作者:楼江航(七锋)
日前,在阿里云 PolarDB 开发者大会上,阿里云 PolarDB 分布式产品部负责人黄贵发表了《分布式的 PolarDB:分布式的能力,一体化的体验》主题演讲。
黄贵表示,PolarDB 分布式版(PolarDB for X-scale,简称“PolarDB-X”)早期一直聚焦分布式形态,我们在 2023 年 10 月公共云和开源同时新增集中式形态,将分布式中的 DN 多副本单独提供服务,支持 Paxos 多副本、lizard 分布式事务引擎,可以 100%兼容 MySQL。同时,PolarDB 分布式版内核上具备了集中式分布式一体化的技术融合,支持集中式和分布式两种形态无缝切换,我们简称为“集分一体化”。

1. 什么是 PolarDB 分布式版集分一体化
我们可以用一个买房子的场景来做简单的类比:
集中式数据库可以类比为 90 平米的小平层。大部分情况下,对于大部分三口之家来说,买一个 90 平米左右的两室一厅小平层就足够了。这样的房子面积适中,价格适中,打扫起来也不用花费太多的精力,能满足一家人日常的需求。但有可能偶尔也会出现房子不够住的情况,比如,有亲戚朋友来的时候。同样地,大部分情况下,对于大部分中小企业来说,集中式数据库就能满足其日常的业务需求,其资源规模适中,成本适中,运维起来也比较简单。但在少部分场景下,中小企业可能也会出现业务突增的情况,需要高并发高吞吐的数据库来处理业务,对数据库的扩展性有一定的要求。
分布式数据库可以类比为 300 平米的复式别墅。复式别墅的一个优点是空间大,足够一个三世同堂甚至四世同堂的大家庭居住。复式别墅的设施也比较齐全,餐厅、会客厅、衣帽间、化妆间、储藏室、车库、花园等等一应俱全,功能丰富。但它的缺点也很明显,价格昂贵,普通家庭很难负担。另外,由于空间较大,使用起来也不太方便。例如,需要上下楼梯;楼层之间的 WiFi 信号可能不太好,可能需要组个局域网;打扫起来不太方便,可能需要雇佣专门的人打扫。同样地,分布式数据库具备较高的性能,能够处理复杂的业务场景,满足客户对高吞吐、大存储、低延时、易扩展和超高可用数据库服务的需求。但是,分布式数据库的价格较高,技术门槛和运维成本都较高,对大部分中小企业来说其适用范围比较窄。
那么,偶尔需要扩展居住空间的小家庭应该怎么办呢?有没有这样一种房子,既有复式别墅的大空间和齐全设施,又不需要业主为此付出高昂的成本呢?在现实生活中,这应该是不太容易实现的,但在数据库这个领域,我们正在努力通过集分一体化技术满足客户的这种诉求。
所谓集分一体化,就是兼具分布式数据库的扩展性和集中式数据库的功能和单机性能,两种形态可以无缝切换。在集分一体化数据库中,数据节点被独立出来作为集中式形态,完全兼容单机数据库形态。当业务增长到需要分布式扩展的时候,架构会原地升级成分布式形态,分布式组件无缝对接到原有的数据节点上进行扩展,不需要数据迁移,也不需要应用侧做改造。
2. PolarDB 分布式版为什么要做集分一体化
可能有人会问,既然大部分中小企业都没有使用分布式数据库的需求,那分布式数据库还是不是真正有效的需求?答案是肯定的,分布式数据库的需求是显性的,我们已经有客户在使用分布式数据库了,可扩展、高并发、高吞吐的分布式数据库已经运行了很多年了。
我们现在应该探讨的问题是,分布式数据库能不能给大部分情况下没有分布式需求、但偶尔有分布式需求的客户来用?从功能上讲,分布式数据库当然可以给没有分布式需求的客户用,就好比 300 平米的复式别墅当然可以给一个普通的三口之家用。但问题是分布式数据库的成本太高了,在常规的业务场景里,没有分布式的需求,使用分布式数据库是否有一种“杀鸡用牛刀”的感觉?对此,我们秉持的理念是“在业务无需分布式时,客户不应为此付出成本”。
PolarDB 分布式版之所以要做集分一体化,就是要解决一个问题:扩展使用场景来降低用户的使用门槛,同时省去分布式数据库带来的额外成本。
3. PolarDB 分布式版怎样实现集分一体化
要实现集分一体化,需要突破一系列的关键技术,我们的核心技术理念:
- 用分布式技术提升集中式的可靠性与扩展性。
- 用集中式优化分布式的性能与体验。
3.1 Paxos 多副本高可用
Paxos 是一种解决分布式系统一致性问题的共识协议。
PolarDB 分布式版的集中式形态,基于分布式中的 DN 节点提供单独服务,全面享受了分布式的技术红利,基于 Paxos 协议的多副本,保障数据多副本之间的一致性,满足 RPO=0 以及 RTO<30 秒,可以很好地满足金融级场景的容灾诉求。

3.2 无缝升级切换
PolarDB 分布式版跨形态的无缝升级切换,支持将集中式形态下的 DN,逆向恢复为分布式下挂的 DN 节点(过程中需要构建分布式元数据、以及带 DNS 域名的一键切换),整个升级过程中原有集中式的数据不动,分钟级完成分布式的整体切换。

3.3 分布式事务优化
PolarDB 分布式版结合 DN 存储节点复制组的边界,引入 TableGroup(简称表组)的概念,其中一个表有多个分区,表组内所有表相同序号的分区称为分区组(Partition Group)。分布式水平扩展后会自动调度数据,但会根据调度算法保持一个分区组内涉及的多张表数据都在相同的 DN 存储节点上。

例如,user、orders 这两张表都以 hash(user\_id)作为分区函数,属于一个表组,对应的分区按照分区组进行绑定调度,确保相同 user\_id 的数据都在一个 DN 存储节点上,这样的事务称为单分区组事务,因为所有的事务状态都发生在一个 DN 存储节点上,针对该场景的事务读和写都可以简化交互流程,我们称为集中式场景的下推优化。
事务下推
PolarDB 分布式版针对分布式事务的标准流程是采用 2PC(Two-Phase Commit)机制,CN 节点(作为 TM 事务管理器)会通过 XA 协议接口和 DN 节点(作为 RM 资源管理器)进行事务交互。标准 2PC 事务提交的流程会有 1 次全局时间戳获取+2 次协议交互,整体的网络交互成本会比较高,影响分布式事务的响应时间。
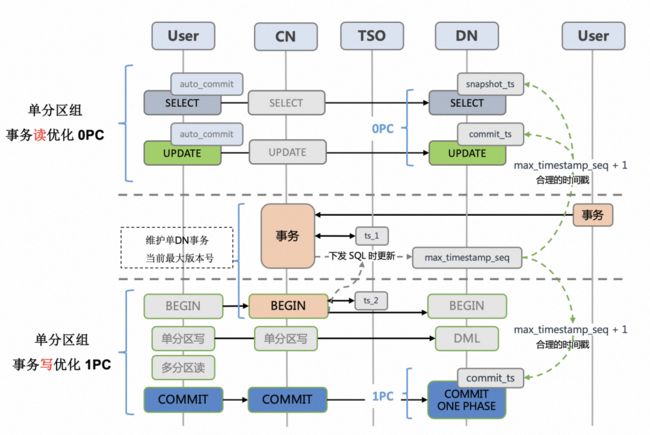
上图展示了 PolarDB 分布式版基于表组模型下的单分区组事务的相关优化:
- 针对 autocommit=true 的单分区读和写场景,可以利用单个 DN 节点的单机事务机制,可以减少通过 GMS 元数据获取 GCN,与集中式相比并不会增加任何多余的网络请求,我们称之为事务 0 PC。
- 针对 autocommit=false 的单分区写场景,可以利用单个 DN 节点的单机事务机制,采用 COMMIT ONE PHASE 语义,与分布式 2PC 相比少了一次 PREPARE 的网络阶段,我们称之为事务 1PC。
- 其余不满足单分区组的事务场景,采用标准的 2PC 事务提交流程。
3.4 按需分布式演进
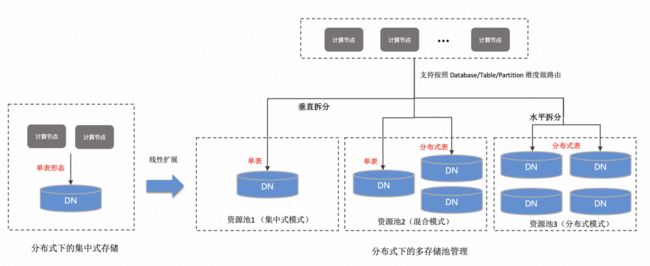
如上图,PolarDB 分布式版在面向分布式线性扩展设计上,针对集中式的能力,引入存储池和 Locality 的概念:
- 存储池:指的是将 DN 存储节点划分为互不交叉的池,支持在单个存储池维度通过添加/减少 DN 存储节点。
- Locality:指的是将数据库中的对象(数据库、表、分区)通过 Locality 属性关联到不同的资源池。
典型的按需演进分布式的场景:
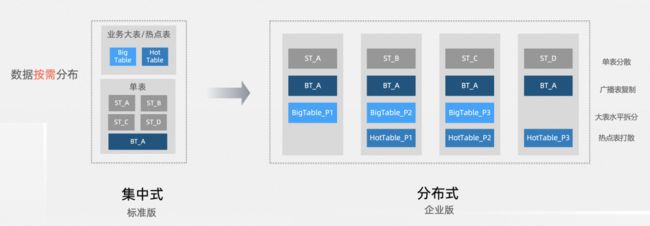
- 原始业务的多个单表,可以继续保持单表的形态,演进为分布式的垂直拆分,通过扩展单个存储池内的分布式节点后,可以实现多个单表在存储池多 DN 节点上的均衡分布。
- 原始业务的大表,可以在线变更为分布式表,演进为分布式的水平扩展,通过扩展单个存储池内的分布式节点后,分布式表的 partition 会自动进行数据均衡调度。
- 原始业务的多张表,大表在线变更为分布式表,单表继续保持并划分到多个存储池,整体演进为分布式的垂直拆分、水平拆分的组合场景,通过资源扩展实现线性能力。
按需演进分布式,除了基础的存储池模型定义,核心技术挑战在于如何支持更灵活的在线表变更能力(分布式 DDL),目前 PolarDB 分布式版支持了完整的多种表类型之间的在线变更、迁移、分裂和合并等。
4. PolarDB 分布式版集分一体化的落地实践
PolarDB 分布式版的集分一体化自发布以来,已经在客户的业务场景中得到了实践,为客户提供了丝滑的无缝升级切换体验,解决了客户的业务痛点。识货 APP 的案例就是一个典型的案例。
4.1 客户痛点
识货 APP 是一个帮助消费者做网购决策的平台,为喜欢追求性价比的消费者提供网购优惠资讯,产品覆盖国内外主流购物商城,提供的商品比价、价格订阅等特色服务为消费者在选购商品时提供了及时而精准的推荐。
这一切归功于识货的数据加工平台,该平台负责收集同类商品全网渠道的价格信息、折扣信息、满减政策,并计算出同类商品在不同平台不同渠道的售价,然后通过数据服务平台推送给消费者,便于消费者准确锁定性价比最高的渠道。
4.1.1 大促期间,数据加工性能难以保证
现在各渠道平台大促期间满减、折扣越来越多样,越来越复杂。商品价格变更瞬息万变,为了在第一时间向消费者推送最及时的价格信息,数据加工的性能就尤为关键。
在以往的大促期间,最核心的价格变更动作就需要数小时完成,导致大促期间商品价格波动情况更新不及时,业务部门投诉比较多。客户也曾尝试使用顶配 MySQL 实例(104 核),通过增加只读节点、读写分离、业务模块剥离等一系列举措,但问题始终得不到有效的解决。
4.1.2 商城扩品在即,平台处理能力捉襟见肘
识货的商品交易总额(GMV)已突破百亿,规模持续增长,预计未来几年内商城将扩品 3~5 倍,对识货整个数据加工平台的存储和计算能力都是很严峻的考验。目前核心业务的数据库已经是集中式的最高规格,升无可升,在过去的几年大促里,资源使用率偏高,处理能力急需突破。
4.2 PolarDB 分布式版的解决方案
4.2.1 集中分布式一体化,性能提升 400%
在过去的几年里,客户试图通过各种方式解决加工平台的性能瓶颈,也调研过市面上主流的分布式数据库产品,但是市面上的分布式数据库产品架构、技术各不相同,为了发挥其最佳性能,都需要遵循各自的最佳实践。识货的核心渠道库经过十多年的沉淀,积累了众多的业务模块,各个业务板块相互依赖关系错综复杂,且开发设计完全是单机习惯。一方面,客户很难将业务进行剥离。另一方面,短期内也不具备分布式改造的可能。所以客户一直未能坚定地迈出分布式升级这条路。
PolarDB 分布式版为客户指出了一条不一样的分布式升级之路。PolarDB 分布式版是一个集中式分布式一体化的数据库,每一个表既可以打散到不同的节点,也可以单节点存储。识货核心渠道库的特点是表的个数非常多,但单表体量有限,最大的日志表也只到亿级别。结合这两个特性,PolarDB 分布式版给出了如下方案:

- 按业务模块区分,各个模块的表以单表形式存储在不同节点。
- 通过不同规格的 DN 支撑不同业务的特性,避免同一规格的 DN 带来的资源浪费。
- 通过 Locality+存储池的能力,确保任何表都具备在任意节点间腾挪的能力,应对未来业务模型发生变化带来的挑战。
识货运维总监翟晟荣是这样介绍这次分布式升级的:“这就好比,我们拿出一个大规格的 DN 当做垃圾桶,所有理不清的业务逻辑的表先统一放在这里,一些核心流程上的关键业务表,我们给它提供单独的 DN 处理,上层通过分布式 CN 统一管理调度,对业务代码完全无感,而底层已经悄悄地完成了分布式改造。”
大促实战证明,经过这样的分布式改造后,数据处理能力提升了 6 倍,价格变更场景性能提升了 4 倍,从小时级别缩短到分钟级别。
整体的业务效果:

4.2.2 平滑迁移,性价比提升 500%
PolarDB 分布式版自身除了提供极致的 MySQL 兼容,确保了客户业务代码的 0 修改之外,在整个迁移过程中,也提供了丰富的功能,使迁移更丝滑。
▶︎ 热力分区图

从集中式向分布式演进的过程中,数据会被打散到不同的节点,客户普遍担心的问题包括:相关联的表是否被打散到了不同的节点带来了性能瓶颈?访问频繁的表是否被打散到了同一个节点上?为了解决这样的困扰,PolarDB 分布式版提供了分区热力图的功能,可视化实时观测各节点的容量和访问的瓶颈,通过准确定位大幅降低了迁移和日常运维的难度。
▶︎ 智能压测

核心渠道库的大量信息是来自淘宝、亚马逊、拼多多等渠道的实时价格信息,在测试环境下无法模拟这些信息,导致客户无法在测试环境进行有效业务压测,这给割接带来了很大的风险。
阿里云提供了智能压测方案 CMH-DOA(也称 frodo),frodo 可以全量采集原生产端 MySQL 的 SQL 审计,在目标端 PolarDB 分布式版进行完整的流量回放,同时支持倍速回放模拟更大的生产压力场景。通过真实流量的压测验证,有效降低了割接的风险,也为未来大促扩容提供了很好的参考依据,目前该工具目前已开源。
▶︎ 性价比大幅提升
以往在大促期间,识货 MySQL 的 QPS 一旦超过 15w 之后,性能明显下降,通过只读实例、应用限流等一系列手段后,整体 QPS 也只能勉强接近 20w。迁移到 PolarDB 分布式版之后,客户在大促期间可以增加数据加工的并发,QPS 峰值可以达到 60w,而资源使用不超过 50%。通过国际公认的性价比计算公式:price/performance,也就是月消费/QPS 峰值,计算出每个 QPS 的成本,可以发现性价比提升了 500%。
4.2.3 平台突破瓶颈,未来可期
渠道、商品、用户是整个识货最核心的板块,借助 PolarDB 分布式版集分一体化的能力轻松完成分布式演进,识货运维总监翟晟荣表示:“一次识货核心业务的分布式改造,我们没有让研发部门修改任何一行代码,性能就得到了质的飞跃。去年双 11 期间我们价格清洗需要 4 小时完成,而今年只花了 15 分钟,真正做到了代码 0 修改的分布式迁移。在 618、双 11 等多个大促期间,我们做到了数据库 0 故障的表现。我们运维部门今年也真正做到了 4 个 9 的 SLA,这对我们团队来说是很大的提升。”