elasticsearch增删改查
一、数据类型
1、字符串类型
(1)text
(2)keyword
2、数值类型
(1)long、integer、short、byte、float、double
3、日期类型
(1)date
4、布尔类型
(1)boolean
5、二进制
(1)binary
注:
如果文档字段没有指定,es会默认配置字段类型。
二、PUT - 创建索引库且插入数据:
(1)使用PUT可以创建索引库
PUT /索引库的名称/类型名称(高版本已废弃,一般默认会写_doc)/ 文档id
{JSON请求体} // 相当于往索引库中添加数据
PUT /lxc/type01/1
{
"name":"lxc",
"age": 28,
"height": "175"
}在elasticsearch-head中查看: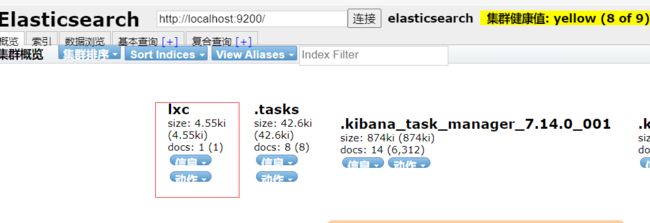
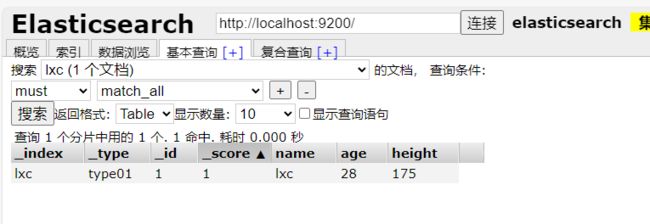
(2)通常会先创建索引库,并指定字段类型(创建规则)
下边创建了一个user索引库,并指定了索引库字段类型(name/age/createTime)
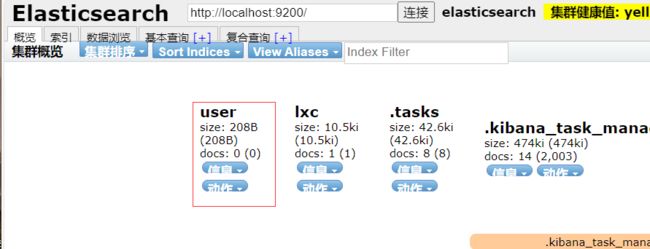
PUT /user
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"age": {
"type": "long"
},
"createTime": {
"type": "date"
}
}
}
}在kibana中执行,即可创建:

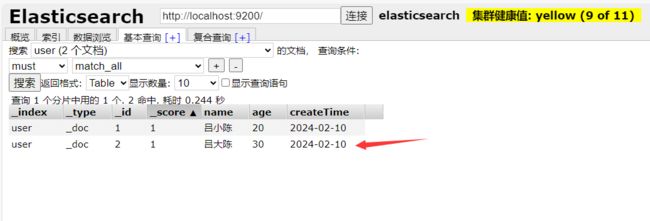
然后,往user索引库中添加数据:

三、GET - 获取索引库数据信息:
(1)GET /索引库名称:获取索引库信息(相当于列出一个表结构信息)
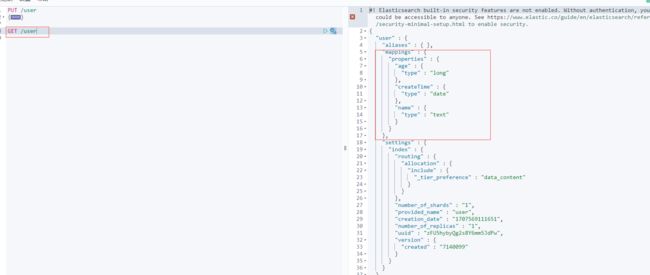
(2)GET /索引库名称/_doc/文档id:获取索引库对应文档id的数据信息(相当于根据id查询某一条数据)
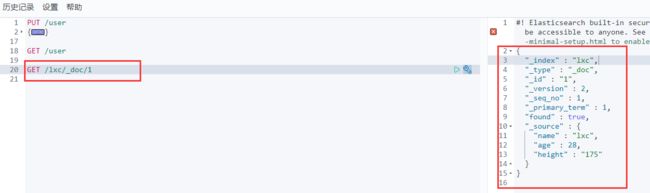
(3)GET _cat/indices?v : 获取当前es信息
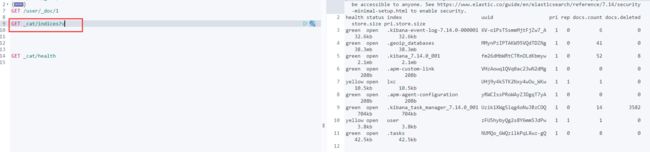
GET _cat/health : 获取当前es健康值状态
(4)高级查询
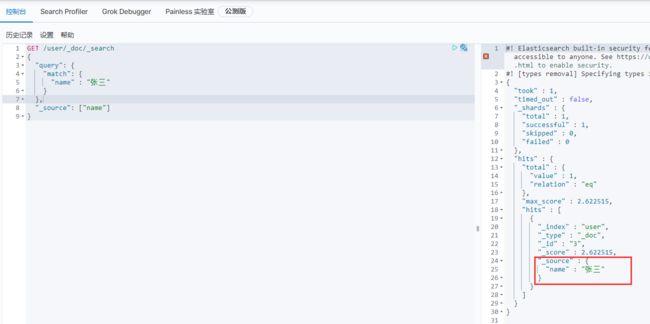
1、查询user索引库,条件:name="张三",过滤字段:只保留name
GET /user/_doc/_search
{
"query": {
"match": {
"name" : "张三"
}
},
"_source": ["name"]
}
2、多条件查询 bool
must:相当于 name = "张三" and name = "李四"
GET /user/_doc/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "张三"}},
{"match": {"name": "李四"}}
]
}
}
}should:相当于 name = "张三" or name = "李四"
GET /user/_doc/_search
{
"query": {
"bool": {
"should": [
{"match": {"name": "张三"}},
{"match": {"name": "李四"}}
]
}
}
}must_not:相当于 name != "张三" 或者 name is not "张三"
GET /user/_doc/_search
{
"query": {
"bool": {
"must_not": [
{"match": {"name": "张三"}}
]
}
}
}3、根据某i个字段排序(如果使用排序,此时分值字段 _score 会失效)
GET /user/_doc/_search
{
"query": {
"match": {
"name" : "张三"
}
},
"_source": ["name"],
// 排序
"sort": [
{
"age": {
"order": "desc"
}
}
]
}4、分页
GET /user/_doc/_search
{
"query": {
"match": {
"name" : "张三"
}
},
"from": 0, // 从第几页开始
"size": 1 // 一页展示条数
}(5)字段类型:text和keyword区别
text类型字段,会被分词器解析。
keyword类型的字段,不会被分词器解析(如果字段是keyword类型的相当于不能模糊匹配了,只能一个整体精确匹配) 。
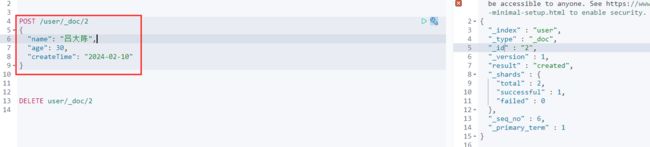
四、POST 根据文档id新增
POST /索引库/_doc/文档id
五、_update 根据文档id修改
POST /索引库/_doc/文档id/_update(这种方式的修改较之前传统PUT方式修改优点:不会因为哪一个字段没有修改就会赋值null或者置空)
下边是没修改之前的user索引库,文档id为1的数据
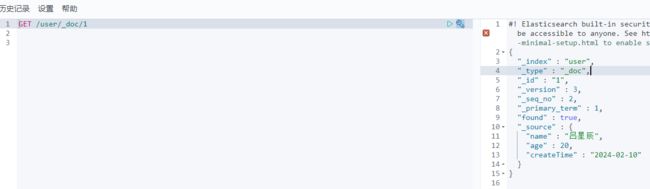
执行修改:
注意版本号 "_version" 由3 变成4 了(下边只修改了索引库中name字段值,其他不会被覆盖修改)
六、DELETE 删除
DELETE /索引库 :删除索引库
DELATE /索引库/_doc/1 删除索引库中文档id为1的数据