LLM之RAG实战(二十五)| 使用LlamaIndex和BM25重排序实践
本文,我们将研究高级RAG方法的中的重排序优化方法以及其与普通RAG相比的关键差异。
一、什么是RAG?
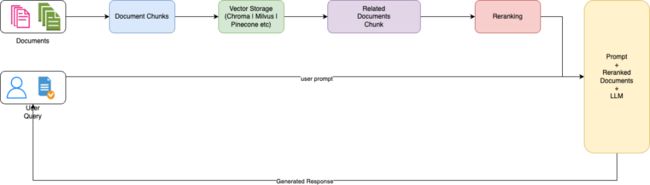
检索增强生成(RAG)是一种复杂的自然语言处理方法,它包括两个不同的步骤:信息检索和生成语言建模。这种方法旨在为语言模型提供访问外部数据源,来提高其在生成响应时的准确性和相关性,从而增强语言模型的能力。
1.1 检索组件:
目的:检索组件的主要功能是响应查询或提示,从大型数据库或语料库中提取相关文档或信息片段。
过程:当收到查询时,检索系统会搜索其数据库(如维基百科文章、书籍或其他文本数据的集合),以找到与查询相关的内容。
输出:此阶段的输出是一组与输入查询相关的文档或文本段落。
1.2 生成语言模型:
与检索到的数据集成:将检索到的文档输入到生成语言模型中,该模型使用这些文档中的信息来通知其响应生成。
响应生成:语言模型处理原始查询和检索到的文档中的信息,以生成不仅与上下文相关而且由外部数据提供信息的响应。
这种方法(RAG)允许语言模型产生比仅依靠其预先训练的知识更准确、更详细、更适合上下文的反应。
二、什么是高级RAG?
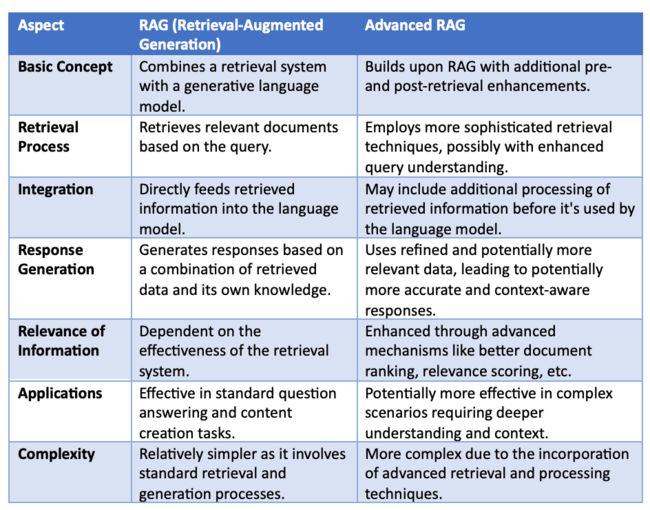
高级检索增强生成(Advanced RAG)通过结合复杂的检索前和检索后过程来增强传统的RAG。Advanced RAG中检索后过程的一个关键方面是“ReRank”,它涉及对检索到的文档进行重新排序,来优先考虑最相关的信息。ReRank通过采用各种算法或框架来实现的,比如基于文档多样性或与查询的相关性之类的标准来调整排序。重新排序的目的是向大型语言模型提供最相关的信息,从而提高生成的响应的质量和相关性。
三、RAG和高级RAG之间的主要区别是什么?
四、高级RAG重排序代码实施:
有了对Advanced RAG概念的理解,现在让我们将使用LlamaIndex作为实施的框架,BM25作为我们的排序函数。BM25算法是信息检索系统中广泛使用的排序函数,特别是在文档检索中。它是概率信息检索家族的一部分,是对经典TF-IDF(术语频率逆文档频率)方法的改进。因此,我们将使用它作为我们的重新排序函数。
在这篇文章中,我们将研究两种不同的实现高级RAG的方法,一种是使用OpenAI LLM,另一种是在完全局部LLM(Mistral)。
首先在项目文件夹的根目录中创建一个项目文件夹和包括如下内容的.env文件。
OPENAI_API_KEY="" LLM_URI="http://localhost:11434"
导入相关库
import nest_asyncioimport osimport sysimport loggingfrom dotenv import load_dotenv, find_dotenvfrom llama_index import (SimpleDirectoryReader,ServiceContext,StorageContext,VectorStoreIndex,)from llama_index.query_engine import RetrieverQueryEnginefrom llama_index.retrievers import BM25Retrieverfrom llama_index.llms import OpenAI, Ollamafrom llama_index.embeddings import OllamaEmbeddingfrom llama_index.postprocessor import SentenceTransformerRerankfrom llama_index import QueryBundle
配置asyncio和logger
logging.basicConfig(stream=sys.stdout, level=logging.INFO)logging.getLogger().handlers = []logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))nest_asyncio.apply()
让我们设计一个名为AdvancedRAG的类,该类具有以下3个函数:
class AdvancedRAG:def __init__(self):_ = load_dotenv(find_dotenv())# load documentsself.documents = SimpleDirectoryReader("./data/", required_exts=['.pdf']).load_data()# global variables used later in code after initializationself.retriever = Noneself.reranker = Noneself.query_engine = Noneself.bootstrap()def bootstrap(self):# initialize LLMsllm = OpenAI(model="gpt-4",api_key=os.getenv("OPENAI_API_KEY"),temperature=0,system_prompt="You are an expert on the Inflamatory Bowel Diseases and your job is to answer questions. Assume that all questions are related to the Inflammatory Bowel Diseases (IBD). Keep your answers technical and based on facts – do not hallucinate features.")# initialize service context (set chunk size)service_context = ServiceContext.from_defaults(chunk_size=1024, llm=llm)nodes = service_context.node_parser.get_nodes_from_documents(self.documents)# initialize storage context (by default it's in-memory)storage_context = StorageContext.from_defaults()storage_context.docstore.add_documents(nodes)index = VectorStoreIndex(nodes=nodes,storage_context=storage_context,service_context=service_context,)# We can pass in the index, doctore, or list of nodes to create the retrieverself.retriever = BM25Retriever.from_defaults(similarity_top_k=2, index=index)# reranker setup & initializationself.reranker = SentenceTransformerRerank(top_n=1, model="BAAI/bge-reranker-base")self.query_engine = RetrieverQueryEngine.from_args(retriever=self.retriever,node_postprocessors=[self.reranker],service_context=service_context,)def query(self, query):# will retrieve context from specific companiesnodes = self.retriever.retrieve(query)reranked_nodes = self.reranker.postprocess_nodes(nodes,query_bundle=QueryBundle(query_str=query))print("Initial retrieval: ", len(nodes), " nodes")print("Re-ranked retrieval: ", len(reranked_nodes), " nodes")for node in nodes:print(node)for node in reranked_nodes:print(node)response = self.query_engine.query(str_or_query_bundle=query)return response
Initialization方法(__init__):
环境设置:使用load_dotenv(find_dotenv())加载环境变量。这可能用于配置设置,如API密钥或URL。
文档加载:使用SimpleDirectoryReader从指定目录加载文档。这些文档可能被用作检索任务的语料库。
全局变量:为检索器、重排序器和query_engine设置占位符,它们可能是检索和排序过程中的关键组件。
Bootstrap方法调用:调用Bootstrap方法来初始化各种组件。
Bootstrap方法:
初始化大型语言模型(llm):使用Ollama或OpenAI GPT-4设置语言模型实例(llm)。
初始化嵌入模型:使用OllamaEmbedding设置嵌入模型(embed_mode),该模型用于创建文本的矢量表示。
服务上下文:使用块大小和模型(llm和embed_mode)配置服务上下文。
节点解析和存储:将文档解析为节点,并将其存储在内存数据库中,以便快速访问。
索引创建:使用VectorStoreIndex创建索引,以高效检索文档。
Retriever初始化:初始化BM25Retriever,这是一个基于BM25算法的检索模型。
重新排序初始化:使用SentenceTransformerRerank设置重新排序,重新排序检索到的结果的相关性。
查询引擎初始化:初始化一个查询引擎,该引擎将检索器和重排序器组合在一起以处理查询。
Query方式:
检索:检索与给定查询相关的节点(文档)。
重排序:对检索到的节点应用重新排序。
响应生成:使用查询引擎根据查询生成响应。
if __name__ == "__main__":adv_rag = AdvancedRAG()resp = adv_rag.query("What is the impact of IBD in women ?")print(resp)
当您使用OpenAI GPT-4配置运行上述代码时,以下应该是输出。

使用本地LLM和本地嵌入模型(Mistral)修改代码,在上面的代码中,只需注释现有的OpenAI GPT-4 LLM并使用下面的代码。
# initialize LLMsllm = Ollama(base_url=os.getenv("LLM_URI"), model="mistral")
初始化Mistral嵌入,如下所示
# initialize mistral embed modelembed_model = OllamaEmbedding(base_url=os.getenv("LLM_URI"), model_name="mistral")
现在,通过传递embed_mode来修改现有的服务上下文,如下所示:
# initialize service context (set chunk size)service_context = ServiceContext.from_defaults(chunk_size=1024, llm=llm, embed_model=embed_model)
现在,如果将代码指向下面的本地LLM和本地嵌入来编写代码,那么输出如下:
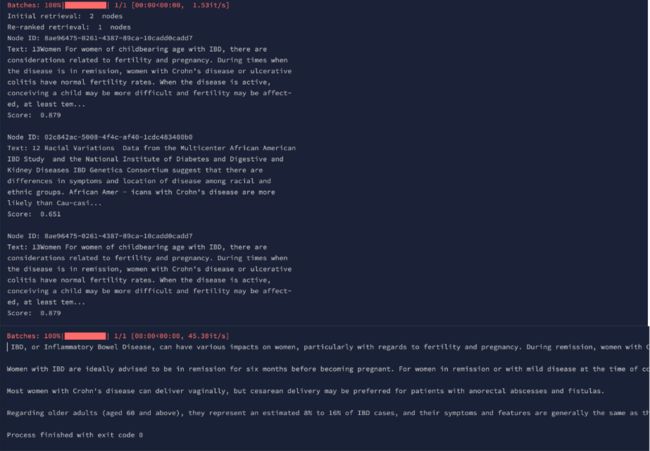
您可以清楚地看到,GPT-4和Mistral等2种方法生成的响应发生了一些显著变化,但具有置信度|重新排序分数的检索节点保持不变。
六、结论
总之,高级检索增强生成(Advanced Retrieval Augmented Generation,简称RAG)是信息检索和自然语言处理领域的一次重大飞跃。通过将BM25等最先进的排名算法与先进的重新排序技术和GPT-4或Mistral等尖端语言模型相集成,advanced RAG为处理复杂的查询任务提供了一个强大而灵活的解决方案。正如我们在讨论中举例说明的那样,这种实际实现不仅展示了Advanced RAG的理论潜力,还展示了其在现实世界中的适用性。无论是在提高搜索引擎的准确性、提高聊天机器人中响应的相关性,还是在推进知识系统的前沿领域,高级RAG证明了人工智能驱动的语言理解和信息处理的不断发展和成熟。Advanced RAG中检索准确性和上下文生成的融合为各种应用中更智能、更灵敏、更知识渊博的系统铺平了道路,预示着人工智能能力的新时代。
参考文献:
[1] https://blog.stackademic.com/advanced-retrieval-augmented-generation-how-reranking-can-change-the-game-d06e12b77074