前提是正确使用数字型字符。
>>> int('123') # 字符串转整数型,注意不能带小数点和非数字字符。
123
>>> float('123') # 字符串转浮点型,注意不能有非数字字符,但是可以有小数点,虽然小数点并不是必须的。
123.0
>>> str(123) # 整数型转字符串型
'123'
>>> str(123.0) # 浮点型转字符串型
'123.0'
第6章 字符串与ASCII码
在Python中,单个的字符,其数据类型也是str,在Python中,
单个的字符,视为只有一个元素的字符串
。Python不像其他的编程语言那样会专门为单个的字符建立一个"char" 的数据类型。单个的字符,我们可以使用ord()函数和chr()函数实现ASCII码中的数值互换。
ASCII(American Standard Code for Information Interchange,美国信息互换标准代码)是世界上通用的编码方式之一,共有127个字符,每个字符长8位,为一个字节。ASCII码中包括英文大小写、数字以及其他的特殊字符。

我们可以看出,每一个英文字符,无论其大小写,都有一个二进制及十进制代表与之对应。
那么,我们使用ord()函数就能获得该字符在ASCII码表中的对应十进制数,反之,使用chr()函数则能将一个十进制的数转化为其对应的字符。
>>> ord("A") # 使用ord("A")就能获得该字符在ASCII码表中的对应十进制数
65
>>> chr(65) # 使用chr(65)则能将一个十进制的数转化为其对应的字符
'A'
第7章 字符串的运算符
Python中可以使用运算符"+“实现字符的拼接;用运算符”*"实现字符的复制。
>>> "abc" + "def" # 运算符"+"实现字符的拼接
'abcdef'
>>> "abc" * 2 # 运算符"*"实现字符的复制
'abcabc'
Python中可以使用运算符 in 和 not in 判断某个字符或字符串片段是否属于该字符串。
>>> s = "I Love China"
>>> s = s[:7] + "Python"
>>> s
'I Love Python'
>>> s = "I Love China"
>>> "I" in s
True
>>> "L" not in s
False
>>> "Love" in s
True
>>> "China" not in s
False
第8章 字符串与转义符
当我们需要在字符串中使用特殊字符时,我们需要使用转义符,Python使用反斜杠""表示转义符。
我们都知道,字符串是由一对 " 或 ’ 字符包裹起来的字符序列。那么问题来了,如果在字符串中,也要输入 " 或 ’ 字符,这中情况下应该怎么办呢?
观察以下的代码:
>>> "注意:在双引号中使用'单引号"
"注意:在双引号中使用'单引号"
>>> '注意:在单引号中使用"双引号'
'注意:在单引号中使用"双引号'
>>> "注意:在字符串中使用\"转义符"
'注意:在字符串中使用"转义符'
>>> '注意:在字符串中使用\'转义符'
"注意:在字符串中使用'转义符"
发现什么规律了吗?
在双引号中,可以使用单引号,但是不能使用双引号;
在单引号中,可以使用双引号,但是不能使用单引号;
如果想在字符串任意地使用单引号或双引号,应该使用转义符。
转义符是一类特殊的字符,用于在字符串中表示特殊字符。
转义符占用一个字符的位置
。
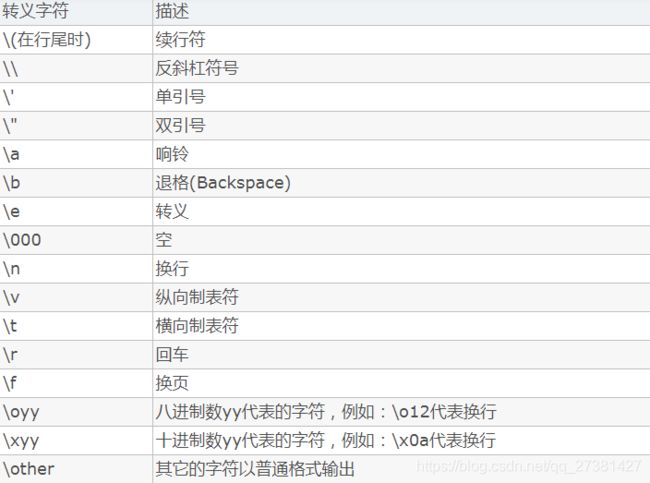
我们来观察下字符串使用了转义符之后的打印效果
>>> print('lily\'s dog')
lily's dog
>>> print('She says:"Hello!"')
She says:"Hello!"
>>> print('Here is a dog.\nThere is a cat.')
Here is a dog.
There is a cat.
提问:字符串 'ab\rcd’的长度是多少?(即字符串中包含多少个字符?)
A 4个
B 5个
C 6个
D 7个
正确答案是B。因为\r这个转义符只占用1个字符的位置。我们可以
使用len()函数获得字符串中字符的个数
。len()函数是Python中一个非常重要的内置函数,后面当我们讲到列表的时候还会用到它。
>>> len('ab\rcd')
5
有时候,我们希望保留字符串原来的模样,不希望对字符进行转义,这时可以使用原始字符串,并在字符串之前加上
r 或者 R
,那么,字符串中所有的字符都会表示其原始的含义而不会进行转义。
>>> path = 'c:\windows\administrator' # 不使用原始字符串的效果
>>> print(path)
c:\windowsdministrator
>>> path = r'c:\windows\administrator' # 使用原始字符串的效果
>>> print(path)
c:\windows\administrator
在Python中,一般在设定文件的路径时使用原始字符串,可以省去写转义符的烦恼。
第9章 字符串的输出
方法一:打印格式化字符,需要注意的是,格式化字符需要与变量的类型保持一致。
%s:对应字符串类型
%d:对应整数型类型
%f:对应浮点数类型,".2"表示保留两位小数
>>> name,age,money = "Ross",20,200000
>>> print("%s虽然只有%d岁,但是她已经赚到了%.2f元的钱了。"%(name,age,money))
Ross虽然只有20岁,但是她已经赚到了200000.00元的钱了。
方法一是延续了C语言的风格,但是Python推荐的是第二种方法。
方法二:使用format函数,需要注意的是,format函数中打印的顺序默认为顺序执行,但是打印顺序可以人为控制。我们可以在{}中设定变量出现的顺序。
更多详细信息请参考:
https://www.runoob.com/python/att-string-format.html
>>> name,age,money = "Ross",20,200000
print("{}虽然只有{}岁,但是她已经赚到了{:.2f}元的钱了。".format(name,age,money))
Ross虽然只有20岁,但是她已经赚到了200000.00元的钱了。
>>> print("{2}虽然只有{0}岁,但是她已经赚到了{1:.2f}元的钱了。".format(age,money,name))
Ross虽然只有20岁,但是她已经赚到了200000.00元的钱了。
age,money,name
出现的顺序是按照0、1、2排列的
,与索引的顺序很类似。在{}中,写明参数对应的index,就能取得相应的变量值了。
方法二是Python推荐的字符串格式化方法。
方法三:使用f"" 或f’'的方式。
在Python3.6.4之后,引入了一种新的字符格式化方式。
观察下列的代码:
>>> print(f"{name}虽然只有{age}岁,但是她已经赚到了{money:.2f}元的钱了。")
Ross虽然只有20岁,但是她已经赚到了200000.00元的钱了。
惊不惊喜?意不意外?在字符串之前加上 f 之后,{}中就可以直接添加变量的名字了。
小练习:
name = ‘hansen’
使用三种格式化的方法打印出"hansen的年龄为20。"的字样。
答案:
print("%s的年龄为%d。"%(name,age))
print("{}的年龄为{}。".format(name,age))
print(f"{name}的年龄为{age}。")
第10章 常用的字符串函数
capitalize() : 将字符串的第一个字符转换为大写。
lower() : 转换字符串中所有大写字符为小写.
upper() : 转换字符串中的所有小写字母为大写
swapcase() : 字符串中的大小写互换
title() : 字符串中的每个单词首字母大写
istitle() : 字符串中是否每个单词首字母大写
islower() : 字符串中是否每个单词为小写
isupper() : 字符串中是否每个单词为大写
center(width, fillchar) : 返回一个指定的宽度 width 居中的字符串,fillchar 为填充的字符,默认为空格。
count(str, beg= 0,end=len(string)) : 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定,则返回指定范围内 str 出现的次数。
endswith(suffix, beg=0, end=len(string)) : 检查字符串是否以 suffix结束,如果beg 或者 end 指定则检查指定的范围内是否以 suffix结束,如果是,返回 True,否则返回 False。
startswith(substr, beg=0,end=len(string)) : 检查字符串是否是以指定子字符串 substr 开头
,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查。
find(str, beg=0, end=len(string)) : 检测 str 是否包含在字符串中
,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,
如果包含返回开始的索引值,否则返回-1
。
index(str, beg=0, end=len(string)) : 跟find()方法一样,只不过如果str不在字符串中会报一个异常。
isalnum() : 如果字符串至少有一个字符并且所有字符都是字母或数字则返 回 True,否则返回 False。
isalpha() : 如果字符串至少有一个字符并且所有字符都是字母则返回 True,,否则返回 False。
isnumeric() : 如果字符串中只包含数字字符,则返回 True,否则返回 False。
isdecimal() : 检查字符串是否只包含十进制字符,如果是返回 True,否则返回 False。
isdigit() : 判断字符串是否全为数字或小数点,如果是返回 True,否则返回 False。
join(seq) : 将序列中的元素以指定的字符连接生成一个新的字符串。
len(string) : 返回字符串长度,即字符串中包含字符的个数。
ljust(width[, fillchar]) : 返回一个原字符串左对齐,并使用 fillchar 填充至长度 width 的新字符串,fillchar 默认为空格。
rjust(width,[, fillchar]) : 返回一个原字符串右对齐,并使用fillchar(默认空格)填充至长度 width 的新字符串
strip([chars]) : 删除字符串两侧的字符,默认为去掉字符串左右两边的空格。
lstrip() : 删除字符串左边的空格或指定字符。
rstrip() : 删除字符串字符串末尾的空格。
min(str) : 返回字符串 str 中最小的字母。
max(str) : 返回字符串 str 中最大的字母。
replace(old, new[, count]) : 用new字符串替换old字符串,默认只替换第1个字符串,可以用count改变更换字符串的位置。
split(sep=None) : 以 sep 来分割字符串 , 并返回列表。 sep 默认为 None, sep默认为空格。
小练习
demo = "I Love Python! "
去掉demo字符串中右边多余的空格;
找到字符"o"在demo新字符串中的第一次出现的位置索引;
计算字符"o"在demo中出现的次数;
计算demo字符串的长度;
用"China" 字符串替换 “Python”;
以分隔符空格" "分割demo字符串,打印分割后的列表;
去掉demo中所有的空格。
答案:
demo = "I Love Python! "
# 去掉demo字符串两边多余的空格
print('去掉demo字符串两边多余的空格:', demo.strip())
print('demo字符串现在的样子:' , demo)
print()
# 找到字符"o"在demo新字符串中的第一次出现的位置索引
print('字符"o"在demo中的第一次出现的位置索引:', demo.find("o"))
print('demo字符串现在的样子:' , demo)
print()
# 计算字符"o"在demo中出现的次数;
print('字符"o"在demo中出现的次数:', demo.count("o"))
print('demo字符串现在的样子:' , demo)
print()
# 计算demo字符串的长度
print('demo字符串的长度:', len(demo))
print('demo字符串现在的样子:' , demo)
print()
# 用"China" 字符串替换 "Python"
print('用"China" 字符串替换 "Python":', demo.replace("Python", "China"))
print('demo字符串现在的样子:' , demo)
print()
# 以分隔符空格" "分割demo字符串,打印分割后的列表。
print('以分隔符空格" "分割demo字符串:', demo.split())
print('demo字符串现在的样子:' , demo)
print()
# 去掉demo中所有的空格。
print('去掉demo中所有的空格:', demo.replace(" ", ""))
print('demo字符串现在的样子:' , demo)
print()
显示结果如下:
去掉demo字符串中的空格: I Love Python!
demo字符串现在的样子: I Love Python!
字符"o"在demo中的第一次出现的位置索引: 3
demo字符串现在的样子: I Love Python!
字符"o"在demo中出现的次数: 2
demo字符串现在的样子: I Love Python!
demo字符串的长度: 14
demo字符串现在的样子: I Love Python!
用"China" 字符串替换 "Python": I Love China!
demo字符串现在的样子: I Love Python!
以分隔符空格" "分割demo字符串: ['I', 'Love', 'Python!']
demo字符串现在的样子: I Love Python!
去掉demo中所有的空格: ILovePython!
demo字符串现在的样子: I Love Python!
小结:我们可以看到,字符串函数的返回结果并不会影响其字符串本身,所有对于字符串的修改都是基于字符串的"副本"进行的。
重点讲解:join()函数的使用方法
join函数的作用是将分隔符插入到字符串的中间。
比如说,如果我们想要将" "空格符插入到字符串"abc"这个字符串中间,打印出"a b c"这样的效果,我们就可以使用join()函数。
>>> print(" ".join('abc') )
a b c
我们来看下join()函数的定义:
“”"
S.join(iterable) -> str
Return a string which is the concatenation of the strings in the iterable. The separator between elements is S.
“”"
join函数是将一个分隔符seq依次加入可迭代对象之后,然后返回一组字符串。除了字符串之外,列表也是一种可迭代对象。我们来观察下列代码:
>>> li = ["Hello", "world!"]
>>> print(" ".join(li))
Hello world!
注意:此时列表中的元素必须是字符串格式,否则系统会报错。
join()函数还经常用在网络爬虫或文本分析的数据处理中。
比如,我得到一组字符串组成的列表,现在要将其拼成一句话表达出来,就可以使用空字符串""来做拼接。
>>> li = ["我们", "爱", "学习", "Python", "编程"]
>>> print("".join(li),end='。') # 使用空字符串将单词拼接成一句话。
我们爱学习Python编程。
第11章 Bytes数据类型
Bytes称之为"字节",Bytes数据类型也叫做字节数据类型。Bytes数据类型的基本单位是字节。在Python3.x以上的版本,字符串 和 Bytes 类型彻底分开了。
字符串是以"字符"为单位进行处理,Bytes数据类型是以字节为单位进行处理。
Bytes数据类型在操作和使用方法上与字符串数据类型基本一致,Bytes数据类型与字符串数据类型都属于"
不可变的序列对象
"
在Python中,Bytes数据类型的作用主要用于网络数据传输、二进制文件或图片的保存等。
有两种方式可以创建Bytes数据类型:
第一种,使用b+字符串的形式;
>>> bytes1 = b'1111'
>>> bytes1
b'1111'
第二种,调用bytes()函数生成Bytes数据对象的实例;
>>> bytes2 = bytes('1111',encoding='utf8') # 在Python中,程序默认是以utf8编码保存的。
>>> bytes2
b'1111'
Bytes数据类型 与 字符串数据类型 的相互转换
在实际应用中,我们通常会将 bytes类型 与 str类型 做转换。
bytes 转为 str:使用bytes.decode()
str 转为 bytes:使用str.encode()
>>> demo1 = b'Python'
>>> demo1
b'Python'
>>> demo1.decode()
'Python'
>>> demo2 = 'Python'
>>> demo2.encode()
b'Python'
Bytes数据类型的元素
在Bytes数据对象的实例中,其每个元素是用字符对应的ASCII码保存的。
>>> demo = b'ABC'
>>> for i in range(len(demo)):
print(demo[i])
65
66
67